15 まとめ
2024/07/20
1.1.1 この授業では
- まだわかっていない(新しい知識や情報が必要なこと)について
- 関連するすでに分かっていること(理論や過去の研究結果)を踏まえて予測を立て
- 検証に適したデータを取得して
- 適切な方法で分析することを通して
- 問いに対する答えを決める
のうち,4に関連する分析方法,特に定量的データを使った定量的分析の基礎と,Rを使った分析例を扱いました。(第2回はRの基礎)
.svg)
![]()
2.2 データの分類
2.2.1 定量的データ
- 実験データ
- アーカイバルデータ
- アンケートデータ1
- 定量的観察データ
2.2.2 定性的データ
- 定性的観察データ
- インタビューデータ

2.3 データの種類
データ(変数)はその性質に応じて分類が可能です。
- 観測値が数値となるような変数を量的変数,量的変数について計測されたデータを量的データと言います。
- 属性や項目,カテゴリなどを便宜的に数値データとしたようなものを質的変数,計測されたデータを質的データと言います。
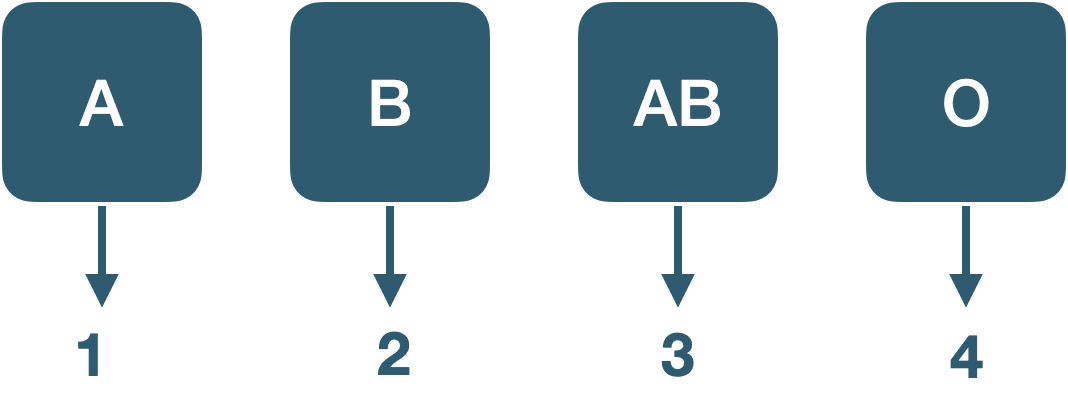
- 質的変数
-
「分類する」変数
数字の大小比較に意味がない
例:血液型
- 量的変数
-
数字そのものが意味を持っている
数字の大小比較に意味がある
例:身長

2.4 データの並び
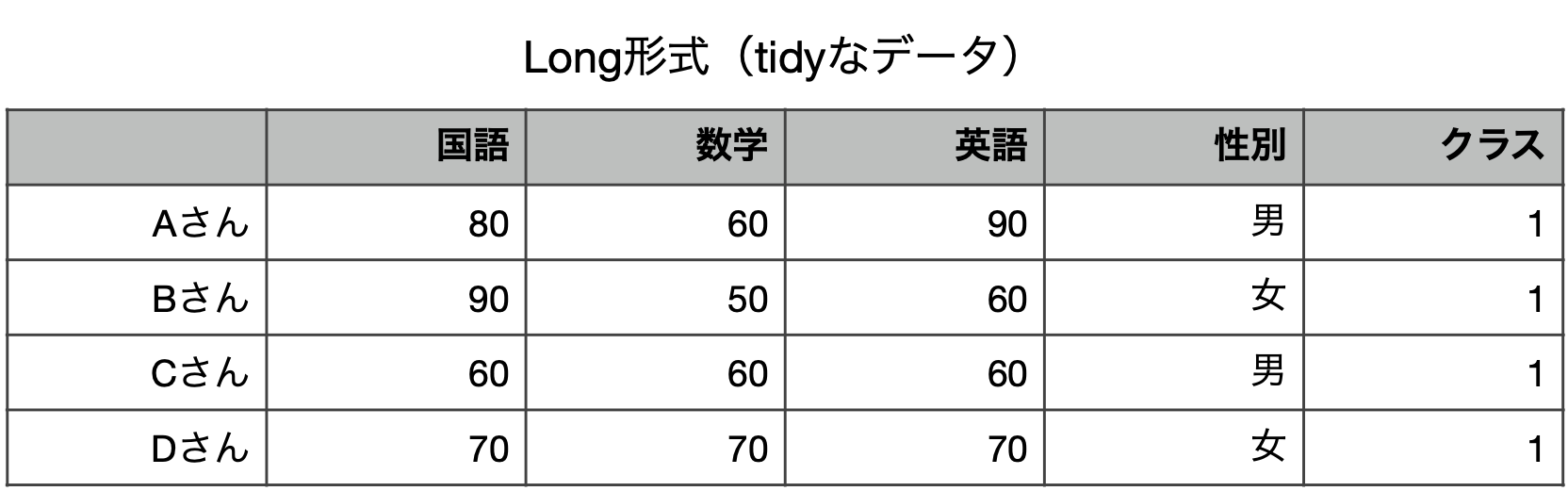
- 列が変数,行が測定単位になっている
- データ分析に望ましい形
3.2 グラフを使ったデータの要約
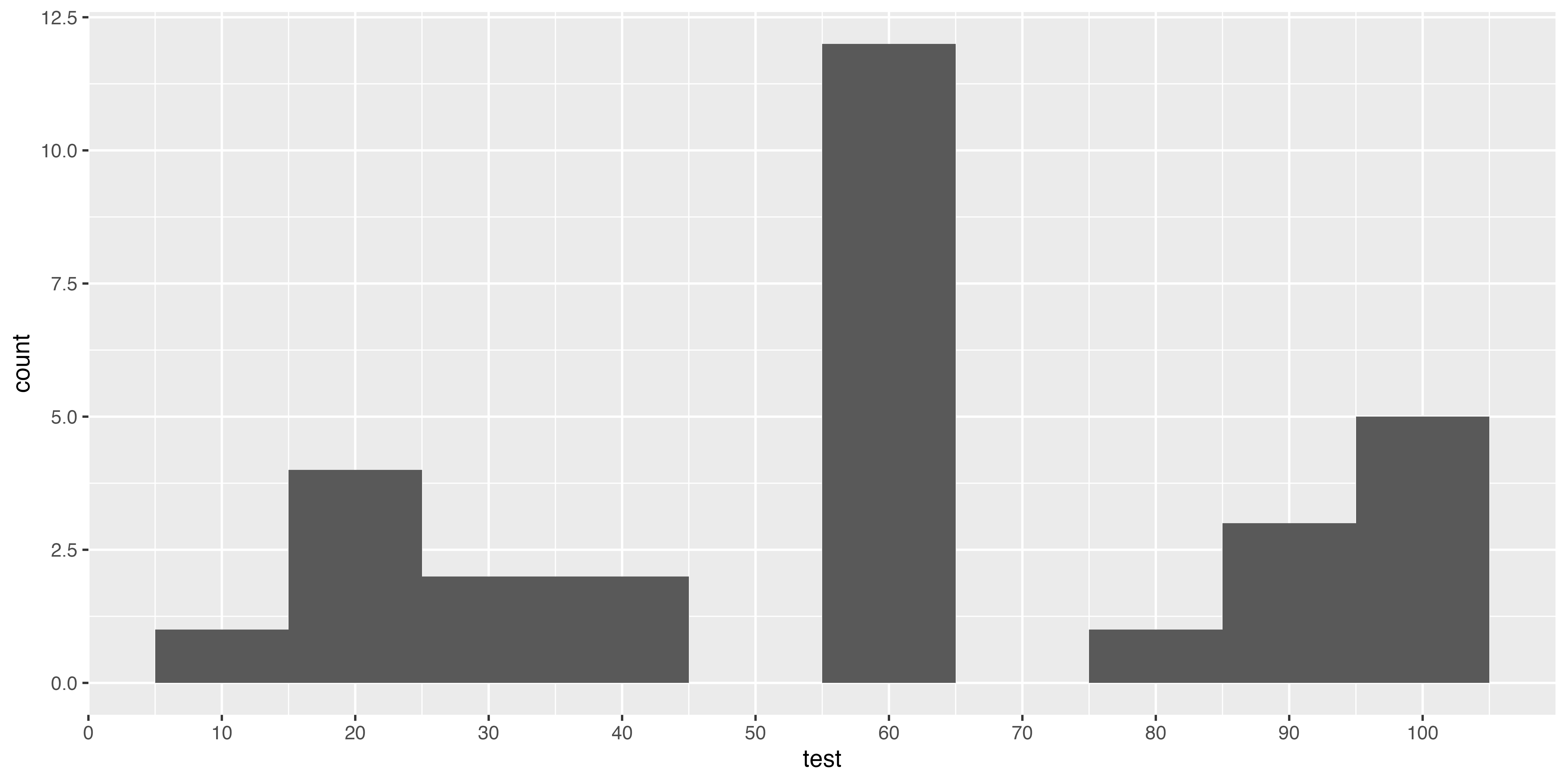
度数分布表
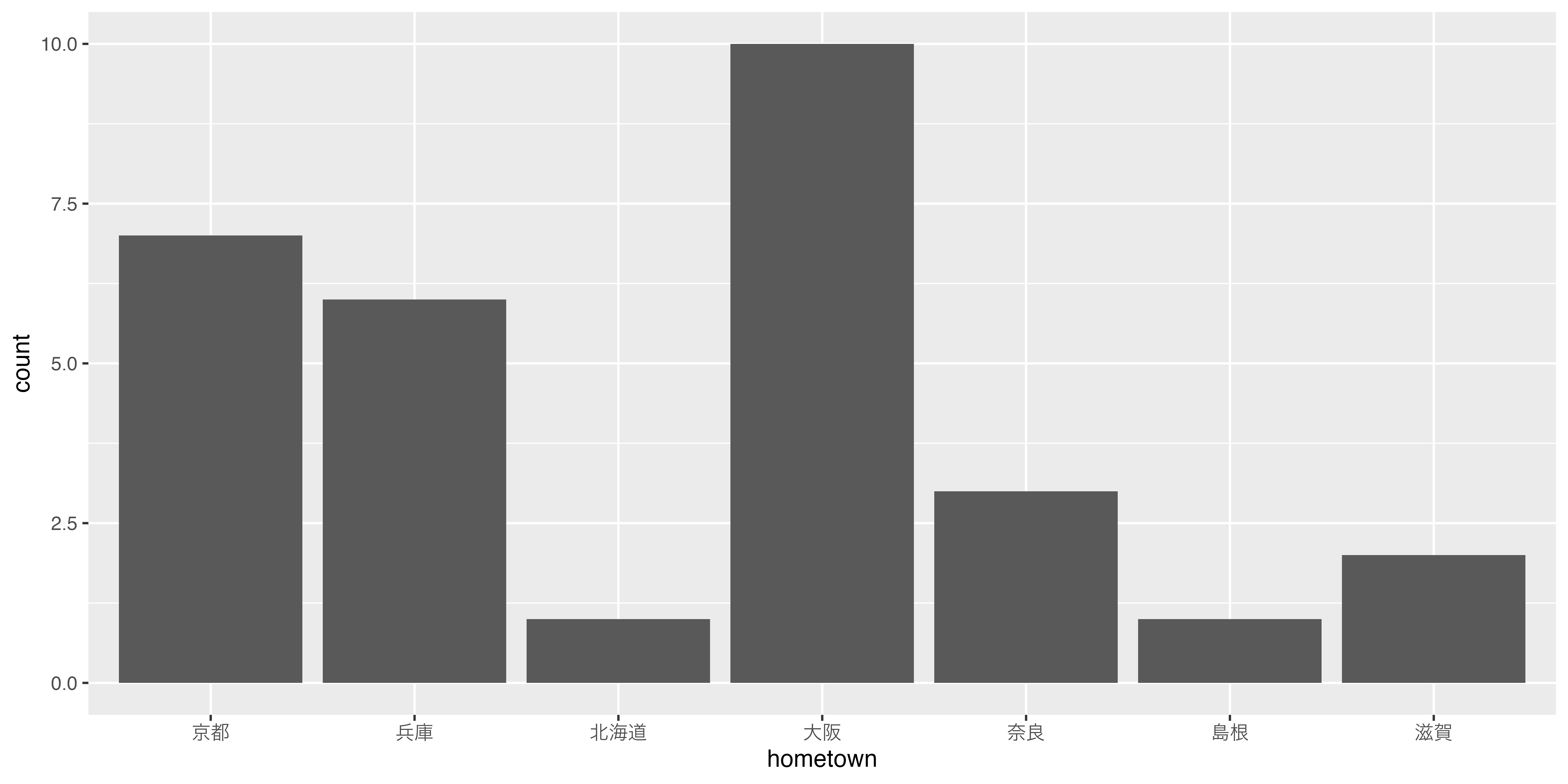
棒グラフ
4.1 量的変数同士の関係
4.1.1 散布図
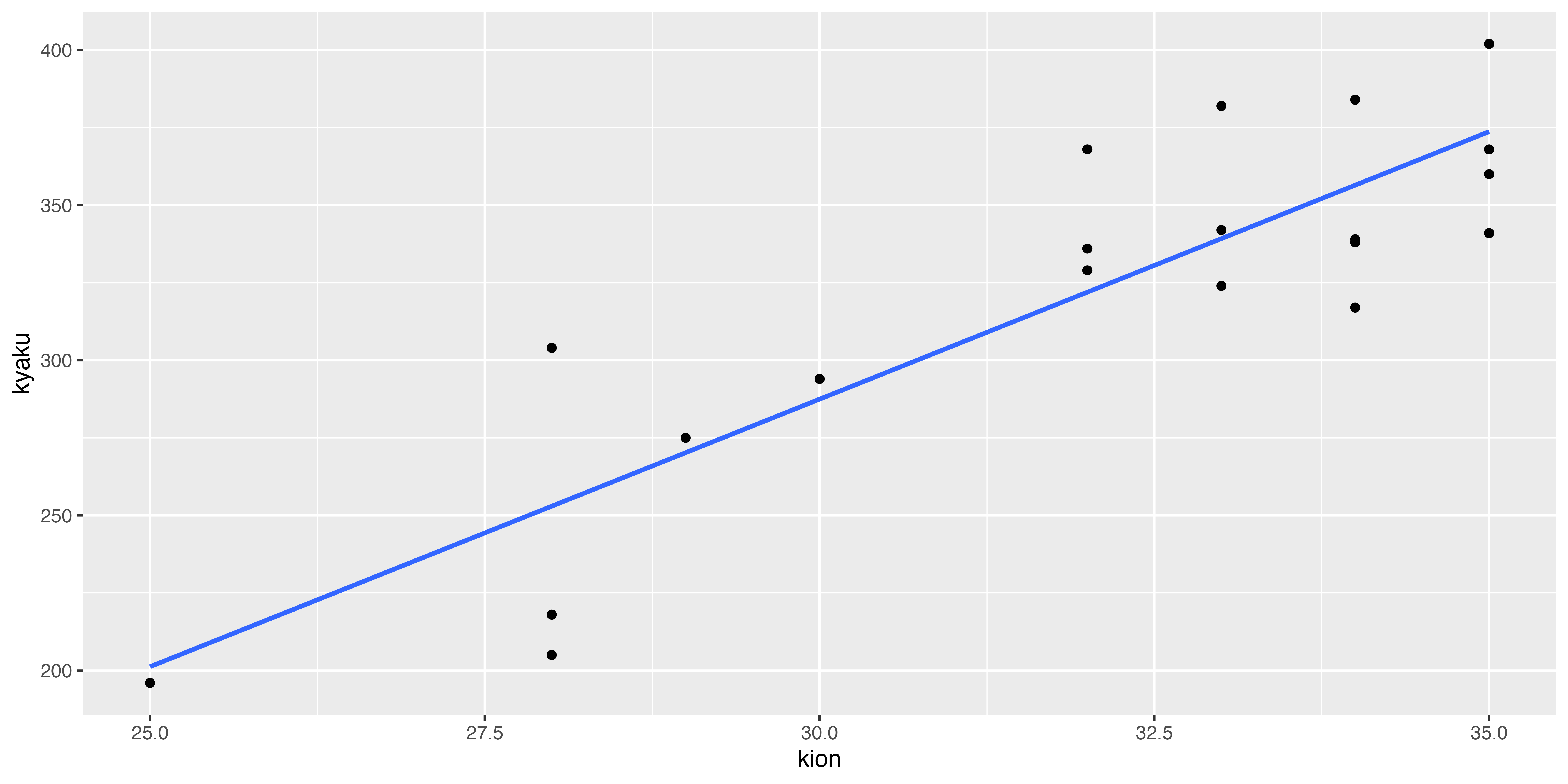
