5 利益分布アプローチによる利益マネジメントの実態分析
2024-05-10
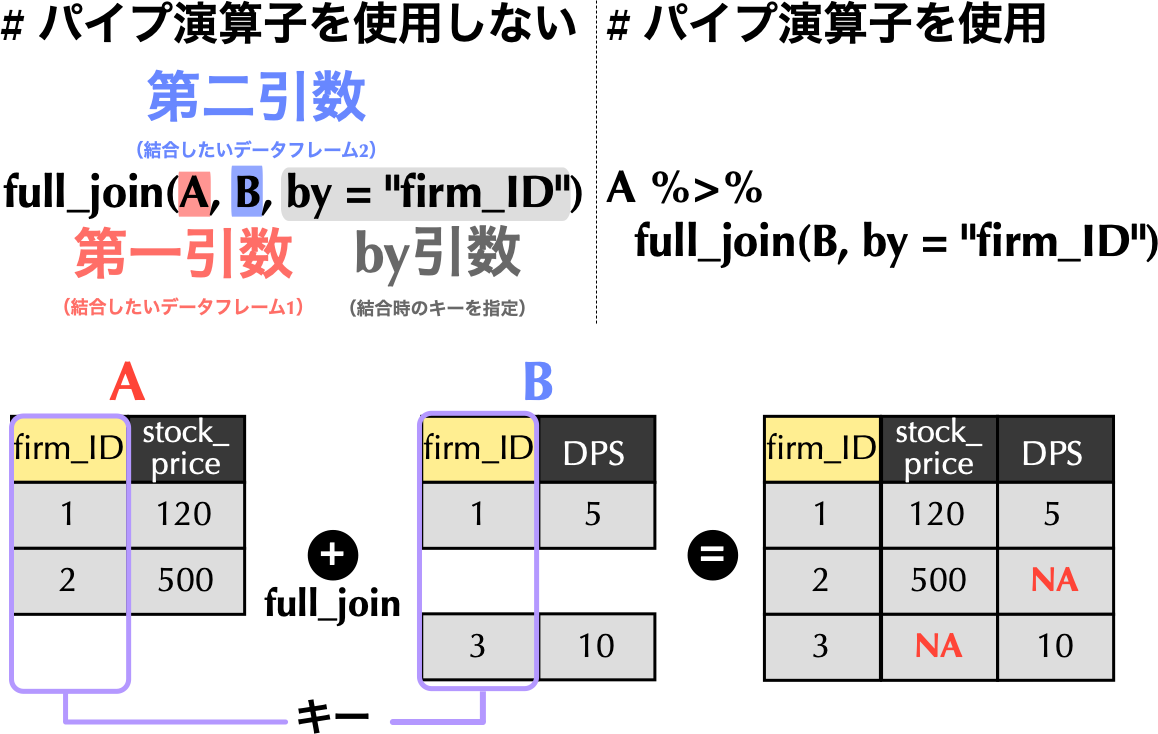
1.2 完全外部結合full_join()関数
1.3 内部結合inner_join()関数
# A tibble: 1 × 3
firm_ID stock_price DPS
<dbl> <dbl> <dbl>
1 1 120 5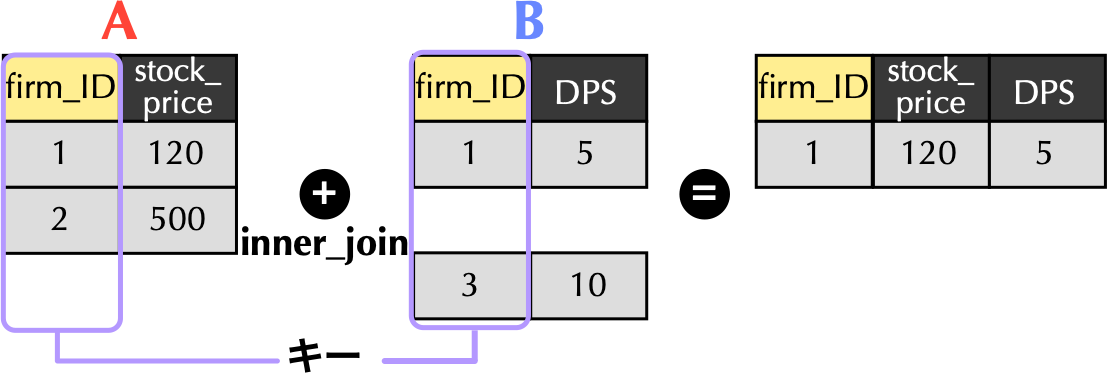
1.4 左結合left_join()関数
# A tibble: 2 × 3
firm_ID stock_price DPS
<dbl> <dbl> <dbl>
1 1 120 5
2 2 500 NA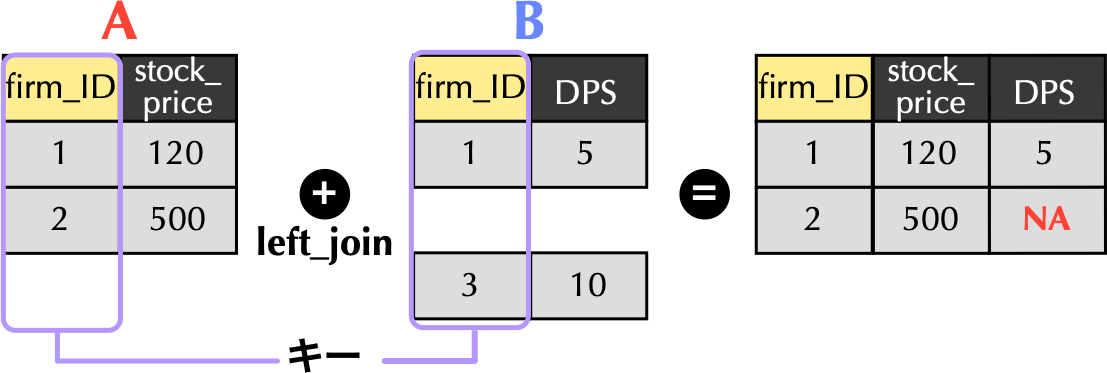
