Code
data3 %>%
ggplot(aes(x = hometown)) +
geom_bar() +
theme_gray (base_family = "HiraKakuPro-W3")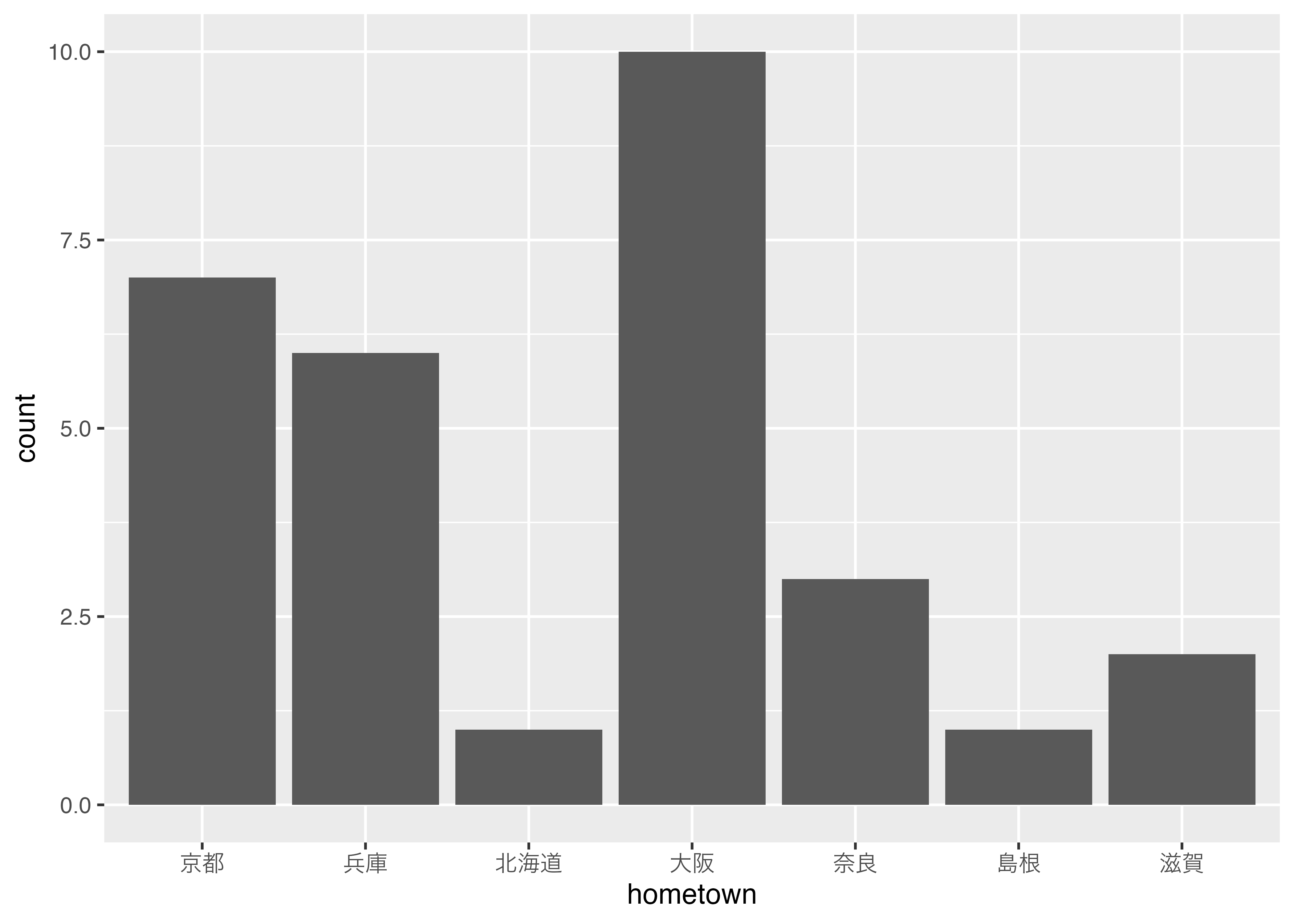
(第1回)
新しい知識や情報を得るために,システマティックに探求されるもの
理論的枠組みや先行研究を踏まえて適切な問いを立て,確実な調査技法を用いて良質のデータを獲得し,的確な方法で分析を行うことによって,問いに対する答えを導き出す
のうち,4に関連する分析方法,特に定量的データを使った定量的分析の基礎と,Rを使った分析例を扱いました。(第2回はRの基礎)
.svg)
![]()
(第3回)

データ(変数)はその性質に応じて分類が可能です。
「分類する」変数
数字の大小比較に意味がない
数字そのものが意味を持っている
数字の大小比較に意味がある

| 種類 | 尺度 | 説明 | 例 |
|---|---|---|---|
| 質的変数 | 名義尺度 | 性質を分類するために使われる(男 = 0, 女 = 1,のように性質に数値を割り当てる)。数値に意味はない。比較も計算もできない | 性別,学籍番号 |
| 質的変数 | 順序尺度 | 並び順に意味がある尺度。大小関係はあるが,計算はできない。 | 人気ランキング,成績(秀優良可不可) |
| 量的変数 | 間隔尺度 | 大小関係に加えて間隔にも意味がある。足し算はできるけど掛け算には意味がない(西暦1000年の2倍は西暦2000年,という計算に意味はある?) | 西暦・温度 |
