準備
パッケージ
Code
rm(list=ls()); gc(); gc();
if (!require("pacman")) install.packages("pacman")
pacman::p_load(tidyverse, magrittr, here,
modelsummary, ggrepel, patchwork,
summarytools, cowplot)
- 1
-
前の作業など,rのメモリに入っているものをリセットするコマンド
- 2
-
パッケージ管理用のパッケージである
pacmanが入っていない場合はインストール
- 3
-
複数のパッケージを一度に呼び出す
データ
アイスクリーム店の日別データです。客数(kyaku)や気温(kion),天気(tenki),週末かどうか(weekend, 週末の時1,平日の時0をとるカテゴリ変数)が含まれています。
Code
ice <- read_csv("data/6_ice.csv")
ice <- ice |>
mutate(weekend = as.factor(weekend))
- 1
-
あとで使うために,weekend変数をカテゴリ変数として教えておく
複数の変数間の関係
- 前回は1つの変数の様子を表す代表値として平均や中央値,ばらつき(分散・標準偏差)等を扱いました。
- 今回は,二つの変数の間の関係に関わる内容を扱います。
- 具体的には,二つの変数の状況によって場合分けした表であるクロス集計表や,二つの変数を図示した散布図,二つの変数間の関係の強さを表す相関係数などを学習します。
- 統計的分析を行う際に考えるののは,個々の変数(例えば質問項目ひとつひとつ)の平均や分散だけではありません。
- 多くの場合複数の変数の関係を見たくなる。ここでは,複数の変数間の関係についてを表す数値やグラフ・表について扱います。
量的変数同士の関係
散布図
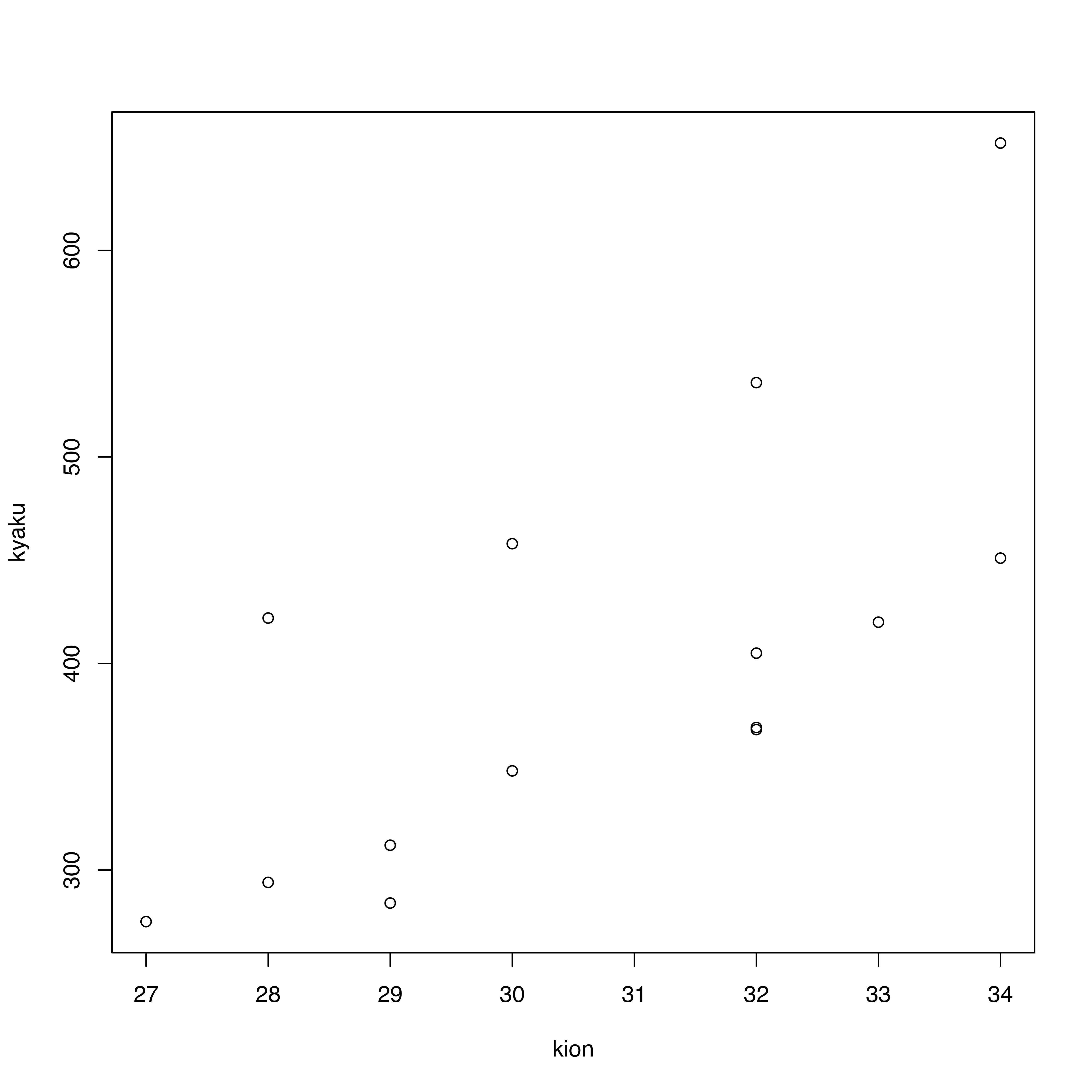
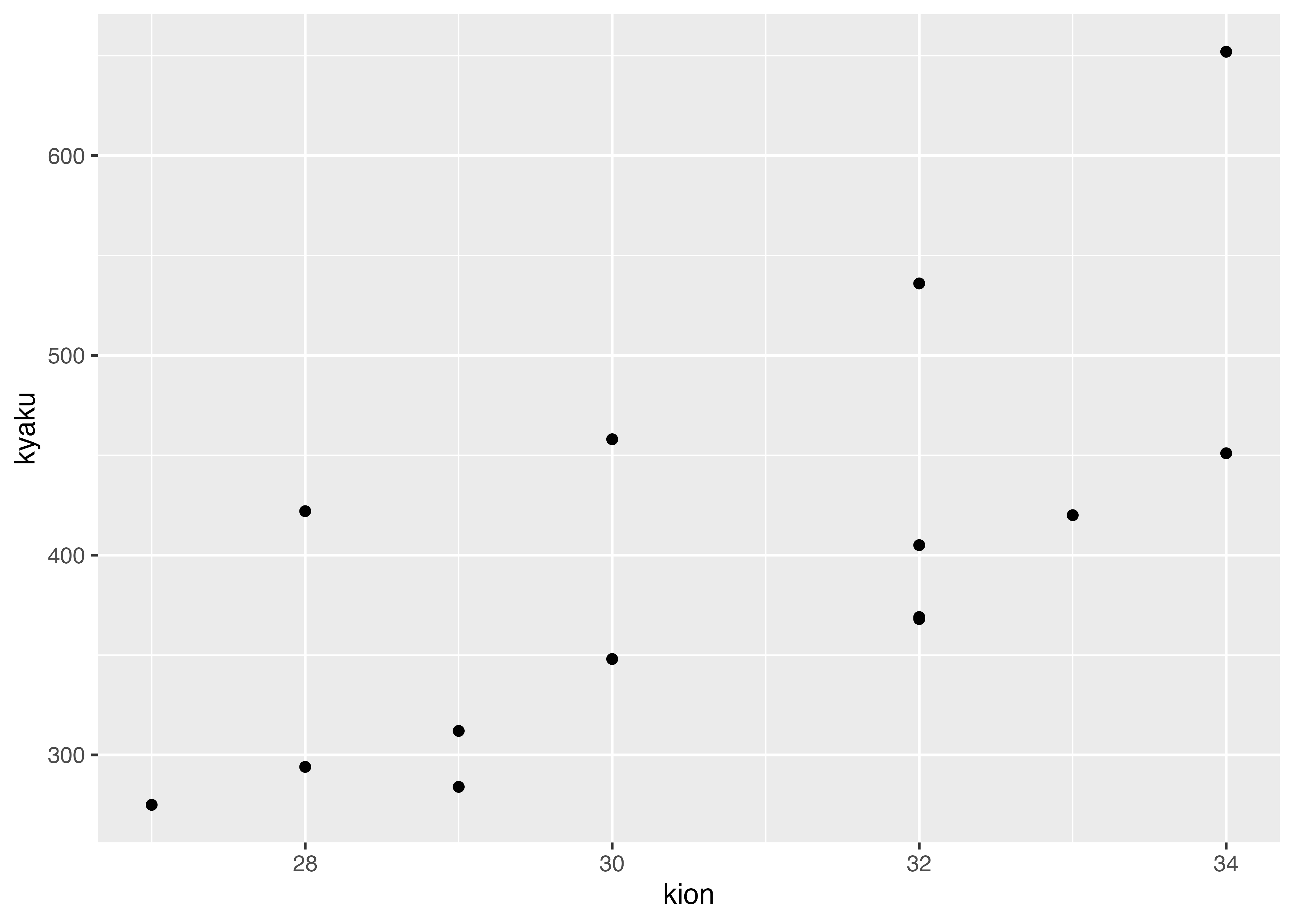
二つの変数,例えば気温とアイスクリーム屋さんの客数との関係を知りたい場合,最も単純な図示の方法は,x軸を気温,y軸を客数として,日毎や時間毎のデータを書き込んでいくこと。これを散布図と言います。
散布図を書いています。散布図を書く一番簡単なコマンドはplot(x軸にしたい変数, y軸にしたい変数)です。
%$%はこのデータを使って次のコードを実行しますよ,というマーク。以下と同じ意味
plot(ice$kion, ice$kyaku)
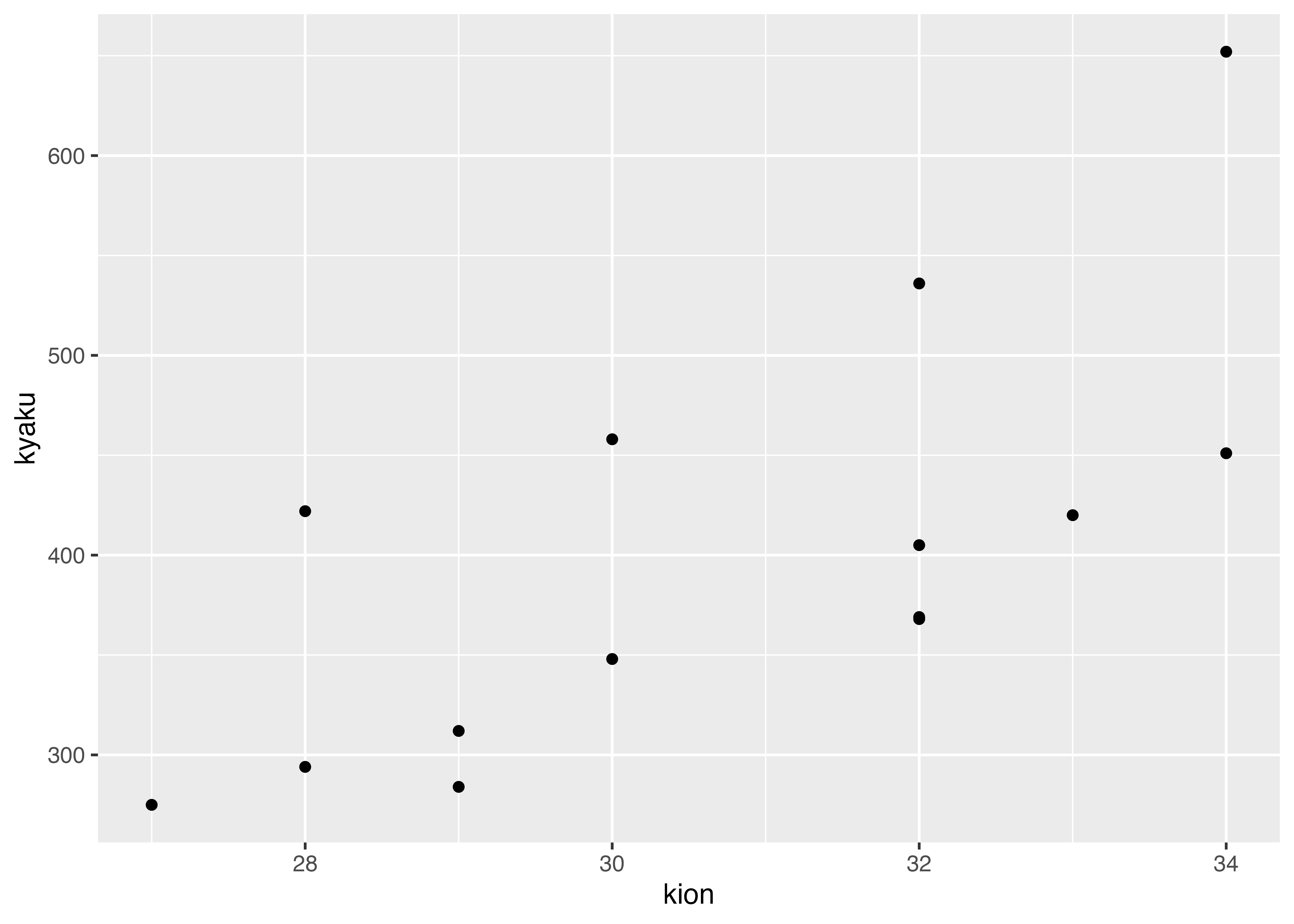
ggplot2というパッケージ(tidyverseの中に入っている)を使うと高度にカスタマイズしたグラフが書けます。
Code
ggplot(data = ice, mapping = aes(kion, kyaku)) +