散布図から視覚的にわかることとして,右肩上がりだと正の関係(片方が高いともう片方も高い),右肩下がりだと負の関係,バラバラに散らばっていると関係がなさそう,ということ。
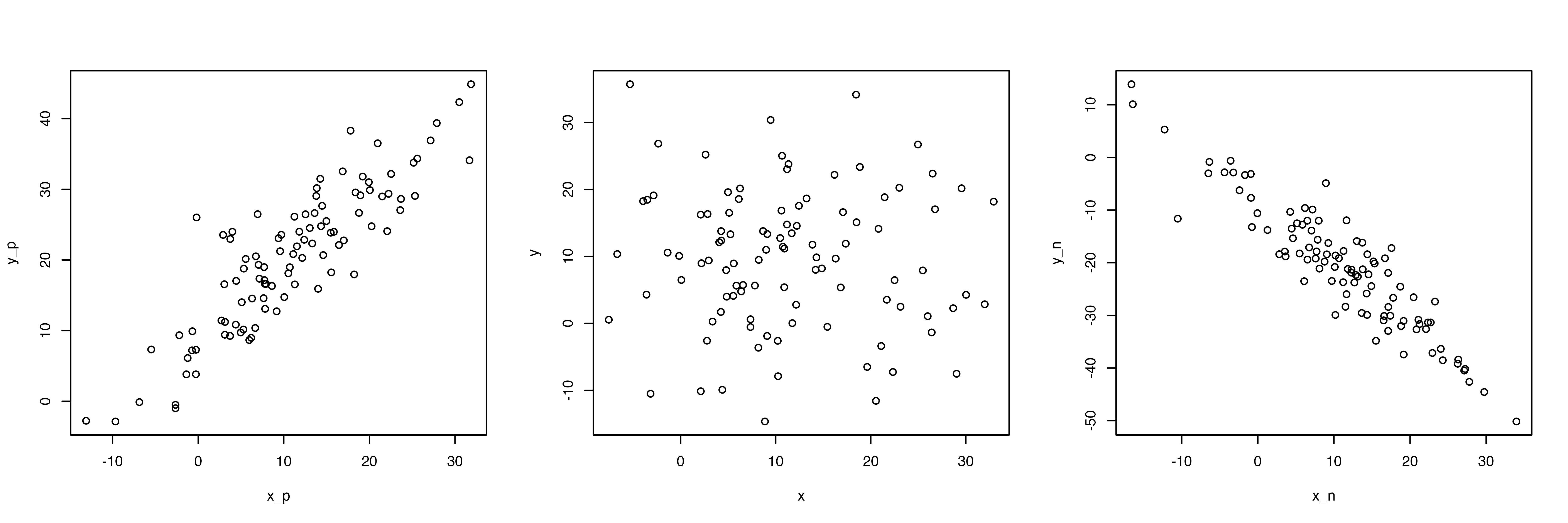
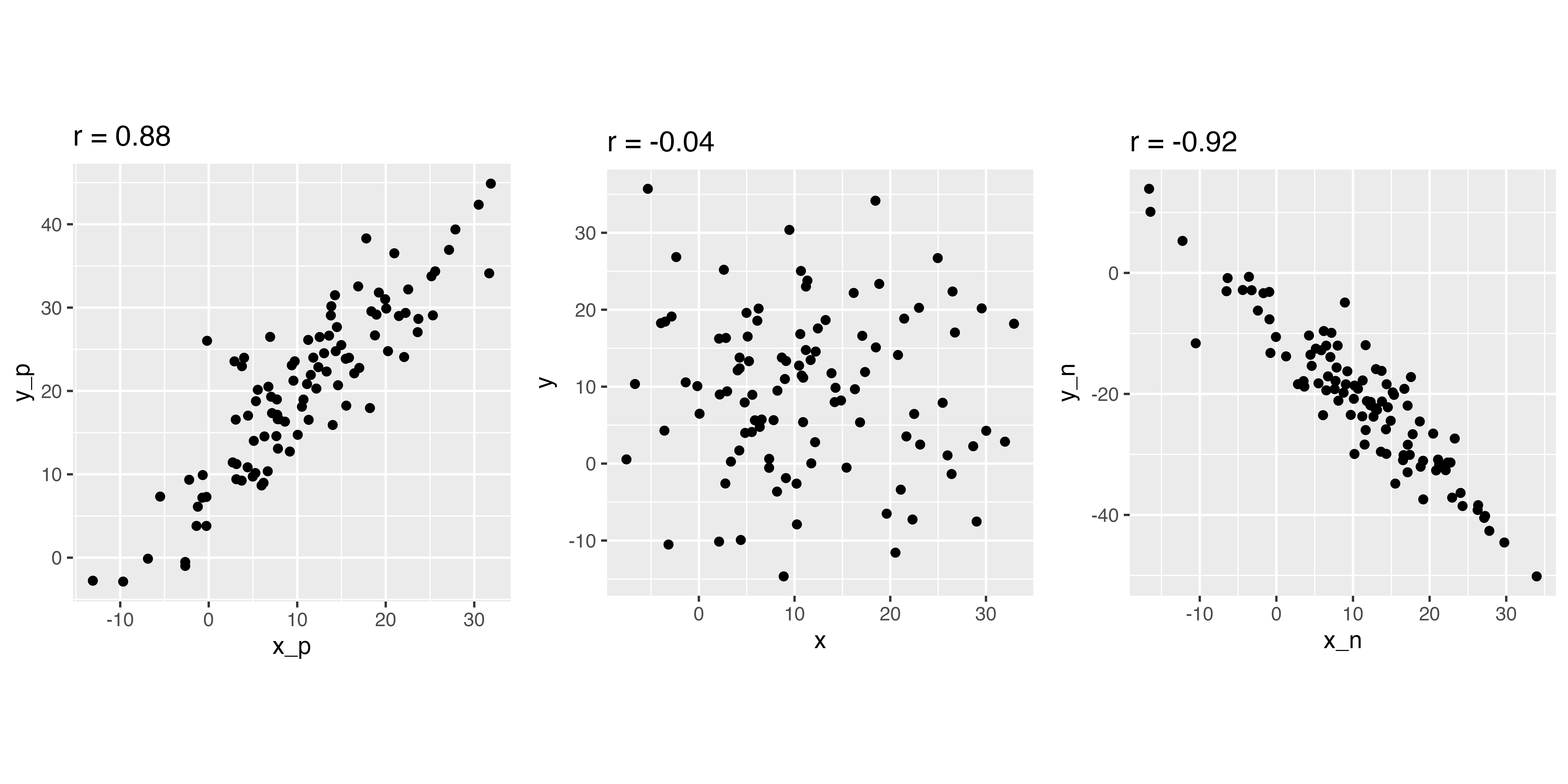
左は正の関係(xが増えるとyも増える),真ん中は関係なし(xとyに特段の関係が見て取れない),右は負の関係(xが増えるとyが減る)
4.2 相関係数
相関係数rは,-1以上1以下の数値をとる。関係が強いほど-1もしくは1に近く。
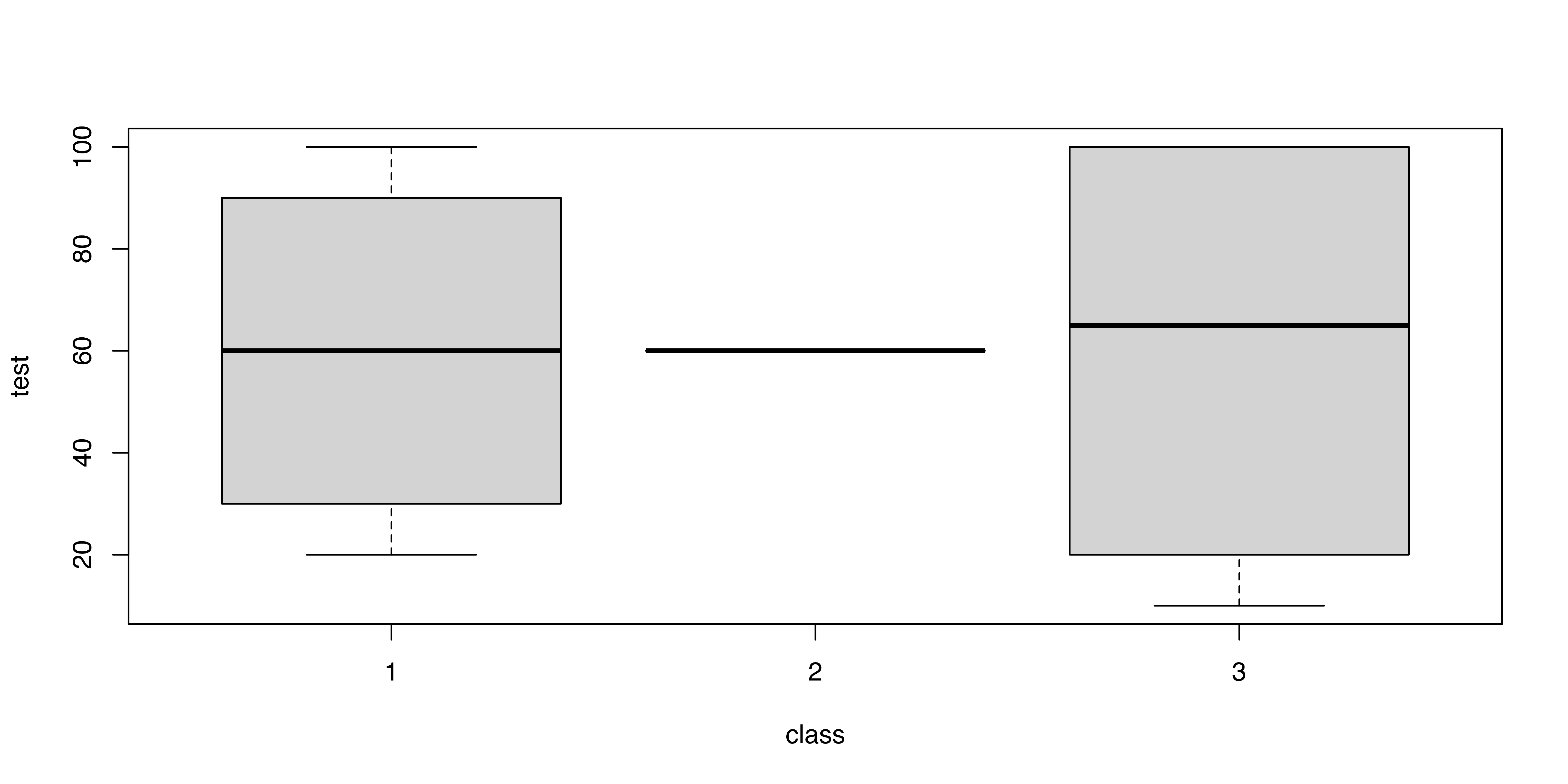
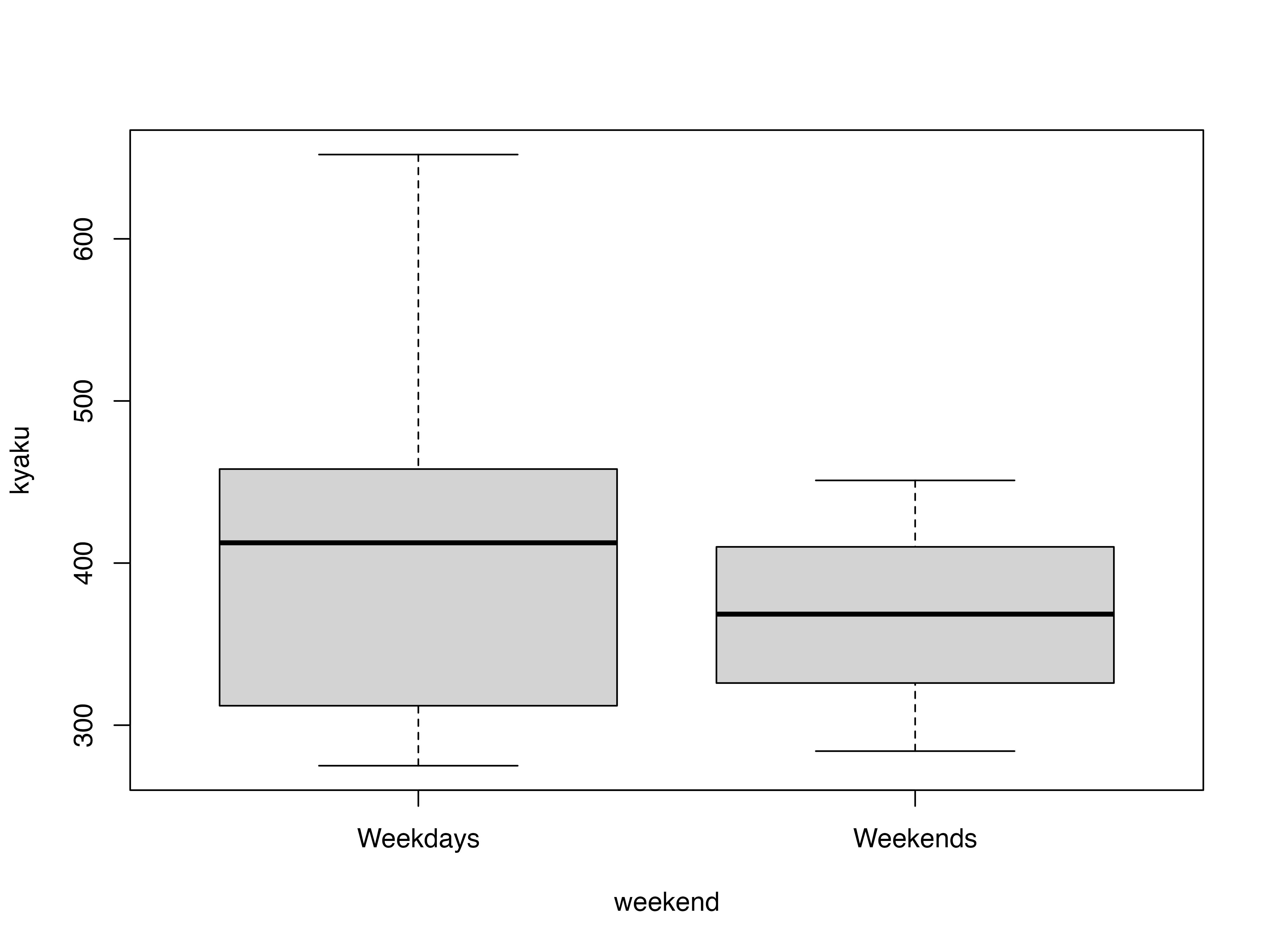
4.4 質的変数と量的変数の関係
質的変数ごとに分けた記述統計
| Weekdays | Weekends | |||||||
|---|---|---|---|---|---|---|---|---|