| 量的変数 | 比例尺度 | 比較・足し算・掛け算全てできる | 身長・体重・価格・売上高・利益 |
データがそれぞれどの種類の尺度なのかによってまとめ方や分析での使い方が変わります。
(第4回)
データ解析の出発点は,データを効率的に整理・要約することで,その特徴を抽出すること
これを記述統計学と呼ぶ(↔︎️推測統計学)
| 代表値 | 意味 | 式 |
|---|---|---|
| 平均 | データの重心 | \(\bar X = \frac{1}{n} \Sigma_{i=1}^{n} X_i\) |
| 中央値 | データを大きさ順に並べたときの真ん中 | 省略 |
| 最小値 | データの中で最も小さい値 | |
| 最大値 | データの中で最も大きな値 | |
| 分散 | データのばらつき度合い | \(Var(X) = \frac{1}{n} \Sigma_{i = 1}^n(\bar X - X_i)^2\) |
| 標準偏差 | 分散の平方根 | \(SD(X) = \sqrt{\text{分散}} = \sqrt{\frac{1}{n} \Sigma_{i = 1}^n(\bar X - X_i)^2}\) |
これらはいずれもデータの概要を視覚的に表現するものです。
名義尺度や順序尺度(もしくは範囲を区切った量的変数)ごとにどれほどデータがあるかをまとめた表
カテゴリごとの度数を棒の高さで表したグラフ
特定のカテゴリごとの度数がわかるグラフ。棒グラフとは違って,連続的な変数をある一定の範囲で区切っている
複数のグループごとの中央値やばらつき度合いを視覚的に表現
freq(data3$hometown
,report.nas = FALSE,