2 分布の不連続性(教科書コラム5.3)
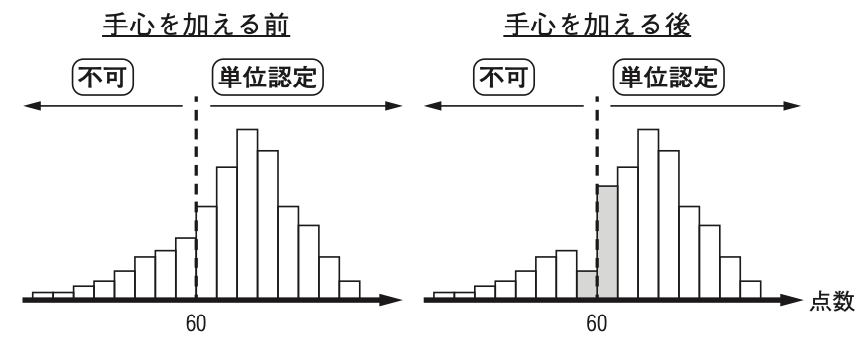
2.1 成績評価チート
2.2 その他の例
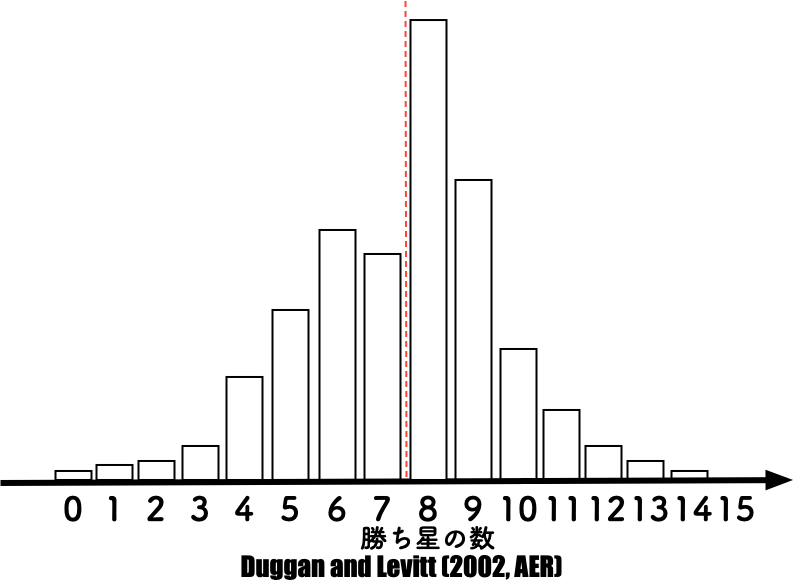
- 大相撲の勝ち星
![]()
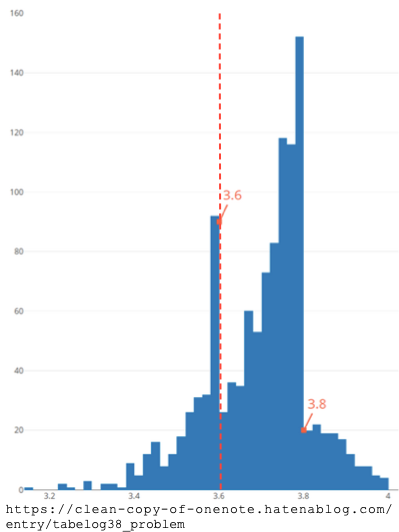
- 食べログ3.6問題
![]()
3.2 フォルダ構造
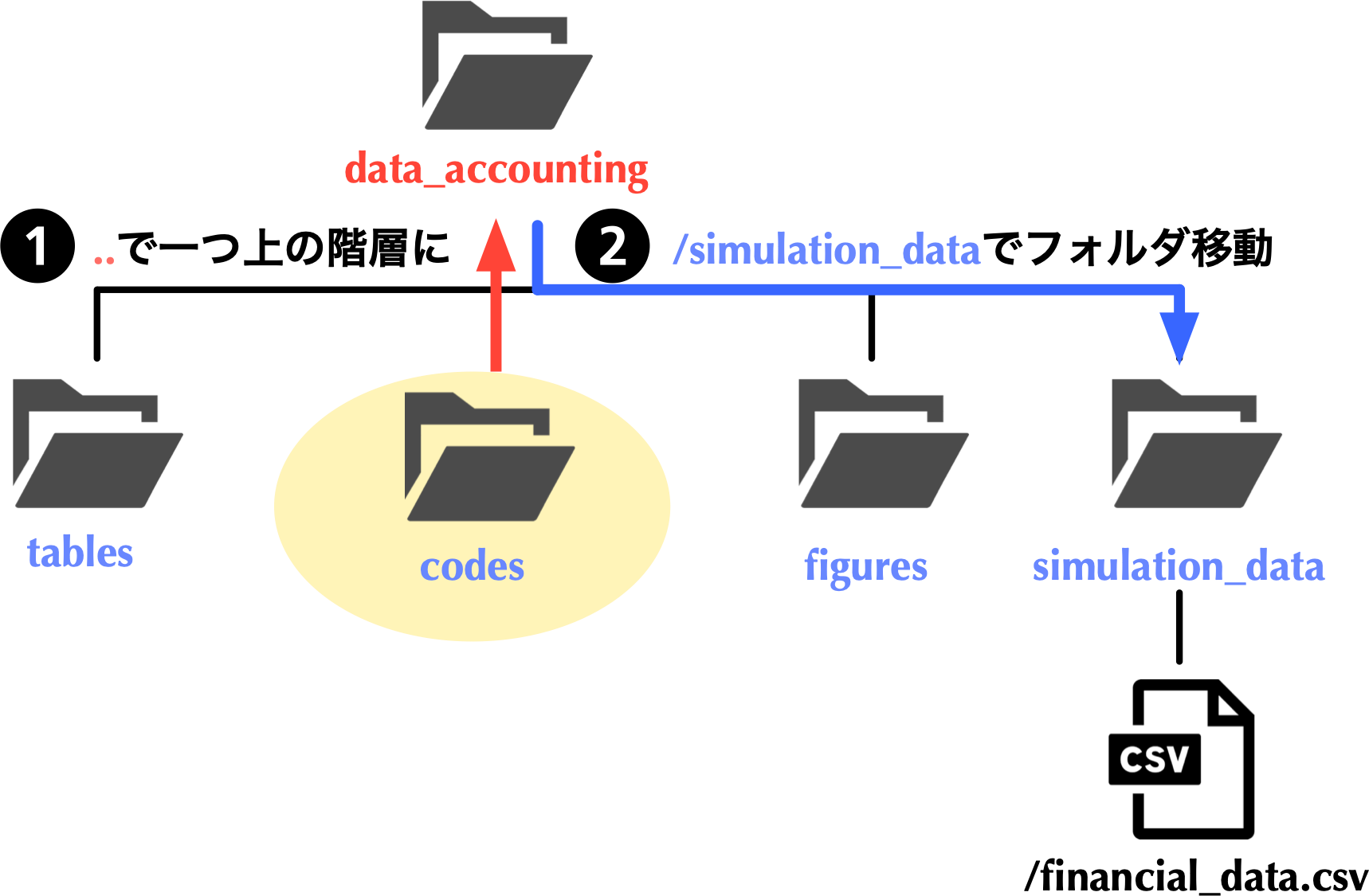
- 現在地が
codesである場合,読み込みたいfinancial_data.csvが格納されているsimulation_dataフォルダにアクセスするには,一個上の階層に一度戻る必要があり,それは..により実現可能である. - あとは,