| mean | sd | max | min | mean | sd | max | min | |
| kyaku | 412.20 | 116.47 | 652.00 | 275.00 | 368.00 | 68.18 | 451.00 | 284.00 |
質的変数ごとに分けた箱ひげ図
5.1 母集団と標本
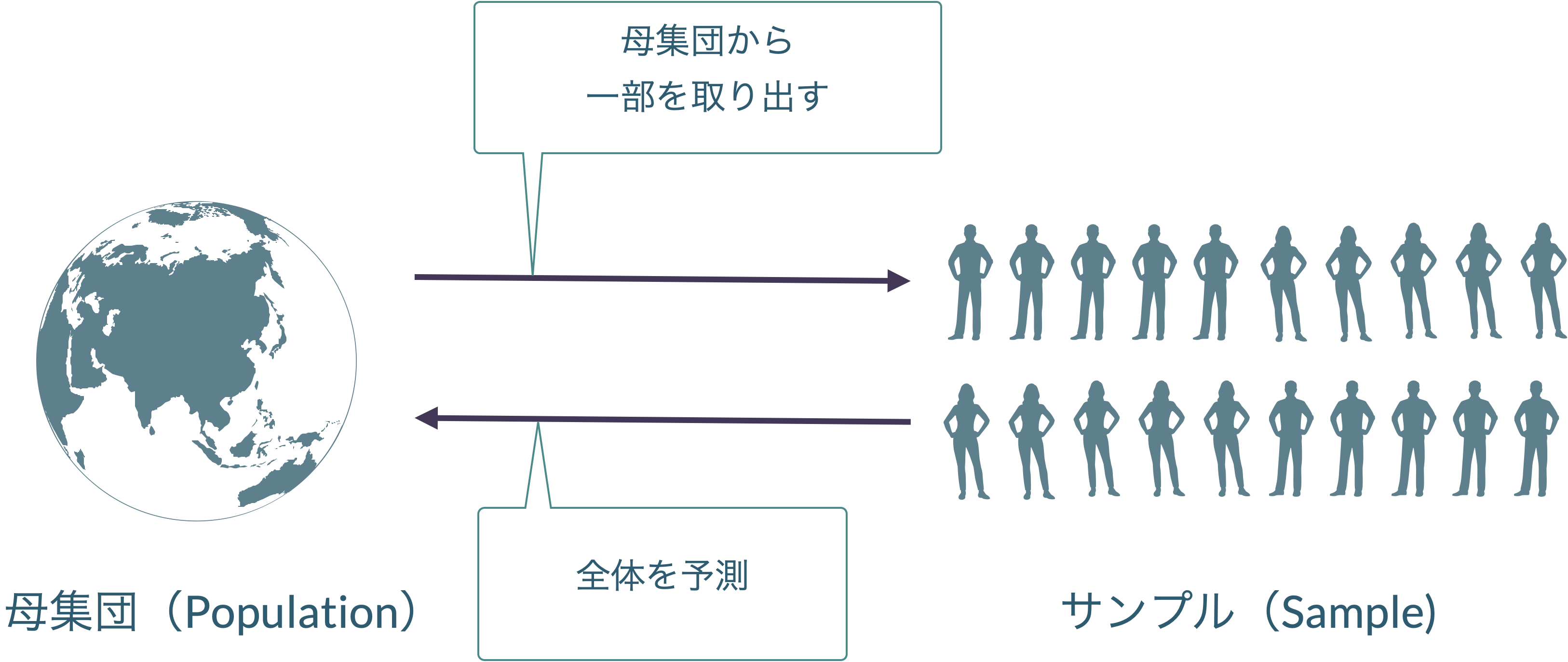
5.2 ランダムサンプリング(無作為抽出)
- 母集団に含まれる各個体が一様に等しい確率で選ばれているということ
- 無作為抽出もしくはランダムサンプリングという
- 無作為抽出によって選ばれた標本を無作為標本という
- 母集団から無作為に標本を集める(無作為抽出)
- 母集団がどんな分布でも,標本平均は不偏(不偏性)で,なおかつ正規分布に従う(中心極限定理)
- 正規分布に従うとわかると,標本平均がどれぐらいの信頼度で母集団を推定できているかを把握できる
