Code
# tidyverseの読み込み
pacman::p_load(tidyverse)
# 例に用いる二つのデータフレームを作成
A = tibble(firm_ID = c(1, 2),
stock_price = c(120, 500)) # 株価データが格納されたAを作成
B = tibble(firm_ID = c(1, 3),
DPS = c(5, 10)) # DPSデータが格納されたBを作成join系関数(教科書コラム5.2)dplyrにはfull_join()関数を始め,結合を行うために用いるjoin系関数が用意されている.AとDPSデータBの結合を通じて,それぞれのjoin系関数の返り値を確認していこう.# tidyverseの読み込み
pacman::p_load(tidyverse)
# 例に用いる二つのデータフレームを作成
A = tibble(firm_ID = c(1, 2),
stock_price = c(120, 500)) # 株価データが格納されたAを作成
B = tibble(firm_ID = c(1, 3),
DPS = c(5, 10)) # DPSデータが格納されたBを作成tibble()関数を使って二つのデータフレームを手動で作成している.full_join()関数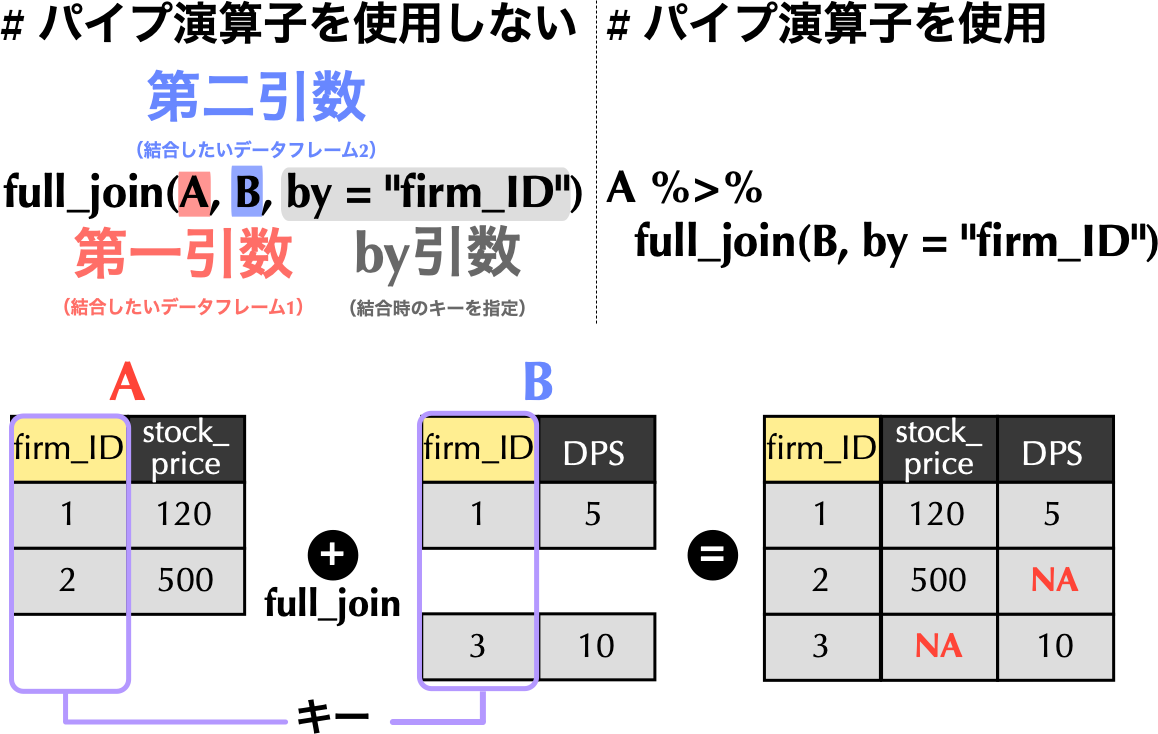
inner_join()関数# inner_join()関数による欠損値の処理
A %>% inner_join(B, by = "firm_ID") # A tibble: 1 × 3
firm_ID stock_price DPS
<dbl> <dbl> <dbl>