geom_point() #書く数値を点(point)で書く
Code
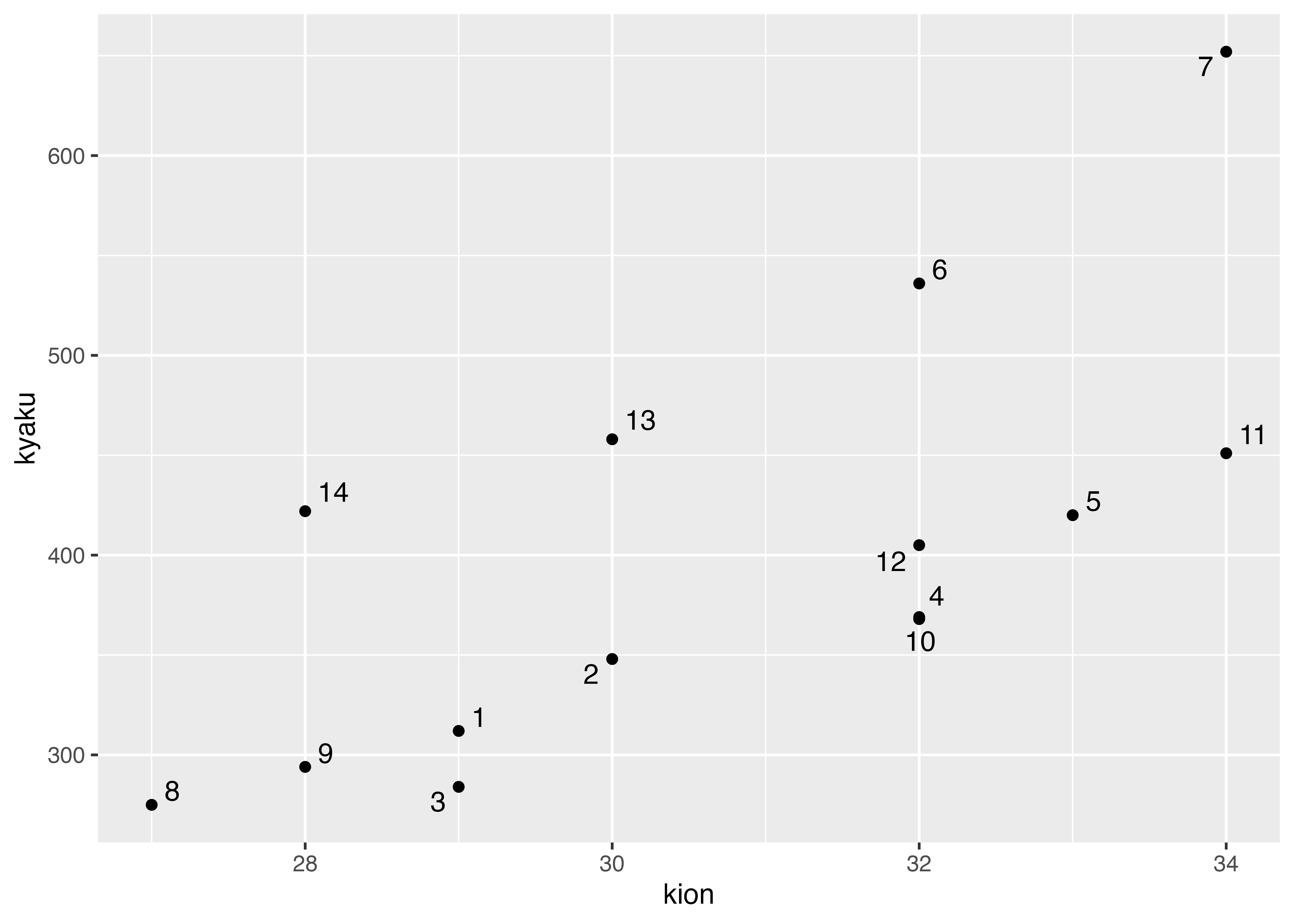
ggplot(data = ice,
mapping = aes(kion, kyaku, label = day)) +
geom_point() +
geom_text_repel()
- 1
-
グラフを作成
- 2
-
書く数値を点(point)で書く
- 3
-
各点にラベルをつける
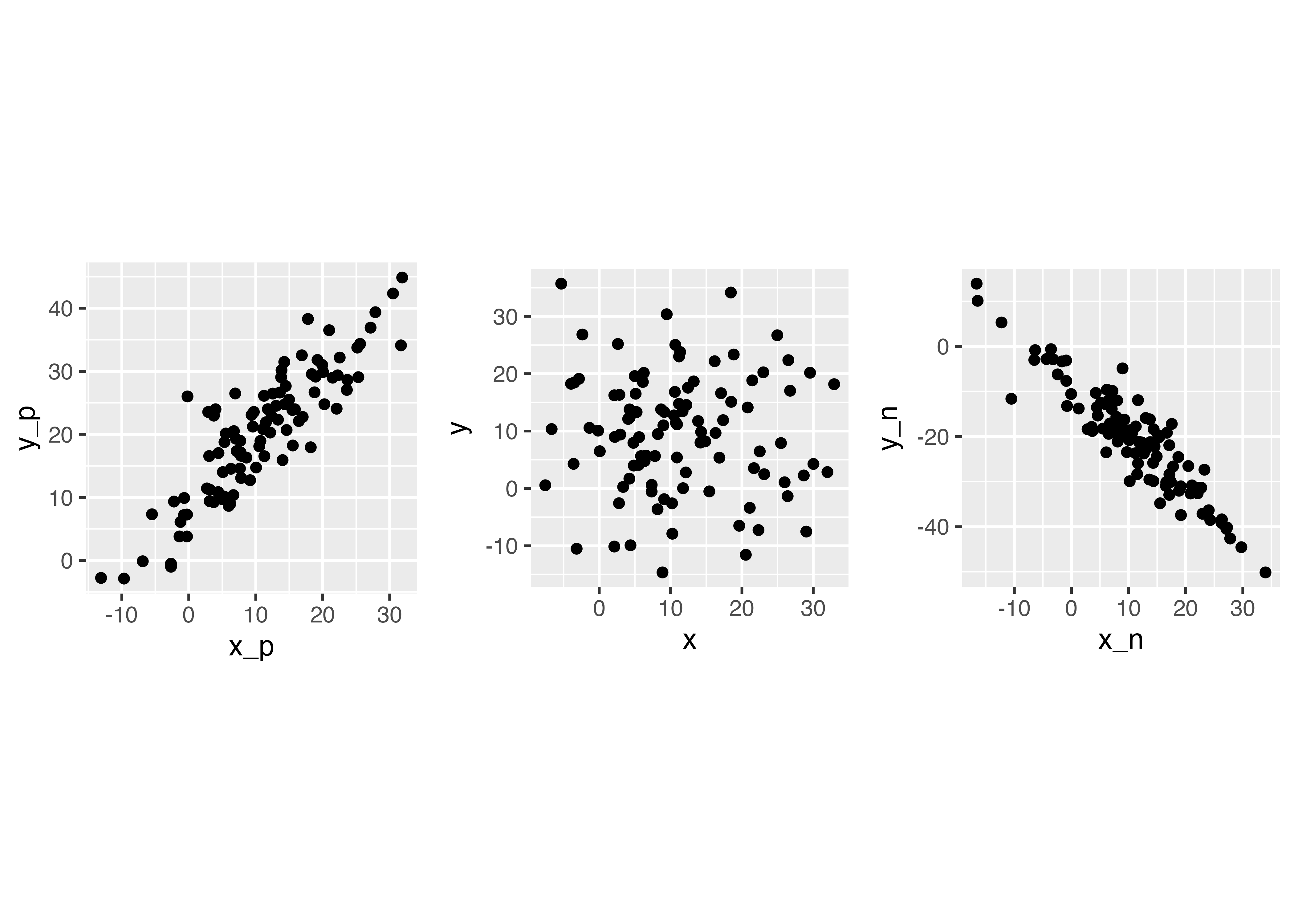
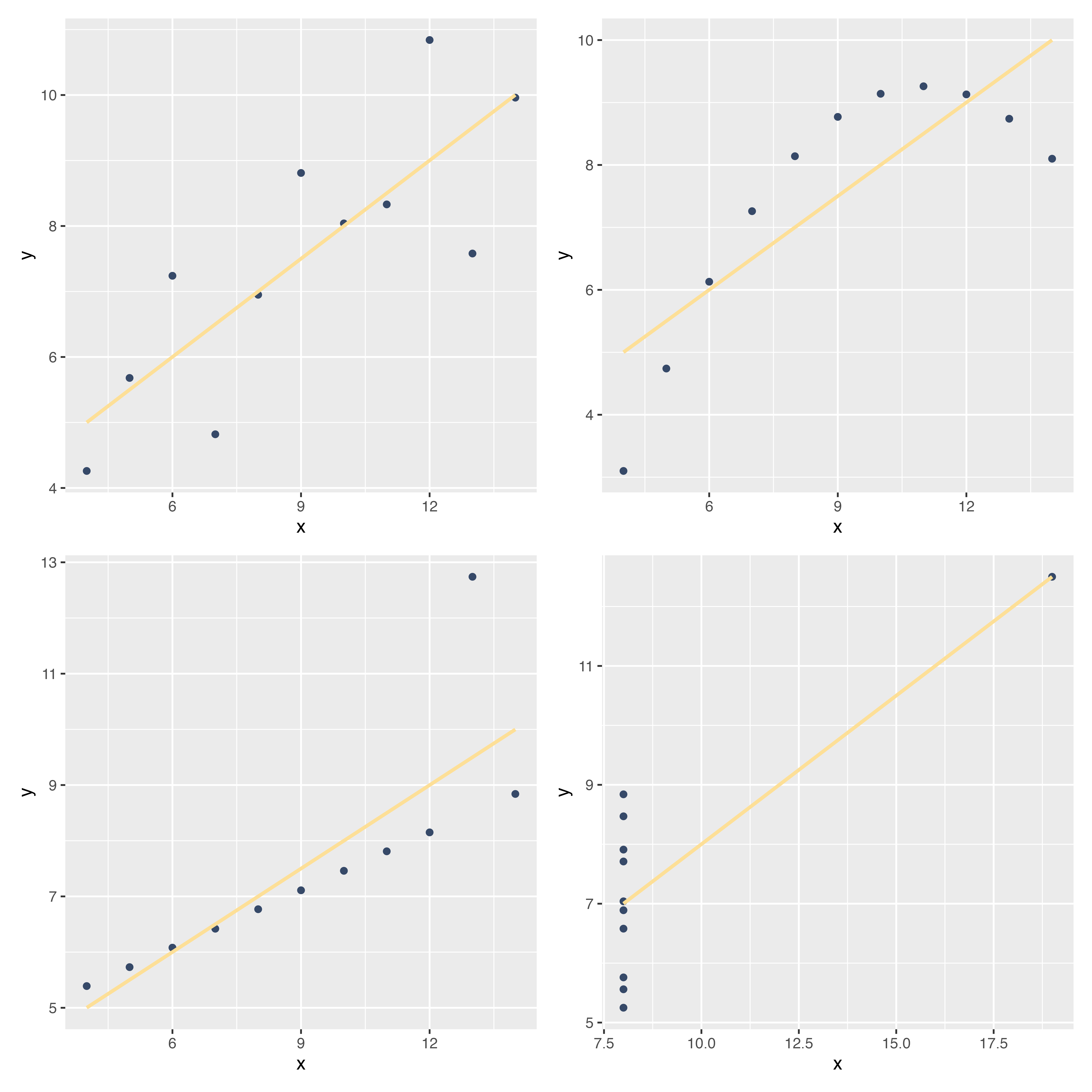
ここで,散布図から視覚的にわかることとして,右肩上がりだと正の関係(片方が高いともう片方も高い),右肩下がりだと負の関係,バラバラに散らばっていると関係がなさそう,ということ。
Code
set.seed(123)
x_p <- rnorm(100,10,10)
y_p <- x_p + rnorm(100,10,5)
x <- rnorm(100,10,10)
y <- rnorm(100,10,10)
x_n <- rnorm(100,10,10)
y_n <- -x_n - rnorm(100,10,5)
Code
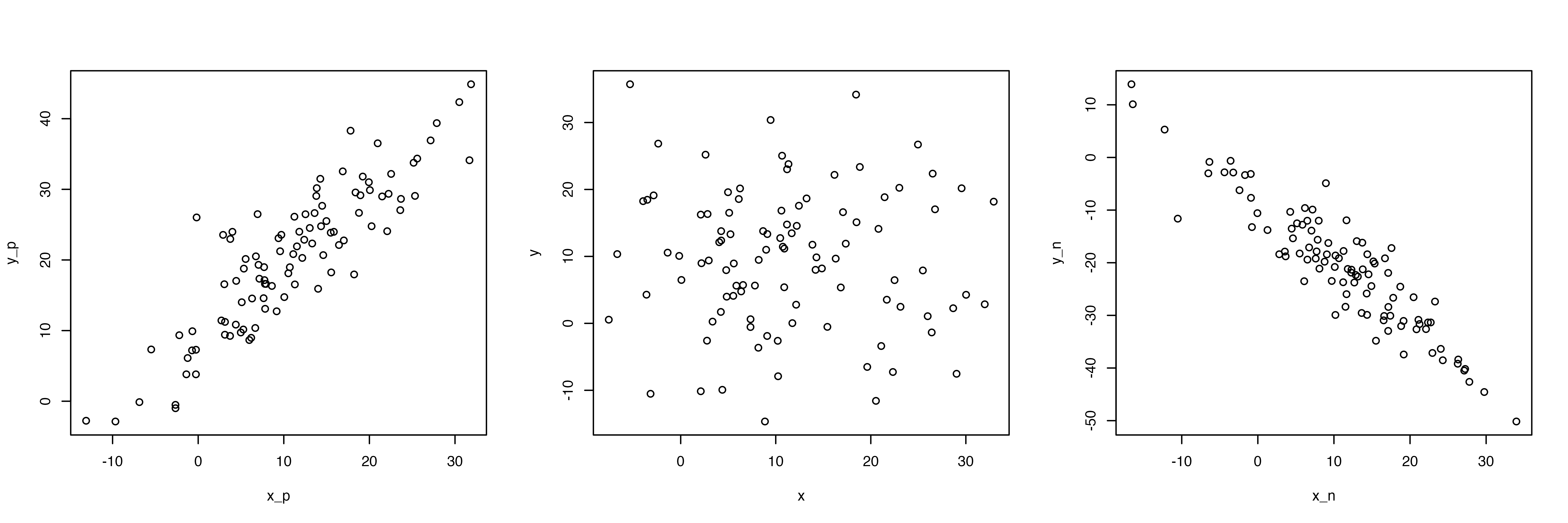
par(mfrow=c(1,3))
plot(x_p,y_p)
plot(x,y)