無作為抽出という手順と,確率の性質を組み合わせて利用することで,未知の母集団を推測できる!

7.1 回帰分析
2つ以上の変数の関係を統計モデルの形で仮定し,パラメータを推定する
典型的には直線関係
\[ y_i = \beta_0 + \beta_1x_i+u_i \tag{1}\]
\(\beta_0\)は切片,\(\beta_1\)は傾き。\(u_i\)は誤差。個々の点と直線の乖離
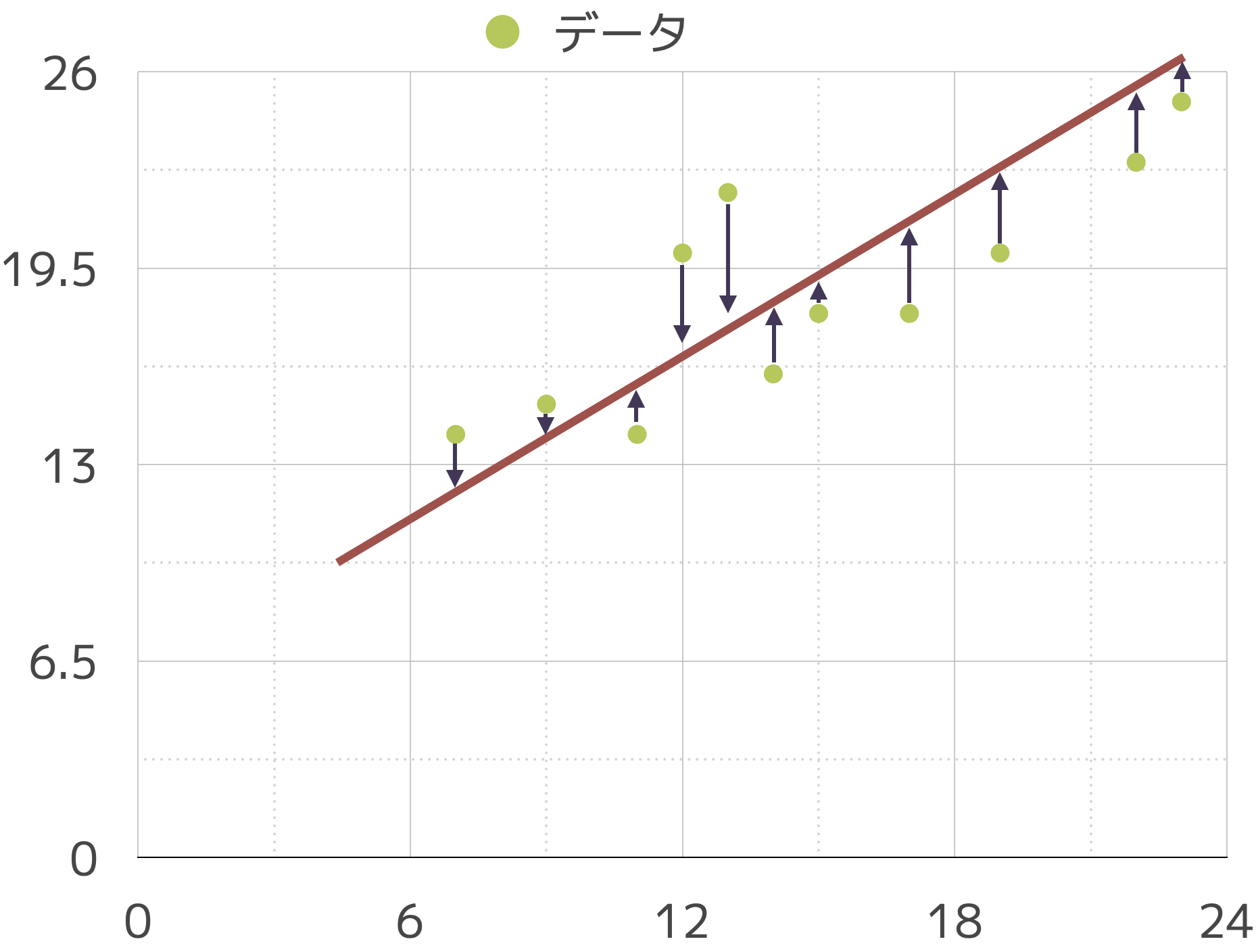
7.2 最小二乗法
回帰分析では,最小二乗法という方法で計算します。この方法の考え方は
直線と各データの誤差を最小にする線が最も良い線であろう
というものです。
これは,他の図で矢印になっている誤差を全部足したらしたらゼロになる点を探すことを意味します。±打ち消し合うので \(E(u)=0\) が理想です。
7.4 重回帰分析
複数の独立変数を一つの式に