simulation_dataフォルダに移動 (/simulation_data)し,/financial_data.csvで目的のファイルにアクセス可能である.
3.5 株式データの読み込み
- Scaled Earningsのデフレータとなる時価総額を得るため,
simulation_dataフォルダにあるstock_data.csvをstock_dataとして読み込んでみよう.
Rows: 22852 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (4): firm_ID, year, stock_price, shares_outstanding
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.# A tibble: 6 × 4
firm_ID year stock_price shares_outstanding
<dbl> <dbl> <dbl> <dbl>
1 8 2007 412 117800776
2 8 2008 514 117800776
3 8 2009 743 117800776
4 8 2010 718 117800776
5 8 2011 1015 117800776
6 8 2012 958 117800776stock_price: 株価shares_outstanding: 発行済株式数
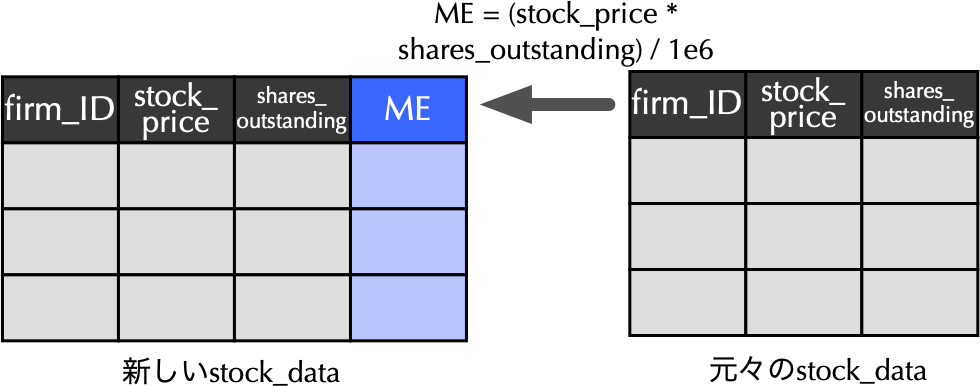
3.6 stock_dataに時価総額ME列の追加
3.8 財務データと株式データの結合
