3 tidyverseパッケージを利用した財務データ分析入門
2024-04-26
1.3 エラーへの対処

- このエラーが表示された場合,まずはダウンロードしたファイルの名前が
ch03_daily_stock_return.csvから変更されていないことを確認しよう.繰り返し同じファイルをダウンロードしているとch03_daily_stock_return(1).csvのように,勝手に名前が変更されてしまう場合がある. - ファイル名の一致を確認した上で上記のエラーが表示され続ける場合,このCSVファイルが作業ディレクトリに位置していない可能性が高い.まずはこのCSVファイルが位置する場所(デスクトップなど)を確認した上で,Rの作業ディレクトリをその場所へと変更してみよう.RStudioを使っている場合,上部のタブのうち[Session] \(\rightarrow\) [Set Working Directory] \(\rightarrow\) [Choose Directory]で作業ディレクトリを指定するのが最も簡単である.
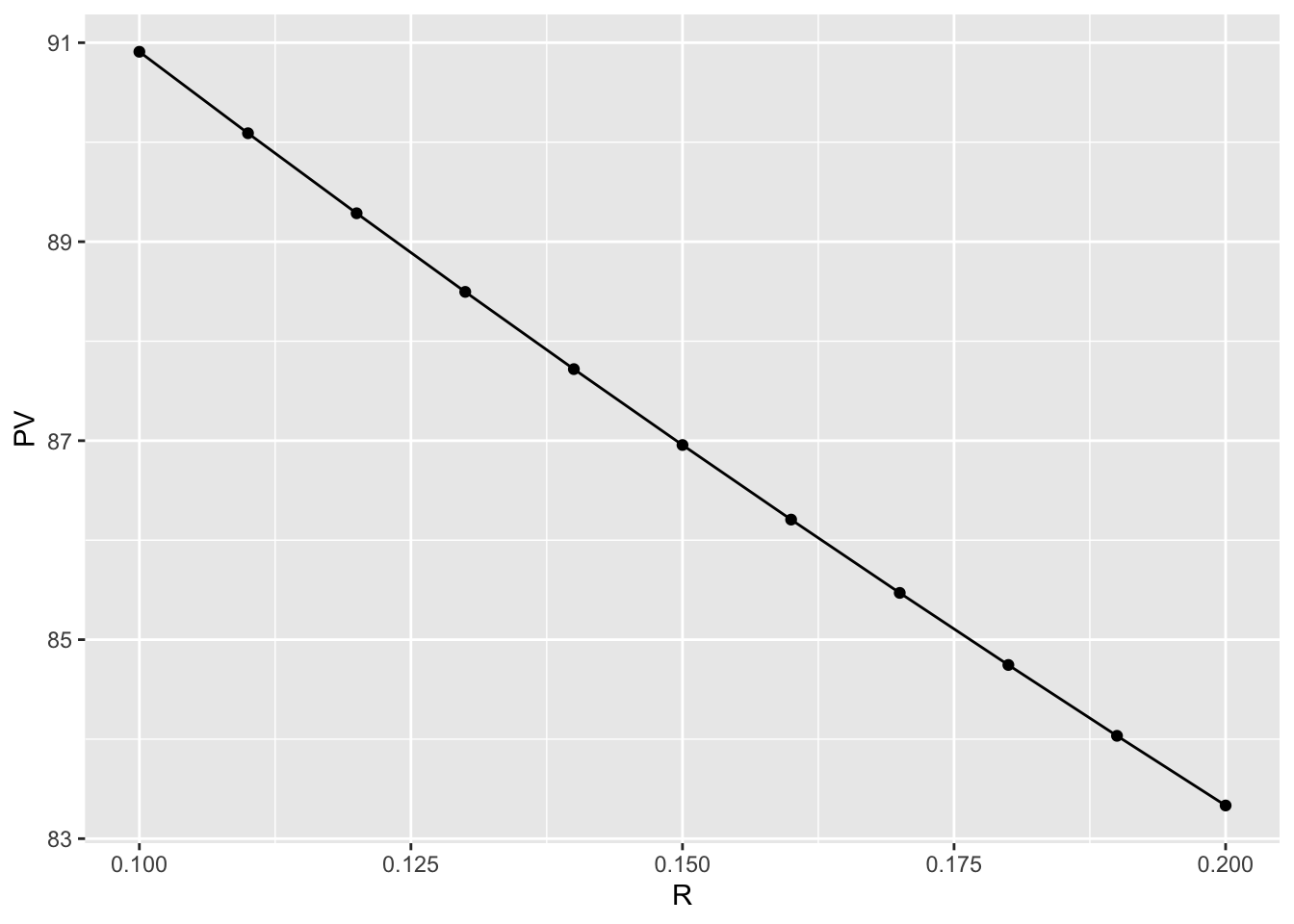
3.5 無リスク金利と現在価値の関係
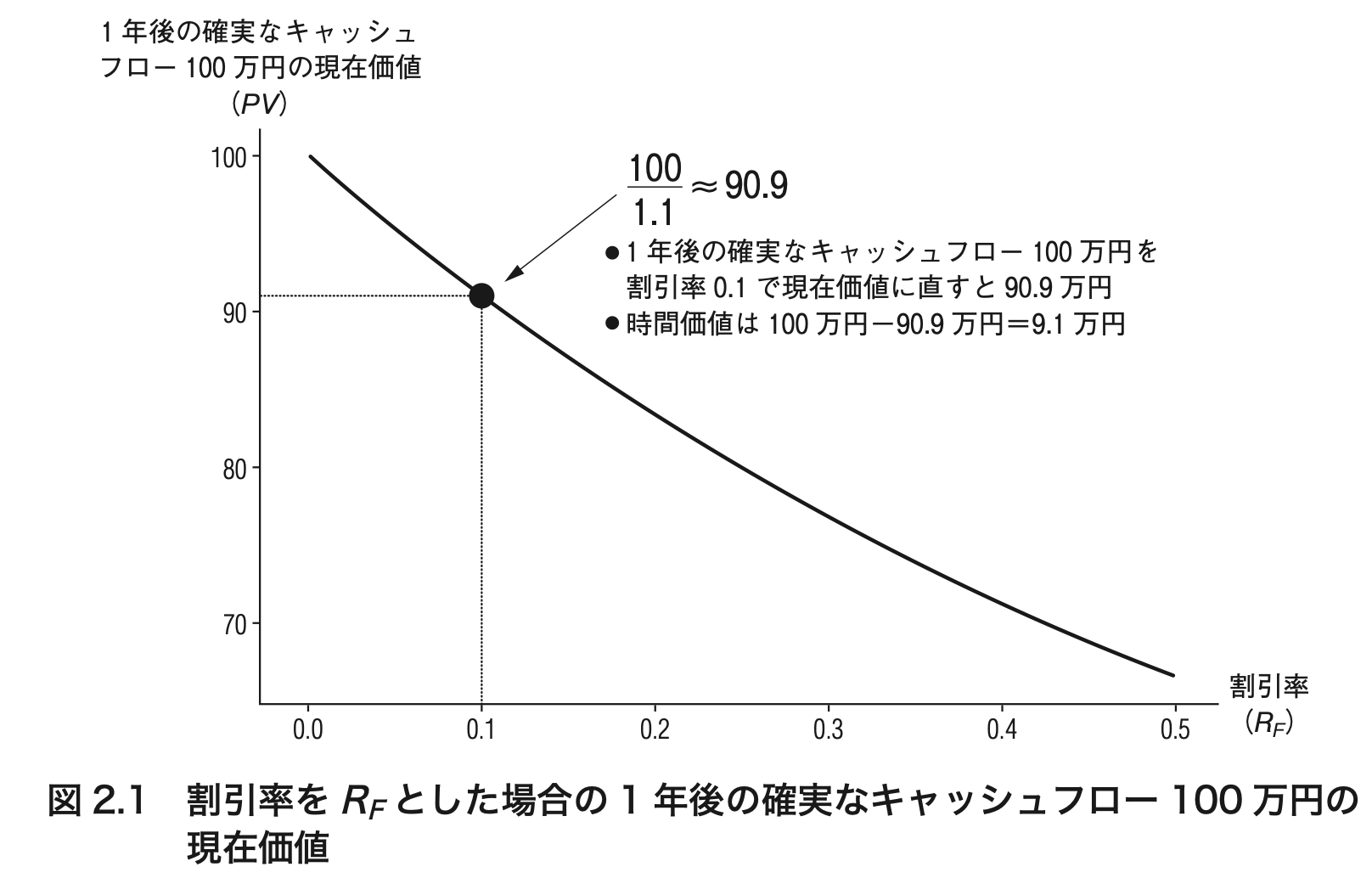
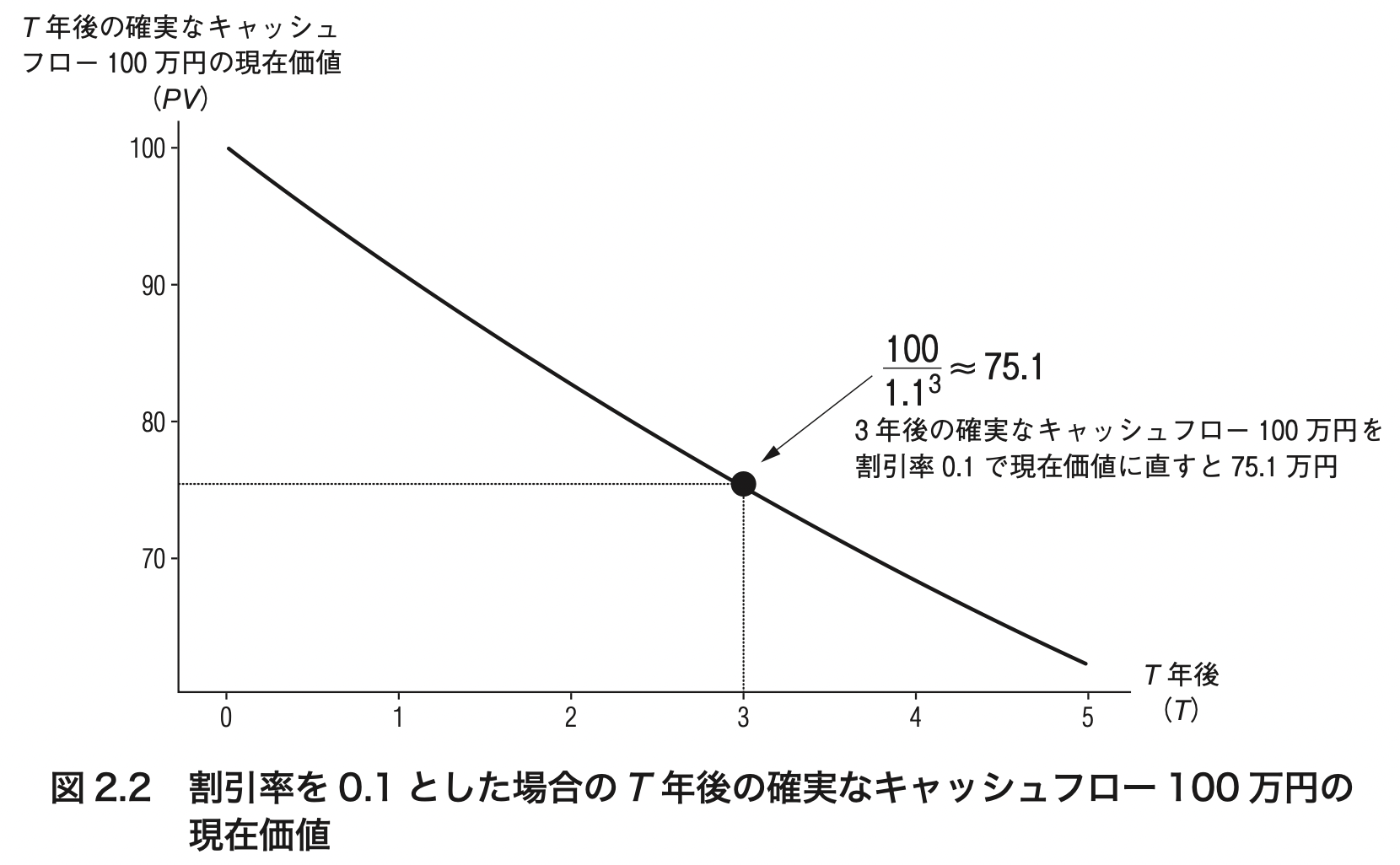
3.7 キャッシュフローの発生年限と現在価値の関係
4.4 ブロードキャスティング
- R言語はブロードキャスティング (broadcasting)といって,片方の次元を整数倍して次元を自動的に揃える機能を持つ.
