Code
if (!require("pacman")) install.packages("pacman")
pacman::p_load(tidyverse, magrittr,
estimatr,car,modelsummary,
ggrepel,patchwork,psych, here)- 1
-
複数のパッケージを一度に読み込める
pacmanパッケージが入っていない場合は,インストールする - 2
- パッケージの読み込み
if (!require("pacman")) install.packages("pacman")
pacman::p_load(tidyverse, magrittr,
estimatr,car,modelsummary,
ggrepel,patchwork,psych, here)pacmanパッケージが入っていない場合は,インストールする
pacman複数のパッケージを読み込めるパッケージ。そのパッケージの中のp_loadコマンドを使うと,()内に指示したパッケージを読み込める。さらにそのパッケージがそもそもインストールされていない場合にはインストールした後に読み込んでくれる
tidyverseRのコードを楽にするたくさんのパッケージをパッケージにしたもの
magrittrtidyverseに含まれる%>%などのコードをさらに拡張するもの。これがあると%$%とか%<>%が使える
前回やった通り,統計的分析の良いところは少ないサンプルから全体を推定できることにあります。
特に,以下の性質を利用することで,母集団がどんなものなのかを推定できるということでした。
無作為抽出という手順と,確率の性質を組み合わせて利用することで,未知の母集団を推測できる!

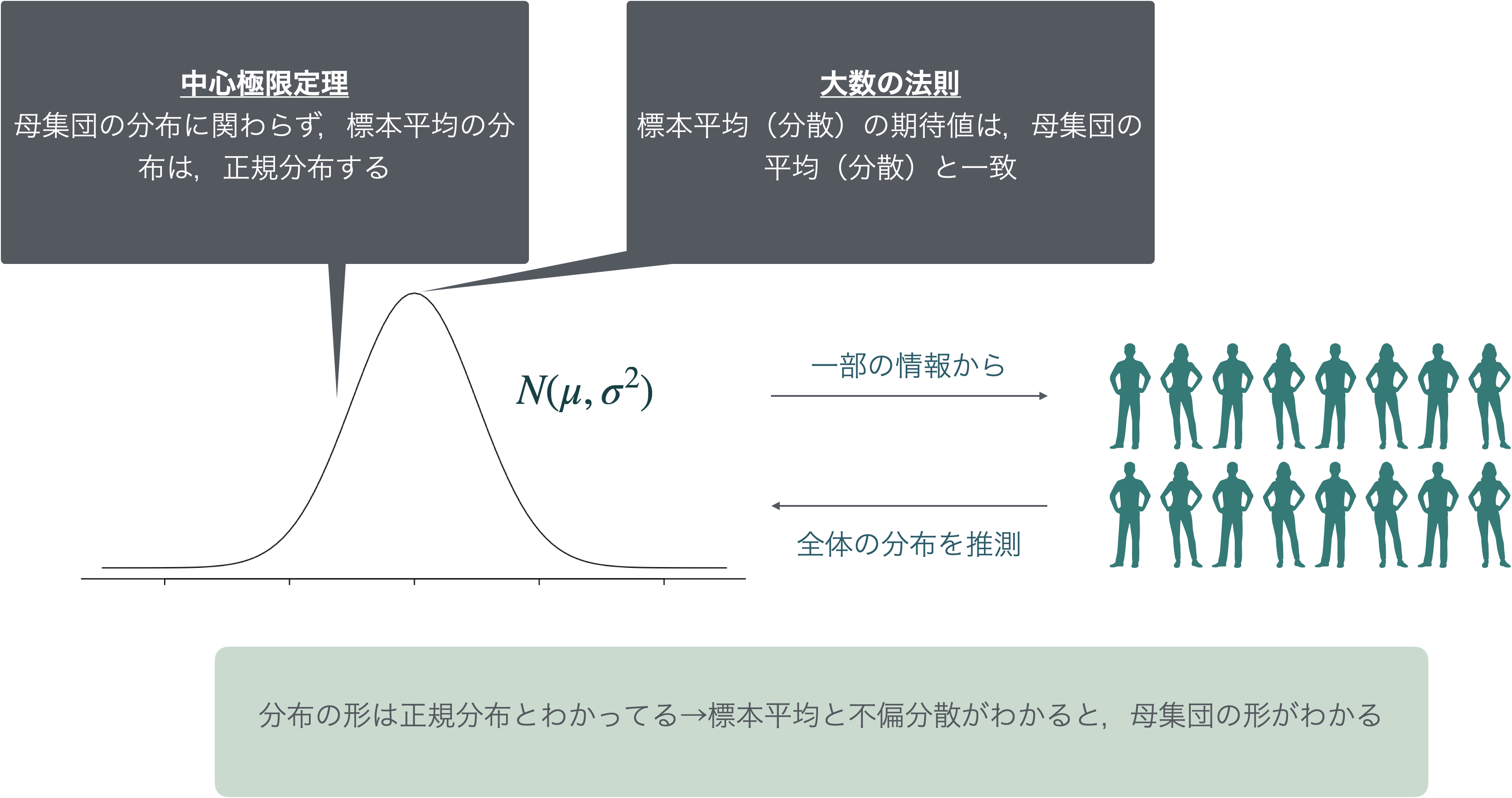
このように,データを元に母集団の形(特にそれを特徴づけるパラメータ\(\theta\))を推測することを統計的推測と言います。
統計的推測には,大きく分け二つ
推定を行い,検定をする,というイメージ
標本を用いて計算された母集団の推定結果について,どちらか一方を選ぶような形で推定結果を検証する手続きをとります。これを統計的仮説検定と言います。
考察の基準となる仮説
帰無仮説が棄却されたときに解釈される仮説
統計的仮説検定では,このような二つの仮説を立て,一方を選ぶような手続きを取ります。
統計的検定は,データに基づいて得られた検定統計量について,以下のような手続きで帰無仮説か対立仮説かを選びます
「有給取得率が高いほど純利益も大きい」のではないかと予測している
歪みのない1コインを投げた場合,表が出る確率は1/2です。今手元にあるコインが歪みのないものかどうかを検証するためには,「歪みがない」ことを仮説として持ちます。これを帰無仮説と言います。逆にこの仮説が否定されたもの「コインが歪んでいる」という仮説を対立仮説と言います。
これらの仮説を以下のプロセスで検討します。
p40 <- pbinom(q = 40, size = 100, prob = 0.5)
p60 <- pbinom(q = 60, size = 100, prob = 0.5)
p60 - p40[1] 0.9539559