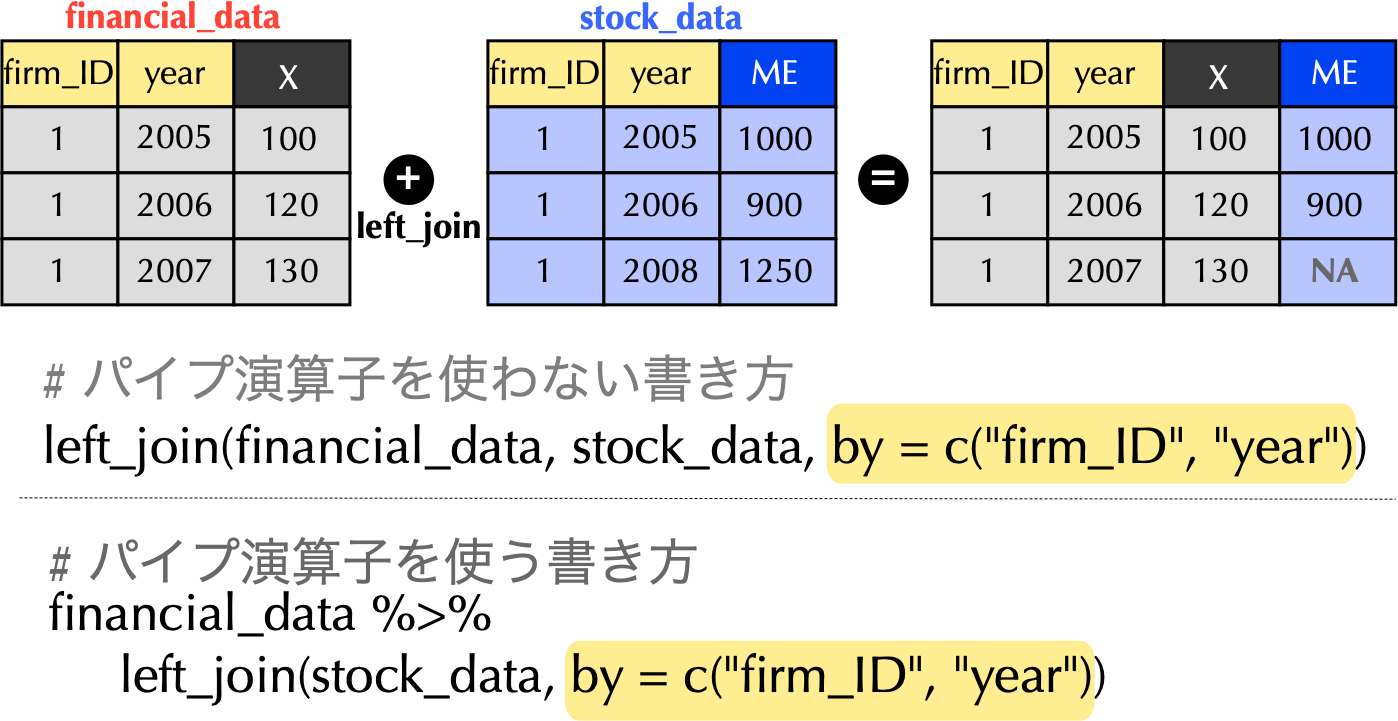
3.9 パイプ演算子を繋げてSE列も追加
- 上のコードでは,
dplyrのif_else()関数を使って決算月数が12ヶ月の場合はSEを計算し,そうでなければ欠損値NAになるように工夫している.

4.5 更に一歩進んで,年度ごとに基本統計量を集計
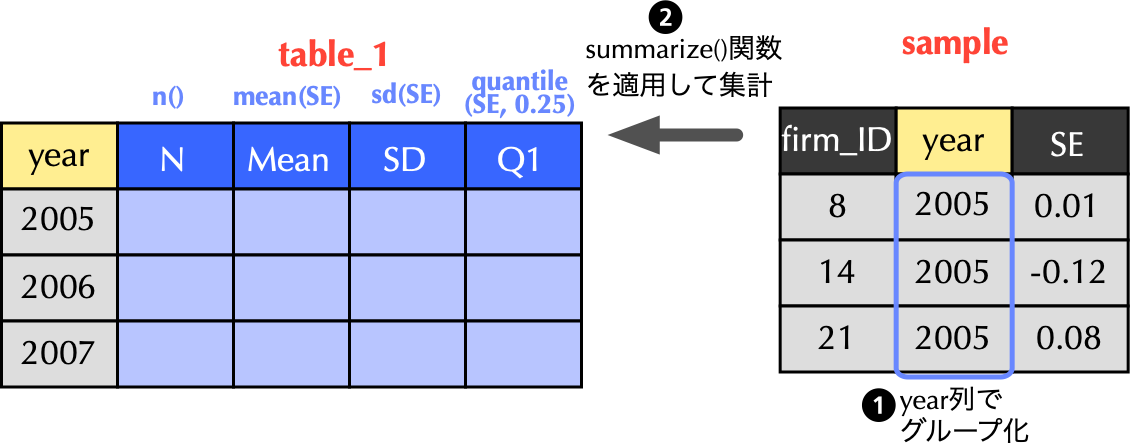
4.6 quantile()関数の使い方
- 分位点を求めるには
quantile()関数を用いる.この関数は第一引数に入力データ(数値ベクトル),第二引数に求めたい分位点の値をパーセントでなく小数表示で代入する(教科書185頁). - 例えば,
SEの第1四分位を求めたいならば,quantile(SE, 0.25)とすれば良い.

