---
title: "5 利益分布アプローチによる利益マネジメントの実態分析"
date: 2026/05/08
format:
html: default
revealjs:
output-file: 5_earnings_slide.html
---
## この回で新たに学ぶ関数 {data-name="この回の見取り図"}
今回はデータフレームの結合から統計量の集計,ヒストグラムの描画・保存まで一気に行う.新しく登場する関数が多いので,まずは全体像を把握しておこう.
| 関数 | パッケージ | 役割 |
|---|---|---|
| `full_join()` / `inner_join()` / `left_join()` | `dplyr` | 二つのデータフレームを結合する |
| `if_else()` | `dplyr` | 条件に応じて異なる値を返す |
| `quantile()` | base R | 分位点(四分位など)を求める |
| `round()` | base R | 数値を指定した桁数で丸める |
| `across()` + `where()` | `dplyr` | 複数列に同じ処理を一括適用する |
| `write_csv()` | `readr` | データフレームをCSVファイルに出力する |
| `seq()` | base R | 等差数列を生成する |
| `geom_histogram()` | `ggplot2` | ヒストグラムを描画する |
| `geom_vline()` | `ggplot2` | グラフに垂直線を追加する |
| `ggsave()` | `ggplot2` | 直前に描画したグラフをファイルに保存する |
| `lag()` | `dplyr` | 一つ前の行の値を取得する(練習問題) |
- 前回までに学んだ`mutate()`,`group_by()`,`summarize()`,`drop_na()`なども引き続き使用する.
- 迷ったらこの表に戻って「今どの関数を使っているのか」を確認しよう.
------------------------------------------------------------------------
## `join`系関数(教科書コラム5.2)
### 二つのデータフレームの結合
- 実証会計・ファイナンスでは,財務データと株式データの結合を典型例として,二つのデータフレームを結合する場面にしばしば遭遇する.
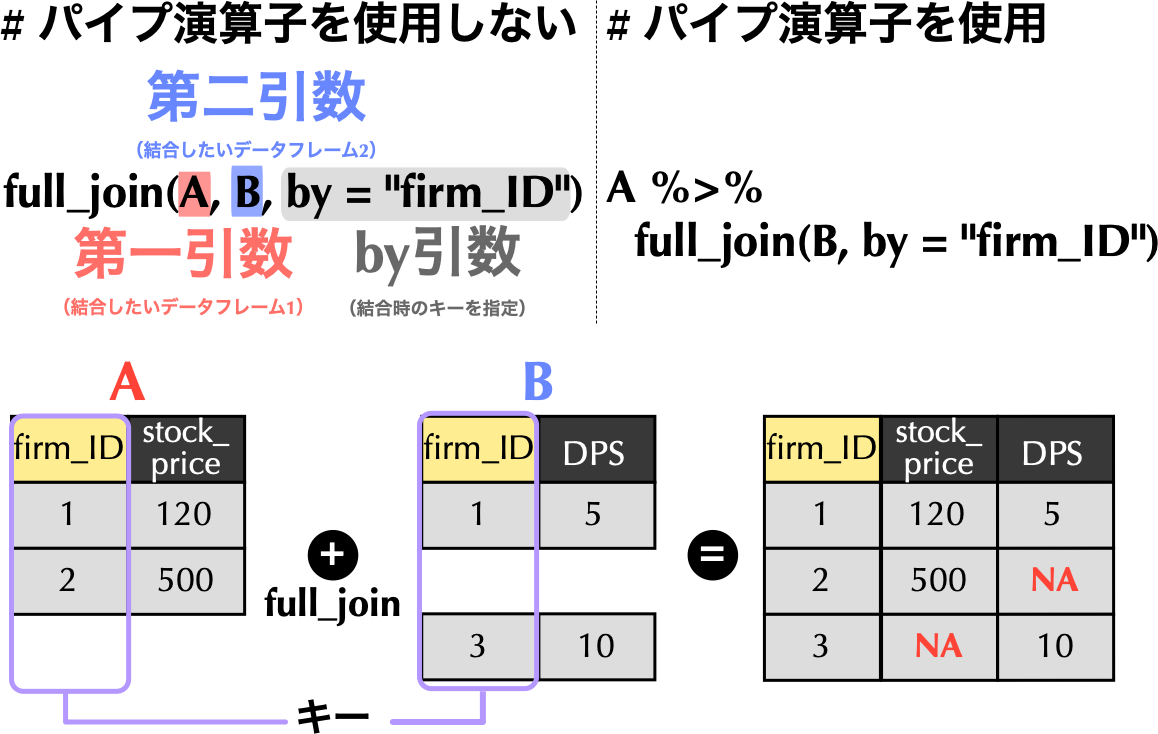
- `dplyr`には`full_join()`関数を始め,結合を行うために用いる`join`系関数が用意されている.
- 以下では,**株価データ`A`とDPSデータ`B`**の結合を通じて,それぞれの`join`系関数の返り値を確認していこう.
```{r}
# tidyverseの読み込み
pacman::p_load(tidyverse)
# 例に用いる二つのデータフレームを作成
A <- tibble(firm_ID = c(1, 2),
stock_price = c(120, 500)) # 株価データが格納されたAを作成
B <- tibble(firm_ID = c(1, 3),
DPS = c(5, 10)) # DPSデータが格納されたBを作成
```
- 上のコードでは,`tibble()`関数を使って二つのデータフレームを手動で作成している.