1 1 120 5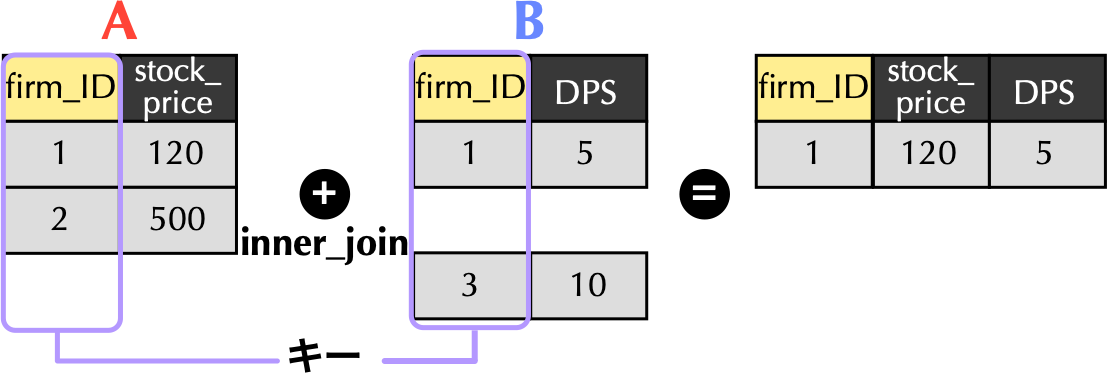
left_join()関数# left_join()関数による欠損値の処理
A %>% left_join(B, by = "firm_ID") # A tibble: 2 × 3
firm_ID stock_price DPS
<dbl> <dbl> <dbl>
1 1 120 5
2 2 500 NA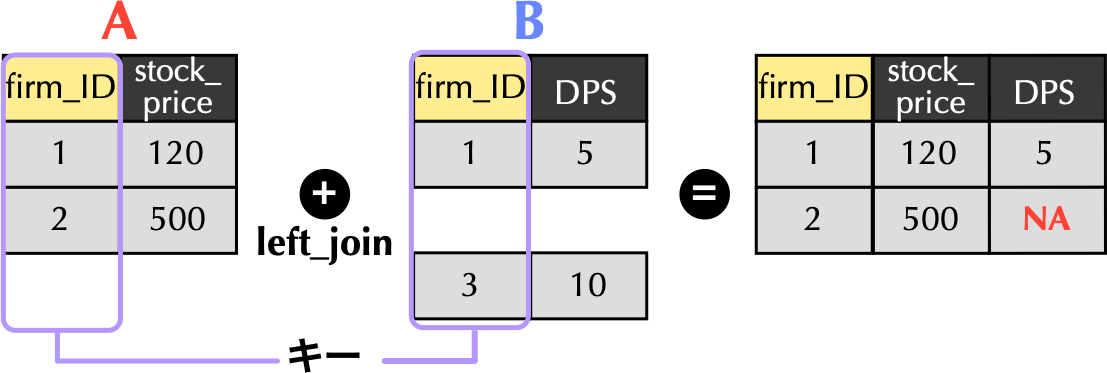
codesである場合,読み込みたいfinancial_data.csvが格納されているsimulation_dataフォルダにアクセスするには,一個上の階層に一度戻る必要があり,それは..により実現可能である.simulation_dataフォルダに移動 (/simulation_data)し,/financial_data.csvで目的のファイルにアクセス可能である.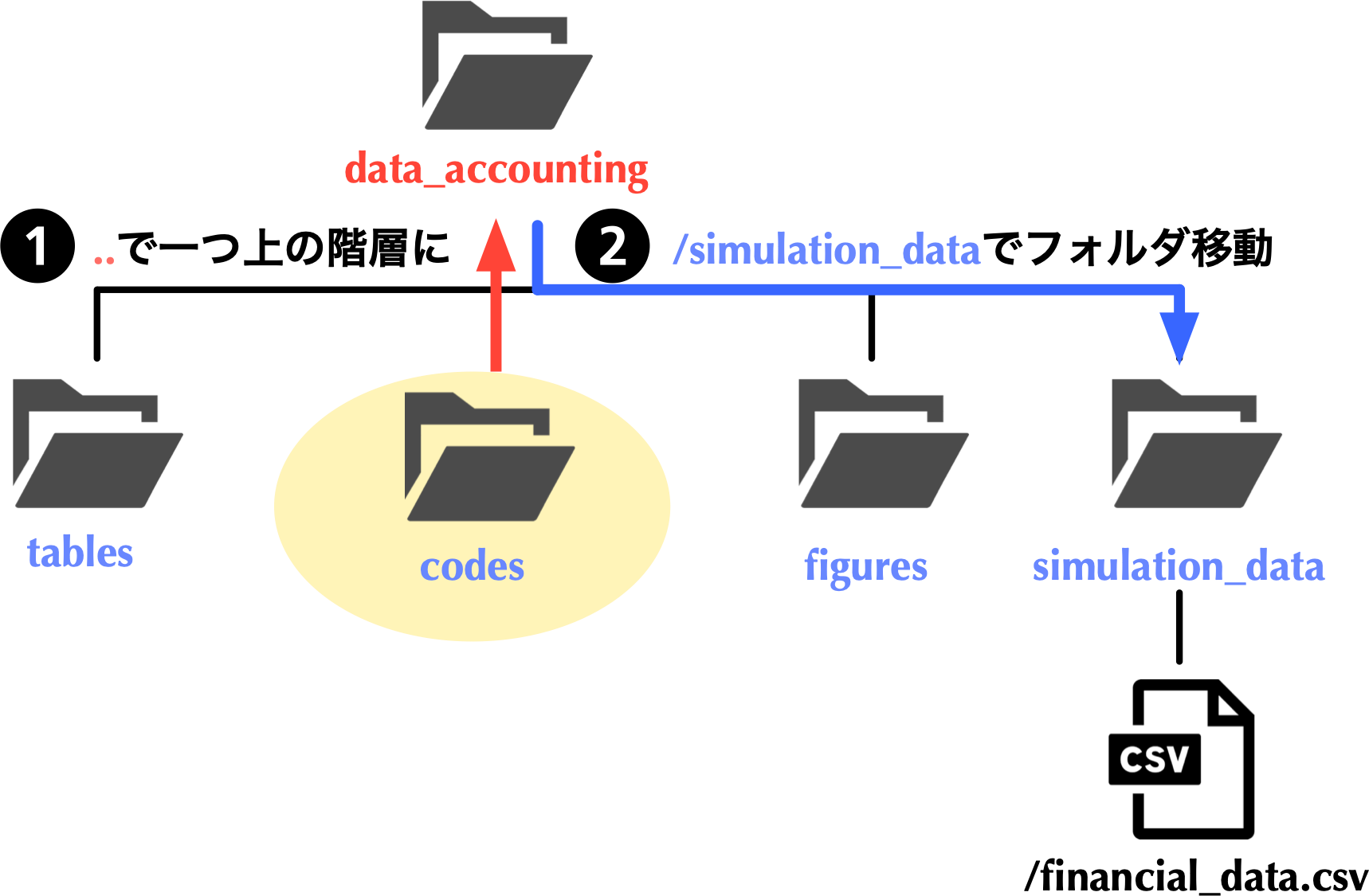
# 財務データの読み込み
financial_data <- read_csv("../simulation_data/financial_data.csv") Rows: 22855 Columns: 7
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (6): firm_ID, year, macc, X, TA, CFO
date (1): fiscal_year_end
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.# head()関数を用いて冒頭6行の結果のみ表示