plot(x_n,y_n)
左は正の関係(xが増えるとyも増える),真ん中は関係なし(xとyに特段の関係が見て取れない),右は負の関係(xが増えるとyが減る)
共分散と相関係数
共分散
2変数の関係を数値で表すのが共分散と相関係数です。共分散は以下のように計算されます。
\[
Cov_{xy}=\frac{1}{n}\Sigma^n_{i=1}\left( x_i - \bar{x}\right)\left( y_i - \bar{y}\right)
\]
- 変数xの値から平均値をひく\(\left( x_i - \bar{x}\right)\)。yも同様\(\left( y_i - \bar{y}\right)\)
- 両者を掛け合わせる\(\left( x_i - \bar{x}\right)\left( y_i - \bar{y}\right)\)
- これをデータ1からnまで順番にやって全てを足し合わせる\(\Sigma^n_{i=1}\left( x_i - \bar{x}\right)\left( y_i - \bar{y}\right)\)
- データのサイズnで割る
Rでは,cov()関数で計算できます
値が大きいほど関係が強い。ただし,データの単位に依存するので,どれぐらい数字が大きかったら関係が強いと言えるのかはわからない。
相関係数
そこで,共分散を各変数の標準偏差の積で割って単位に依存しない基準を作る。これを相関係数という
\[