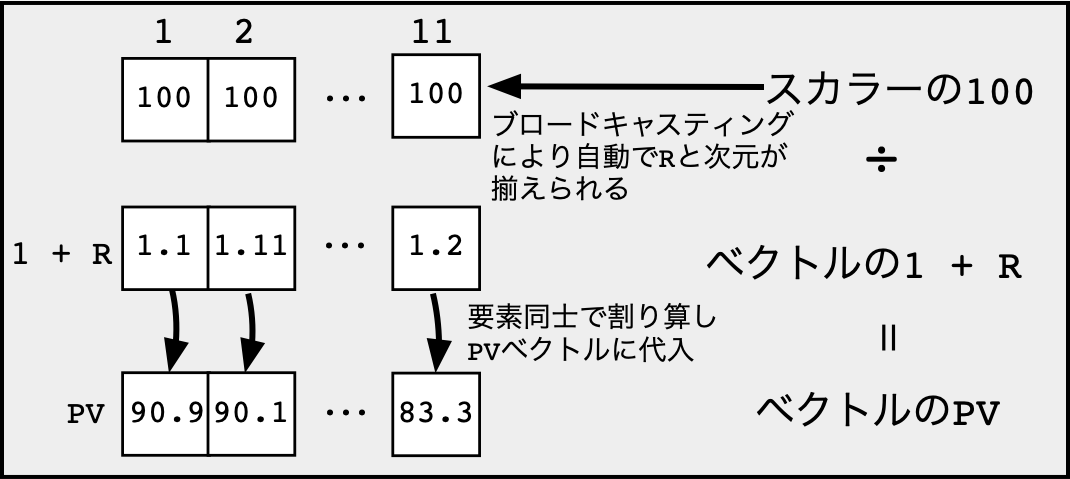
ブロードキャスティングのイメージ
4.7 ggplot2による作図 — data引数の指定
- 次は,
ggplot()関数により,作図用キャンバスを準備し,入力データを指定. - 引数では
data = figure_dataとして,figure_dataを入力用データとして用いることを宣言している.

- あとは,
+演算子を用いてレイヤーを足していく形で図を作成する. - グラフの中心となる折れ線グラフを追加しているのが,
geom_line()関数である. mapping引数のaes()関数では,\(x\)軸と\(y\)軸の要素をラベル名で指定している.