head(financial_data) # A tibble: 6 × 7
firm_ID fiscal_year_end year macc X TA CFO
<dbl> <date> <dbl> <dbl> <dbl> <dbl> <dbl>
1 8 2004-07-01 2004 12 3125 204270 3319
2 8 2005-07-01 2005 12 3973 197259 4571
3 8 2006-07-01 2006 12 4117 203422 3820
4 8 2007-07-01 2007 12 4277 217386 2367
5 8 2008-03-01 2008 8 4743 218038 5591
6 8 2009-03-01 2009 12 5445 222643 3604fiscal_year_end: 決算年月 (YYYY-MM-DD形式)macc: 決算月数X: 当期純利益(百万円)TA: 資産合計(百万円)CFO: 営業活動によるキャッシュフロー(百万円)Xを基準化分析にあたっては,当期純利益Xそのものの分布ではなく,各企業の規模を統制して各観測値を横並びで比較可能にしたScaled Earnings (SE)の分布を考えよう.
\[ \underbrace{SE_{i,t}}_{\textbf{企業$i$の年度$t$のScaled Earnings}} = \frac{\overbrace{X_{i,t}}^{\textbf{企業$i$の年度$t$の当期純利益}}}{\text{各企業の規模の代理変数}} \]
この分析では,簡便的に各企業の発行する株式の時価総額 (株価 \(\times\) 発行済株式数)を規模の代理変数と捉え,分析を進めて行こう.
