この回で新たに学ぶ関数・演算子
今回はtidyverseパッケージ群の関数を本格的に使い始める回である.新しく登場する関数・演算子が多いので,まずは全体像を把握しておこう.
read_csv()readrCSVファイルをtibble形式で読み込む
%>%(パイプ演算子)magrittr左の結果を右の関数の第一引数に渡す
filter()dplyr条件に合う行を抽出する
select()dplyr指定した列のみを選択する
mutate()dplyr新しい列を追加する
group_by()dplyrデータをグループ化する
ungroup()dplyrグループ化を解除する
summarize()dplyrグループごとに集計する
lag()dplyr一期前の値を参照する
drop_na()tidyr欠損値を含む行を削除する
一度に全てを覚える必要はない.各関数の使い方は実際のコードの中で順を追って説明する.
迷ったらこの表に戻って「今どの関数を使っているのか」を確認しよう.
財務データの読み込み(教科書第4.2節)
readrのread_csv()関数を用いたデータの読み込み
Code
# tidyverseの読み込み :: p_load (tidyverse) # これまではread.csv()関数,これからはreadrのread_csv()関数を使う <- read_csv ("ch04_financial_data.csv" ) # 行数の確認 nrow (financial_data)
Code
# 冒頭N行を確認するにはhead(financial_data, N)とする head (financial_data)
read_csv()関数の特徴
データの読み込みがより高速であり,かつ,型推論が柔軟である.
読み込んだデータをデータフレームではなく,その改良版であるtibbleで返す.
データフレームには,列名の空白を勝手に.(ピリオド)に変換したり,うっかりprint()関数で表示すると膨大な行数全てを表示してしまったりと,様々な不都合な側面があり,tibbleはそれらを改良したものである.
列名を勝手に(X.1, X.2, X.3などのように)変換しない.
文字列を勝手にファクター型扱いしない.
read_csv()関数の型推論の柔軟性
Code
<- read.csv ("ch03_daily_stock_return.csv" ) str (daily_stock_return)
'data.frame': 21 obs. of 3 variables:
$ date : chr "2020-04-01" "2020-04-02" "2020-04-03" "2020-04-06" ...
$ firm1: num -0.03948 0.00598 0.05579 0.04193 -0.02019 ...
$ firm2: num 0.07696 -0.00725 -0.0173 0.00217 0.07555 ...
Code
<- read_csv ("ch03_daily_stock_return.csv" ) str (daily_stock_return)
spc_tbl_ [21 × 3] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
$ date : Date[1:21], format: "2020-04-01" "2020-04-02" ...
$ firm1: num [1:21] -0.03948 0.00598 0.05579 0.04193 -0.02019 ...
$ firm2: num [1:21] 0.07696 -0.00725 -0.0173 0.00217 0.07555 ...
- attr(*, "spec")=
.. cols(
.. date = col_date(format = ""),
.. firm1 = col_double(),
.. firm2 = col_double()
.. )
- attr(*, "problems")=<externalptr>
read_csv()関数で読み込んだdate列が日付型 Date)になっていることが確認できる.他方,基本パッケージのread.csv()関数で読み込むと,この列は文字型 (chr)と認識されていたので,read_csv()関数の方がより正確に型推論できていることが分かる.
ファクター型への変換
Code
# class()関数を用いて,各変数の型を確認しよう class (financial_data$ firm_ID)
Code
class (financial_data$ industry_ID)
firm_ID列とindustry_ID列は,いずれもカテゴリカル変数にも関わらず,数値型 (numeric)になっている.そこで,factor()関数を使ってきちんとファクター型に変換しておこう.
(続)ファクター型への変換
Code
# firm_ID列とindustry_ID列をファクター型に変換 $ firm_ID <- factor (financial_data$ firm_ID)$ industry_ID <- factor (financial_data$ industry_ID)head (financial_data)
# A tibble:6 x 11以下を見てみると,各変数の下にはそれぞれの変数のデータ型が記述されており,firm_IDとindustry_IDの下にある<fct>は,ファクター型を意味する.それ以外の列の<dbl>はdouble(倍精度浮動小数点数)型を意味し,実数を表すのに用いられる数値型の一種である.
探索的データ分析(教科書第4.3節)
データセットの概要確認
初見のデータセットを扱う場合,データ分析を本格的に始める前にまずはその概要を大まかに掴む必要がある.その作業を一般に探索的データ分析
一口に探索的データ分析と言っても,データの性質に応じて様々な方法が考えられるが,まずは手始めにsummary()関数を用いてみよう.