この0.9539は,コインを100回投げて,60回から40回表が出る確率を表しています。95%以上の確率で60-40回表が出る,逆に65回は5%以下と解釈できます。事前に設定された有意水準5%を下回るので,帰無仮説は棄却され,対立仮説である\(H_1\)の\(p \ne \frac{1}{2}\)が採択されます。
母集団の分布が平均\(\mu\)標準偏差1と判明しているケースで,仮に平均が0かどうかを検定したいとします。以下のような手続きを取ります。
母集団の分布があらかじめわかっているということは基本的にはありません。しかし,母集団の分布がわからないという条件でも上のような検定が行える場合があります。
上記\(t_n\)をt値,これを用いた検定をt検定と言います。
前回課題で求めた54%から62%の範囲はこの95%信頼区間
母集団からのサンプリングを繰り返し行った場合,95%はこの範囲の中に入る。
95%真のパラメータがこの範囲の中に入っている。
特定の研究における95%信頼区間は,「95%の確率でestimand(母集団のパラメータ)がこの範囲の中に入る」ということを意味しているわけではない。
信頼区間は,頻度論的な解釈しか与えない。
三重大学奥村先生の説明が丁寧
(ハンバーガー統計学より引用)
ハンバーガー屋であるワクワクバーガーは自身のハンバーガーの味とモグモグのハンバーガーの味とで,評価が違っているのかを調べたい。
街頭試食アンケートとして,改札を通る人を10人ごとに1人選びだして調査を協力してもらいました。1人目にはワクワクのハンバーガーを食べてもらい100点満点で味の採点をしてもらいます。2人目は,モグモグのハンバーガーで同じようにしてもらいます。3人目はワクワクに戻ります。このようにして,それぞれのハンバーガーについて8人ずつのデータを取りました。
ham <- here('data', '8_ham1.csv') |>
read_csv()
hamsummary(ham) wak mog
Min. :70.00 Min. :70.00
1st Qu.:70.00 1st Qu.:78.75
Median :75.00 Median :80.00
Mean :76.88 Mean :81.88
3rd Qu.:81.25 3rd Qu.:86.25
Max. :90.00 Max. :95.00 describe(ham)わくわくバーガーの平均は76.875,もぐもぐバーガーの平均は81.875。これだけみたらもぐもぐバーガーの方が評価が高い。
ただし,これはあくまで町行く人からランダムに募った16名の意見から生じた差。この差は全体の差として意味があるかを検定したい。
以上の仮説をもとに,平均値の差の検定を行う。判断の基準はp値5%とする。ここで行う検定はt検定。コマンドはt.test()。
ham %$%
t.test(wak,mog)
Welch Two Sample t-test
data: wak and mog
t = -1.2881, df = 13.951, p-value = 0.2187
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-13.327988 3.327988
sample estimates:
mean of x mean of y
76.875 81.875 t値は,-1.2881,p値は0.2187。