simulation_dataフォルダにあるstock_data.csvをstock_dataとして読み込んでみよう.# 株式データの読み込み
stock_data <- read_csv("../simulation_data/stock_data.csv") Rows: 22852 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (4): firm_ID, year, stock_price, shares_outstanding
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.head(stock_data)# A tibble: 6 × 4
firm_ID year stock_price shares_outstanding
<dbl> <dbl> <dbl> <dbl>
1 8 2007 412 117800776
2 8 2008 514 117800776
3 8 2009 743 117800776
4 8 2010 718 117800776
5 8 2011 1015 117800776
6 8 2012 958 117800776stock_price: 株価shares_outstanding: 発行済株式数stock_dataに時価総額ME列の追加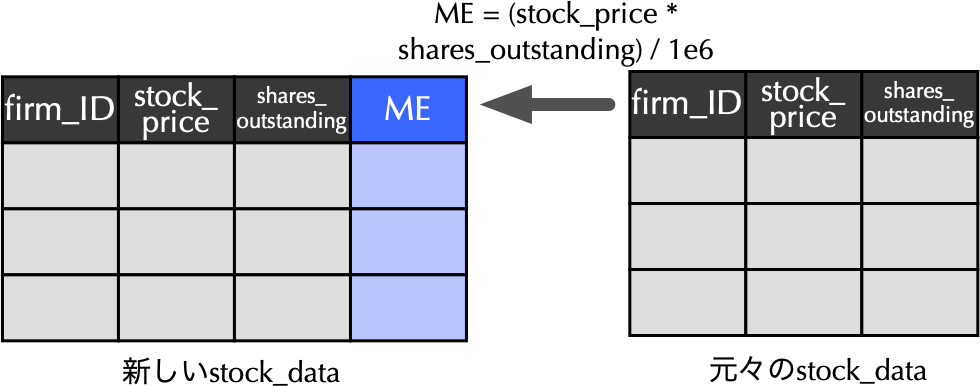
# mutate()関数を使ってME列の追加
stock_data <- stock_data %>%
mutate(ME = (stock_price * shares_outstanding) / 1e6) # MEを百万円単位で計算 1e6は科学技術分野で一般的に用いられる科学的表記と呼ばれる表記法(教科書157頁)であり,\(1 \times 10^6 (= 1,000,000)\)と等しい.MEを計算する際,財務データと単位を揃えることを目的として1e6で除している.(stock_price * shares_outstanding) / 1000000とはしないこと!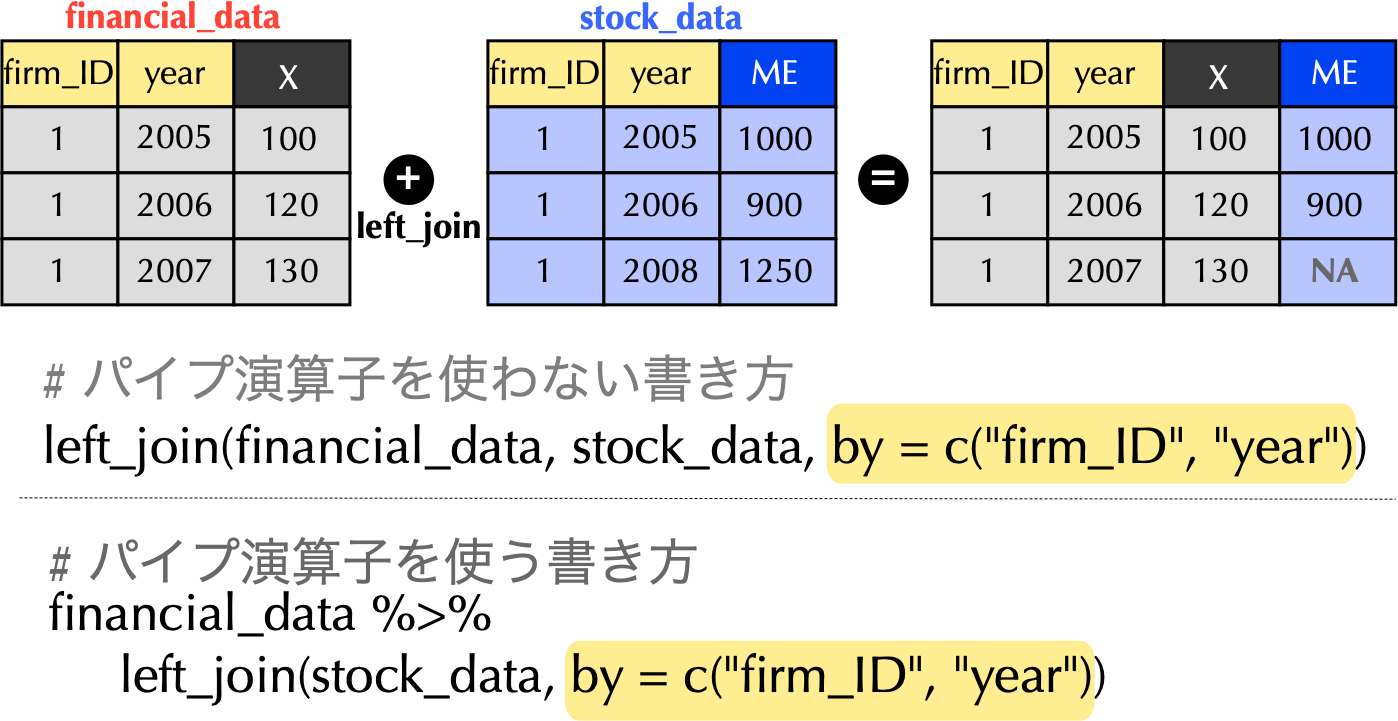
SE列も追加# 財務データと株式データの結合し,SE列も追加
financial_data <- financial_data %>%
left_join(stock_data, by = c("firm_ID", "year")) %>%
mutate(SE = if_else(macc == 12, X / ME, NA))