\[ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + u \tag{2}\]
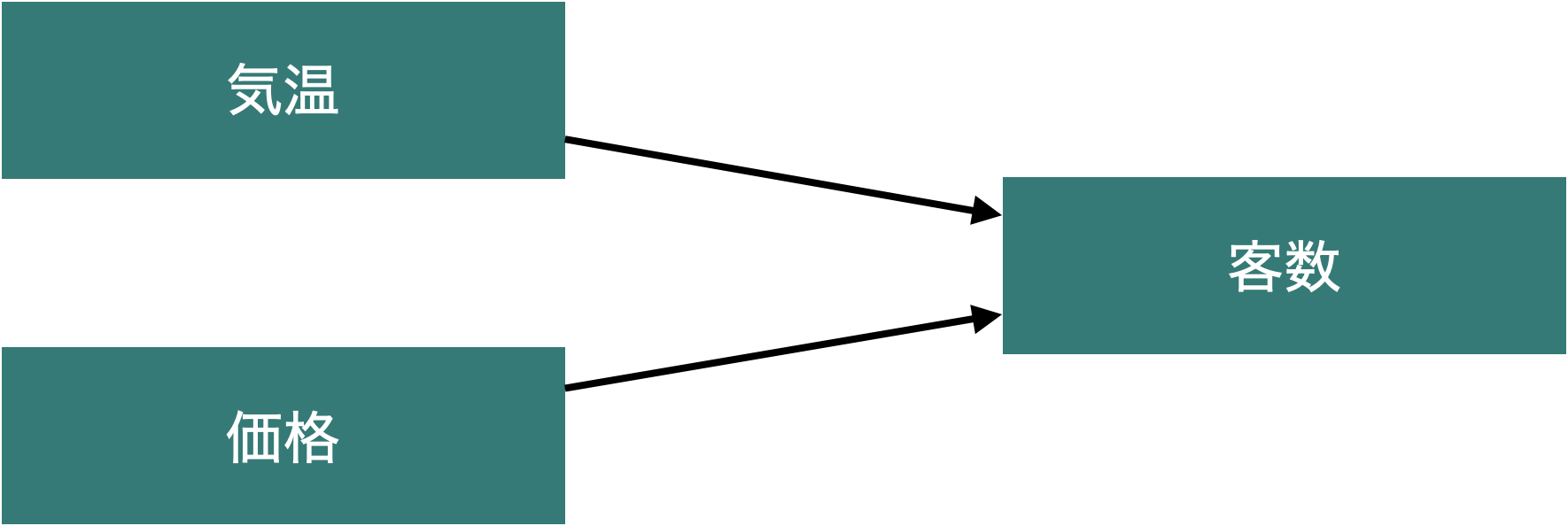
7.4.1 他の要因を一定とした場合の関係を推定できる
- 重回帰分析は,単回帰分析を複数行うこととは違い,「他の要因をコントロールした」係数を推定できる点が特徴です。
- その他の要因を一定としたとき,ある独立変数が従属変数とどのように関係しているかがわかる
- この「他の条件がすべて等しければ」はceteris paribusというラテン語で表記されたりします
- 上記の例の場合,価格の係数は「気温を一定としたとき,価格は客数とどのように関係しているか」が分かる
- その他の要因を一定としたとき,ある独立変数が従属変数とどのように関係しているかがわかる
8.1 相関≠因果関係
- xとyに相関関係がある,もしくは回帰分析によって統計的に有意な関係がある,ということは必ずしもxがyに影響を与えるという因果関係を表しているわけではない。