(続)データセットの概要確認
Code
# 要約統計量の表示 summary (financial_data)
year firm_ID industry_ID sales
Min. :2015 1 : 6 3 :1760 Min. : 205.3
1st Qu.:2016 2 : 6 10 :1702 1st Qu.: 16103.3
Median :2018 3 : 6 7 :1334 Median : 40430.7
Mean :2018 4 : 6 1 :1143 Mean : 166007.0
3rd Qu.:2019 5 : 6 9 : 667 3rd Qu.: 118313.8
Max. :2020 7 : 6 8 : 429 Max. :3496433.0
(Other):7884 (Other): 885
OX NFE X
Min. :-353606.7 Min. :-285383.87 Min. :-357624.8
1st Qu.: 399.3 1st Qu.: -66.43 1st Qu.: 383.3
Median : 1602.9 Median : -1.19 Median : 1586.1
Mean : 7968.9 Mean : 64.02 Mean : 7904.9
3rd Qu.: 5260.5 3rd Qu.: 41.36 3rd Qu.: 5204.6
Max. : 398034.5 Max. : 331035.25 Max. : 572588.7
NA's :1
OA FA OL
Min. : 216.5 Min. :2.884e+02 Min. :3.504e+01
1st Qu.: 12559.9 1st Qu.:6.835e+03 1st Qu.:3.965e+03
Median : 30799.2 Median :1.910e+04 Median :1.087e+04
Mean : 152272.8 Mean :8.019e+04 Mean :5.026e+04
3rd Qu.: 93469.2 3rd Qu.:5.212e+04 3rd Qu.:3.311e+04
Max. :7987936.2 Max. :2.925e+07 Max. :2.818e+06
FO
Min. : 43.6
1st Qu.: 3757.4
Median : 11125.2
Mean : 70680.6
3rd Qu.: 35446.0
Max. :7026923.6
summary()関数は,数値型(整数型や倍精度浮動小数点数型)が代入された場合,各データセットに含まれる各変数の平均や中央値,分位点を返す.ファクター型に対しては,要素数が多いカテゴリーを上から順に表示する.
欠損データの処理
Code
# head()関数を用いて冒頭6行の結果のみ表示 head (complete.cases (financial_data))
[1] FALSE TRUE TRUE TRUE TRUE TRUE
ここで登場したTRUEとFALSEは,通称論理型 (logical)と呼ばれるデータ型である.その特徴は,TRUEとFALSEの二つのみで構成される点にある.この二つを算術関数の引数として用いると,TRUEが1,FALSEが0と解釈されるので,sum()関数の引数にcomplete.cases(financial_data)を代入することで,欠損が無い観測値数を数え上げてくれる.
Code
# 欠損のない行の総数をカウント sum (complete.cases (financial_data)) # TRUE/FALSEを1/0に変換して足し合わせる
(続)欠損データの処理
欠損データの処理について,最も単純な方法は,欠損値が含まれる観測データを削除してしまうことである.
tidyrに含まれるdrop_na()関数は,第二引数を省略した場合,入力されたデータフレームに対し,欠損値が存在しない行のみを抽出して返す.
Code
# 元々のデータフレームを確認 head (financial_data)
Code
# 欠損行を削除し,データフレームを上書き <- drop_na (financial_data) # 欠損行を削除後のデータフレームを確認 head (financial_data)
実を言うと,このコードのように,前処理の過程で元のデータが復元不可能になる上書きを行うのは 余り望ましくない.なぜなら,CSVファイルを改めて読み直さない限り,元のfinancial_dataにアクセスできなくなってしまうからである.したがって,本来であれば元データを上書きする代わりに,新しいデータフレームにprocessed_financial_dataなどの別の変数名を付すのが望ましい.しかし,ここでは後々の説明が冗長になるのを防ぐために,あえてfinancial_dataに上書きする書き方を選んで いる.