display.labels = FALSE,
display.type = FALSE,
headings = FALSE,
style = "rmarkdown")| Freq | % | % Cum. | |
|---|---|---|---|
| 京都 | 7 | 23.33 | 23.33 |
| 兵庫 | 6 | 20.00 | 43.33 |
| 北海道 | 1 | 3.33 | 46.67 |
| 大阪 | 10 | 33.33 | 80.00 |
| 奈良 | 3 | 10.00 | 90.00 |
| 島根 | 1 | 3.33 | 93.33 |
| 滋賀 | 2 | 6.67 | 100.00 |
| Total | 30 | 100.00 | 100.00 |
data3 %>%
ggplot(aes(x = hometown)) +
geom_bar() +
theme_gray (base_family = "HiraKakuPro-W3")
data3 |>
ggplot(aes(test)) + #<1>
geom_histogram(breaks = seq(5, 105, 10)) + #<2>
scale_x_continuous(breaks = seq(0, 100, 10)) #<3>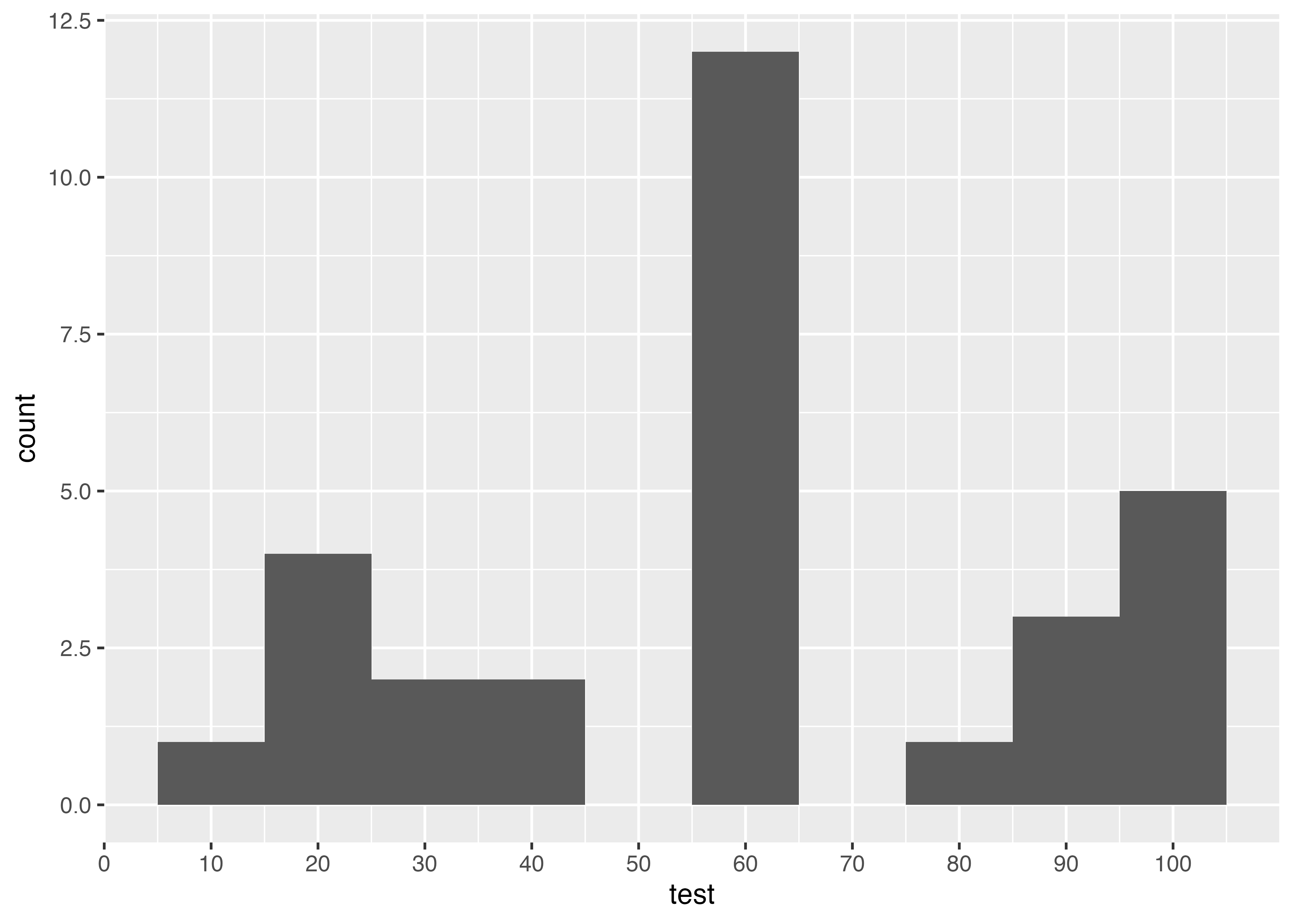
data3 %$%
boxplot(test ~ class)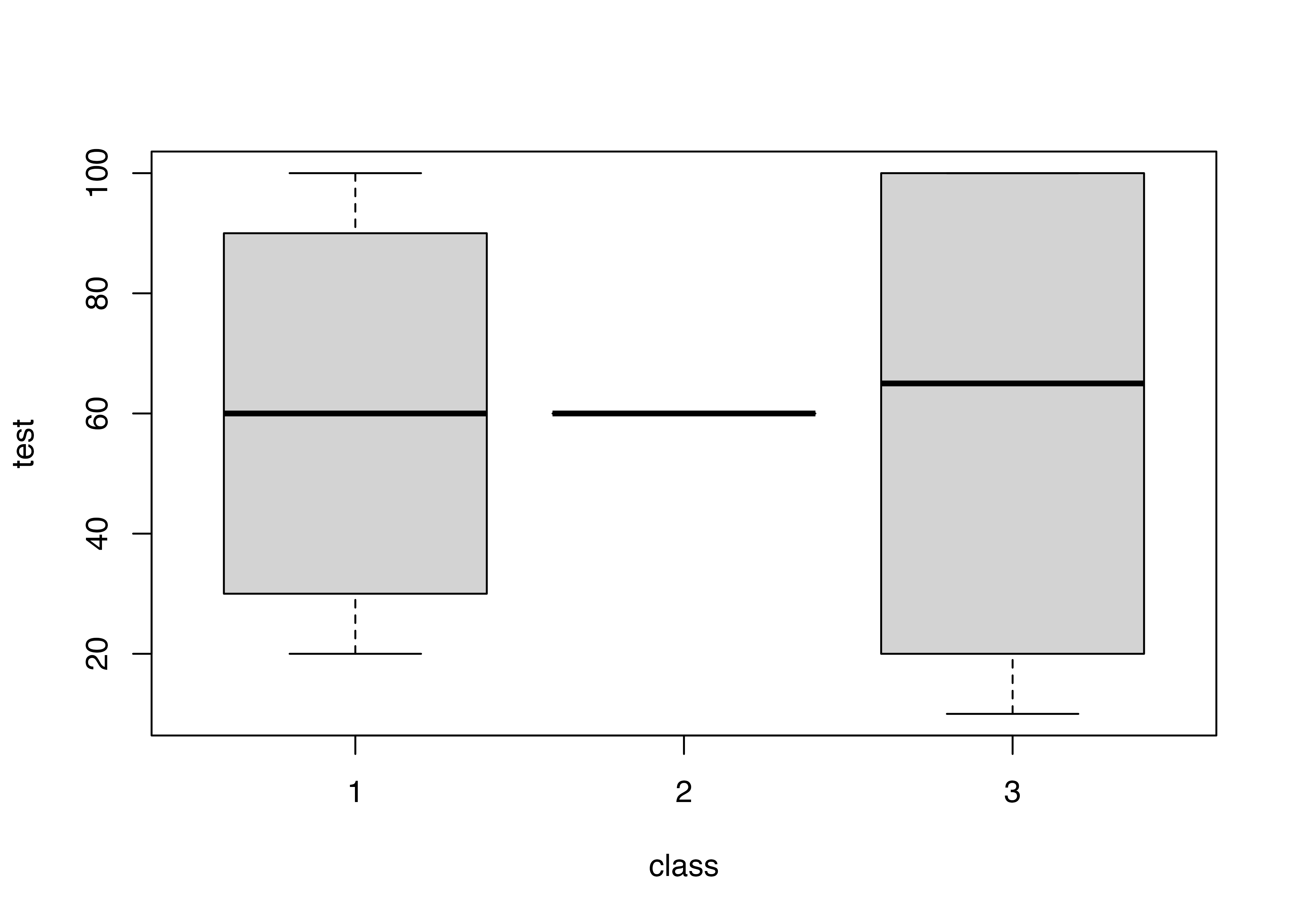
(第6回)
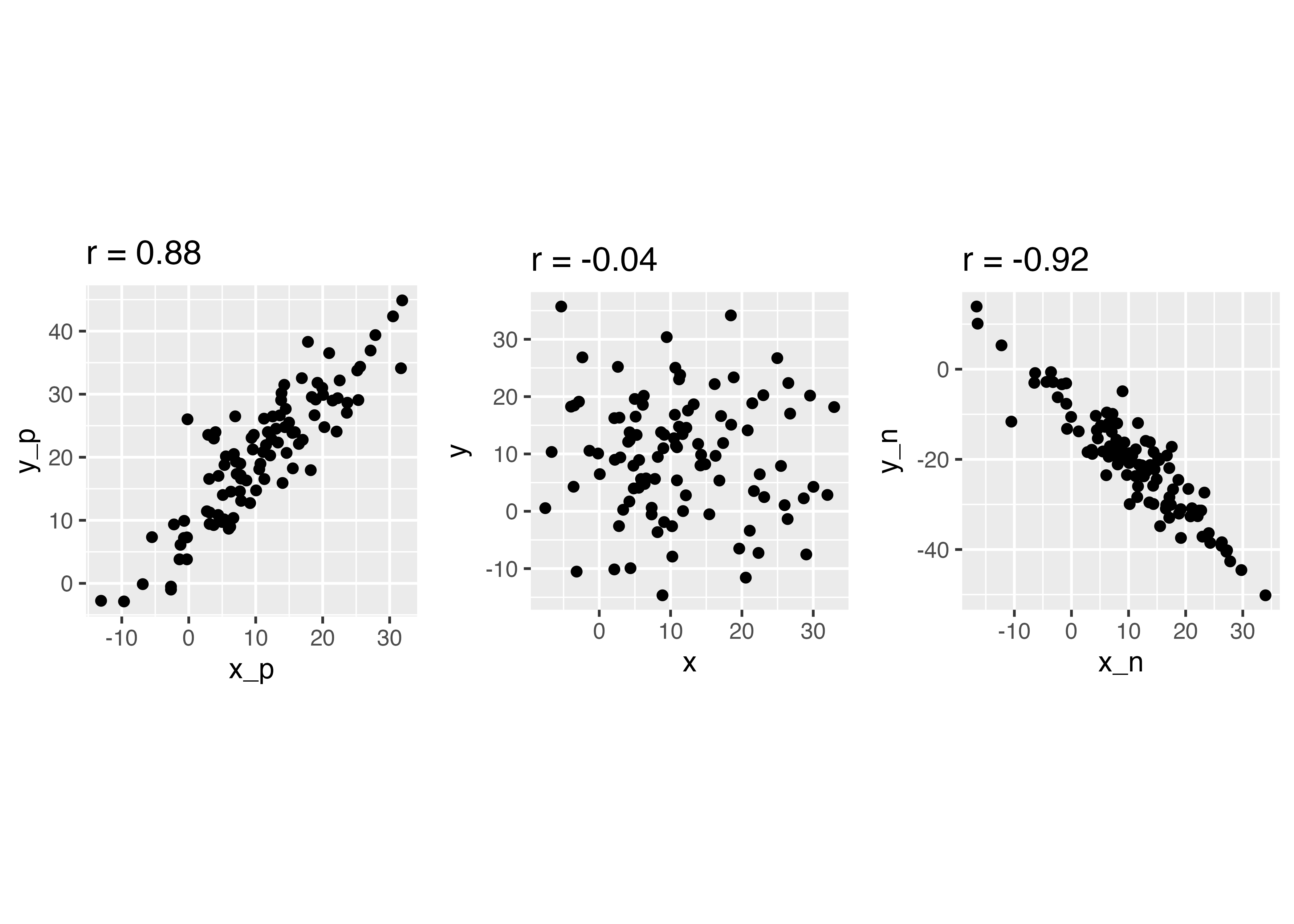