------------------------------------------------------------------------
### 完全外部結合`full_join()関数`
{width="75%"}
------------------------------------------------------------------------
### 内部結合`inner_join()`関数
```{r}
# inner_join()関数による結合
A %>% inner_join(B, by = "firm_ID")
```
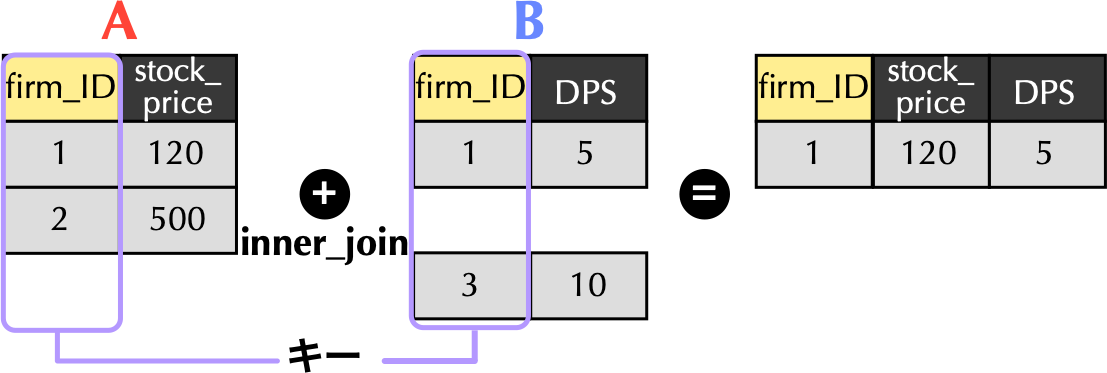{width="80%"}
------------------------------------------------------------------------
### 左結合`left_join()`関数
```{r}
# left_join()関数による結合
A %>% left_join(B, by = "firm_ID")
```
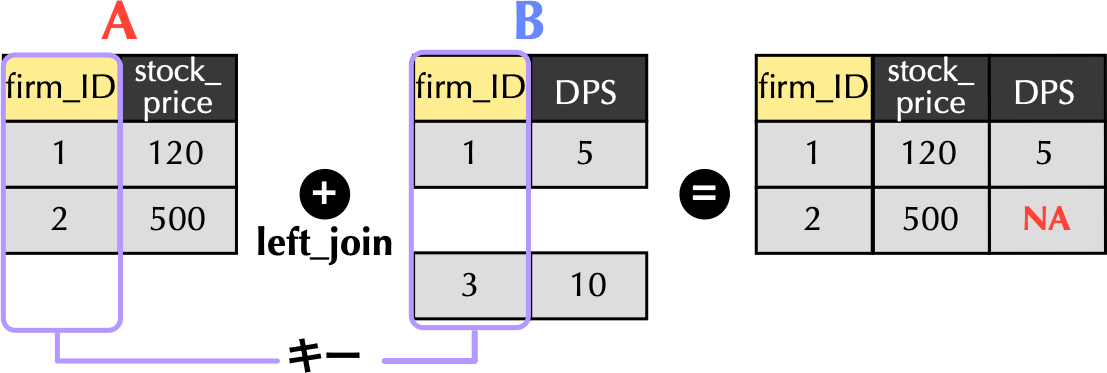{width="80%"}
## 分布の不連続性(教科書コラム5.3)
### 成績評価チート
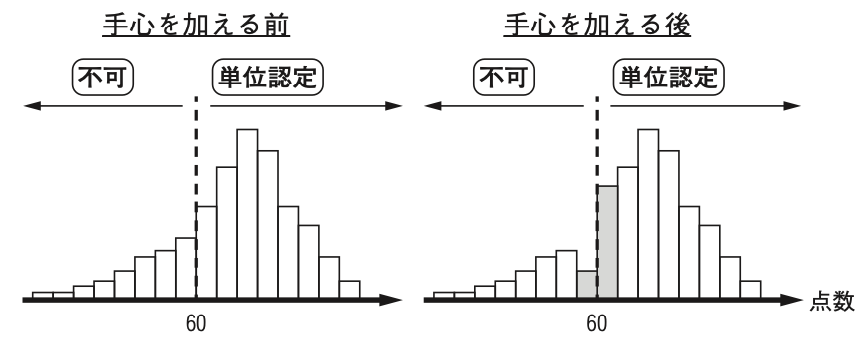{width="80%"}
------------------------------------------------------------------------
### その他の例
::::: columns
::: {.column width="50%"}
- 大相撲の勝ち星 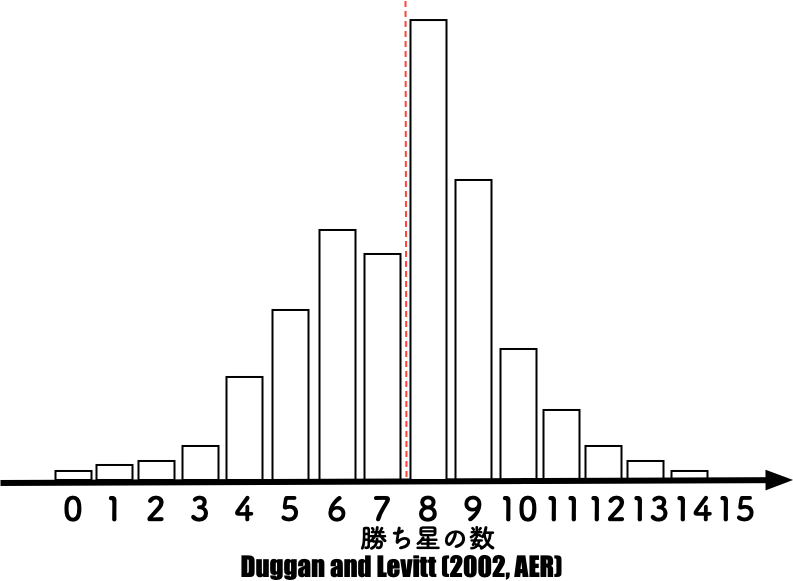{fig-align="center"}
:::
::: {.column width="50%"}
- 食べログ3.6問題 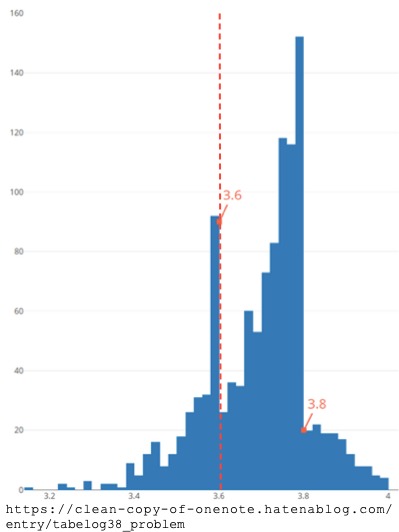{fig-align="center"}
:::
:::::
------------------------------------------------------------------------
## 分析の準備
### 財務データの読み込み
- 会計利益の分布に果たして歪みがあるかを検証を進めるため,まずは分析に利用する財務データを読み込むことから始めよう.
::: {.callout-note icon="false"}
#### 目標
- [**目標1:**]{style="color: blue"} `simulation_data`フォルダにある`financial_data.csv`をデータフレーム`financial_data`として読み込んでみよう.
- [**目標2:**]{style="color: blue"} その後,`head()`関数により,`financial_data`の冒頭6行を表示し,どのようなデータが収録されているか確認してみよう.