データの加工から可視化まで(教科書第4.4節)
dplyrのパイプ演算子の使い方
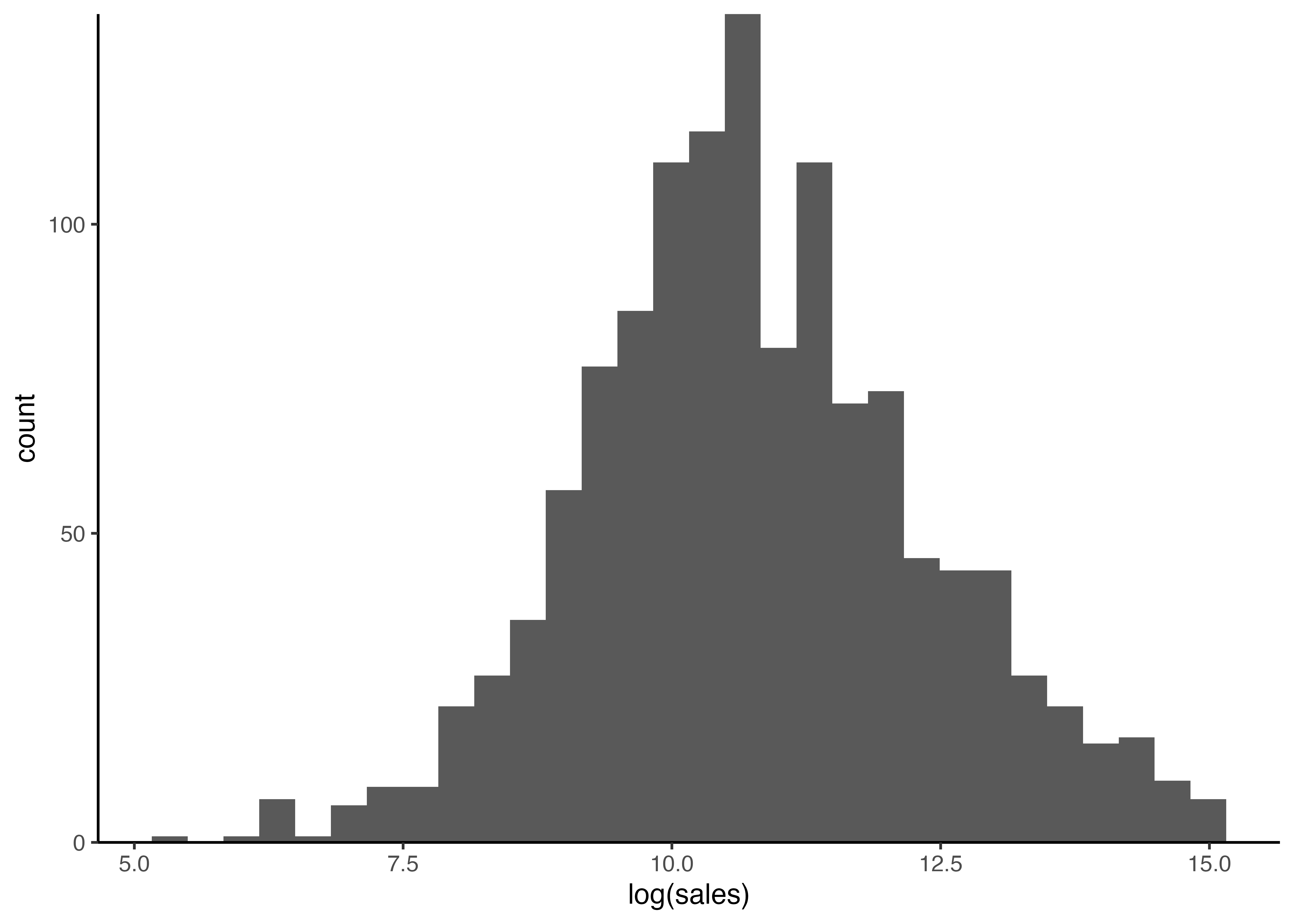
2015 年度のデータのみを抽出して,売上高の自然対数をヒストグラムで描画してみよう.
パイプ演算子%>%は,左側で処理されたデータフレームを,右側の関数の第一引数として受け渡す 役割を果たす.
実際の使用例
パイプ演算子%>%の入力は,RStudio上で以下のショートカットキーを利用すると便利である.
macOS: ⌘ + Shift + M
Windows / Linux: Ctrl + Shift + M
Code
# 2015年度のデータのみ抽出 %>% filter (year == 2015 ) # 2015年度のみ抽出
%>% と |> の違い
Rには2種類のパイプ演算子がある.
%>%
magrittrパッケージ由来長年使われてきたため,既存のコードや教材ではこちらが一般的である.
|>
R 4.1.0から導入されたbase R のパイプ演算子.
外部パッケージに依存せず,今後は標準として推奨されていくと考えられる.
まとめると!
%>%はmagrittr由来,|>は base R の機能である.本講義ではテキストの記述に沿って %>% を利用する.
ただし,Rのバージョンが新しければ|>も使えることを知っておくとよい.
パイプ演算子%>%を用いる利点
パイプ演算子%>%は「データを次の関数に渡す」だけのものであるが,それを使うと頭の中でイメージした処理の流れをそのままコードにできる という利点がある.
試しに,financial_data内のsales列の自然対数の中央値を計算して,結果を表示する方法を考えてみよう.
パイプ演算子を使う場合
Code
$ sales %>% log () %>% # log(financial_data$sales)を計算 median () %>% # その中央値を計算 print () # 結果を表示
パイプ演算子を使わない場合
Code
print (median (log (financial_data$ sales)))
パイプ演算子を使わない場合は「内側から外側へ」と入れ子構造で読まないといけない.
パイプを使うと「左から右へ」と処理の流れを順に追えるため,コードが直感的で書きやすく,読みやすい.
抽出後,更に列選択して別名で保存
抽出後にfirm_ID,year,salesの三列を選択し,こうして出来上がった新たなデータフレームをfinancial_data_2015として定義しよう.
Code
# 抽出後,列選択し,新たなデータフレームとして定義 <- financial_data %>% filter (year == 2015 ) %>% # 2015年度のみ抽出 select (firm_ID, year, sales) # 必要な列のみ選択 head (financial_data_2015) # head()関数で確認
2015年度のデータを抽出して一気に可視化まで処理
わざわざfinancial_data_2015を作らなくても,目標を達成するだけであれば,filter()関数を適用した後のデータをggplot()関数に引き渡してあげれば良い.
Code
%>% filter (year == 2015 ) %>% ggplot () # %>%演算子以前のデータを第一引数に取るので()内の指定不要
ヒストグラムを描画し,体裁を整える
Code
%>% filter (year == 2015 ) %>% ggplot () + geom_histogram (aes (x = log (sales))) + # ヒストグラムの描画 scale_y_continuous (expand = c (0 ,0 )) + # y軸の位置を調整 theme_classic ()
ggplot2でヒストグラムを描くには,geom_histogram()関数を用いる.aes()引数には,\(x\) 軸の値としてlog(sales)を指定する.scale_y_continuous(expand = c(0,0))はヒストグラムが\(x\) 軸にぴったりくっ付くよう調整する役割を果たす.