散布図から視覚的にわかることとして,右肩上がりだと正の関係(片方が高いともう片方も高い),右肩下がりだと負の関係,バラバラに散らばっていると関係がなさそう,ということ。
set.seed(123)
x_p <- rnorm(100, 10, 10)
y_p <- x_p + rnorm(100, 10, 5)
x <- rnorm(100, 10, 10)
y <- rnorm(100, 10, 10)
x_n <- rnorm(100, 10, 10)
y_n <- -x_n - rnorm(100, 10, 5)par(mfrow=c(1, 3))
plot(x_p, y_p)
plot(x, y)
plot(x_n, y_n)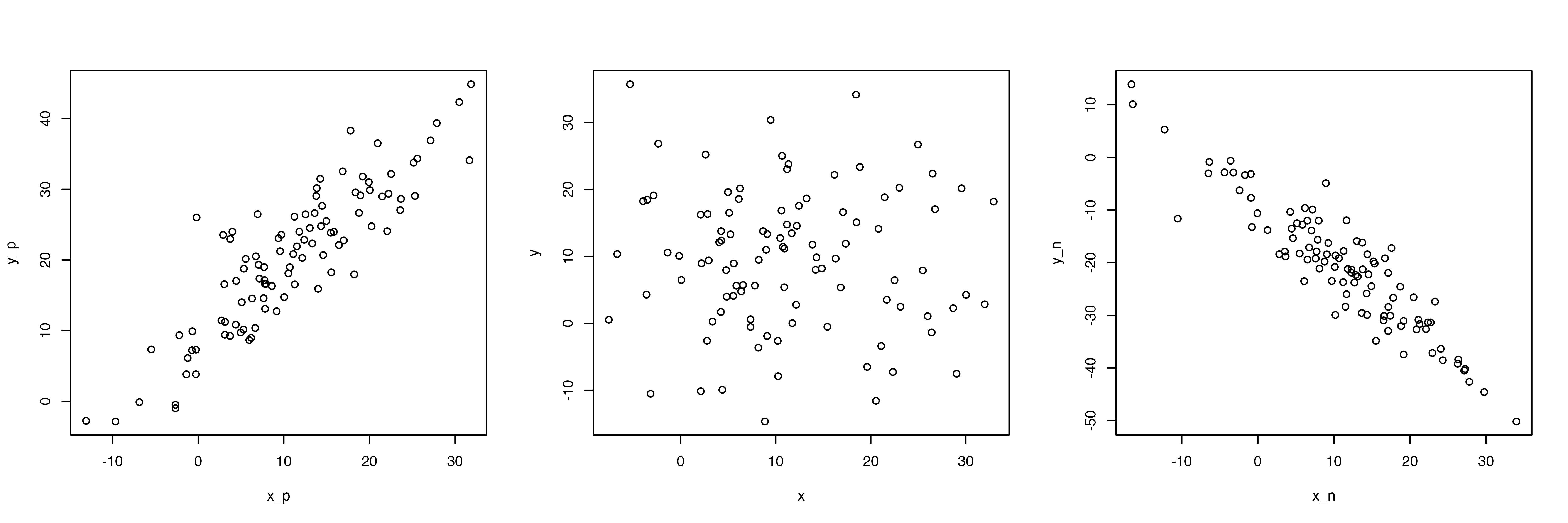
左は正の関係(xが増えるとyも増える),真ん中は関係なし(xとyに特段の関係が見て取れない),右は負の関係(xが増えるとyが減る)
相関係数rは,-1以上1以下の数値をとる。関係が強いほど-1もしくは1に近く。
クロス集計表
icedata <- icedata |>
mutate(weekend = factor(weekend,
levels = c(0,1),
labels = c("Weekdays", "Weekends")
)
)
icedata %$%
ctable(weekend, tenki,
style = 'rmarkdown',
display.labels = FALSE,
headings = FALSE)| tenki | 晴れ | 曇り | 雨 | Total | |