r = \frac{Cov_{xy}}{SD_xSD_y} = \frac{Cov_{xy}}{\sqrt{\frac{1}{n}\Sigma^n_{i=1}\left( x_i - \bar{x}\right)^2}\sqrt{\frac{1}{n}\Sigma^n_{i=1}\left( y_i - \bar{y}\right)^2}}
\]
相関係数rは,-1以上1以下の数値をとります。関係が強いほど-1もしくは1に近くなります。
これで,散布図で見た関係性の違いを数値で表すことができました。
Code
cov(x,y)/(sqrt(var(x))*sqrt(var(y)))
相関係数(correlation)は,cor()関数でできます。先ほどの3つの例の相関係数はそれぞれ以下の通り
Code
a<-ggplot(mapping = aes(x_p, y_p)) + #グラフを作成
geom_point() + #書く数値を点(point)で書く
theme(aspect.ratio = 1)
b<-ggplot(mapping = aes(x, y)) + #グラフを作成
geom_point() + #書く数値を点(point)で書く
theme(aspect.ratio = 1)
c<-ggplot(mapping = aes(x_n, y_n)) + #グラフを作成
geom_point() + #書く数値を点(point)で書く
theme(aspect.ratio = 1)
plot_grid(a, b, c, nrow = 1)
相関行列
複数の変数のペア毎の相関係数を行列形式で表示するもの。
Code
tibble(x_p, y_p, x, y, x_n, y_n) |>
datasummary_correlation()
- 1
-
先程まで使っていたデータを一つに繋げて
tibble形式にして
- 2
-
コマンド
datasummary_correlation()で相関行列を出力(modelsummaryパッケージの一部)
| |
x_p |
y_p |
x |
y |
x_n |
y_n |
| x_p |
1 |
. |
. |
. |
. |
. |
| y_p |
.88 |
1 |
. |
. |
. |
. |
| x |
-.13 |
-.10 |
1 |
. |
. |
. |
| y |
-.04 |
-.02 |
-.04 |
1 |
. |
. |
| x_n |
-.19 |
-.24 |
-.02 |
-.02 |
1 |
. |
| y_n |
.18 |
.20 |
.01 |
.05 |
-.92 |
1 |
質的変数同士の関係
クロス集計表
質的変数は,相関係数を算出できないし散布図もかけない。
そこでクロス集計表という表を使ってまとめられることが多い。
例えば,iceには,天気 (tenki),と週末かどうか (weekend)という変数が入っています。これらの関係を見るにはそれぞれを行と列にした表が役立ちます。