mutate()関数を使って新たな列の追加(教科書第4.6節)
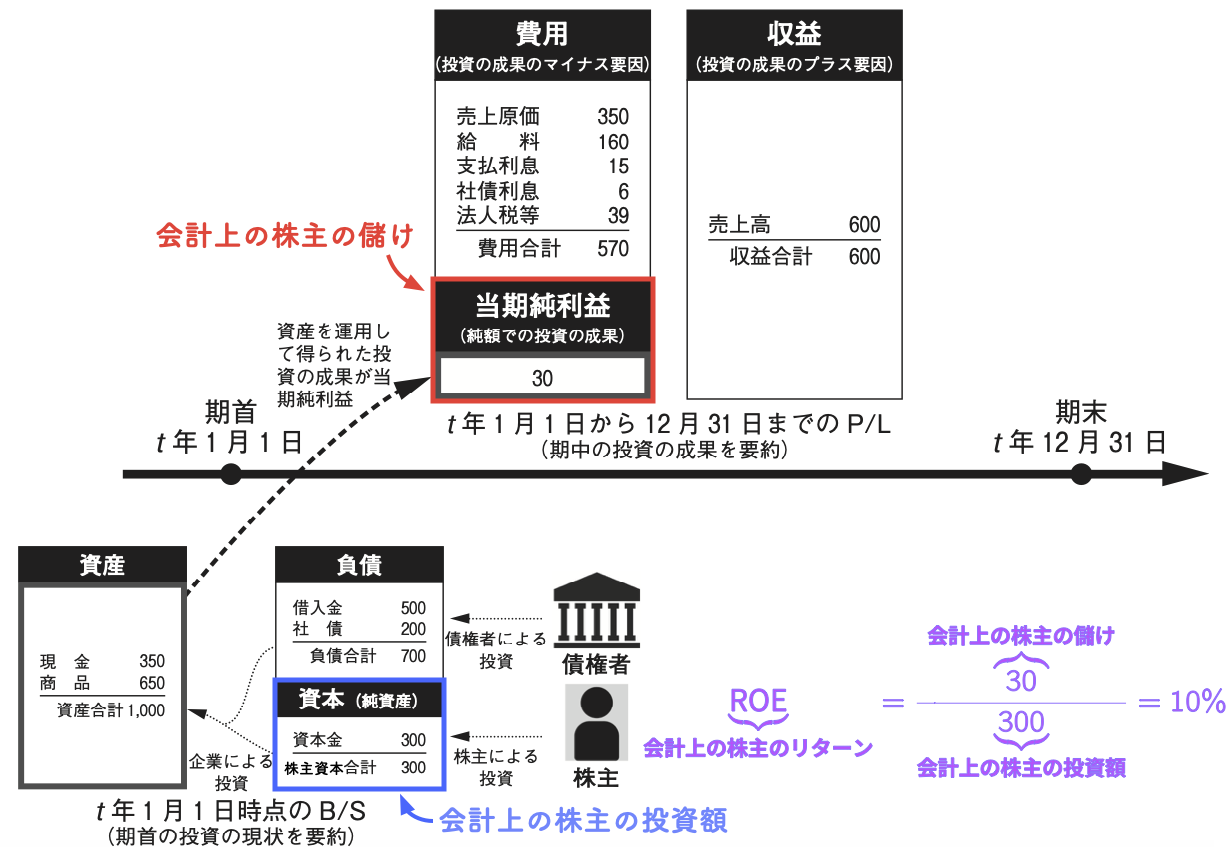
会計上の株主のリターン \(=\) ROE
ROEの計算方法
\[
\begin{align}
ROE_{t} = \frac{X_{t}}{\mathit{BE}_{t-1}} \label{eq:ch04_ROE}
\end{align}
\]
ここで分子の\(X_{t}\) は\(t\) 期の当期純利益を指し,分母の\(\mathit{BE}_{t-1}\) は\(t\) 期首(別の言い方をすると\(t-1\) 期末)の株主資本を指す.
分母の\(\mathit{BE}\) は一期前の値を取っていることに注意しよう.
これは,ROEを期首時点の株主の投資額(期首の株主資本)に対する期中の投資の成果(期中の当期純利益)と解釈するためである.
こうして計算されたROEは,一期間における会計上の株主のリターン
ここでの目標
目標1: financial_dataに\(t\) 期末の株主資本BE列を追加する.目標2: financial_dataに\(t-1\) 期末の株主資本を表すlagged_BE列を追加する.目標3: financial_dataにROE列を追加目標4: ROEをヒストグラムに可視化する.ただし,作図に利用するのは,ROEが-0.2から0.4の観測値のみ,ビン幅は0.01に指定すること.また,\(x\) 軸のラベルはROE Interval,\(y\) 軸のラベルはFrequencyとすること.
