Code
# CSVファイルの読み込み
daily_stock_return <- read.csv("ch03_daily_stock_return.csv") ,) で区切って書いたテキスト・ファイルのことを指す..xlsxファイル)を思い浮かべるかもしれないが,特定のアプリケーションに依存したファイル形式だと,互換性がなくて他の環境では開けない恐れがある.したがって,テキストファイルに値とカンマだけで内容を書き込み,互換性を高めたファイル形式がCSVファイルである.read.csv()関数を使ったCSVファイルの読み込みread.csv()関数が用意されている.read.csv()関数には数多くのオプション引数が存在するが,それらをいったん無視して,ファイルのパスをダブルクォーテーション("")で囲って引数に指定すれば良い.# CSVファイルの読み込み
daily_stock_return <- read.csv("ch03_daily_stock_return.csv") ch03_daily_stock_return.csvがコードと同じ作業ディレクトリに位置しているなら,上のように"ch03_daily_stock_return.csv"という相対パスのみ指定すれば,Rはそのファイルを発見できる.もし上のコードを実行して,次のようなエラーが出る場合,Rはch03_daily_stock_return.csvを発見できていない.
ch03_daily_stock_return.csvから変更されていないことを確認しよう.繰り返し同じファイルをダウンロードしているとch03_daily_stock_return(1).csvのように,勝手に名前が変更されてしまう場合がある.daily_stock_returnの詳細の確認head()関数を用いて,コンソール上でdaily_stock_returnの冒頭6行を出力してみる.# データフレームの冒頭を確認
head(daily_stock_return) date firm1 firm2
1 2020-04-01 -0.039482142 0.076962597
2 2020-04-02 0.005978689 -0.007248848
3 2020-04-03 0.055786605 -0.017304080
4 2020-04-06 0.041934669 0.002168957
5 2020-04-07 -0.020192796 0.075545365
6 2020-04-08 -0.002294705 -0.096211744nrow()関数を用いて,何営業日分の株価を含んでいるか確認してみよう.ここで,nrowはnumber of rows(行数)の略である.# データフレームの行数を確認
nrow(daily_stock_return)[1] 21daily_stock_returnの詳細の確認daily_stock_returnの各列の名前やデータ型を確認したい.str()関数を用いてdaily_stock_returnの内部構造を調べてみよう.strはstructure(構造)の略で,変数の内部構造を意味する.# データフレームの内部構造を確認
str(daily_stock_return)'data.frame': 21 obs. of 3 variables:
$ date : chr "2020-04-01" "2020-04-02" "2020-04-03" "2020-04-06" ...
$ firm1: num -0.03948 0.00598 0.05579 0.04193 -0.02019 ...
$ firm2: num 0.07696 -0.00725 -0.0173 0.00217 0.07555 ...21 obs. of 3 variablesより,三変数について,21の観測値が収録されていることが確認できる.chr)のdatenum)のfirm1num)のfirm2daily_stock_returnの詳細の確認firm1)と企業2 (firm2)の株式の日次リターンについて,平均的に見てどちらのリターンが高かったのか,mean()関数を用いて確認してみよう.$演算子を用いると列名で各列を参照できることを思い出そう.# 日次リターンの平均値を計算
mean(daily_stock_return$firm1)[1] 0.01416117mean(daily_stock_return$firm2)[1] 0.008025261# industry列を文字型として定義
firm_ID <- c(1, 2, 3)
name <- c("Firm A", "Firm B", "Firm C")
industry <- c("Machinery", "Chemicals", "Machinery")
# data.frame()関数により三変数のデータフレームを作成
firm_data <- data.frame(firm_ID, name, industry)
print(firm_data) # firm_dataの確認 firm_ID name industry
1 1 Firm A Machinery
2 2 Firm B Chemicals
3 3 Firm C Machineryfirm_dataというデータフレームを作成すると,firm_ID列は数値型,name列とindustry列が文字型となる.industry列はカテゴリカル変数と呼ばれ,各観測データがどのサブカテゴリーに属するかを明らかにする役割を果たしている.