Code
ice %$%
table(weekend,tenki)
tenki
weekend 晴れ 曇り 雨
0 6 1 3
1 1 2 1
これをクロス集計表と言います。
例えば,平日 (weekend = 0)で晴れは6日,休日 (weekend = 1)で雨は1日です。
もう少し見やすい表は,summarytoolsパッケージのctableコマンドで作成可能です。
Code
ice %$%
ctable(weekend, tenki,
style = 'rmarkdown',
display.labels = FALSE,
headings = FALSE)
|
tenki |
晴れ |
曇り |
雨 |
Total |
| weekend |
|
|
|
|
|
| 0 |
|
6 (60.0%) |
1 (10.0%) |
3 (30.0%) |
10 (100.0%) |
| 1 |
|
1 (25.0%) |
2 (50.0%) |
1 (25.0%) |
4 (100.0%) |
| Total |
|
7 (50.0%) |
3 (21.4%) |
4 (28.6%) |
14 (100.0%) |
%は行ごとの割合を示しています。例えば平日の晴れは60%で,休日の晴れは25%です。
質的変数と量的変数の関係
質的変数と量的変数の関係は一部すでに前回やっています。
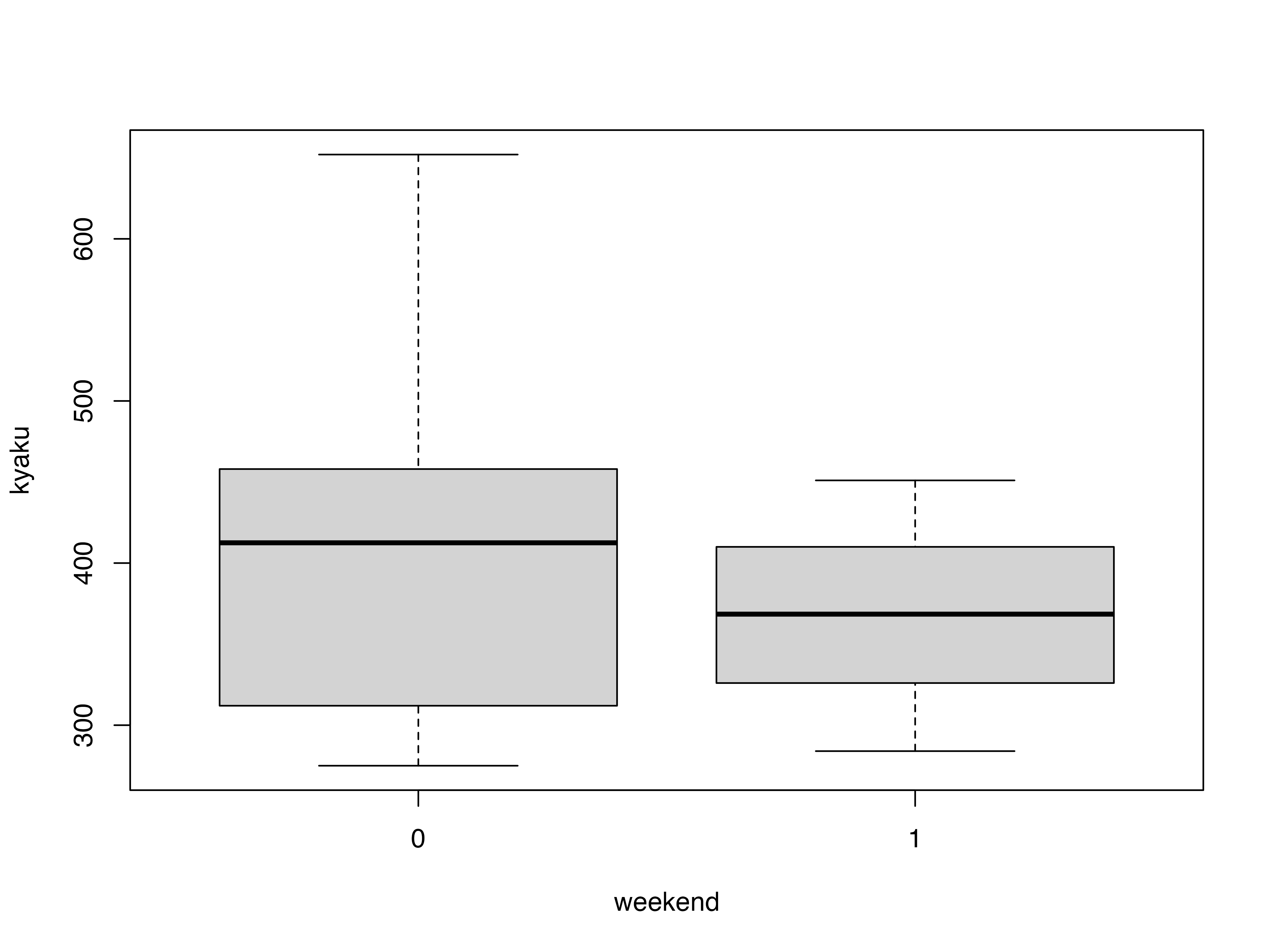