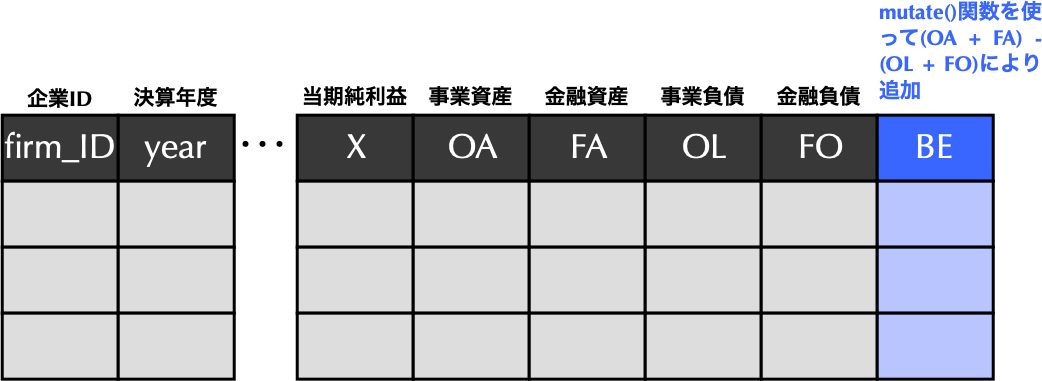
目標1: BE列の追加
Code
# mutate()関数を用いて株主資本BE列の追加 <- financial_data %>% mutate (BE = (OA + FA) - (OL + FO)) # 資産合計から負債合計を差し引いて計算
dplyrでは新しい列を追加するのにmutate()関数
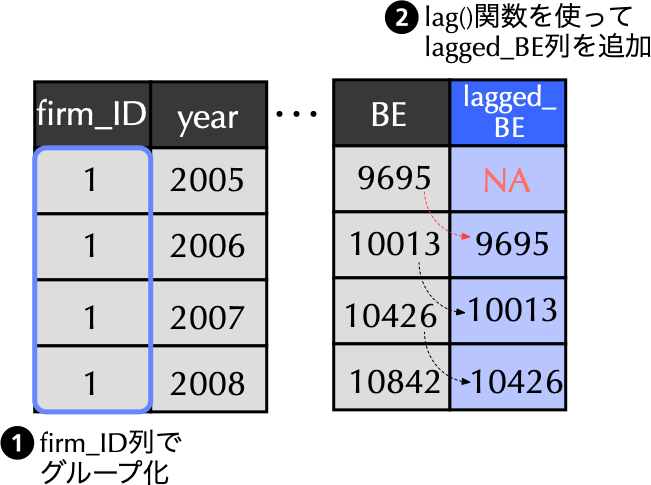
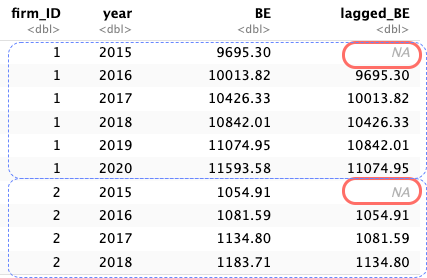
目標2: lagged_BE列の追加
Code
# lag()関数を用いて1年前の株主資本lagged_BE列を追加 <- financial_data %>% group_by (firm_ID) %>% # ①firm_IDでグループ化 mutate (lagged_BE = lag (BE)) %>% # ②lag()関数を使ってlagged_BEを追加 ungroup ()
先のコードの概要
2行目: financial_dataに上書き.3行目: group_by()関数を用いて,firm_IDに基づくグループ化情報を付与 4行目: mutate()関数内でlag()関数を使うことで,lagged_BE列を作成し,そこに一期前のBEを格納.5行目: ungroup()関数を用い,不要になったグループ化情報を消去
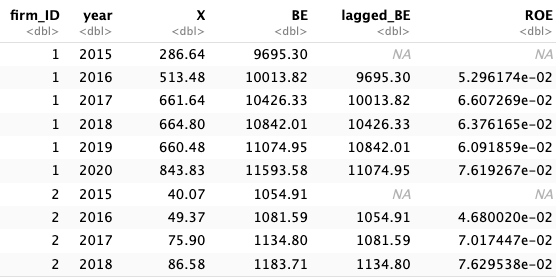
目標3: ROE列を追加
最後にmutate()関数を使って,ROE列を追加しよう.
Code
# ROE列の追加 <- financial_data %>% mutate (ROE = X / lagged_BE) # 定義に従ってROEを計算
実践上はパイプ演算子を繋げて書く
Code
# 実践でのROEの計算 <- financial_data %>% mutate (BE = (OA + FA) - (OL + FO)) %>% # 目標1: BE列の追加 group_by (firm_ID) %>% # 目標2: 以下の三行でlagged_BE列を追加 mutate (lagged_BE = lag (BE)) %>% ungroup () %>% mutate (ROE = X / lagged_BE) # 目標3: ROE列の追加
従来は group_by() → mutate() → ungroup() の流れで書いていた.
dplyr 1.1.0 以降 では,.by 引数を使うことで,一時的にグループ化した処理 を利用して簡潔に書けるようになった.
Code
# .by引数を利用した別の書き方 <- financial_data %>% mutate (BE = (OA + FA) - (OL + FO),lagged_BE = lag (BE), .by = firm_ID,ROE = X / lagged_BE
.by = firm_IDはこのmutate()の中でだけ効くため,グループ化を持ち越さずに処理できる.したがって,わざわざungroup()を書く必要がない.