:::
------------------------------------------------------------------------
### フォルダ構造
- 現在地が`codes`である場合,読み込みたい`financial_data.csv`が格納されている`simulation_data`フォルダにアクセスするには,[**一個上の階層に一度戻る必要があり,それは`..`により実現可能**]{style="color: blue"}である.
- あとは,`simulation_data`フォルダに移動 (`/simulation_data`)し,`/financial_data.csv`で目的のファイルにアクセス可能である.
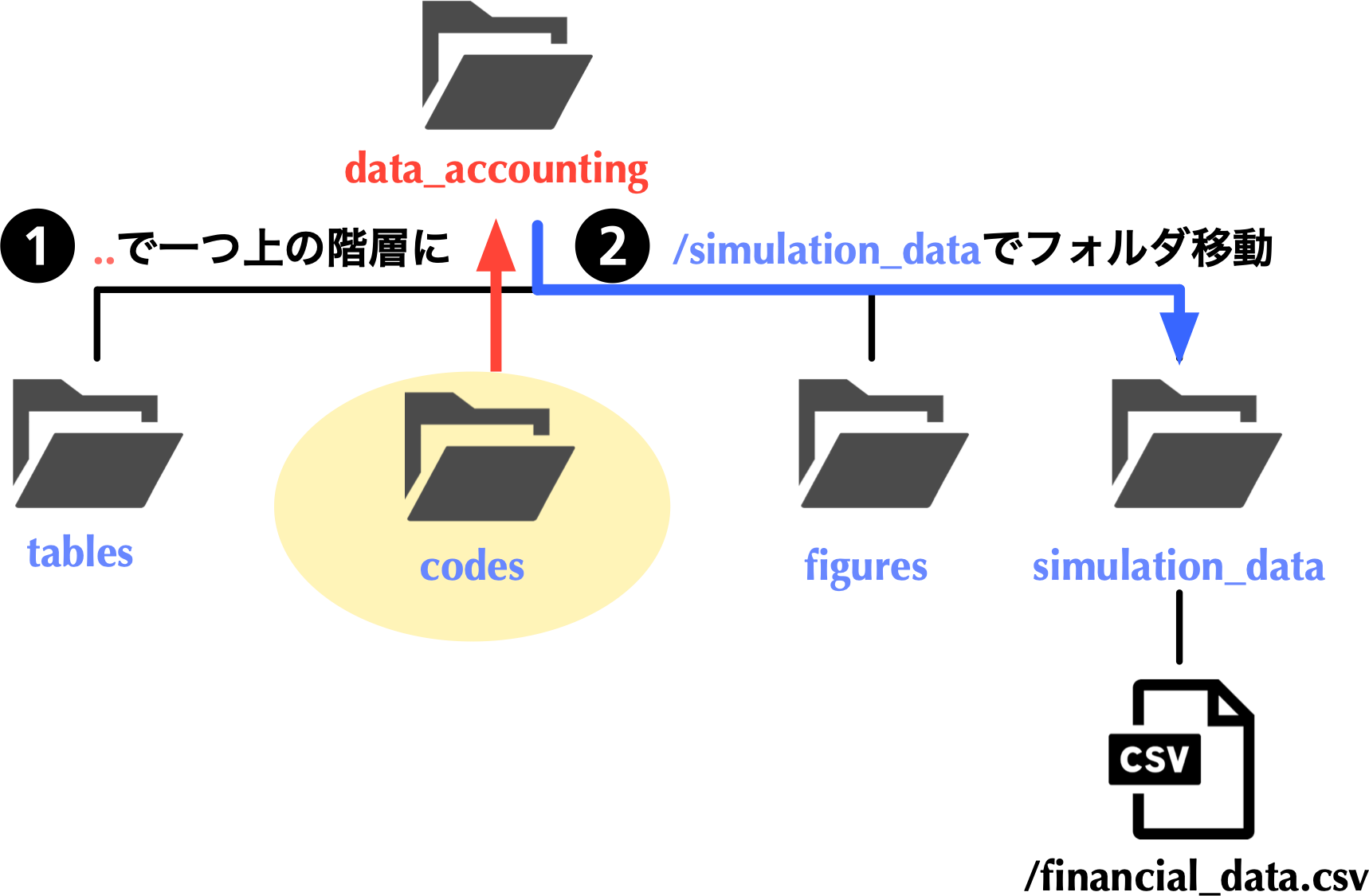{width="80%"}
------------------------------------------------------------------------
### 目標を達成するためのコード例
```{r}
# 財務データの読み込み
financial_data <- read_csv("../simulation_data/financial_data.csv")
# head()関数を用いて冒頭6行の結果のみ表示
head(financial_data)
```
::::: columns
::: {.column width="50%"}
- `fiscal_year_end`: 決算年月 (YYYY-MM-DD形式)
- `macc`: 決算月数
- `X`: 当期純利益(百万円)
:::
::: {.column width="50%"}
- `TA`: 資産合計(百万円)
- `CFO`: 営業活動によるキャッシュフロー(百万円)
:::
:::::
------------------------------------------------------------------------
### 当期純利益`X`を基準化
- 分析にあたっては,当期純利益`X`そのものの分布ではなく,各企業の規模を統制して各観測値を[**横並びで比較可能にしたScaled Earnings (`SE`)の分布**]{style="color: blue"}を考えよう.
$$
\underbrace{SE_{i,t}}_{\textbf{企業$i$の年度$t$のScaled Earnings}} = \frac{\overbrace{X_{i,t}}^{\textbf{企業$i$の年度$t$の当期純利益}}}{\text{各企業の規模の代理変数}}
$$
- この分析では,簡便的に各企業の発行する[**株式の時価総額**]{style="color: red"} ($=$ 株価 $\times$ 発行済株式数)を規模の代理変数と捉え,分析を進めて行こう.
------------------------------------------------------------------------
### 株式データの読み込み
- Scaled Earningsのデフレータとなる時価総額を得るため,`simulation_data`フォルダにある`stock_data.csv`を`stock_data`として読み込んでみよう.