| weekend | |||||
| Weekdays | 6 (60.0%) | 1 (10.0%) | 3 (30.0%) | 10 (100.0%) | |
| Weekends | 1 (25.0%) | 2 (50.0%) | 1 (25.0%) | 4 (100.0%) | |
| Total | 7 (50.0%) | 3 (21.4%) | 4 (28.6%) | 14 (100.0%) |
質的変数ごとに分けた記述統計
datasummary(kyaku ~ weekend * (mean + sd + max + min),
data = icedata)| Weekdays | Weekends | |||||||
|---|---|---|---|---|---|---|---|---|
| mean | sd | max | min | mean | sd | max | min | |
| kyaku | 412.20 | 116.47 | 652.00 | 275.00 | 368.00 | 68.18 | 451.00 | 284.00 |
質的変数ごとに分けた箱ひげ図
icedata %$%
boxplot(kyaku ~ weekend)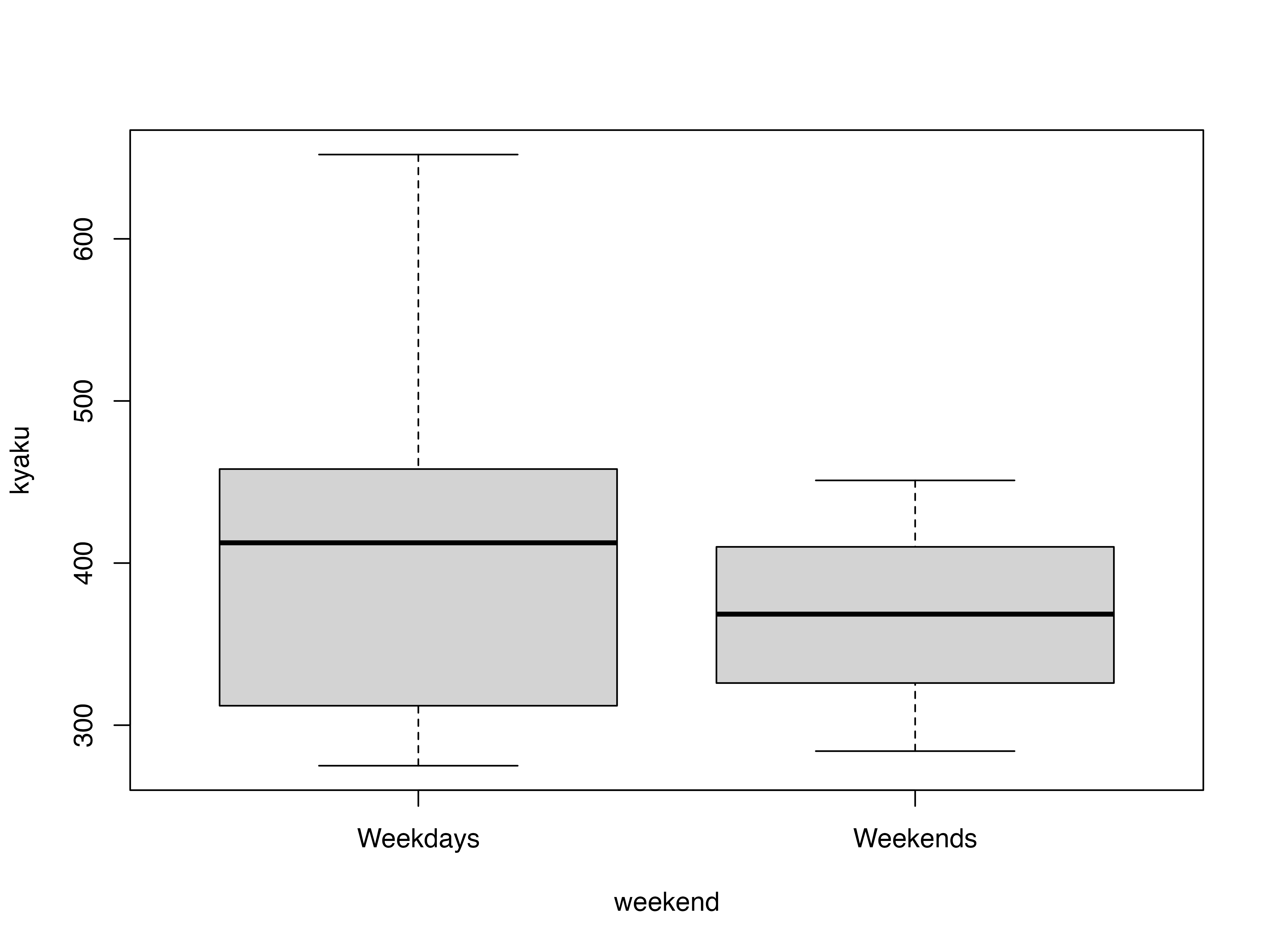
(第7回)
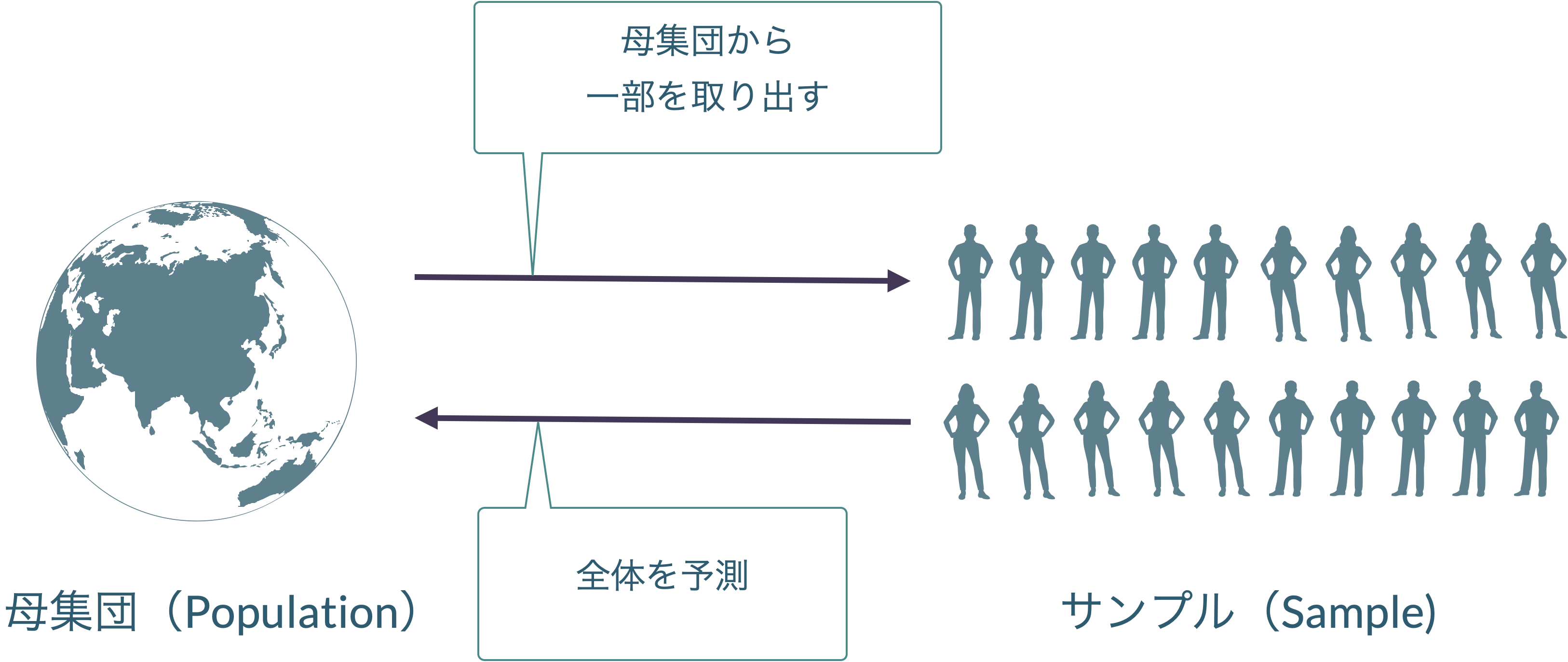
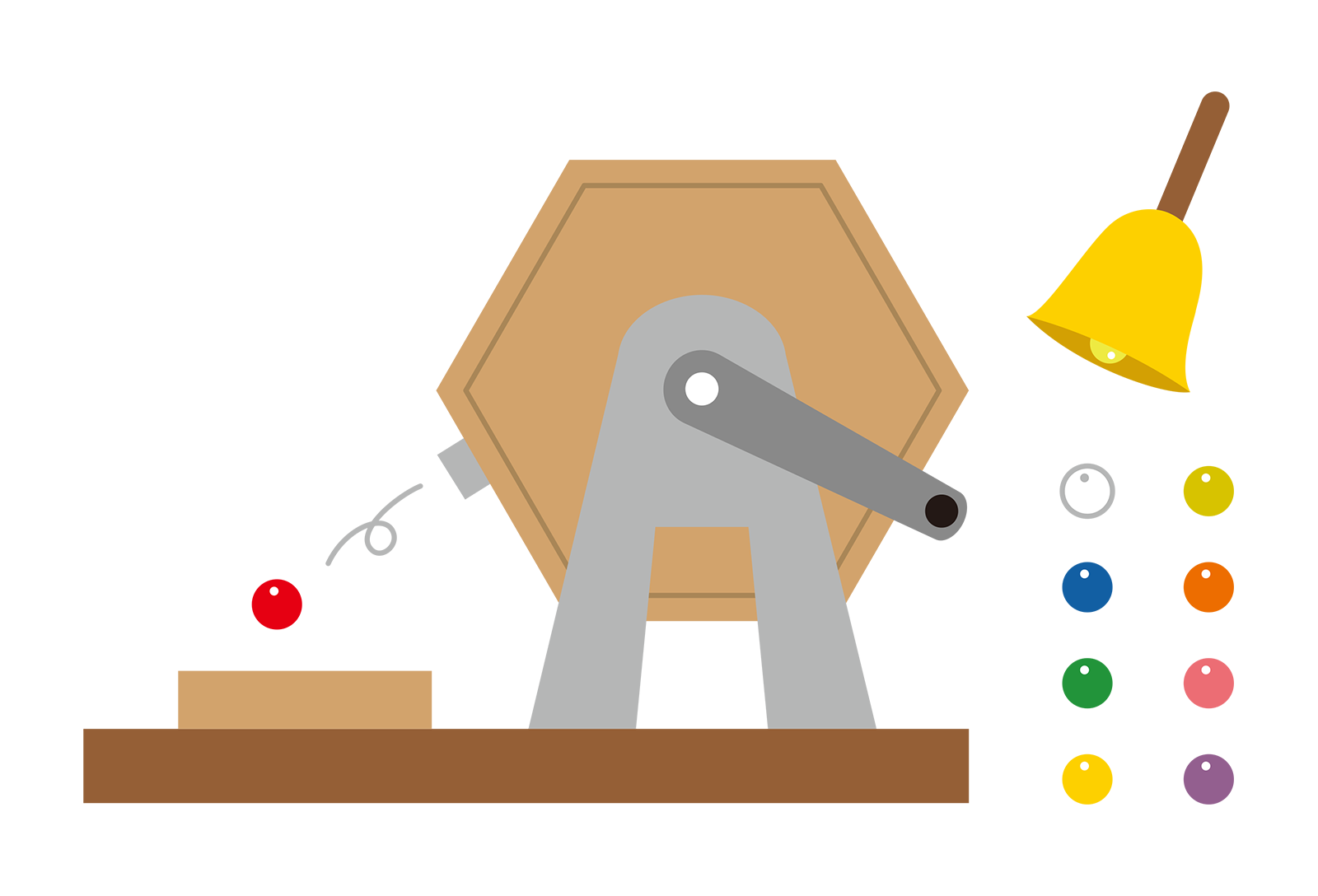
無作為抽出という手順と,確率の性質を組み合わせて利用することで,未知の母集団を推測できる!

