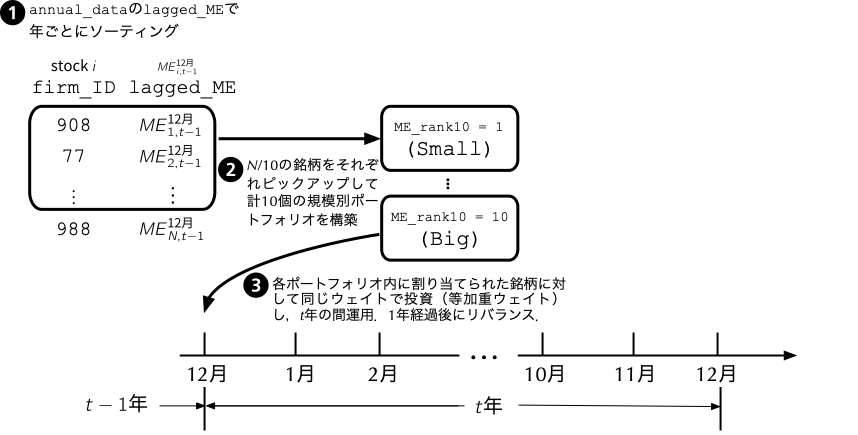
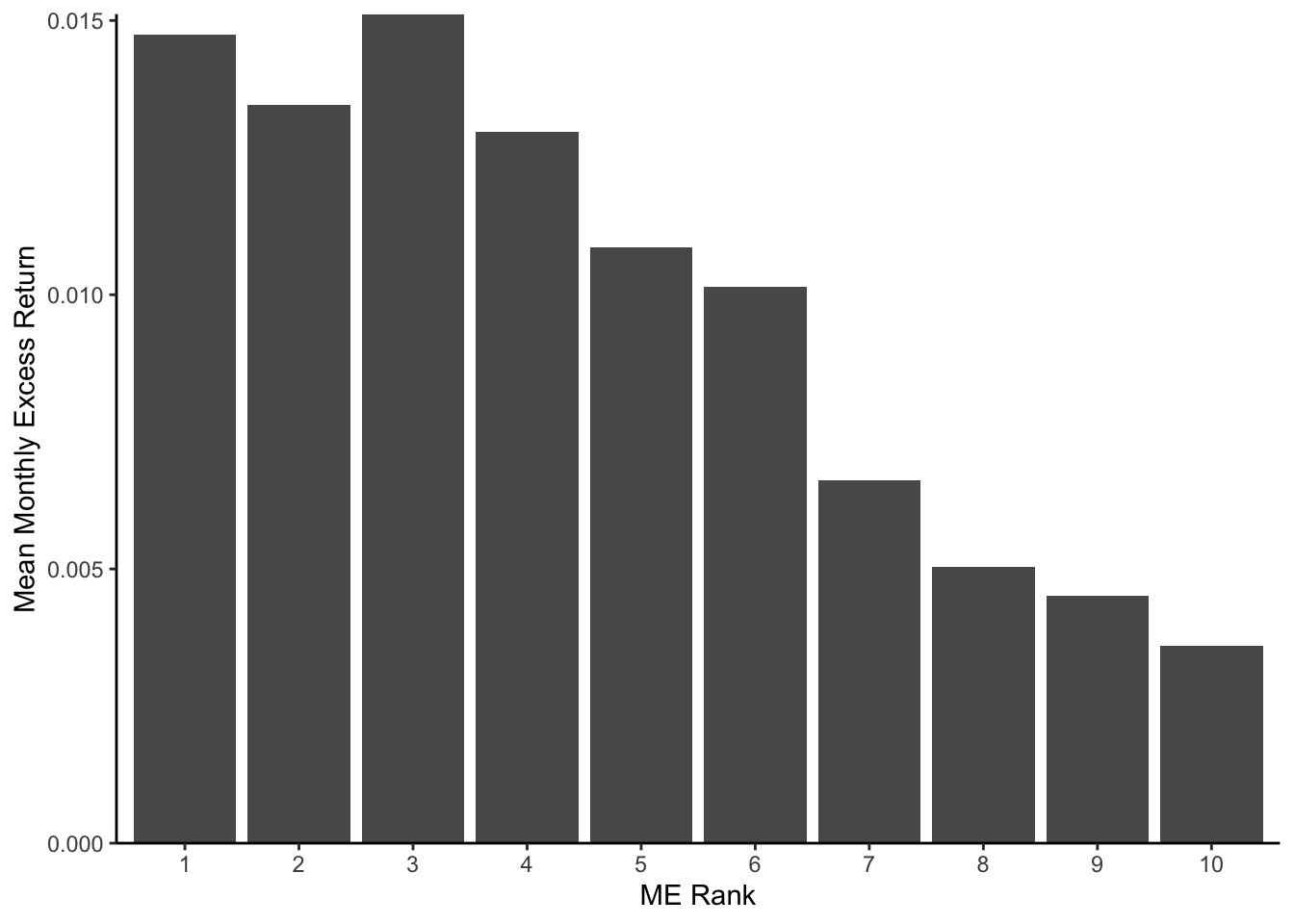
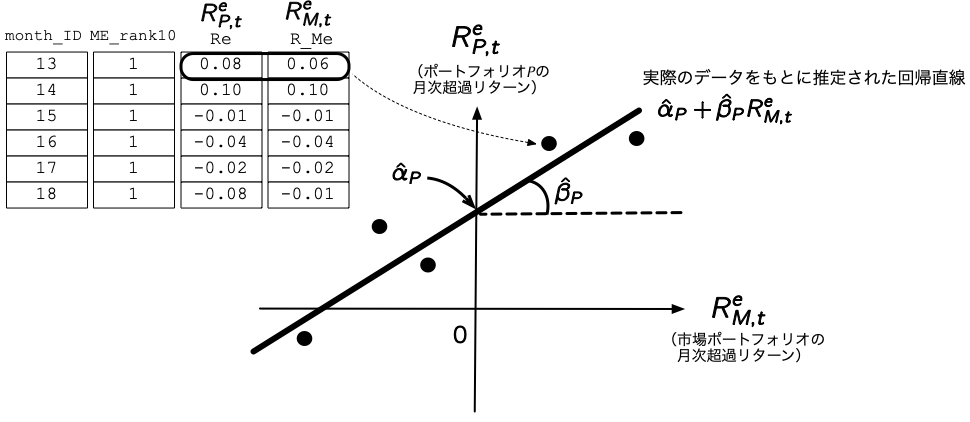
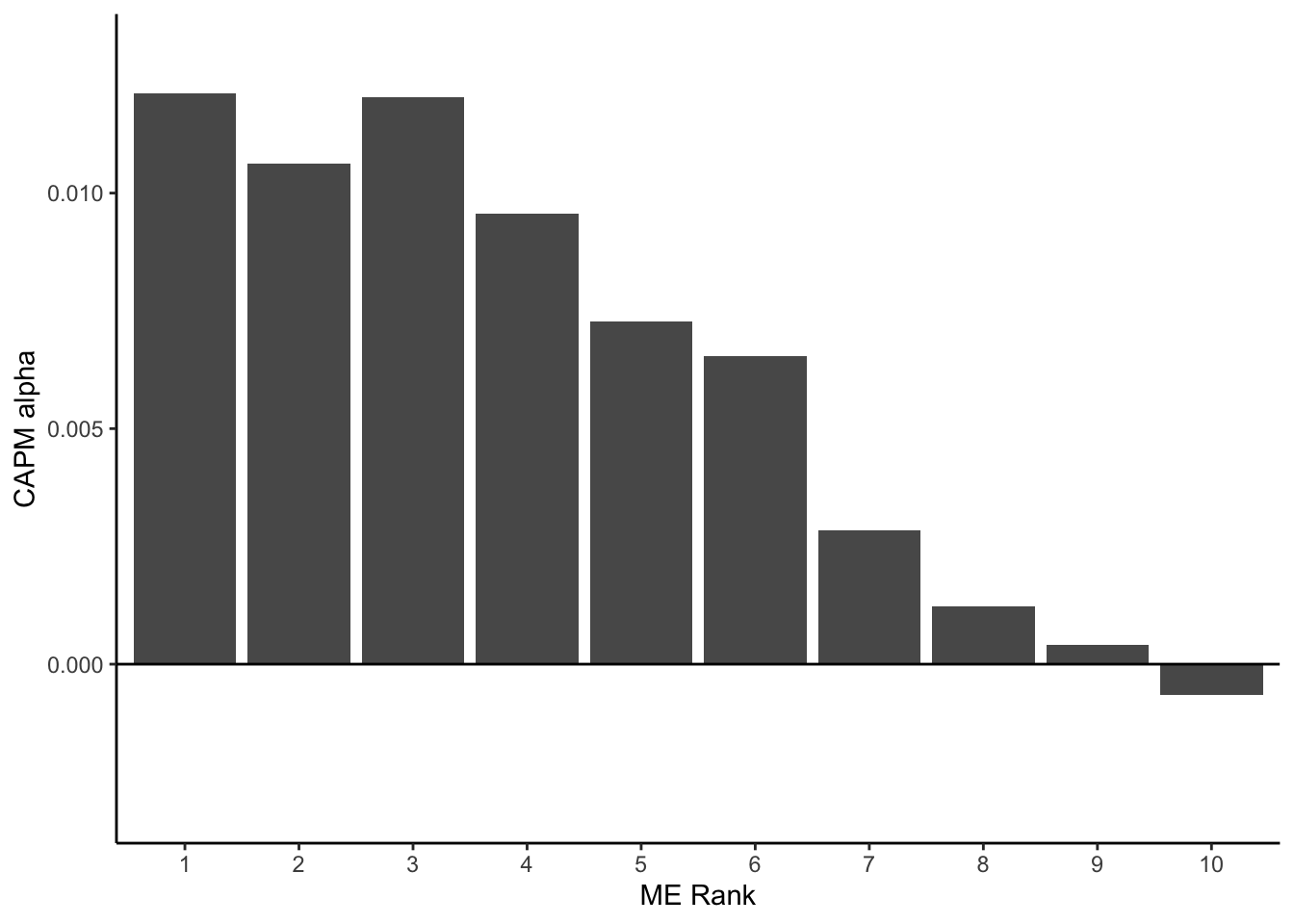
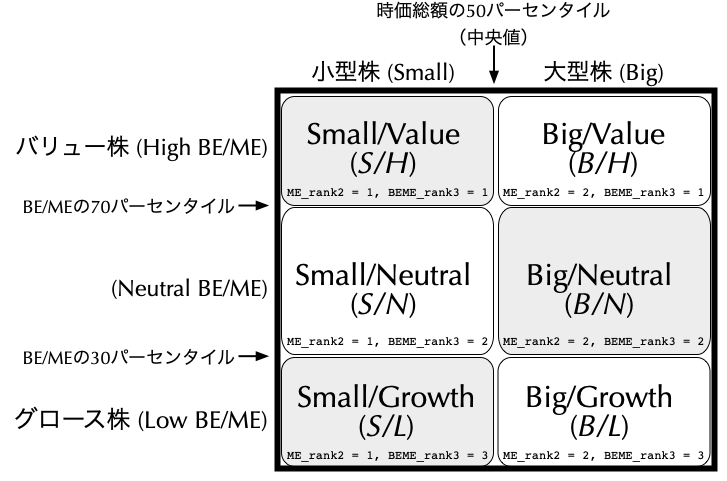
任意の証券の無リスク金利に対する超過リターンが,ファクターと呼ばれる\(K\)個の確率変数\(F^k\) (\(k = 1, 2, \ldots, K\)),及び誤差項\(\varepsilon_{i}\)の線形結合で記述できるというモデルである. \[
\begin{align*}
R_{i,t}^e = \beta_i^1 F_t^1+\beta_i^2 F_t^2+\cdots + \beta_i^K F_t^K + \varepsilon_{i,t}
\end{align*}
\]
ただし,誤差項\(\varepsilon_{i}\)は\(\mathbb{E}[\varepsilon_{i}]=0\),かつ\({\rm Cov}[\varepsilon_{i}, F^k]=0\)を満たす.ここで,\(\beta_i^k\)はファクター・ローディング (factor loading)と呼ばれ,証券\(i\)のリターンとファクター\(F^k\)との共変動の強さを表すパラメータであり,説明変数を一つから複数へと増やした重回帰分析によって推定することができる.ただし,通常の回帰分析と異なり,定数項を除いている点がポイントである.