# 決算月数が12ヶ月ではないものは欠損値にdplyrのif_else()関数を使って決算月数が12ヶ月の場合はSEを計算し,そうでなければ欠損値NAになるように工夫している.
sampleを利用して分析を進めて行こう.# 分析に利用する観測値のみのデータフレームsampleを作成
sample <- financial_data %>%
drop_na(SE) # SEが欠損値のものを削除 drop_na()の使い方は,ここを参照.summarize()関数を使ってみよう# 年度ごとにSEの平均値を計算
table_1 <- sample %>% # 集計結果をtable_1として定義
group_by(year) %>% # 年度でグループ化
summarize(Mean = mean(SE)) # 平均値をMeanと命名
head(table_1) # 内容の確認# A tibble: 6 × 2
year Mean
<dbl> <dbl>
1 2005 0.0144
2 2006 0.0126
3 2007 -0.0109
4 2008 0.0337
5 2009 0.0749
6 2010 0.0378table_1として定義.yearでグループ化.summarize関数を適用し,SEの平均値をmean(SE)により計算し,それをMeanと命名.# 年度ごとに基本統計量を集計
table_1 <- sample %>%
group_by(year) %>% # 年度毎にグループ化
summarize(N = n(), # 観測値数
Mean = mean(SE), # 平均値
SD = sd(SE), # 標準偏差
Q1 = quantile(SE, 0.25), # 第1四分位
Median = median(SE), # 中央値
Q3 = quantile(SE ,0.75)) # 第3四分位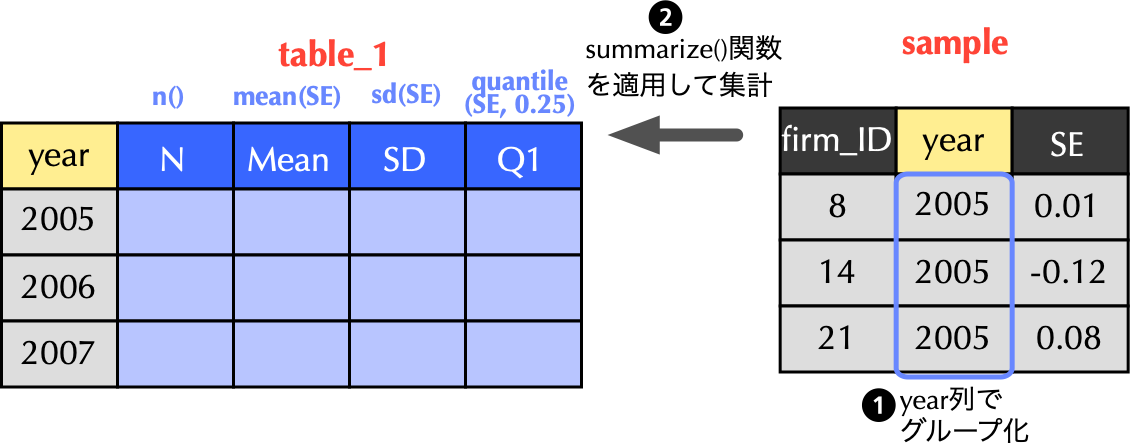
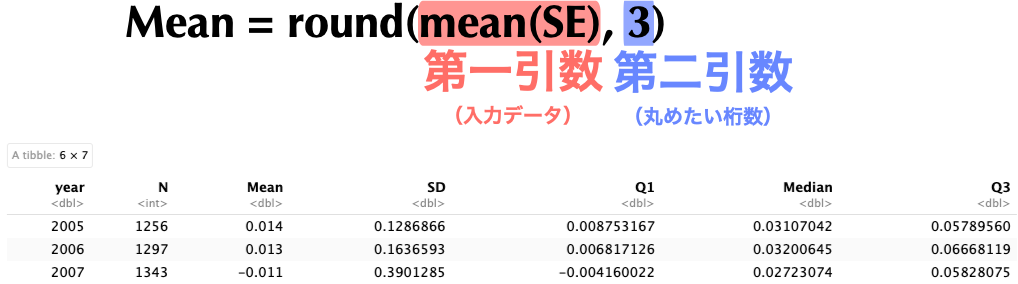
quantile()関数の使い方quantile()関数を用いる.この関数は第一引数に入力データ(数値ベクトル),第二引数に求めたい分位点の値をパーセントでなく小数表示で代入する(教科書185頁).SEの第1四分位を求めたいならば,quantile(SE, 0.25)とすれば良い.