(第8回)
このように,データを元に母集団の形(特にそれを特徴づけるパラメータ\(\theta\))を推測することを統計的推測
統計的推測には,大きく分け二つ
推定を行い,検定をする,というイメージ
標本を用いて計算された母集団の推定結果について,どちらか一方を選ぶような形で推定結果を検証する手続きをとります。これを統計的仮説検定と言います。
考察の基準となる仮説
帰無仮説が棄却されたときに解釈される仮説
統計的仮説検定では,このような二つの仮説を立て,一方を選ぶような手続きを取ります。
統計的検定は,データに基づいて得られた検定統計量について,以下のような手続きで帰無仮説か対立仮説かを選びます
2つ以上の変数の関係を統計モデルの形で仮定し,パラメータを推定する
典型的には直線関係
\[ y_i = \beta_0 + \beta_1x_i+u_i \tag{1}\]
\(\beta_0\)は切片,\(\beta_1\)は傾き。\(u_i\)は誤差。個々の点と直線の乖離
ice <- read_csv("data/9_ice4.csv")g <- ggplot(data = ice, #<1>使うデータを指定
aes(x = kion, y = kyaku) #<2>x軸とy軸を指定
) +
geom_point() + #<3>散布図
geom_smooth(method = "lm",se = FALSE) #<4>散布図にフィットする直線を書く。方法は,線形モデル(lm)
plot(g)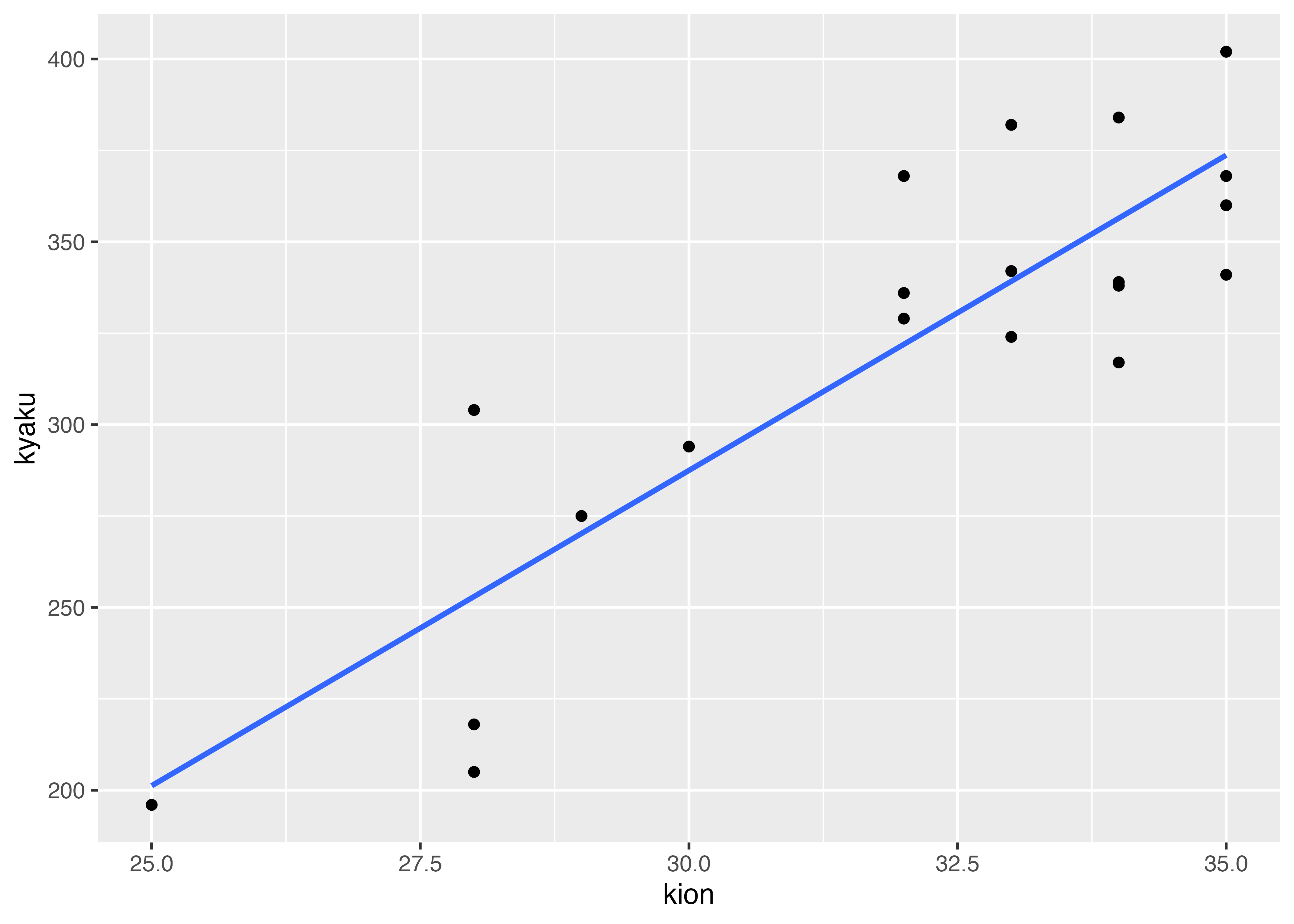
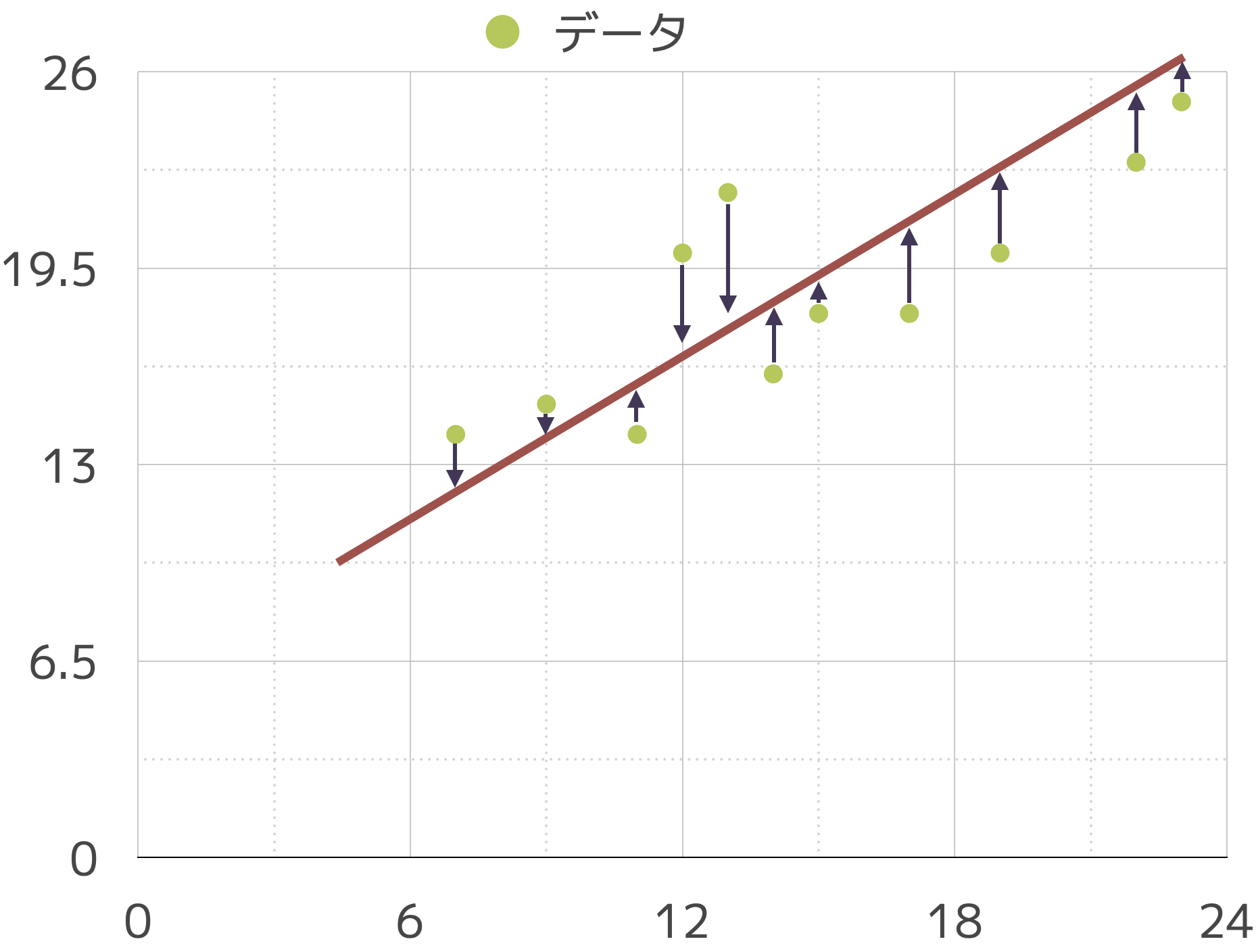
回帰分析では,最小二乗法という方法で計算します。この方法の考え方は
直線と各データの誤差を最小にする線が最も良い線であろう
というものです。
これは,他の図で矢印になっている誤差を全部足したらしたらゼロになる点を探すことを意味します。±打ち消し合うので \(E(u)=0\) が理想です。
lm(kyaku ~ kion, data = ice) |>
summary()
Call:
lm(formula = kyaku ~ kion, data = ice)
Residuals:
Min 1Q Median 3Q Max
-47.969 -17.709 -1.218 17.413 51.031
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -229.98 73.79 -3.117 0.00596 **