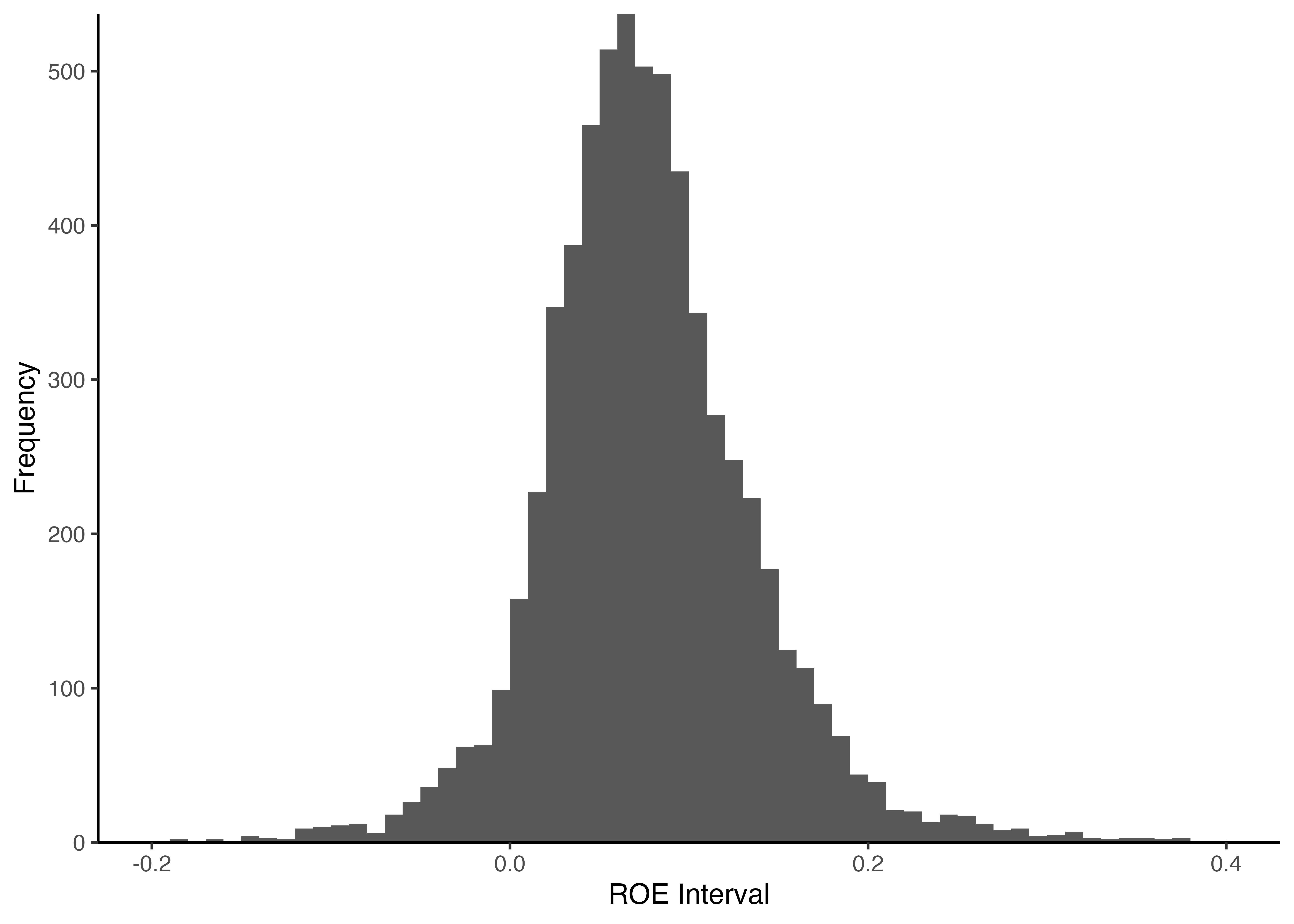
目標4: ROEのヒストグラム
最終目標として,ggplot2を利用し,ROEをヒストグラムにより描画しよう.
Code
# ROEのヒストグラムの描画 ggplot (financial_data) + geom_histogram (aes (x = ROE),breaks = seq (- 0.2 , 0.4 , 0.01 )) + labs (x = "ROE Interval" , y = "Frequency" ) + scale_y_continuous (expand = c (0 , 0 )) + theme_classic ()
geom_histogram()関数のbreaks引数により\(x\) 軸の範囲とビン幅を調整している.seq()関数は等差数列を作成するための関数であり,第一引数に始点,第二引数に終点,第三引数に等差数列の差分 (教科書84頁) .ここでは-0.2から0.4までのROEを描画することを考え,ビン幅に相当する等差数列の差分は0.01としてみよう.
なお,breaks引数で指定した範囲外の観測値(ROEが-0.2未満や0.4超の企業)はヒストグラムに描画されない点に注意しよう.つまり,breaks引数はビン幅の設定と同時に,描画対象のデータ範囲の指定も兼ねている.
集計作業(教科書第4.7.1節の応用)
summarize関数の使い方
ROEが計算可能な観測値のみを抽出し,年度ごとにROEの平均値を求めよ.
Code
# 年度ごとにROEの平均値を算出 %>% drop_na (ROE) %>% # ROEが欠損値の観測値を削除 group_by (year) %>% # 年でグループ化 summarize (mean_ROE = mean (ROE)) # 各年のROEの平均値mean_ROEを計算
先のコードの概要
3行目: tidyrに含まれるdrop_na()関数は,第二引数で指定した変数(この場合であればROE列)に欠損値が存在しない行のみを抽出して返す(教科書152頁) .4行目: group_by()関数を用いて,年度yearに基づいてグループ化.5行目: summarize()関数を用いて,各グループ(年度)ごとに平均ROEを計算し,mean_ROE列に保存する.