write_csv()関数を使ったデータフレームの出力# table_1の結果を出力
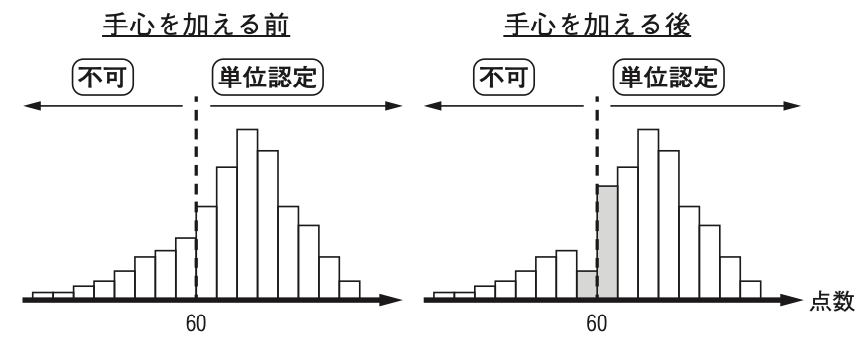
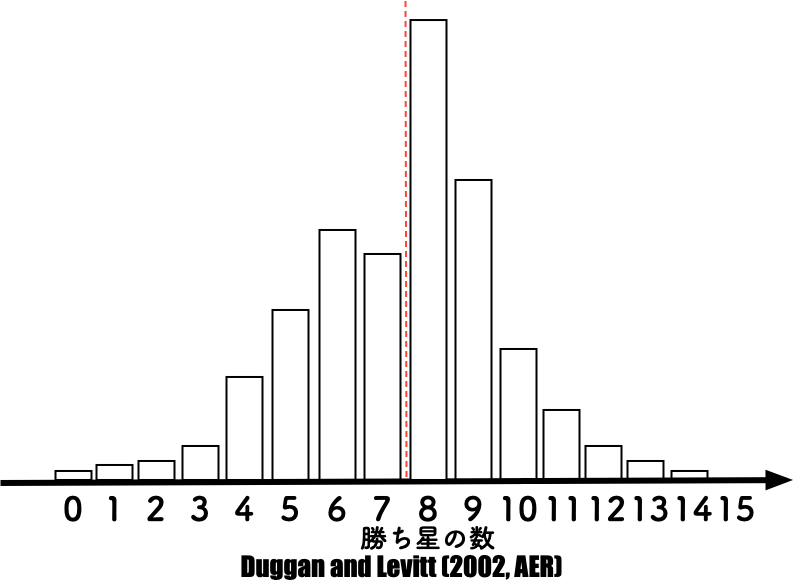
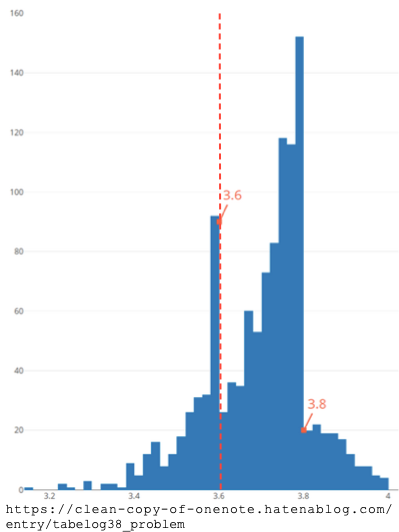
write_csv(table_1, "../tables/table_1.csv")readrのwrite_csv()関数を使って,先に作成したデータフレームtable_1をtablesフォルダに出力しよう.write_csv()関数の第一引数はデータフレーム名を入力し,第二引数でファイル名を指定する(教科書184頁).codesであることを前提にすれば,出力したいtablesフォルダへ移動するには,一個上の階層に一度戻る必要があり,それは..により実現可能である.tablesフォルダに移動 (/tables)し,table_1.csvという名前で出力 (/table_1.csv)すれば良いので,write_csv()関数の第二引数は,"../tables/table_1.csv"と指定する.SE)のヒストグラムggplot2を利用し,Scaled Earnings (SE)のヒストグラムを描画し,利益マネジメントの実態を明らかにしていこう.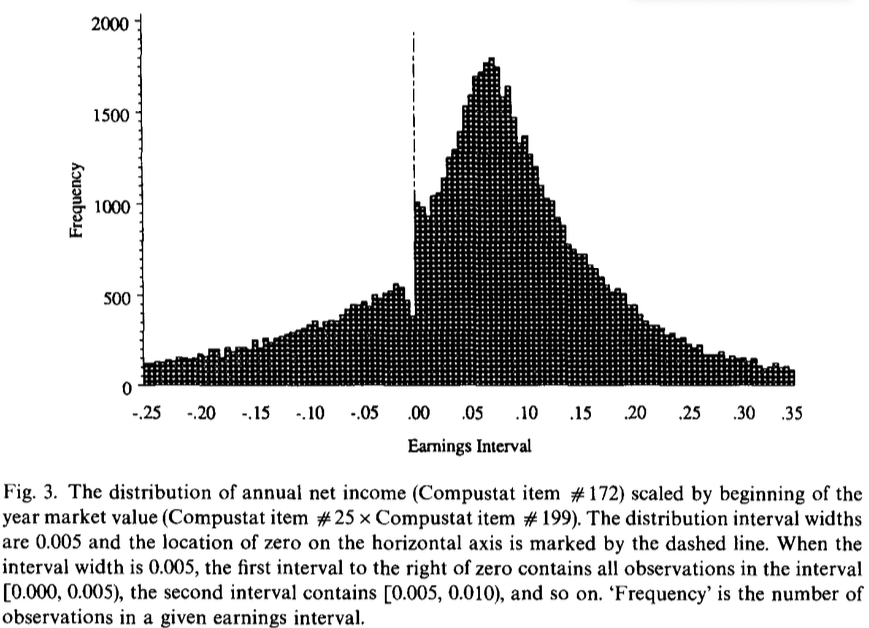
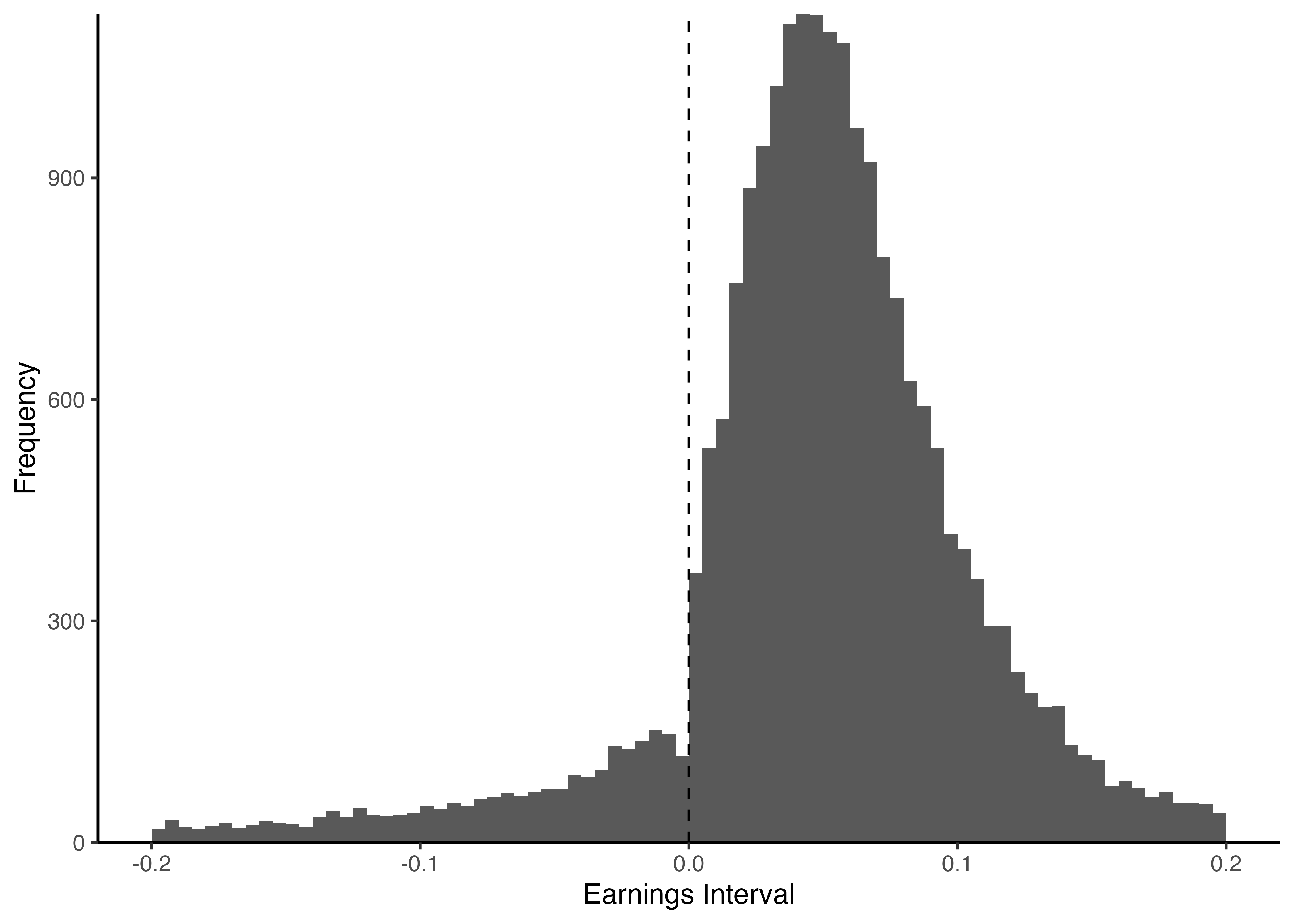
SEのヒストグラムの描画# SEのヒストグラムの描画
ggplot(sample) +
geom_histogram(aes(x = SE),
breaks = seq(-0.2, 0.2, 0.005)) +
labs(x = "Earnings Interval", y = "Frequency") +
scale_y_continuous(expand = c(0, 0)) +
theme_classic()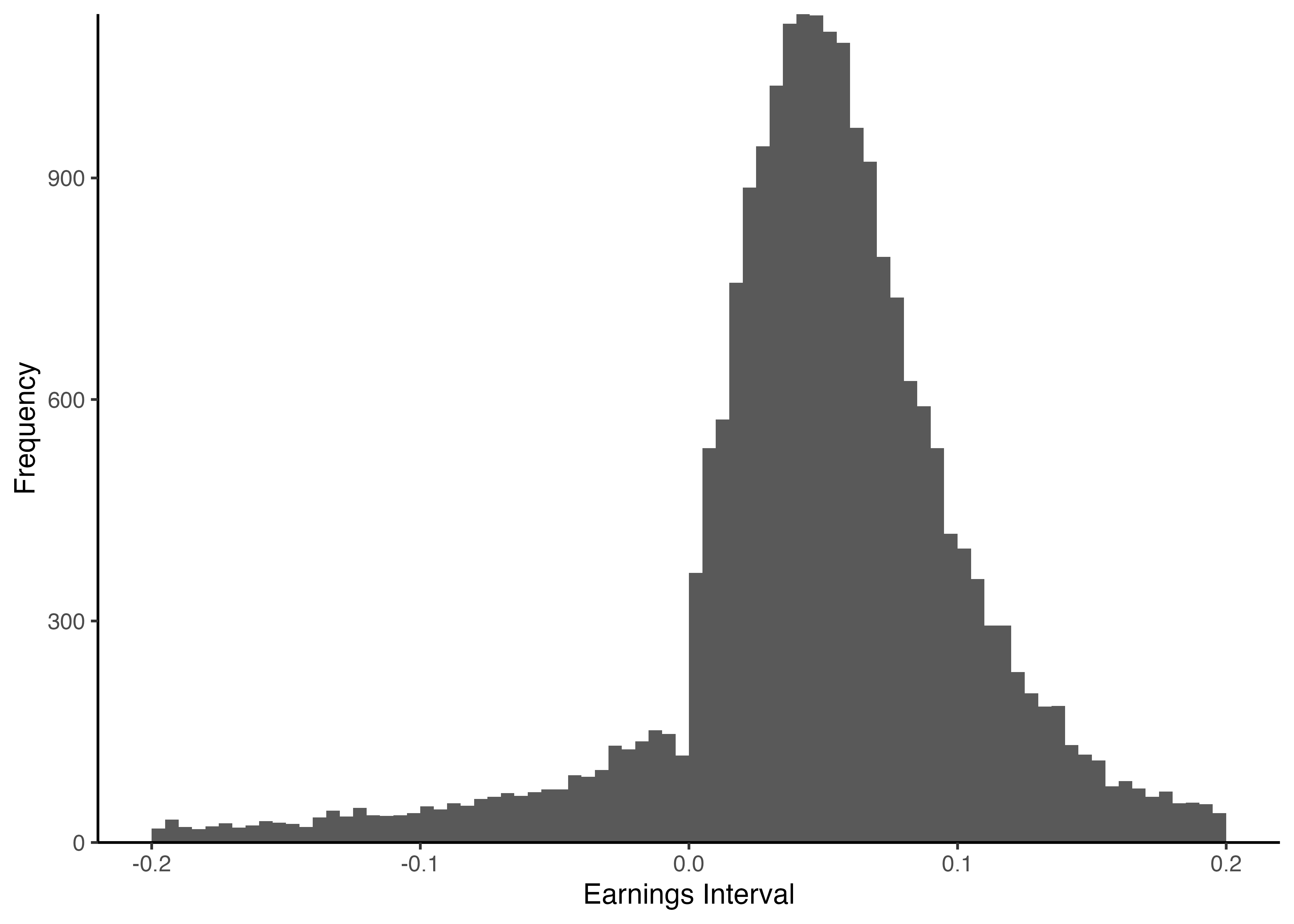
geom_vline()関数は,vertical(垂直)に直線を引く.xintercept引数で値を指定し,またlinetype引数で適当な線種を指定する(dashedの他にも,dottedやsolidなど多様にオプションが用意されている).PNG形式で出力ggsave()関数を利用する.第一引数にはファイル名を指定しよう.figuresフォルダのある階層を意識して第一引数を指定しよう.# ggsave()関数を使ってSEのヒストグラムをfigure_1.pngとして出力
ggsave("../figures/figure_1.png") Saving 7 x 5 in image# 出力サイズを明示的に指定して出力
ggsave("../figures/figure_1.png",
width = 20, # 幅を指定
height = 10, # 高さを指定
units = "cm") # 幅と高さの単位を指定SEが正で少なくとも過去1期は損失回避できた企業群だけに絞り,同様のヒストグラムを描画する方法を実践していこう.首藤昭信 (2010)『日本企業の利益調整: 理論と実証』中央経済社.↩︎