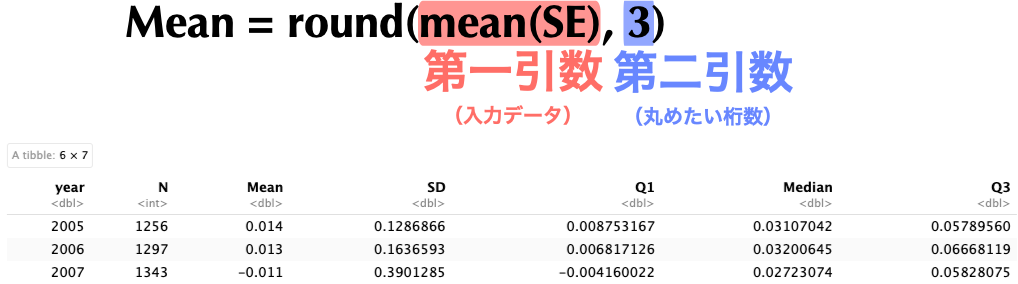
4.7 出力結果のアレンジ — 桁数の調整
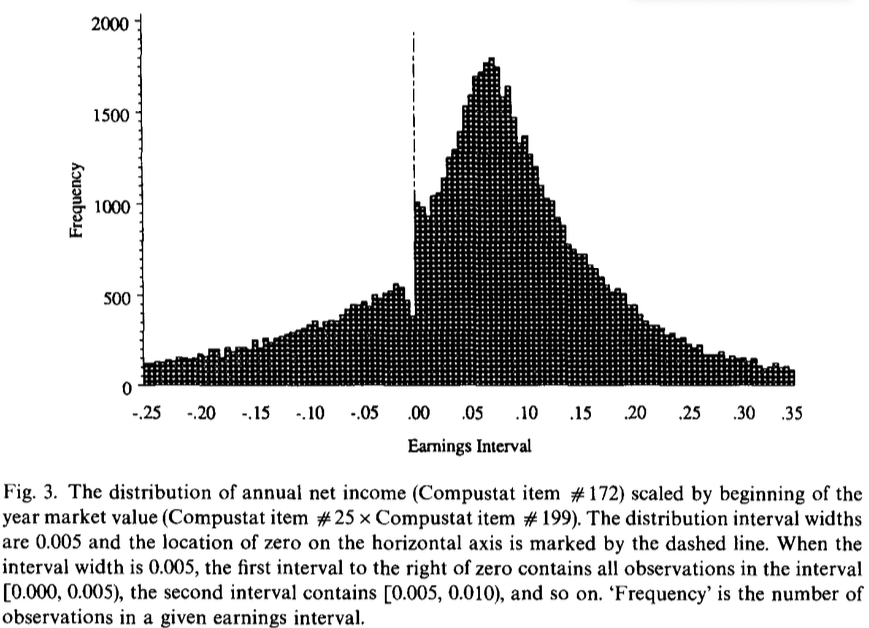
4.10 オリジナル論文のヒストグラム (Fig. 3)
4.11 SEのヒストグラムの描画
Code