# industry列をファクター型に変換
firm_data$industry <- as.factor(firm_data$industry)
str(firm_data)'data.frame': 3 obs. of 3 variables:
$ firm_ID : num 1 2 3
$ name : chr "Firm A" "Firm B" "Firm C"
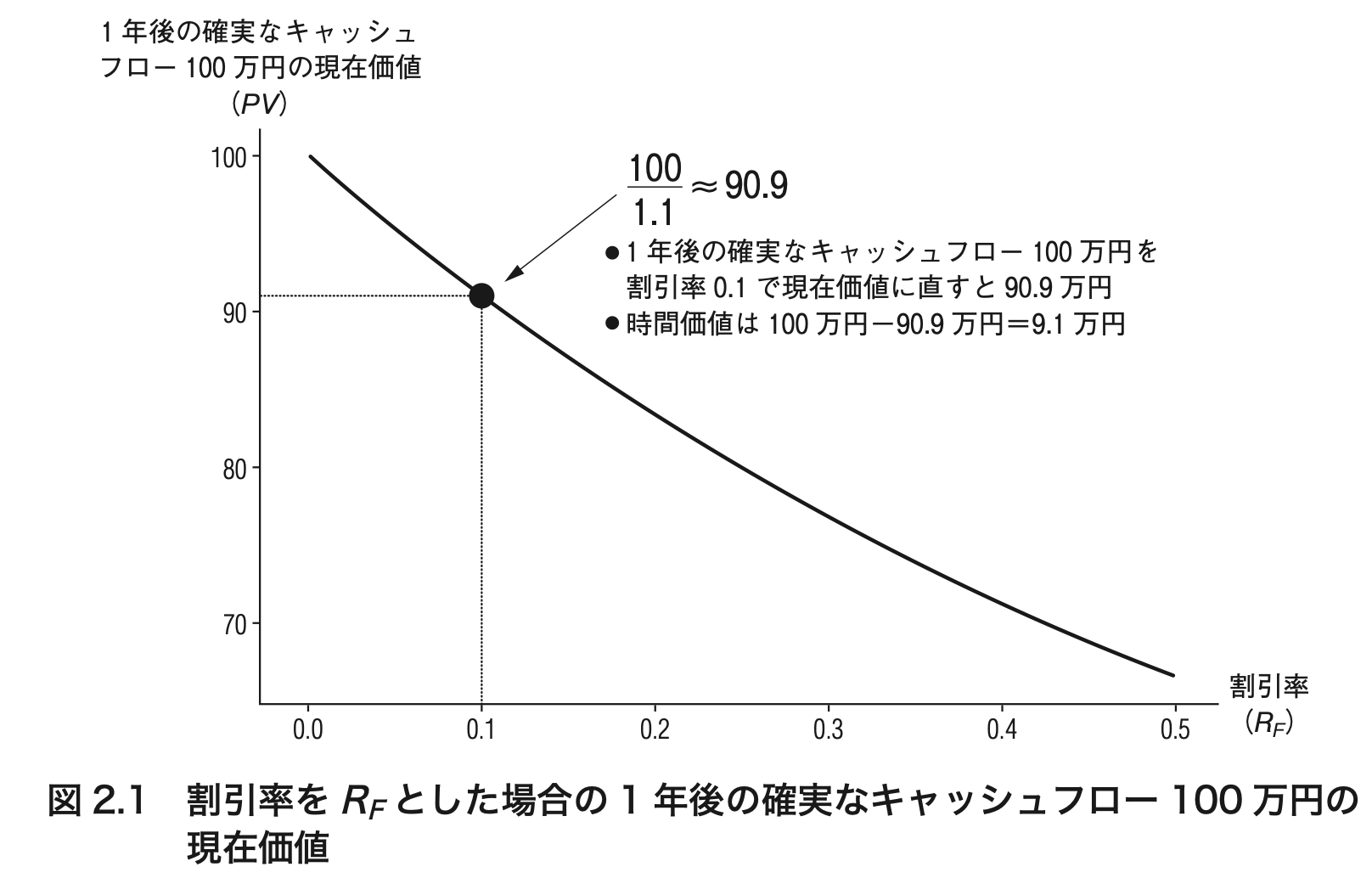
$ industry: Factor w/ 2 levels "Chemicals","Machinery": 2 1 2as.factor()関数は,データ列をファクター型に変換する関数.str()関数を用いて構造を眺めてみると,name列が文字型 (chr)のままであるのに対し,industry列はファクター型 (Factor)に変換済."Chemicals"と"Machinery"は水準 (level)と呼ばれ,各カテゴリーの名前を表す.コンピュータ内部では各カテゴリーが自然数で表されており,今回の観測データはその番号を介して,2 (Machinery),1 (Chemicals),2 (Machinery)と表現されている.\[ \begin{align*} \underbrace{\mathit{PV}}_{\textbf{現在価値}}= \frac{\overbrace{CF_1}^{\textbf{1年後の確実なキャッシュフロー}}}{\underbrace{1 + R_{F}}_{\textbf{無リスク金利$R_F$で割り引く}}} \end{align*} \]