(注意点)summarize()関数を適用することにより,グループ化は解除される.ただし,summarize()関数は1つのグループしか解除しないため,複数の変数でグループ化した場合は注意が必要である.以下の例で確認してみよう.
Code
# 年度・産業ごとにROEの平均値を算出 - .groups引数を指定しない場合 %>% drop_na (ROE) %>% # ROEが欠損値の観測値を削除 group_by (year, industry_ID) %>% # 年・産業でグループ化 summarize (mean_ROE = mean (ROE)) %>% # 各年のROEの平均値mean_ROEを計算 print ()
# A tibble: 50 × 3
# Groups: year [5]
year industry_ID mean_ROE
<dbl> <fct> <dbl>
1 2016 1 0.0786
2 2016 2 0.107
3 2016 3 0.0771
4 2016 4 0.0723
5 2016 5 0.0908
6 2016 6 0.0812
7 2016 7 0.0555
8 2016 8 0.0874
9 2016 9 0.0863
10 2016 10 0.0646
# ℹ 40 more rows
上のコードでは.groups引数を指定していないため,yearによるグループ化が残ったままになっている.これを防ぐには,以下のように.groups = "drop"を指定し,明示的にグループ化を解除する.
Code
# 年度・産業ごとにROEの平均値を算出 - .groups引数を指定する場合 %>% drop_na (ROE) %>% # ROEが欠損値の観測値を削除 group_by (year, industry_ID) %>% # 年・産業でグループ化 summarize (mean_ROE = mean (ROE), # 各年のROEの平均値mean_ROEを計算 .groups = "drop" ) %>% # グループ化を明示的に解除 print ()
# A tibble: 50 × 3
year industry_ID mean_ROE
<dbl> <fct> <dbl>
1 2016 1 0.0786
2 2016 2 0.107
3 2016 3 0.0771
4 2016 4 0.0723
5 2016 5 0.0908
6 2016 6 0.0812
7 2016 7 0.0555
8 2016 8 0.0874
9 2016 9 0.0863
10 2016 10 0.0646
# ℹ 40 more rows
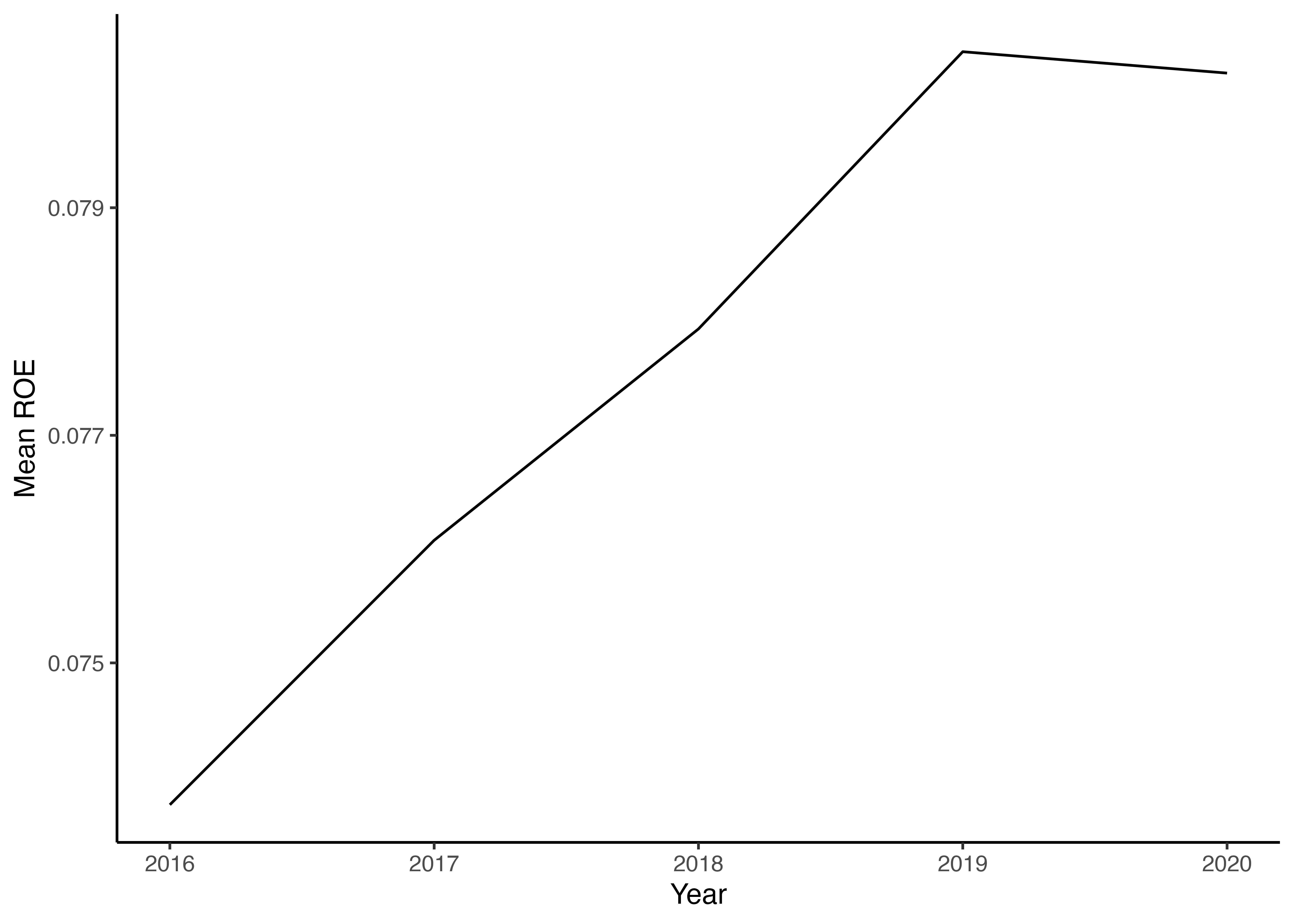
平均値計算から可視化までを一度に処理
Code
# 年度ごとにROEの平均値を求め,折れ線グラフにより描画 %>% drop_na (ROE) %>% group_by (year) %>% # 年でグループ化 summarize (mean_ROE = mean (ROE)) %>% # 各年のROEの平均値を計算 ggplot () + # ggplot()関数にデータを引き渡す geom_line (aes (x = year, y = mean_ROE)) + # 折れ線グラフを描くにはgeom_line()関数を用いる labs (x = "Year" , y = "Mean ROE" ) + # 両軸のラベルを設定 theme_classic () # グラフ全体の体裁を設定
練習問題
firm_IDが350の企業の売上高を折れ線グラフで表示せよ.ただし,\(y\) 軸は売上高sales,\(x\) 軸は年度year を取ることとする.
最終年度のROEに関して20%分位点を求め,ROE_first_quintileという変数に保存せよ.
(ヒント) 分位点を求めるにはquantile()関数を用いる.この関数は第一引数にデータセット,第二引数に求めたい分位点の値をパーセントでなく小数表示で代入する.また,データセットに欠損値が含まれている場合,na.rm = TRUE を追加する必要がある.na.rmはremove NA values の略を意味する.