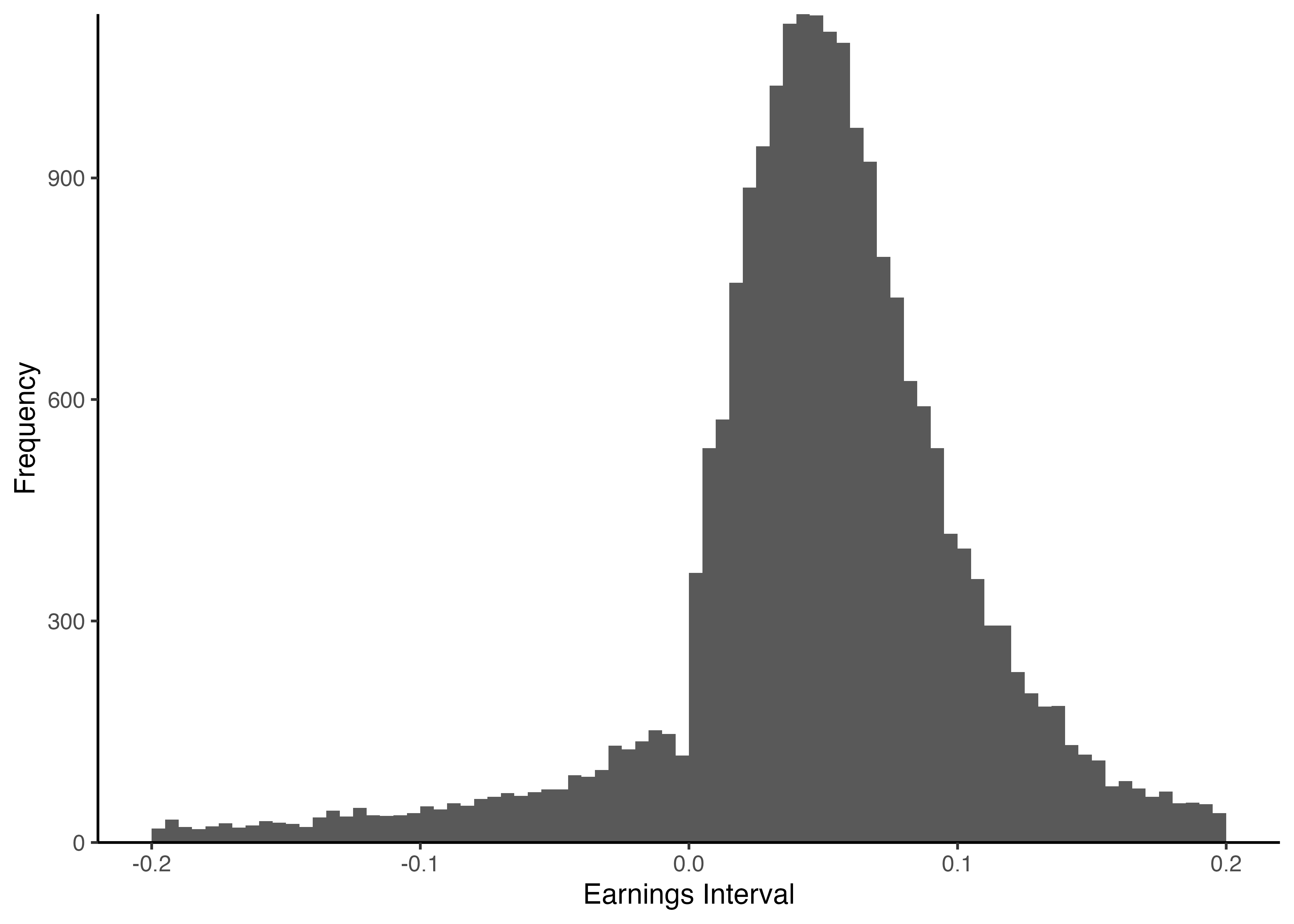
4.12 \(x = 0\)を表す破線の追加
geom_vline()関数は,vertical(垂直)に直線を引く.xintercept引数で値を指定し,またlinetype引数で適当な線種を指定する(dashedの他にも,dottedやsolidなど多様にオプションが用意されている).