```{r}
# 株式データの読み込み
stock_data <- read_csv("../simulation_data/stock_data.csv")
head(stock_data)
```
- `stock_price`: 株価
- `shares_outstanding`: 発行済株式数
### `stock_data`に時価総額`ME`列の追加
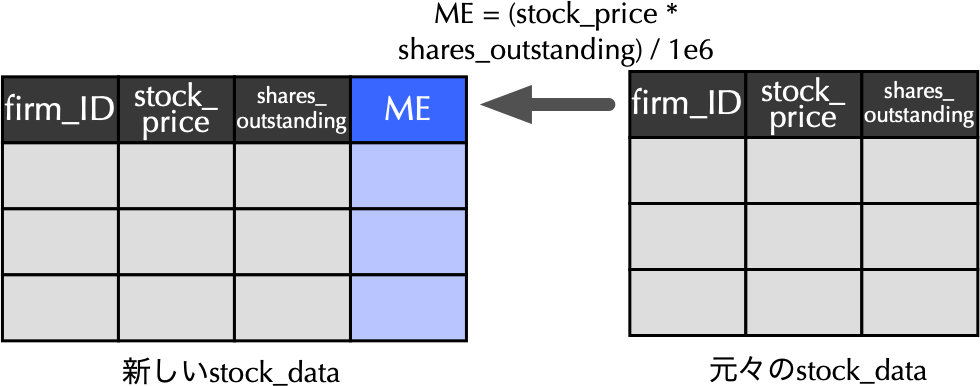{width="80%"}
```{r}
# mutate()関数を使ってME列の追加
stock_data <- stock_data %>%
mutate(ME = (stock_price * shares_outstanding) / 1e6) # MEを百万円単位で計算
```
------------------------------------------------------------------------
### 単位確認の重要性
- 先のコードで登場した`1e6`は科学技術分野で一般的に用いられる[**科学的表記**]{style="color: red"}と呼ばれる表記法[(教科書157頁)]{style="color: blue"}であり,$1 \times 10^6 (= 1,000,000)$と等しい.
- 会計・ファイナンス研究で頻用される[**財務データは,一般的に百万円単位でデータが収録**]{style="color: blue"}されているため,`ME`を計算する際,財務データと単位を揃えることを目的として`1e6`で除している.
- `(stock_price * shares_outstanding) / 1000000`とはしないこと!
------------------------------------------------------------------------
### 財務データと株式データの結合
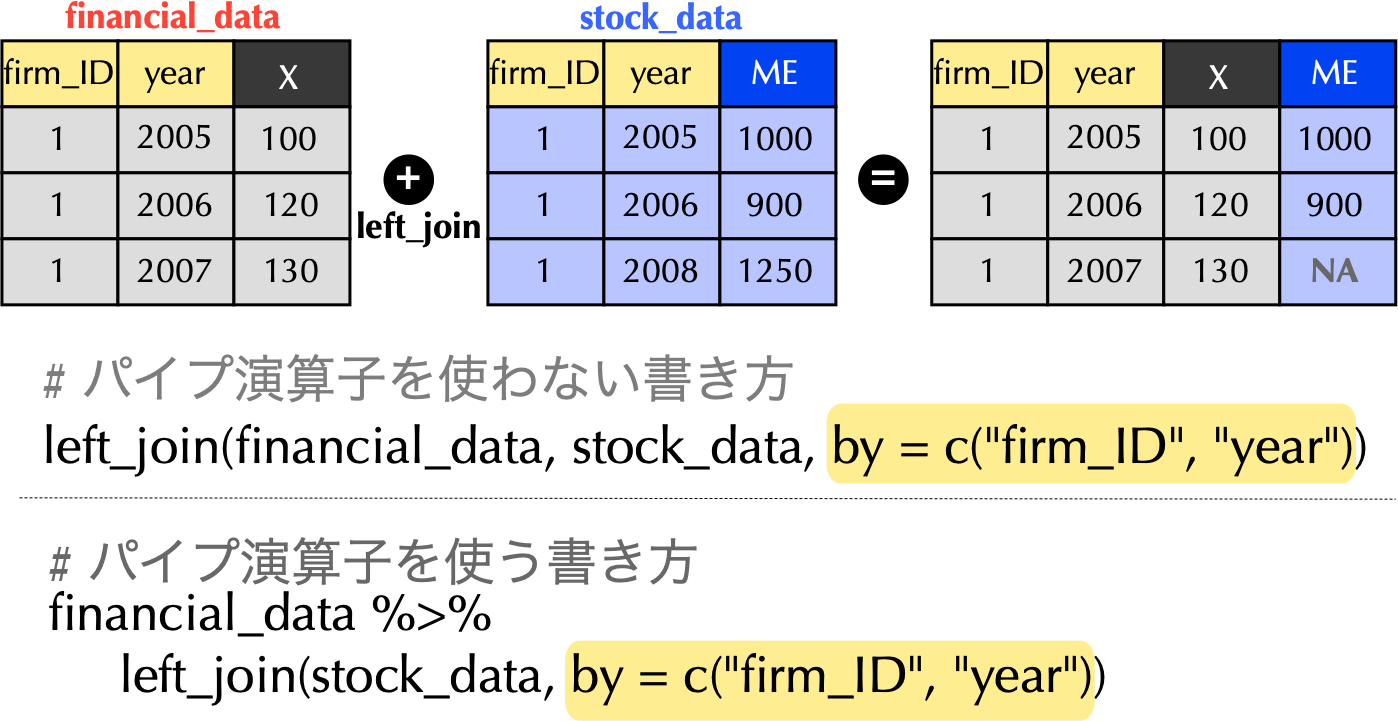{width="80%"}
------------------------------------------------------------------------
### パイプ演算子を繋げて`SE`列も追加
```{r}
# 財務データと株式データの結合し,SE列も追加
financial_data <- financial_data %>%
left_join(stock_data, by = c("firm_ID", "year")) %>%
mutate(SE = if_else(macc == 12, X / ME, NA))
# 決算月数が12ヶ月ではないものは欠損値に
```
- 上のコードでは,`dplyr`の`if_else()`関数を使って決算月数が12ヶ月の場合は`SE`を計算し,そうでなければ欠損値`NA`になるように工夫している.
{width="80%"}
------------------------------------------------------------------------
## 利益分布アプローチによる分析
### サンプルの確定
- データの前処理が完了すれば,分析対象を確定させ,新たなデータフレーム`analysis_sample`を利用して分析を進めて行こう.
::: {.callout-note icon="false"}
#### 目標
- ここでは,`SE`が欠損値となっている観測値を除外($=$ `SE`が計算可能な観測値のみを抽出)し,分析対象となるデータフレームを`analysis_sample`として定義してみよう.
:::
------------------------------------------------------------------------
### 目標を達成するためのコード例
```{r}
# 分析に利用する観測値のみのデータフレームanalysis_sampleを作成
analysis_sample <- financial_data %>%
drop_na(SE) # SEが欠損値のものを削除
```
- `drop_na()`の使い方は,[ここ](4_data.html#drop_na_exp)を参照.