kion 17.25 2.30 7.499 6.08e-07 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 29.54 on 18 degrees of freedom
Multiple R-squared: 0.7575, Adjusted R-squared: 0.744
F-statistic: 56.23 on 1 and 18 DF, p-value: 6.082e-07複数の独立変数を一つの式に
\[ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + u \tag{2}\]
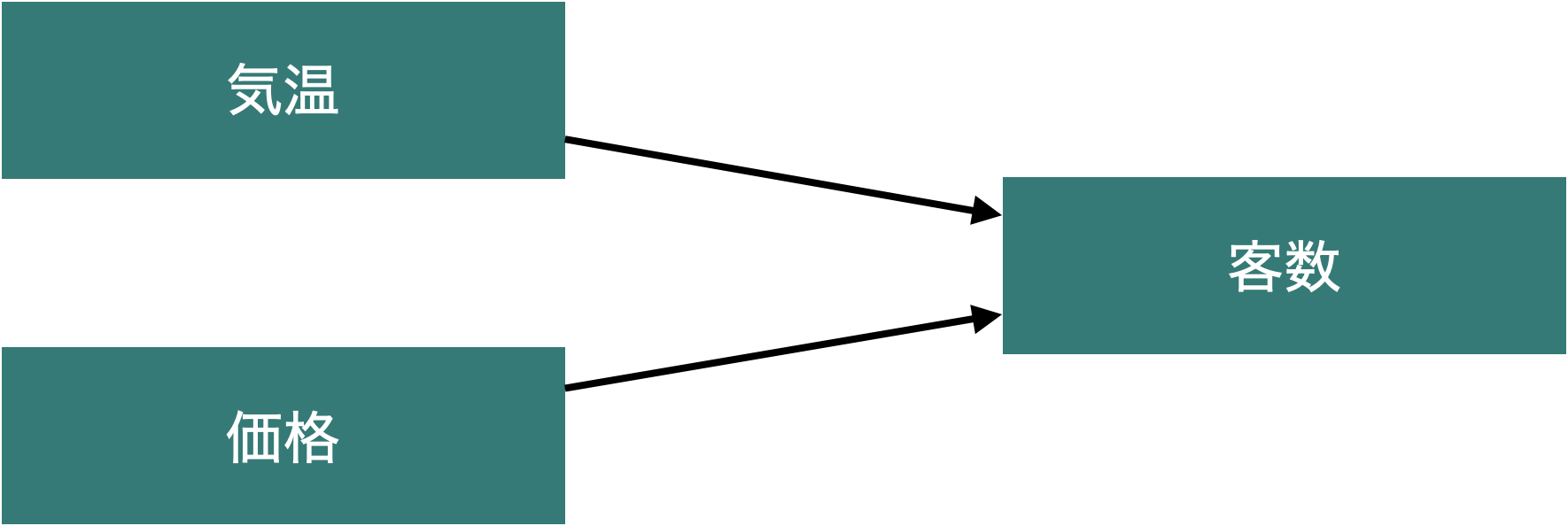
カテゴリ変数もダミー変数(偽の変数?)として回帰分析に含めることが可能。
\[ income = \beta_0 + \beta_1 age + \beta_2 gender + u \tag{3}\]
\(income\) は年収(円)、 \(age\) は年齢(歳)、 \(gender\)は性別(男は0女は1)とします。この回帰モデルを推定した場合、 \(\beta_1\)の推定値は「年齢が1歳上がると年収が \(\beta_1\)円上がる」ということを示します。一方,ダミー変数は0か1で属性をに分割しています。そのため,以下のように,男性と女性で違う式が推定されます。
\[ \begin{cases} income = \beta_0 + \beta_1 age + u & gender = 0 \text{(男性)} \\ income = \beta_0 + \beta_1 age + \beta_2 + u & gender = 1 \text{(女性)} \end{cases} \]
\[ test_i = \beta_0 + \beta_1 time_i + \beta_2 IQ_i +\beta_3 time_i \times IQ_i + u_i \tag{4}\]
みたいな式を使うと,独立変数同士の交互作用を含めた検証が可能。\(\beta_3\)の項目は,時間とIQの掛け合わせに。これによって,テストの点数の時間に対する効果(の一部)は,IQに依存する,という関係が式に含まれることになる
\[ y_i = \beta_0 + \beta_1 x_{i} + \beta_2 x^2_{i}+ u_i \tag{5}\]
(第12回)
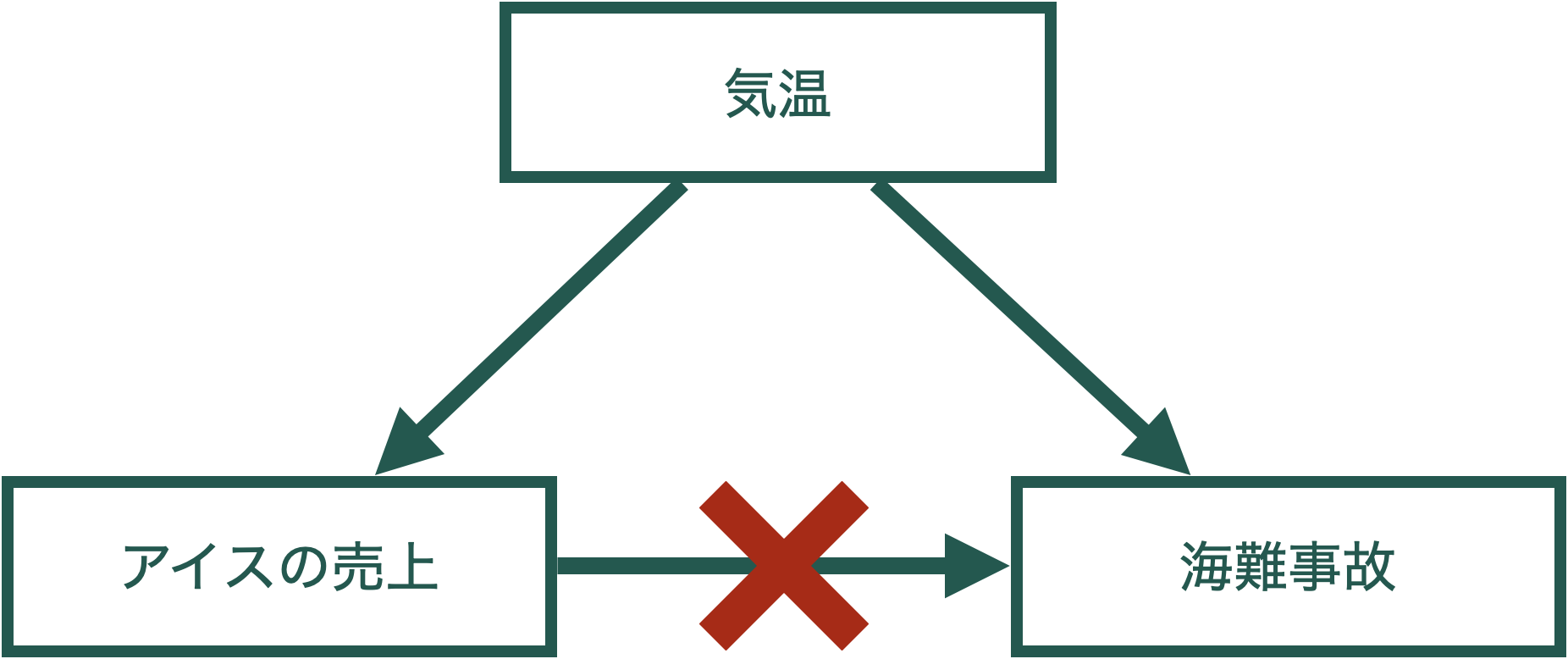