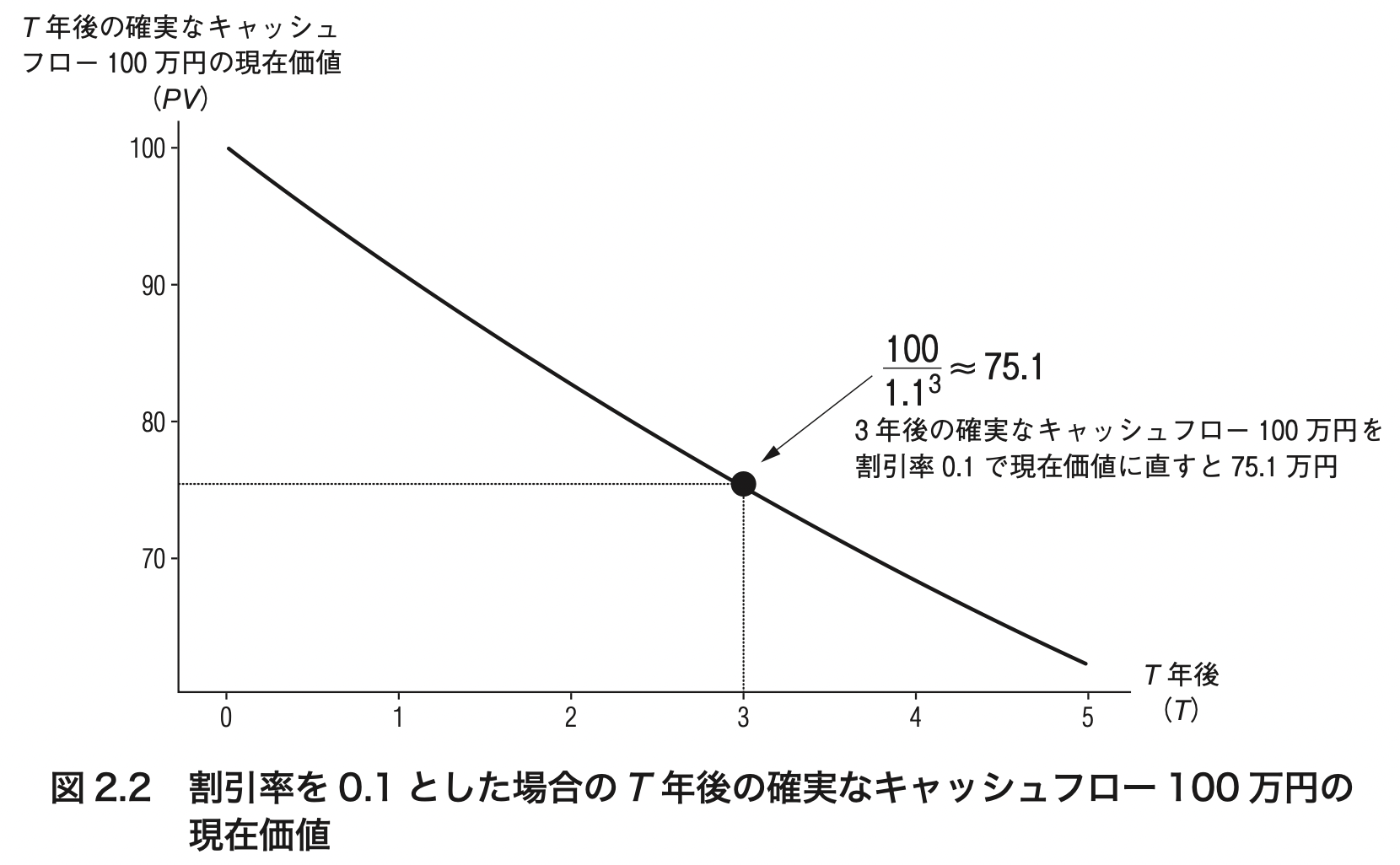
\[ \begin{align*} \underbrace{\mathit{PV}}_{\textbf{現在価値}} &= \frac{\overbrace{CF_T}^{\textbf{$T$年後の確実なキャッシュフロー}}}{\underbrace{(1+R_F)^ {T}}_{\textbf{$T$年分だけ無リスク金利$R_F$で割り引く}}} \end{align*} \]
tidyverseパッケージとは?tidyverseと呼ばれるパッケージ群である.以下が,それに含まれる主なパッケージ一覧である.| 名称 | 使用用途 |
|---|---|
ggplot2 |
グラフの描画によるデータの可視化 |
dplyr |
データの加工や操作に便利な関数の提供 |
tidyr |
雑然データを整然データの形式に変換する関数の提供 |
readr |
CSVファイルなどの高速,かつ,ユーザー・フレンドリーな読み込み |
tibble |
データフレームを改良したtibbleというデータ形式の提供 |
tidyverseパッケージのインストール# tidyverseのインストール - 通常バージョン
install.packages("tidyverse")install.packages()関数を用いて,第一引数にインストールしたいパッケージ名を""で囲って指定する.ggplot2による作図 — 作図データの準備# 11次元の無リスク金利ベクトルの作成