------------------------------------------------------------------------
### 集計作業の実践 --- `summarize()`関数を使ってみよう
::: {.callout-note icon="false"}
#### 目標
- データフレーム`analysis_sample`を用いて,年度ごとに`SE`の平均値を算出し,それを`Mean`列と名付けよう.
- こうして出来た`year`列と`Mean`列から成るデータフレームを`table_1`として定義しよう.
:::
------------------------------------------------------------------------
### 目標を達成するためのコード例
```{r}
# 年度ごとにSEの平均値を計算
table_1 <- analysis_sample %>% # 集計結果をtable_1として定義
group_by(year) %>% # 年度でグループ化
summarize(Mean = mean(SE)) # 平均値をMeanと命名
head(table_1) # 内容の確認
```
- [**2行目:**]{style="color: blue"} 以下の処理により作成されるデータフレームを`table_1`として定義.
- [**3行目:**]{style="color: blue"} 年度`year`でグループ化.
- [**4行目:**]{style="color: blue"} `summarize`関数を適用し,`SE`の平均値を`mean(SE)`により計算し,それを`Mean`と命名.
------------------------------------------------------------------------
### 更に一歩進んで,年度ごとに基本統計量を集計
```{r}
# 年度ごとに基本統計量を集計
table_1 <- analysis_sample %>%
group_by(year) %>% # 年度毎にグループ化
summarize(N = n(), # 観測値数
Mean = mean(SE), # 平均値
SD = sd(SE), # 標準偏差
Q1 = quantile(SE, 0.25), # 第1四分位
Median = median(SE), # 中央値
Q3 = quantile(SE ,0.75)) # 第3四分位
```
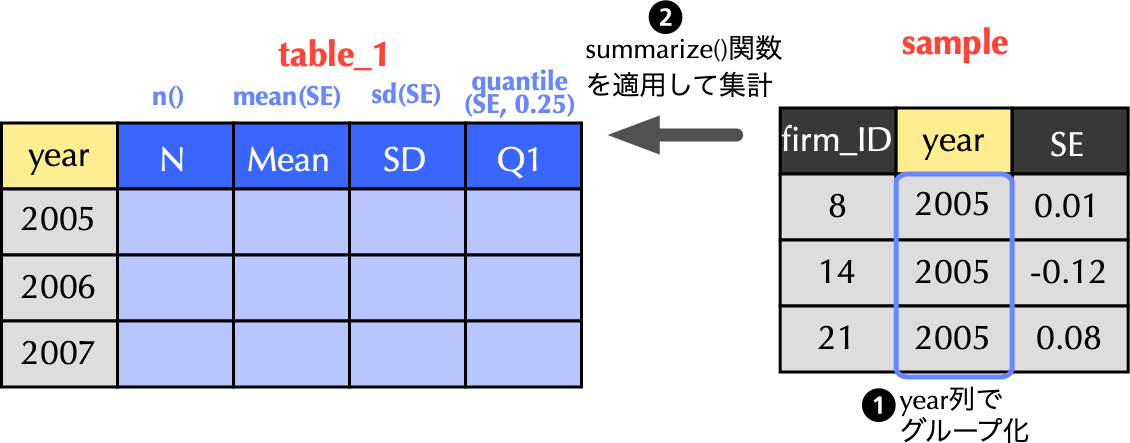{width="80%"}
------------------------------------------------------------------------
### `quantile()`関数の使い方
- 分位点を求めるには`quantile()`関数を用いる.この関数は第一引数に入力データ(数値ベクトル),第二引数に求めたい分位点の値をパーセントでなく[**小数表示**]{style="color: red"}で代入する[(教科書185頁)]{style="color: purple"}.
- 例えば,`SE`の第1四分位を求めたいならば,`quantile(SE, 0.25)`とすれば良い.
{width="80%"}
------------------------------------------------------------------------
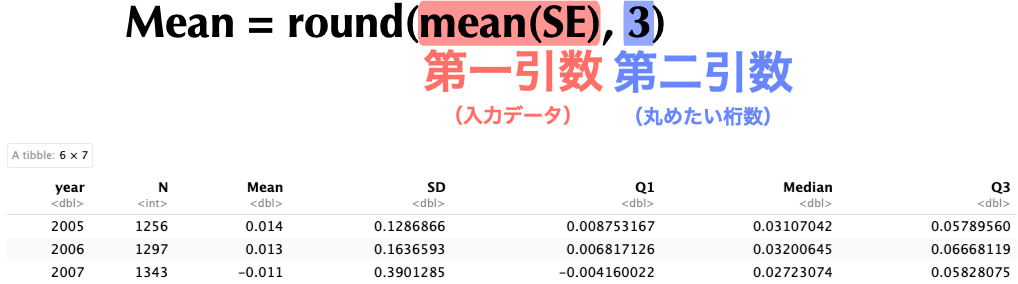
### 出力結果のアレンジ --- 桁数の調整
```{r}
#| code-line-numbers: "5"
# 年度ごとに基本統計量を集計(平均値のみ桁数調整)
table_1 <- analysis_sample %>%
group_by(year) %>% # 年度毎にグループ化
summarize(N = n(), # 観測値数
Mean = round(mean(SE), 3), # 平均値
SD = sd(SE), # 標準偏差
Q1 = quantile(SE, 0.25), # 第1四分位
Median = median(SE), # 中央値
Q3 = quantile(SE, 0.75)) # 第3四分位
```
{width="80%"}
------------------------------------------------------------------------
### 一気に出力結果を調整する方法
```{r}
# table_1の数値列を小数点第3位まで丸め直す
table_1 <- table_1 %>%
mutate(across(where(is.double), ~ round(.x, 3)))
head(table_1)
```
- `across()` は「複数の列に対して同じ処理を一括で適用する」ための関数である.
- `where(is.double)` は「小数を含む数値型`<dbl>`の列をすべて選択する」という意味である.このため,整数型`<int>`の`N`列は対象にならず,平均`Mean`や標準偏差`SD`などの列だけが処理される.
- `~ round(.x, 3)` の部分は「無名関数(ラムダ関数)」と呼ばれる書き方である.
- `~` の後に書いた式が「その列に対してやる処理」を表している.
- `.x` は「今処理している列の値」を指している(このように一時的に処理対象を表す記号を**プレースホルダー**という).
- ここでは「`across()`関数で指定された各列を小数点第3位まで丸める」という意味になる.