例えば平日と休日の客数平均,標準偏差,最大値,最小値を分けて
Code
datasummary(kyaku ~ weekend * (mean + sd + max + min),
data = ice)
| |
0 |
1 |
| |
mean |
sd |
max |
min |
mean |
sd |
max |
min |
| kyaku |
412.20 |
116.47 |
652.00 |
275.00 |
368.00 |
68.18 |
451.00 |
284.00 |
平日と休日で分けた箱ひげ図も
Code
ice %$%
boxplot(kyaku ~ weekend)
回帰直線
以下は,気温と客数の散布図(再掲)です。
この変数間の関係を直線関係
\[
客数 = a + b \times気温
\]
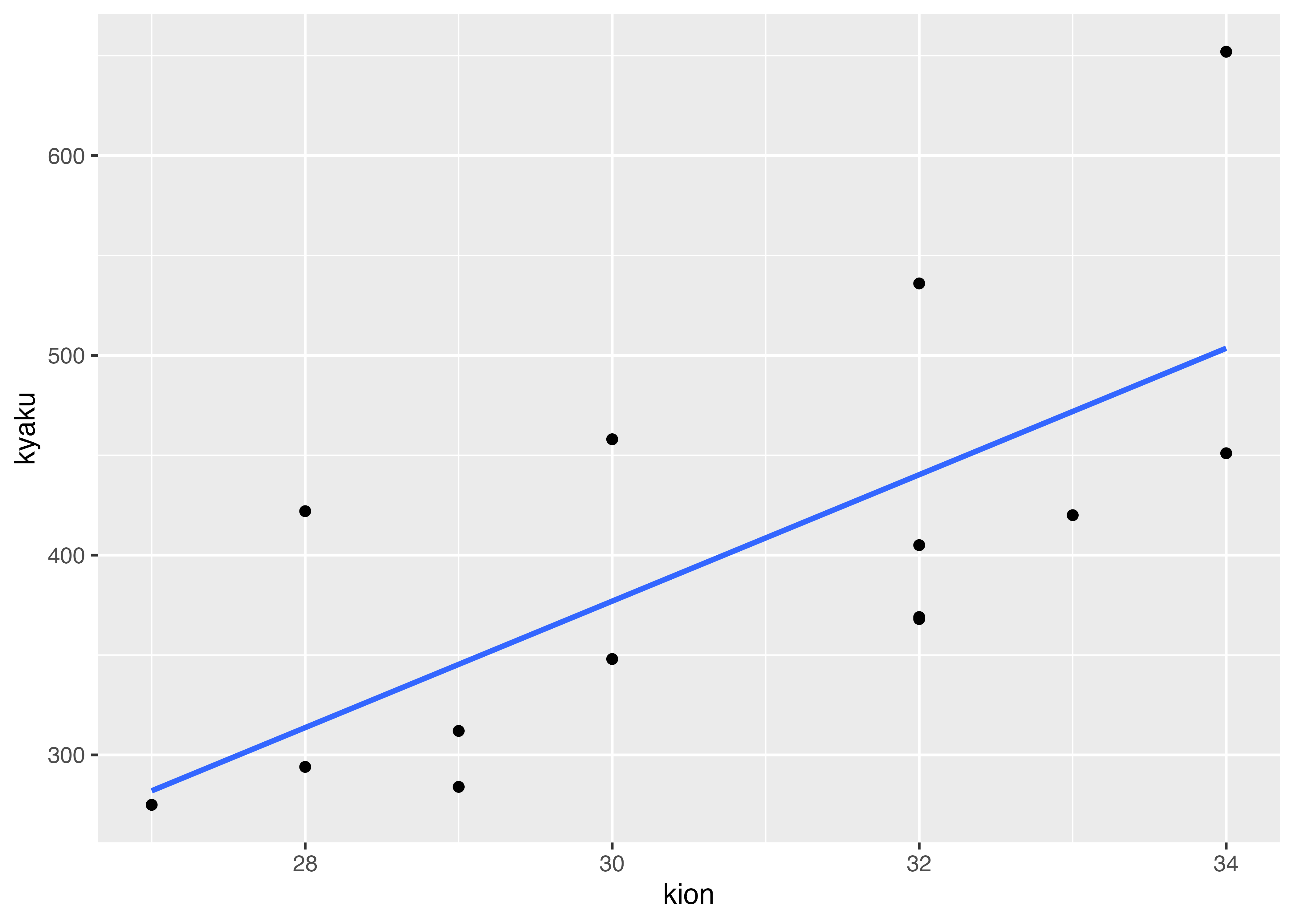
を当てはめることを考えます。この当てはめかたとして,最もよく使われるのが最小二乗法で,それによって求められた直線を回帰直線と言います。
計算方法等詳しくは第8回でお話ししますが,このデータを使って推定すると
\[
客数 = -572.52 + 31.65気温
\]
と求まります。
傾き31.65は,気温が1度上がった時に客数が31.65人増えるということを意味しています。
ただし,回帰分析は,時に真の関係とは違った線を引いてしまうことがあります。