R <- seq(0.1, 0.2, 0.01) # 無リスク金利ベクトルRを作成100というのは1次元のスカラー(一つの実数)であり,Rは11次元のベクトルである.したがって,次式を計算しようとすると,両者の次元が一致しておらず,数学的には不完全な式となっている. \[
PV = \frac{\overbrace{100}^{\textbf{スカラー}}}{1 + \underbrace{\text{R}}_{\textbf{11次元のベクトル}}}
\]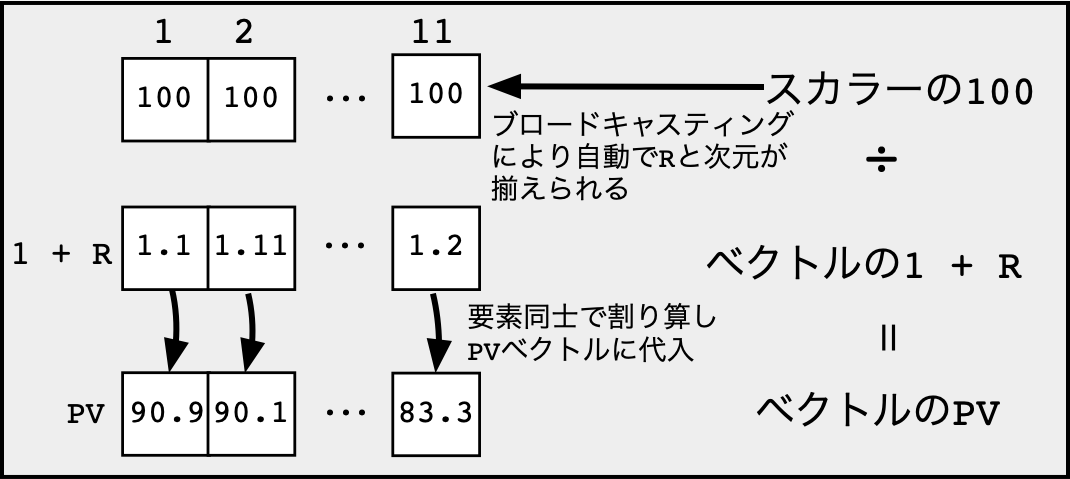
# ブロードキャスティングによるPVの計算
PV <- 100 / (1 + R) ggplot2による作図 — データフレームの準備ggplot2は,入力データをデータフレームの形式で準備する必要があるので,まずはdata.frame()関数を使って 新たなデータフレームfigure_dataを作成しよう.# データフレームの作成
figure_data = data.frame(R, PV) # 計算結果をデータフレームに格納ggplot2による作図 — tidyverseパッケージの読み込みggplot2パッケージを使うためには,library()関数を使ってtidyverseを利用することを冒頭で宣言する必要がある.pacman::p_load()を利用する.# ggplot2による作図