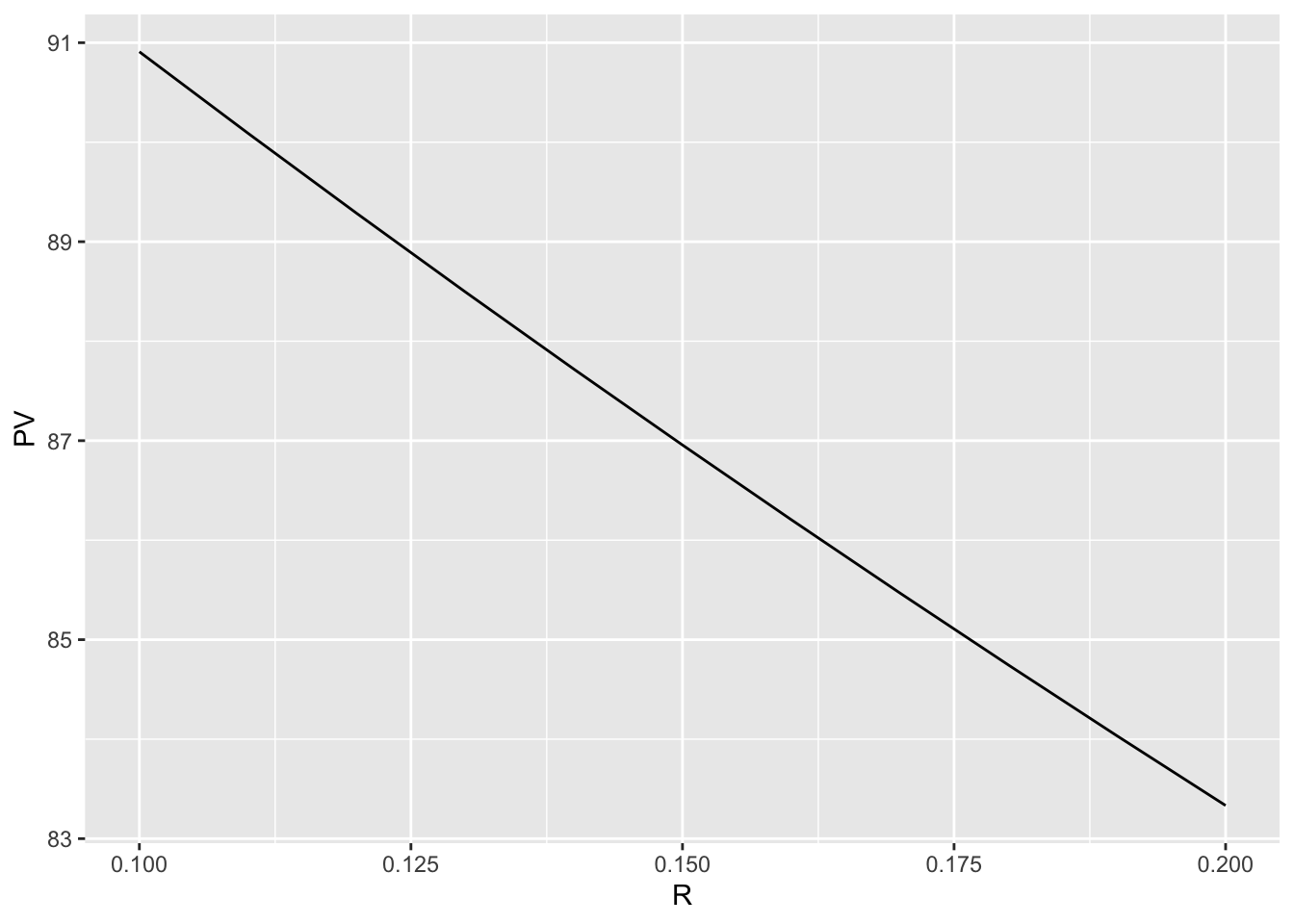
4.8 ggplot2による作図 — 散布図の追加
ggplot2の使い方に慣れるために,先ほどの折れ線グラフに各データを表す点を追加してみよう.- 散布図を追加する関数は
geom_point()であるから,+演算子を用いてそれを先ほどのコードに追加すると,散布図が上書きされる.
4.9 ggplot2による作図 — その他の調整
- 続いて,グラフの見栄えを微調整しよう.まず,\(x\)軸と\(y\)軸のラベルをそれぞれ
Discount RateとPresent Valueへと変更しよう. - ラベルの変更は,
labs()関数を使えば簡単にできる.