Code
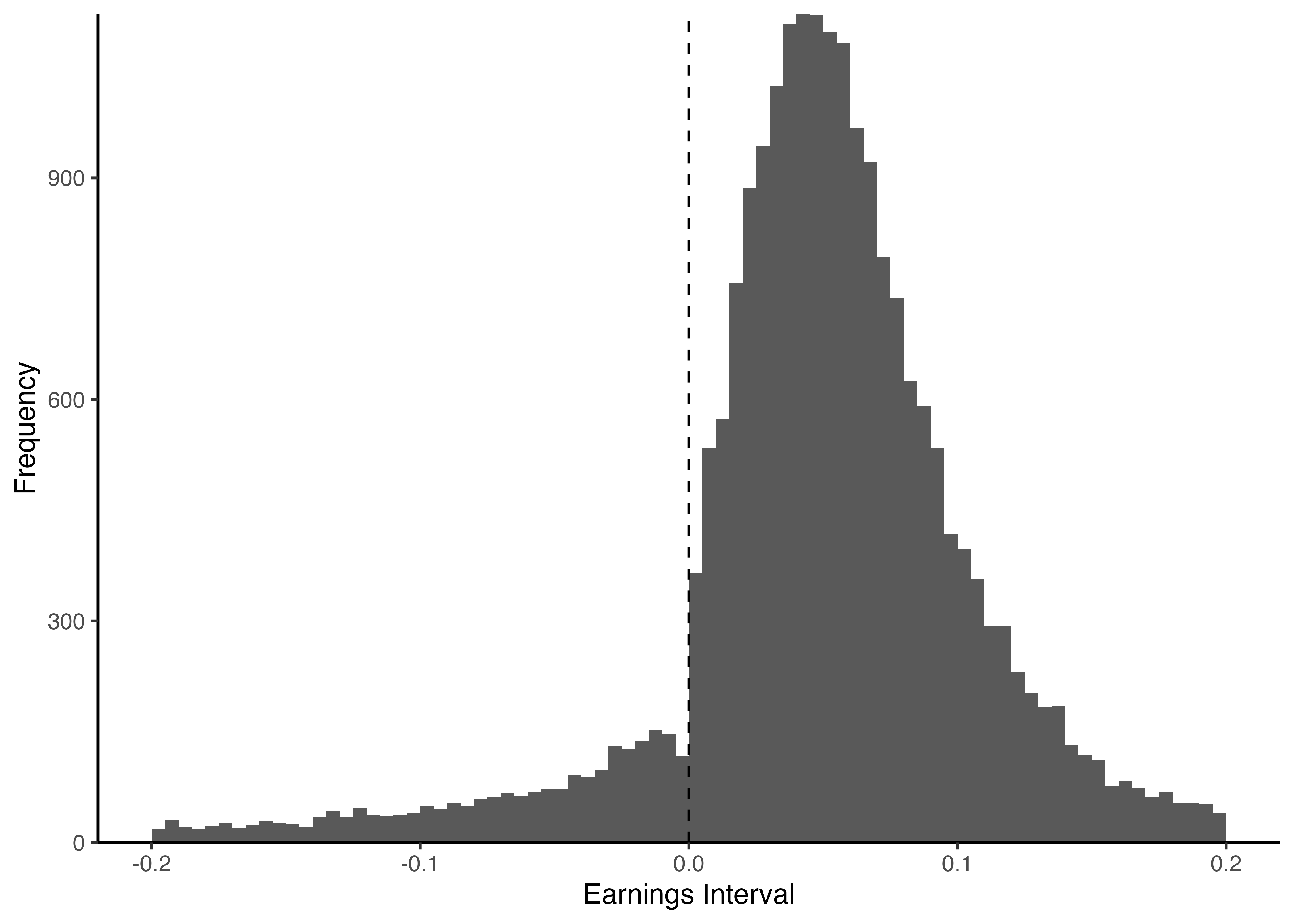
4.13 完成したグラフをPNG形式で出力
- (ヒント1) 直前に出力したグラフを保存したい場合,
ggsave()関数を利用する.第一引数にはファイル名を指定しよう. - (ヒント2)
figuresフォルダのある階層を意識して第一引数を指定しよう.
4.14 目標を達成するためのコード例
Saving 7 x 5 in image- 必要に応じてグラフのサイズなどの細部を調整したい場合は,別途引数により調整すれば良い.