
Code
# tidyverseの読み込み
pacman::p_load(tidyverse)
# 財務データの読み込み
financial_data <- read_csv("../simulation_data/financial_data2.csv")Rows: 22855 Columns: 7
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (6): firm_ID, year, macc, X, TA, CFO
date (1): fiscal_year_end
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Code
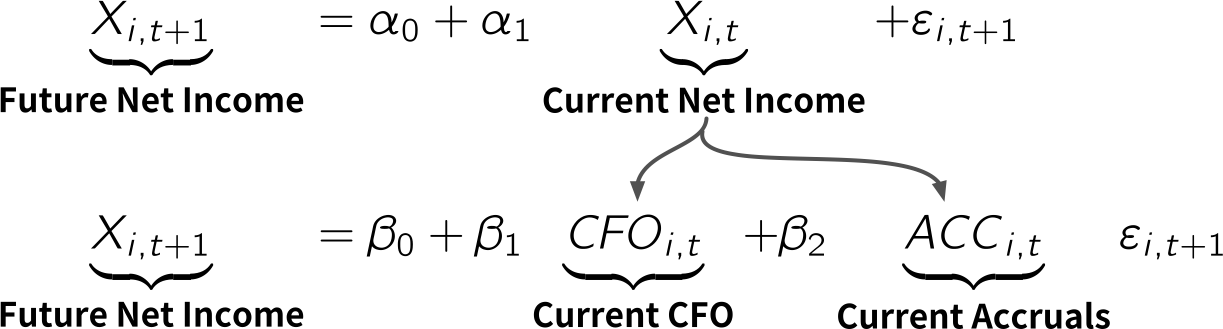
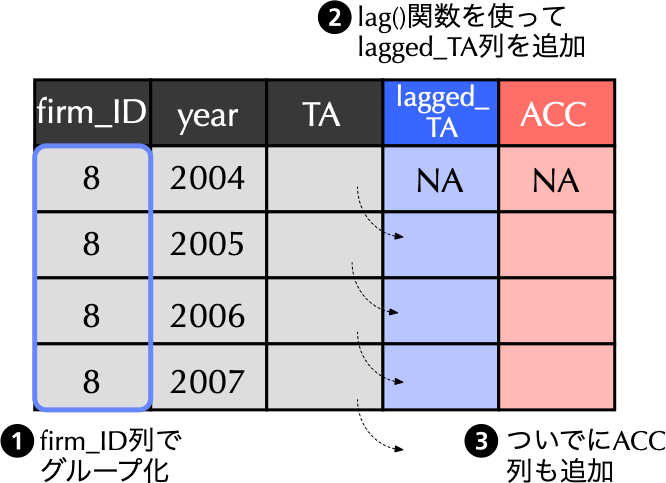
# アクルーアルズACCを計算し,データフレームに追加
financial_data <- financial_data %>%
group_by(firm_ID) %>% # firm_IDでグループ化
mutate(lagged_TA = lag(TA), # 前期末の資産合計をlagged_TAと定義
ACC = ifelse(macc == 12, (X - CFO) / lagged_TA, NA)) %>% # 定義に従いACCを計算
ungroup() # グループ化の解除