------------------------------------------------------------------------
### `write_csv()`関数を使ったデータフレームの出力
```{r}
# table_1の結果を出力
write_csv(table_1, "../tables/table_1.csv")
```
- `readr`の`write_csv()`関数を使って,先に作成したデータフレーム`table_1`を`tables`フォルダに出力しよう.
- `write_csv()`関数の第一引数はデータフレーム名を入力し,第二引数でファイル名を指定する[(教科書184頁)]{style="color: purple"}.
- 現在地が`codes`であることを前提にすれば,出力したい`tables`フォルダへ移動するには,[**一個上の階層に一度戻る必要があり,それは`..`により実現可能**]{style="color: blue"}である.
- あとは,`tables`フォルダに移動 (`/tables`)し,`table_1.csv`という名前で出力 (`/table_1.csv`)すれば良いので,`write_csv()`関数の第二引数は,`"../tables/table_1.csv"`と指定する.
------------------------------------------------------------------------
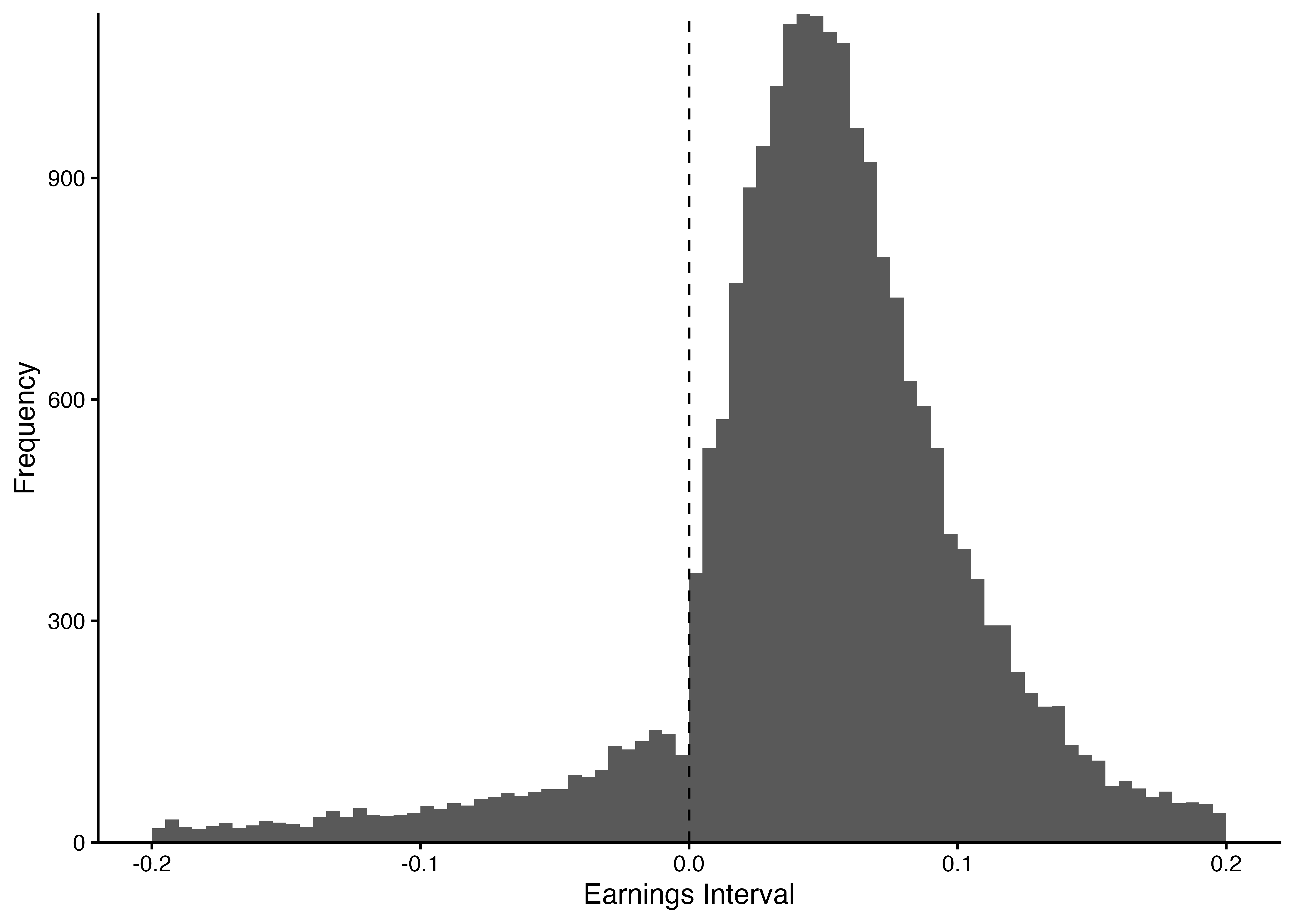
### Scaled Earnings (`SE`)のヒストグラム
- 締めくくりとして,`ggplot2`を利用し,Scaled Earnings (`SE`)のヒストグラムを描画し,利益マネジメントの実態を明らかにしていこう.
::: {.callout-note icon="false"}
#### 目標
- データフレーム`analysis_sample`内の`SE`について,-0.2から0.2までの`SE`のヒストグラムを描画しよう.
- ビン幅は0.005とする.
- $x$軸のラベルは`Earnings Interval`,$y$軸のラベルは`Frequency`とする.
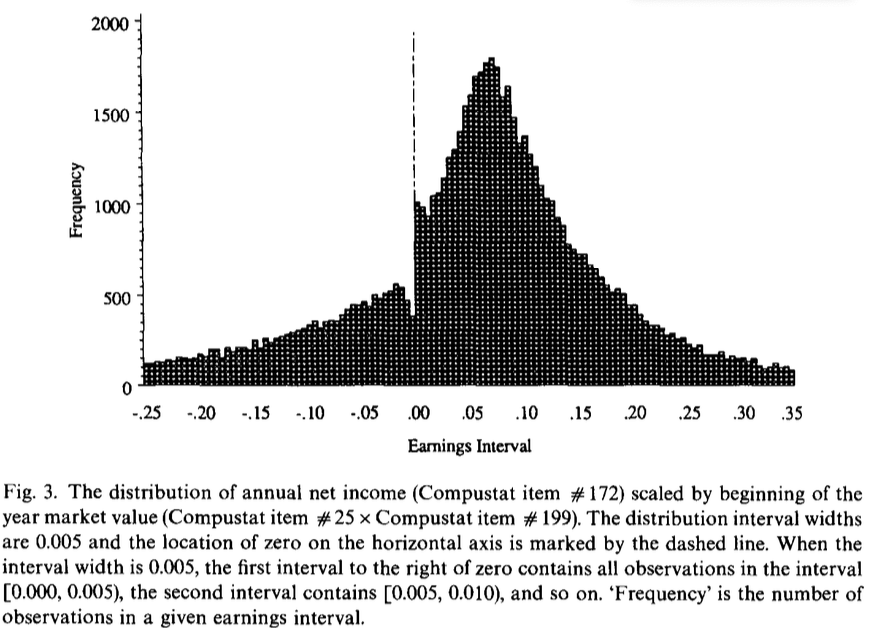
- (余力がある人は)Burgstahler and Dichev (1997)同様,$x = 0$の破線を引き,ベンチマークが一目瞭然で分かるように調整.