最終年度の ROEがROE_first_quintileより小さい企業は何社あるか答えよ.ただし,ROEが欠損している企業はカウントしないこと.
自習課題
以下の課題に取り組み,今回学んだ内容の理解度を自分で確認しよう.
課題では,講義で読み込んだfinancial_dataをそのまま使用する.
準備:自分だけの分析条件を生成する
以下のコードをRコンソールで実行しよう.set.seed()関数の引数には,自分の学籍番号の末尾4桁の数字 (末尾の英字を除く)を入力すること.
Code
# 全期間にわたってデータが揃っている企業を対象に絞る <- financial_data %>% count (firm_ID) %>% filter (n == max (n)) %>% pull (firm_ID)# 自分の学籍番号の末尾4桁の数字を入力(例: 学籍番号が2001234Bの場合は1234) set.seed (1234 )# 自分だけの分析条件を生成 <- sample (intersect (1 : 500 , target_firms), 1 ) # 分析対象の企業ID <- sample (2015 : 2020 , 1 ) # 分析対象の年度 <- sample (3 : 8 , 1 ) # 抽出する企業数 cat ("対象企業:" , my_firm, " \n " )cat ("対象年度:" , my_year, " \n " )cat ("抽出企業数:" , my_n, " \n " )
Q1: filter() と select() の練習
financial_dataから,準備で生成したmy_year年度のデータのみをfilter()で抽出し,さらにselect()でfirm_ID,sales,Xの3列だけを表示せよ.パイプ演算子%>%を使って一連の処理として書くこと.抽出結果の先頭6行をhead()で確認し,1行目のsalesの値を報告せよ.
Q2: mutate() による新しい列の追加
financial_dataに対し,mutate()を使って以下の定義に従い売上高純利益率profit_marginを新しい列として追加せよ.ただし,\(i\) は企業,\(t\) は年度を表す.\[\text{profit\_margin}_{i,t} = \frac{X_{i,t}}{\text{sales}_{i,t}}\] その上で,準備で生成したmy_firmの企業について,全年度のyear,sales,X,profit_marginを表示せよ.
Q3: group_by() + summarize() による集計
financial_dataをyearでグループ化し,年度ごとのsalesの平均値を計算してmean_salesと名付けたデータフレームを作成せよ..groups = "drop"を忘れないこと.作成したデータフレームから,my_year年度のmean_salesの値を報告せよ.
Q4: lag() と drop_na() を使った成長率の計算
financial_dataをfirm_IDでグループ化した上で,lag()を使って前年度の売上高lagged_salesを作成し,さらに以下の定義に従って売上高成長率sales_growthを計算せよ.ただし,\(i\) は企業,\(t\) は年度を表す.\[\text{sales\_growth}_{i,t} = \frac{\text{sales}_{i,t} - \text{sales}_{i,t-1}}{\text{sales}_{i,t-1}}\] lag()による欠損値をdrop_na(sales_growth)で除去した上で,my_firmの企業のyear,sales,sales_growthを表示し,売上高成長率が最も高かった年度を答えよ.
(ヒント!)
group_by(firm_ID)を忘れずに.グループ化しないとlag()が異なる企業のデータを参照してしまう.パイプ演算子を使ってgroup_by() → mutate() → drop_na() → filter() と繋げて書いてみよう.