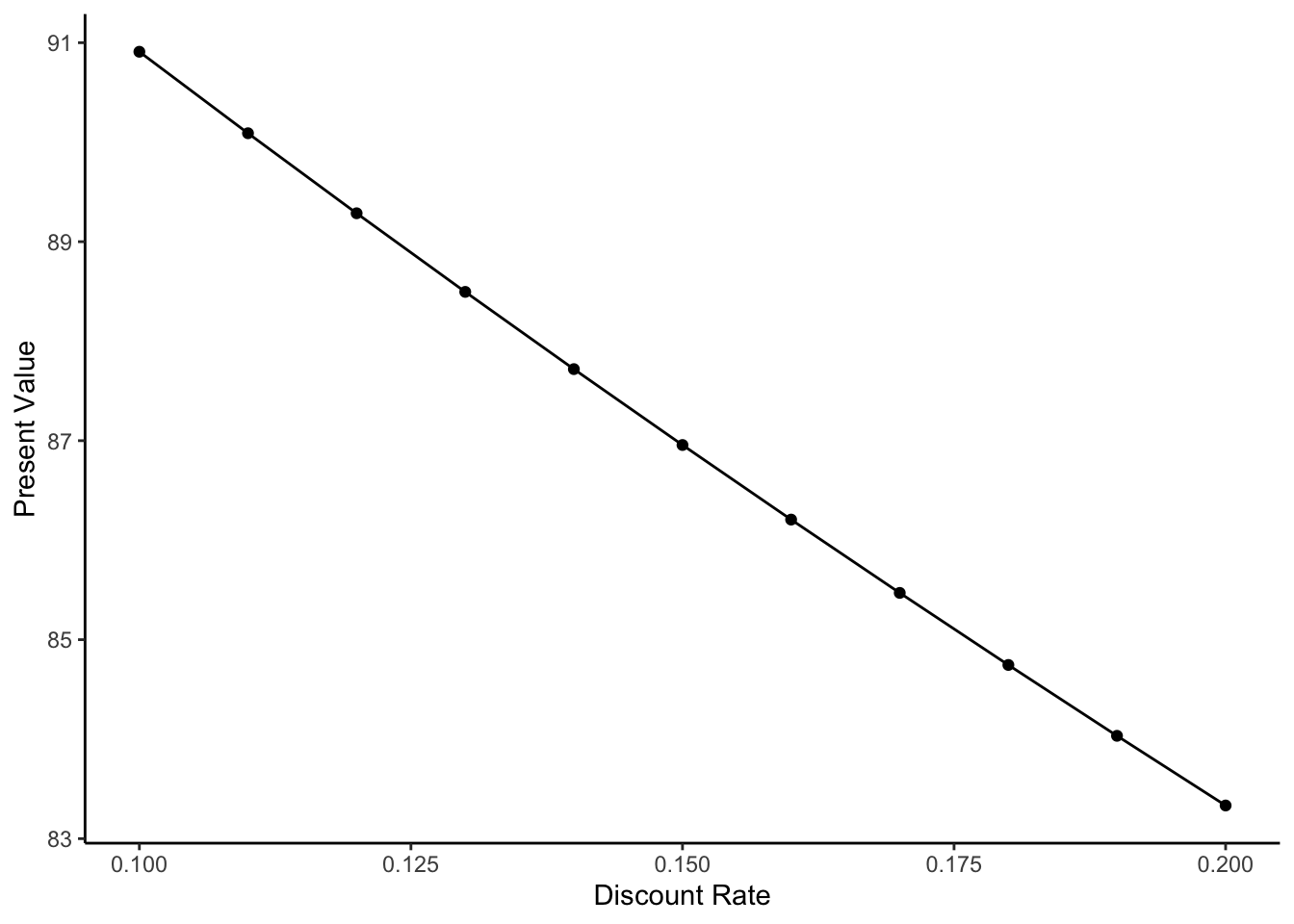
- 最後に加えた
theme_classic()関数は,グラフの背景や枠線など(グラフのテーマと言う)を統一的に変更するための関数である. - グラフのテーマは他にも多数用意されており,枠線を無くす
theme_void()や,背景は白だがメモリを表す十字線が入るtheme_bw()など,複数の選択肢があるので,目的に応じて使い分けると良いだろう.