- 単なる相関
- 単なる偶然(擬似相関)
- 共通の要因がある(交絡)
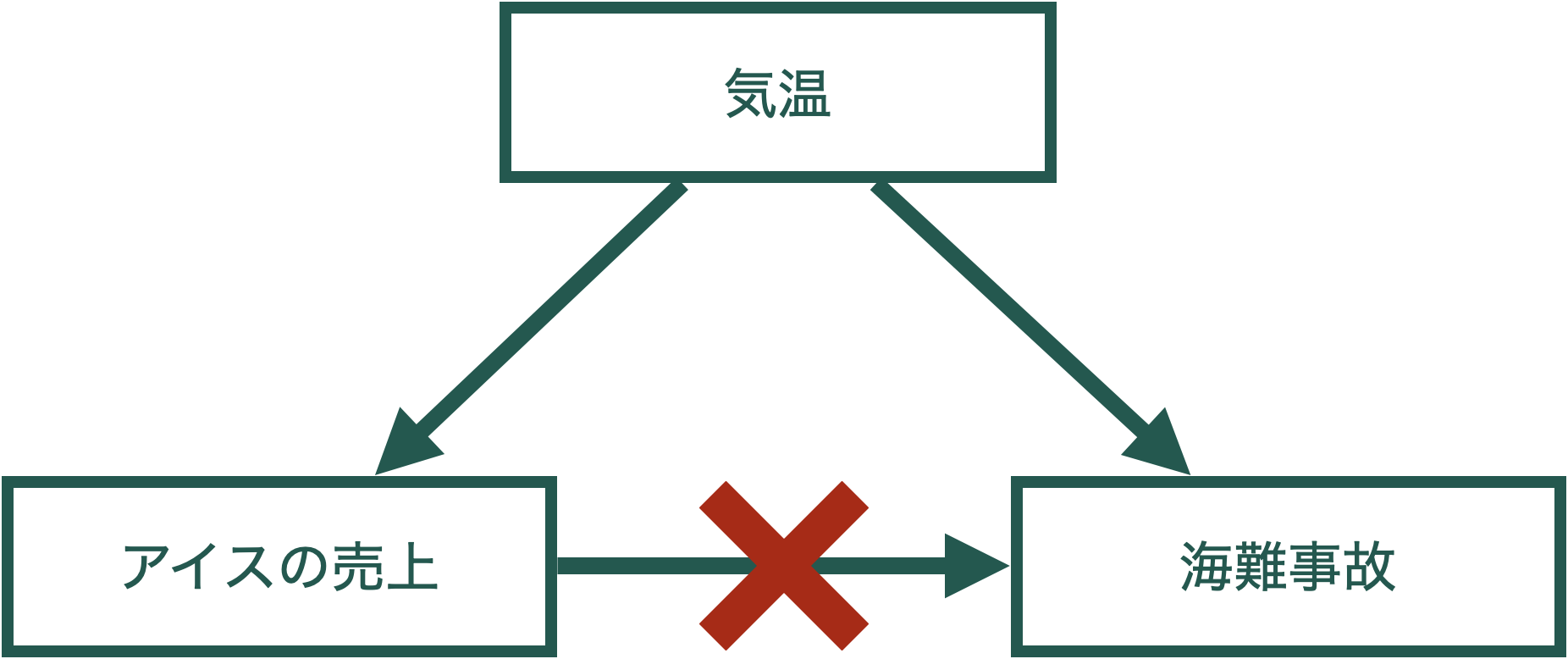
単に相関を計算したり,回帰分析をしただけではx → yという因果関係はわからない。
たくさんの参加者を集めて,その人たちにランダムに処置(投与するかしないか)を割り振る
- これによって個人個人の差は平均的に同じになる
- 症状が重い人軽い人,その他持病がある人ない人,性別などは確率的に均一になることが期待される
ランダムに割り振った集団間の比較をすることで薬の「平均的な」効果を推定することができる

つまり…
個人レベルで見ると因果関係はそもそも検証が不可能
集団レベルでランダムに処置を割り振ることで,平均的な効果の推定を通した因果関係が可能
9.1.1 ABテスト
アクセスしてくる人のうち一定割合に別のデザインの画面を表示し,クリックする先やクリック率等を比較する。(どちらのデザインの方が良いか?)