:::
------------------------------------------------------------------------
### オリジナル論文のヒストグラム (Fig. 3)
{fig-align="center"}
### `SE`のヒストグラムの描画
```{r}
# SEのヒストグラムの描画
ggplot(analysis_sample) +
geom_histogram(aes(x = SE),
breaks = seq(-0.2, 0.2, 0.005)) +
labs(x = "Earnings Interval", y = "Frequency") +
scale_y_continuous(expand = c(0, 0)) +
theme_classic()
```
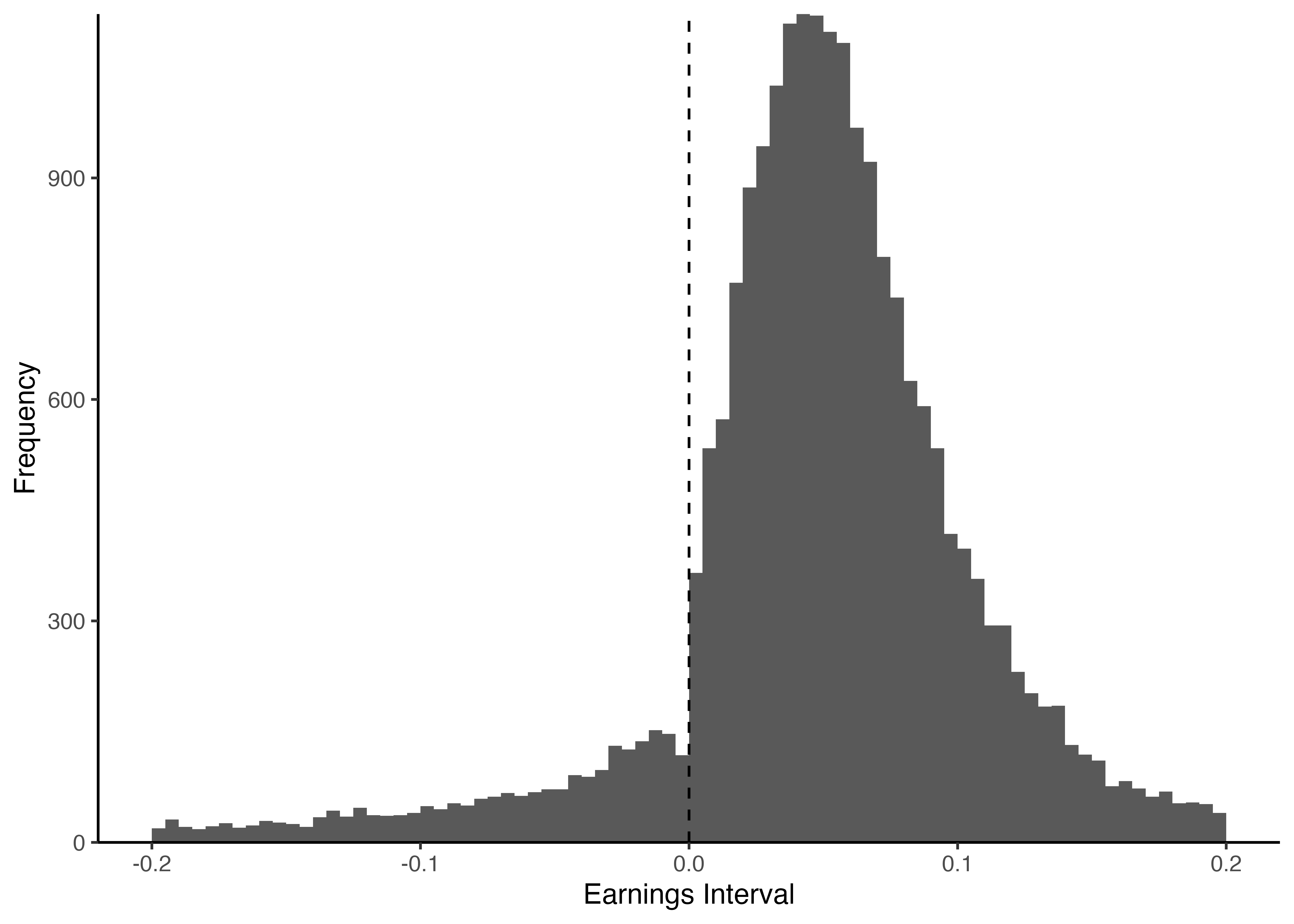
### $x = 0$を表す破線の追加
- `geom_vline()`関数は,vertical(垂直)に直線を引く.`xintercept`引数で値を指定し,また`linetype`引数で適当な線種を指定する(`dashed`の他にも,`dotted`や`solid`など多様にオプションが用意されている).
```{r}
#| code-line-numbers: "7"
# SEのヒストグラムの描画
ggplot(analysis_sample) +
geom_histogram(aes(x = SE),
breaks = seq(-0.2, 0.2, 0.005)) +
labs(x = "Earnings Interval", y = "Frequency") +
scale_y_continuous(expand = c(0, 0)) +
geom_vline(xintercept = 0, linetype = "dashed") +
theme_classic()
```
### 完成したグラフを`PNG`形式で出力
::: {.callout-note icon="false"}
#### 目標
- こうして描画されたヒストグラムを`figures`フォルダに`figure_1.png`の名前を付して出力しよう.
:::
- **(ヒント1)** 直前に出力したグラフを保存したい場合,`ggsave()`関数を利用する.第一引数にはファイル名を指定しよう.
- **(ヒント2)** `figures`フォルダのある階層を意識して第一引数を指定しよう.