単に相関を計算したり,回帰分析をしただけではx → yという因果関係はわからない。
たくさんの参加者を集めて,その人たちにランダムに処置(投与するかしないか)を割り振る
ランダムに割り振った集団間の比較をすることで薬の「平均的な」効果を推定することができる

個人レベルで見ると因果関係はそもそも検証が不可能
集団レベルでランダムに処置を割り振ることで,平均的な効果の推定を通した因果関係が可能
内生性の問題が起こる原因は例えば
独立変数と関係があり,コントロール変数として回帰分析に含めなければいけない変数が含まれていない→誤差項に入ってしまっている
測りたいものを,誤差のある指標でしか測れない。例えば,「英語のうまさ」は直接測れない。
xはyに影響することはするけど,yがxにも影響する。
実験的手法は,調査者が何らかの介入をして,その介入効果を見るようなもの。そのような特徴から
元々理系では実験的手法が中心だったけれど,上記の特徴から社会科学領域でも実験的研究が重視されてきている
アクセスしてくる人のうち一定割合に別のデザインの画面を表示し,クリックする先やクリック率等を比較する。(どちらのデザインの方が良いか?)



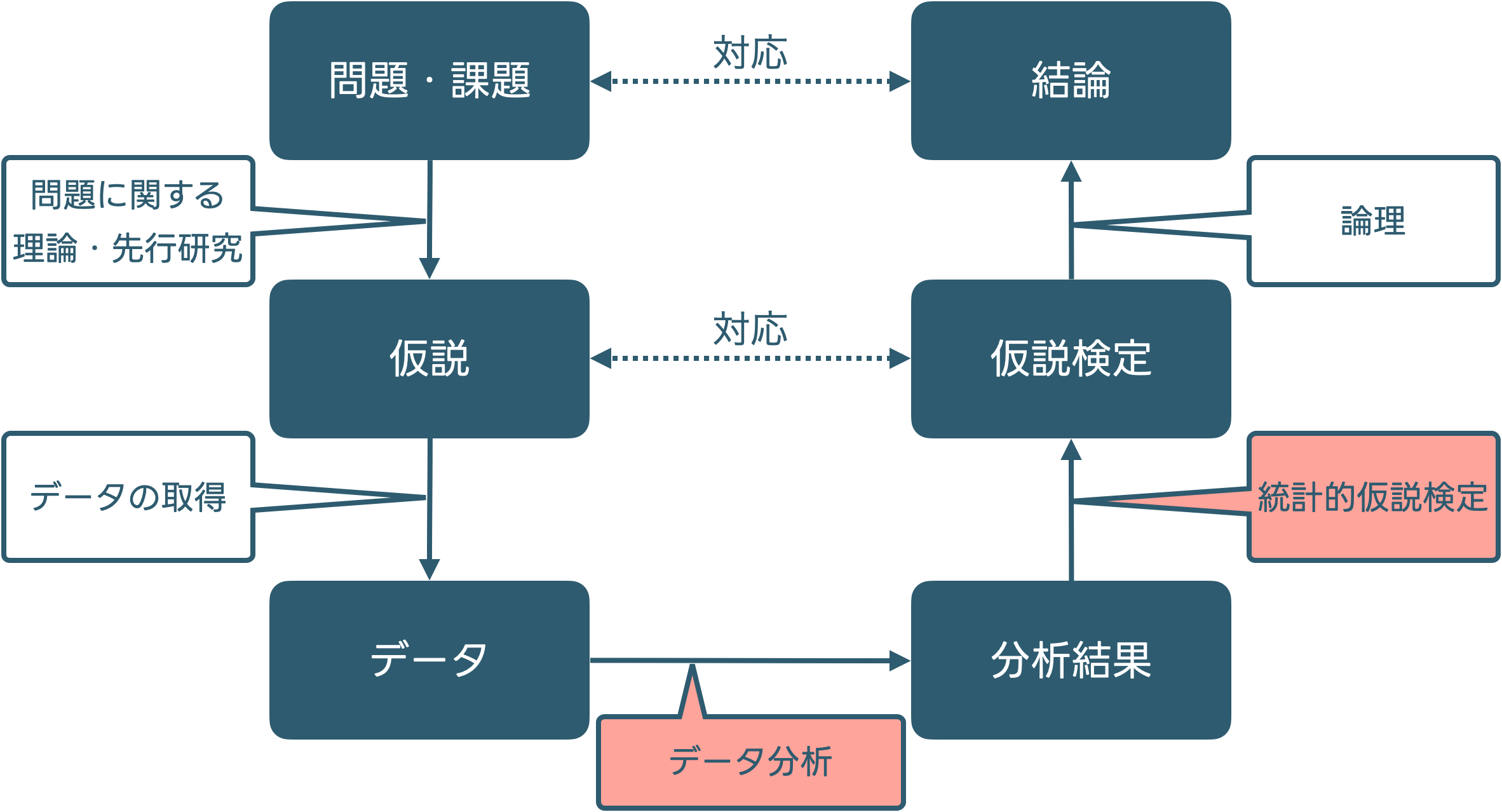
このプロセスは問題解決の最も効率的な方法?
明らかにするべき課題は何か?
例えば 伊丹 (2001) は問題の見つけ方について詳しいです。
問題・課題について関連する理論や先行研究を集め
を整理することで,問題・課題の中で重要な点を明らかにする。その上で
という仮説を設定する
仮説を検証するのに適したデータを選択
得られたデータを分析可能な形に整備
仮説検定の結果から,当初の問題の結論を論理的に結びつける
データ分析という道具を使って,ある問題の答えを出した,という位置付けを意識してください
この授業は
の間あたり,理屈がわかって分析ツールを使えるようになることを目指して(ある種挑戦的に)授業を作ってみました。

この授業の内容を理解し,各回の分析手法を体験していただけていたら
といったことがわかった上で,Rでの簡単な分析方法を身につけていただけた(らいいなと思っています)
アンケート特有の分析手続き(因子分析など)など研究方法特殊的な一部の分析を除いて,卒論レベルで求められる知識や分析手法は一通り扱ったつもりです
ありがとうございました
授業に関係なくても,データ分析などでご相談があれば連絡ください
アンケート調査のデータを定量的データと見做さないような学問領域もある↩︎