10.1 社会調査のプロセスと,この授業で扱ったこと
- まだわかっていない(新しい知識や情報が必要なこと)について
- 関連するすでに分かっていること(理論や過去の研究結果)を踏まえて予測を立て
- 検証に適したデータを取得して
- 適切な方法で分析することを通して
- 問いに対する答えを決める
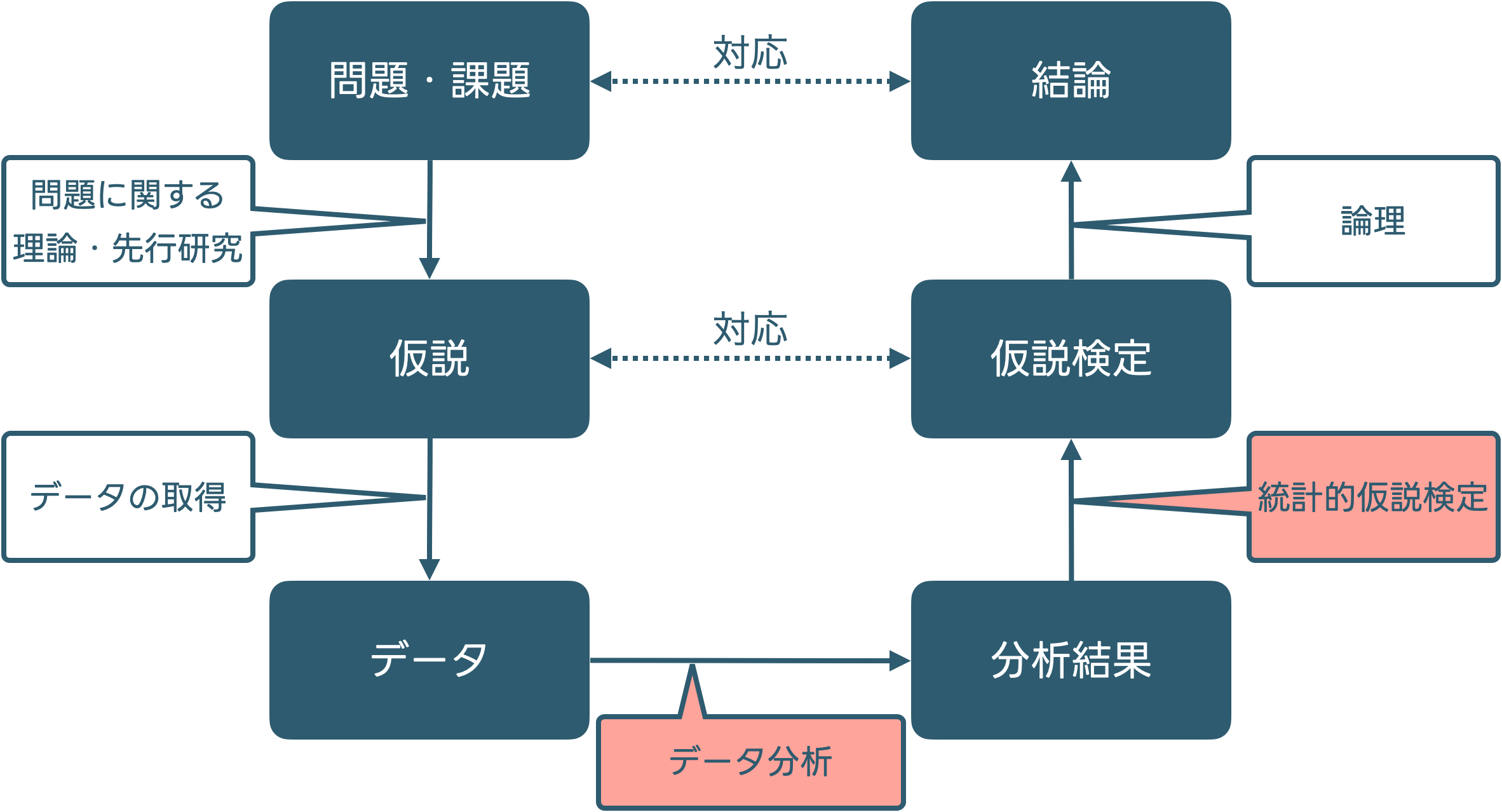
このプロセスは問題解決の最も効率的な方法?
- 卒論や社会調査だけの話ではない
- どんなデータがある?
- データの要約・図示
- 統計分析の背後の仕組み
- 母集団の情報を,限られたデータから予測したい
- 多変量解析
- 回帰分析とその応用
- 相関と因果関係
- 因果関係を予測する方法としての実験
この授業は
- 統計理論の授業(実際のデータ分析には触れない)
- 統計ソフトの使い方(理論はわからない)
の間あたり,理屈がわかって分析ツールを使えるようになることを目指して(ある種挑戦的に)授業を作ってみました。

この授業の内容を理解し,各回の分析手法を体験していただけていたら
- データって何?どんな種類があるの?
- 回帰分析って何やってるの?回帰分析の結果で議論される「統計的に有意」ってどんな意味?
といったことがわかった上で,Rでの簡単な分析方法を身につけていただけた(らいいなと思っています)
アンケート特有の分析手続き(因子分析など)など研究方法特殊的な一部の分析を除いて,卒論レベルで求められる知識や分析手法は一通り扱ったつもりです