pacman::p_load(tidyverse) # 本講義のやり方ggplot2のggとは
grammar of graphicsの略である.ggplot2では,グラフの構成要素を各種のレイヤーに分解し,コード上でそれを積み重ねていく形でグラフを作図する.
ggplot2による作図 — data引数の指定ggplot()関数により,作図用キャンバスを準備し,入力データを指定.data = figure_dataとして,figure_dataを入力用データとして用いることを宣言している.# ggplot2による作図
pacman::p_load(tidyverse)
ggplot(data = figure_data) # data引数により入力データを指定
+演算子を用いてレイヤーを足していく形で図を作成する.geom_line()関数である.mapping引数のaes()関数では,\(x\)軸と\(y\)軸の要素をラベル名で指定している.# ggplot2による作図
pacman::p_load(tidyverse)
ggplot(data = figure_data) +
geom_line(mapping = aes(x = R, y = PV)) # 折れ線グラフを書く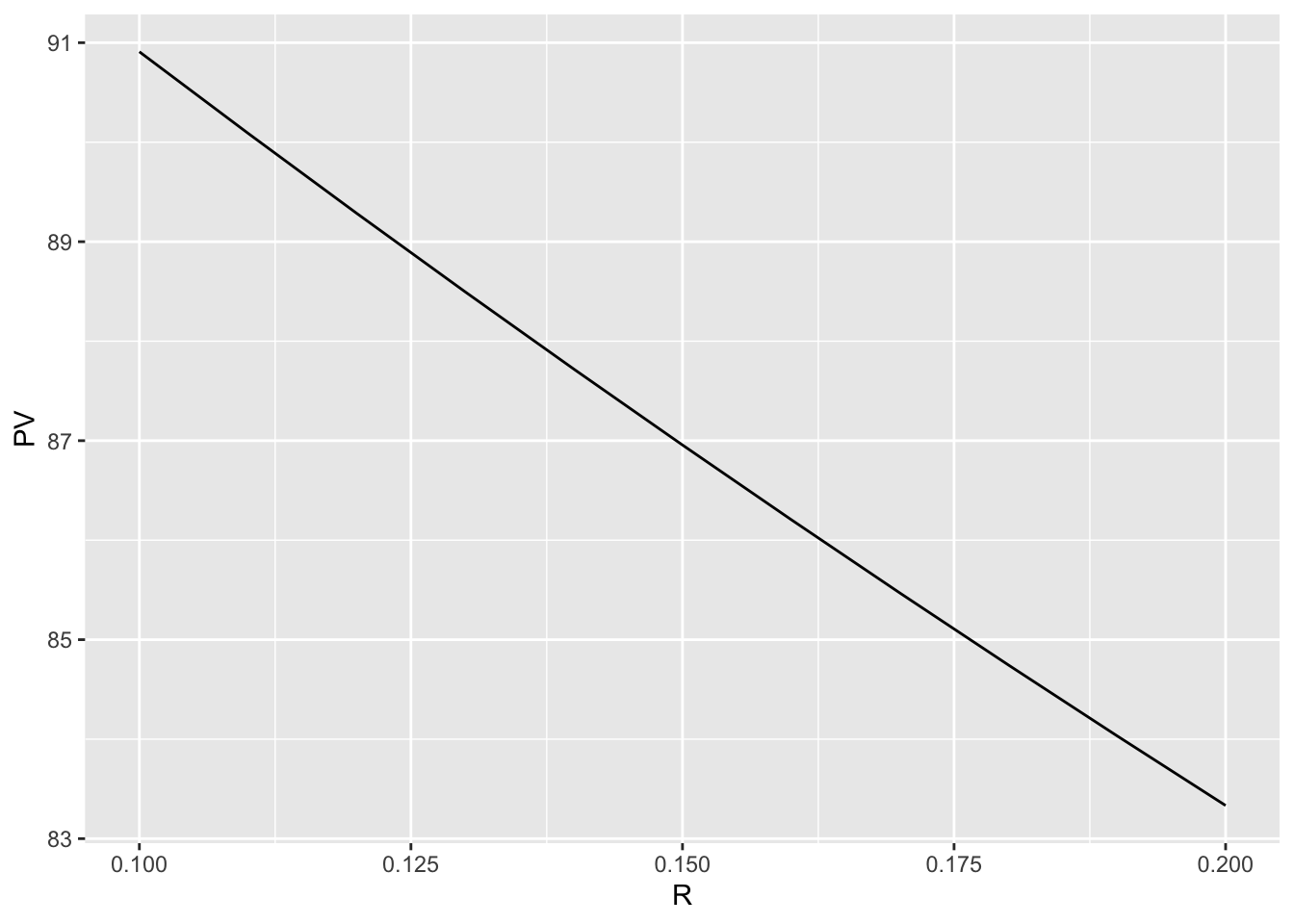
ggplot2による作図 — 散布図の追加ggplot2の使い方に慣れるために,先ほどの折れ線グラフに各データを表す点を追加してみよう.geom_point()であるから,+演算子を用いてそれを先ほどのコードに追加すると,散布図が上書きされる.pacman::p_load(tidyverse)
ggplot(data = figure_data) +
geom_line(mapping = aes(x = R, y = PV)) +
geom_point(mapping = aes(x = R, y = PV)) # 点グラフを追加
ggplot2による作図 — その他の調整Discount RateとPresent Valueへと変更しよう.labs()関数を使えば簡単にできる.pacman::p_load(tidyverse)
ggplot(data = figure_data) +
geom_line(mapping = aes(x = R, y = PV)) +
geom_point(mapping = aes(x = R, y = PV)) +
labs(x = "Discount Rate", y = "Present Value") + # labs()関数でラベル指定
theme_classic() # 全体的な体裁(テーマ)を設定
theme_classic()関数は,グラフの背景や枠線など(グラフのテーマと言う)を統一的に変更するための関数である.theme_void()や,背景は白だがメモリを表す十字線が入るtheme_bw()など,複数の選択肢があるので,目的に応じて使い分けると良いだろう.完全に無リスクの資産は存在しないが,実務的には国債金利を無リスク金利のベンチマークとすることが標準的である.↩︎