帰無仮説が真の確率が,0.2187,つまり約22%。判断の基準である5%よりも大きいので,帰無仮説を採択する
なお,t.test()コマンドでは既定で95%信頼区間が出力される。これが
95 percent confidence interval:
-13.327988 3.327988として表示されている。95%あり得る区間の中に0が入っているので,差が0という可能性が否定できない。
ちなみに,もっと厳しい99%信頼区間を表示するには
ham %$%
t.test(wak,mog,
data = ham,
conf.level = .99)
Welch Two Sample t-test
data: wak and mog
t = -1.2881, df = 13.951, p-value = 0.2187
alternative hypothesis: true difference in means is not equal to 0
99 percent confidence interval:
-16.561187 6.561187
sample estimates:
mean of x mean of y
76.875 81.875 データice3_1.csvには,アイスクリーム屋さんの年齢(age)と今年の来店回数(raiten)が含まれています。このアイスクリーム屋さんは,「年齢層と来店頻度には関係があるのではないか」と考え,ポイントカード会員のデータから,20名の年齢と来店回数を集計しました。
ice3_1 <- here('data', '8_ice3.csv') |> read_csv()
ice3_1 |>
describe()%$%とか,%>%といったコード(パイプ演算子)は,前のコードをそのまま受ける時,次のコードの()内を(.)として省略できます
平均年齢は19.55,最小値13,最大値26
平均来店回数は5.70,最小2,最大8
ice3_1 %$%
cor(age,raiten)[1] 0.26652272つの変数の相関係数は0.266。正の相関だけど,大きいわけではない。
この相関は,20名というデータの中で生じたものだけど,母集団全体として正の相関があるのか,それともこの正の値は偶然生じたものなのか?
分析の際には,相関の検定を実行するcor.test()を行います。()の中には相関を検定したい2つの変数を入れます。
ice3_1 %$%
cor.test(age,raiten)
Pearson's product-moment correlation
data: age and raiten
t = 1.1732, df = 18, p-value = 0.256
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.1995311 0.6342401
sample estimates:
cor
0.2665227 この結果の一番下に,相関係数( 0.2665227)が書かれています。t値は1.17,また, p-value = 0.256が検定の結果算出された有意確率です。約26% > 5% なので,有意ではない。つまり,相関なしという帰無仮説を棄却できない(帰無仮説を採択)
高校数学でやりましたか?歪んだコインって見たことないですよね。↩︎