### 目標を達成するためのコード例
```{r}
# ggsave()関数を使ってSEのヒストグラムをfigure_1.pngとして出力
ggsave("../figures/figure_1.png")
```
- 必要に応じてグラフのサイズなどの細部を調整したい場合は,別途引数により調整すれば良い.
```{r}
# 出力サイズを明示的に指定して出力
ggsave("../figures/figure_1.png",
width = 20, # 幅を指定
height = 10, # 高さを指定
units = "cm") # 幅と高さの単位を指定
```
## 練習問題
### 損失回避期間と利益マネジメントのインセンティブ
- Burgstahler and Dichev (1997)や首藤 (2010)[^1]では,過去において[**損失回避期間が長い企業の経営者**]{style="color: red"}ほど,損失を回避するインセンティブが高まり,[**分布の歪みがより顕著**]{style="color: red"}に現れることが明らかにされている.
- ここでは,その検証結果の再現を試みる一環として,[**一期前の`SE`が正で少なくとも過去1期は損失回避できた企業群**]{style="color: blue"}だけに絞り,同様のヒストグラムを描画する方法を実践していこう.
### 前年度損失回避企業のみを抽出して描画
::: {.callout-note icon="false"}
#### Exercise
- [**目標1:**]{style="color: blue"} 最初に`mutate()`関数と`lag()`関数を組み合わせて,一期前の`SE`を表す`lagged_SE`をデータフレーム`analysis_sample`に追加しよう.
- (注意点1) パネルデータで`lag()`関数を使う場合は,[**必ず`group_by(firm_ID)`で企業ごとにグループ化してから**]{style="color: red"}適用すること.グループ化せずに`lag()`を使うと,異なる企業の前行の値を取得してしまう.
- (注意点2) [**一行前が必ずしも一期前とは限らない**]{style="color: red"}ため,`if_else()`関数を用いて`year`と`lag(year)`との関係を示す条件式を予め指定し,`lagged_SE`の計算式を工夫するのが理想的である.
- [**目標2:**]{style="color: blue"} `lagged_SE`列が追加できれば,前年度損失回避企業を`filter()`関数により抽出し,パイプ演算子を使って抽出データを`ggplot()`関数に引き渡して一気にヒストグラムの可視化まで行ってみよう.
:::
[^1]: 首藤昭信 (2010)『日本企業の利益調整: 理論と実証』中央経済社.
## 自習課題 {data-name="自習課題"}
- 以下の課題に取り組み,今回学んだ内容の理解度を自分で確認しよう.
- 課題では,講義で作成した`financial_data`,`stock_data`,および`analysis_sample`をそのまま使用する.
### 準備:自分だけの分析条件を生成する
- 以下のコードをRコンソールで実行しよう.`set.seed()`関数の引数には,**自分の学籍番号の末尾4桁の数字**(末尾の英字を除く)を入力すること.
```{r}
#| eval: false
# 自分の学籍番号の末尾4桁の数字を入力(例: 学籍番号が2001234Bの場合は1234)
set.seed(1234)
# 自分だけの分析条件を生成
my_year <- sample(2010:2018, 1) # 分析対象の年度
my_breaks <- sample(c(0.002, 0.005, 0.008, 0.01), 1) # ヒストグラムのビン幅
my_threshold <- round(runif(1, min = 0.01, max = 0.05), 3) # サブサンプルの閾値
cat("対象年度:", my_year, "\n")
cat("ビン幅:", my_breaks, "\n")
cat("閾値:", my_threshold, "\n")
```
------------------------------------------------------------------------
### Q1: `inner_join()` と `full_join()` の違い
::: {.callout-note icon="false"}
#### 問題
- 講義で読み込んだ`financial_data`と`stock_data`を,`inner_join()`で結合した場合と`full_join()`で結合した場合のそれぞれについて,`nrow()`で行数を報告せよ.
- 両者の行数に差が生じる理由を一文で説明せよ.
:::
------------------------------------------------------------------------
### Q2: `summarize()` + `across()` による記述統計の作成
::: {.callout-note icon="false"}
#### 問題
- データフレーム`analysis_sample`から,準備で生成した`my_year`年度のデータのみを`filter()`で抽出せよ.
- 抽出したデータについて,$SE$の基本統計量($N$, $\text{Mean}$, $SD$, $Q1$, $\text{Median}$, $Q3$)を`summarize()`で計算し,`across(where(is.double), ~ round(.x, 3))`で小数点第3位まで丸めよ.
- `my_year`年度の$\text{Mean}$の値を報告せよ.
:::
------------------------------------------------------------------------
### Q3: `geom_histogram()` + `geom_vline()` によるヒストグラム
::: {.callout-note icon="false"}
#### 問題
- データフレーム`analysis_sample`の$SE$について,$-0.2$から$0.2$の範囲で,準備で生成した`my_breaks`をビン幅とするヒストグラムを`geom_histogram()`で描画せよ.$x$軸ラベルは`Earnings Interval`,$y$軸ラベルは`Frequency`とすること.
- `geom_vline()`を使って$x = 0$に破線を追加せよ.
- 講義で使用したビン幅($0.005$)と`my_breaks`とでヒストグラムの見え方がどう異なるか,一文で答えよ.
:::
------------------------------------------------------------------------
### Q4: 条件付きサブサンプルの分析
::: {.callout-note icon="false"}
#### 問題
- データフレーム`analysis_sample`に対し,`group_by(firm_ID)`の上で`lag()`と`if_else()`を用いて前年度の$SE$を表す`lagged_SE`列を追加せよ(講義の練習問題と同様に,`year`と`lag(year)`の差が1であることを確認すること).
- `lagged_SE`が準備で生成した`my_threshold`**以上**の企業($=$ 前年度に少なくとも`my_threshold`以上の利益を確保していた企業)のみを`filter()`で抽出し,$SE$のヒストグラムを描画せよ.ビン幅は$0.005$,範囲は$-0.2$から$0.2$とする.
- 全サンプルのヒストグラム(Q3で描画したもの)と比較して,$SE = 0$付近の分布の形状にどのような違いが見られるか,一文で答えよ.
:::
::: goal
**(ヒント!)**
1. `lagged_SE`の作成には,`mutate(lagged_SE = if_else(year - lag(year) == 1, lag(SE), NA))`のように`if_else()`で年度の連続性を確認するのがポイントである.
2. Q3とQ4のヒストグラムを並べて見比べると,損失回避インセンティブの効果がより明確に観察できる.
:::