Code
pacman::p_load(tidyverse)
# 財務データの読み込み
financial_data <- read_csv("../simulation_data/ch04_output.csv")Rows: 7919 Columns: 14
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (14): year, firm_ID, industry_ID, sales, OX, NFE, X, OA, FA, OL, FO, BE,...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Code
# 先週保存したannual_stock_data.csvを読み込み
annual_stock_data <- read_csv("../simulation_data/annual_stock_data.csv")Rows: 7920 Columns: 5
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (5): firm_ID, year, R, Re, R_F
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Code
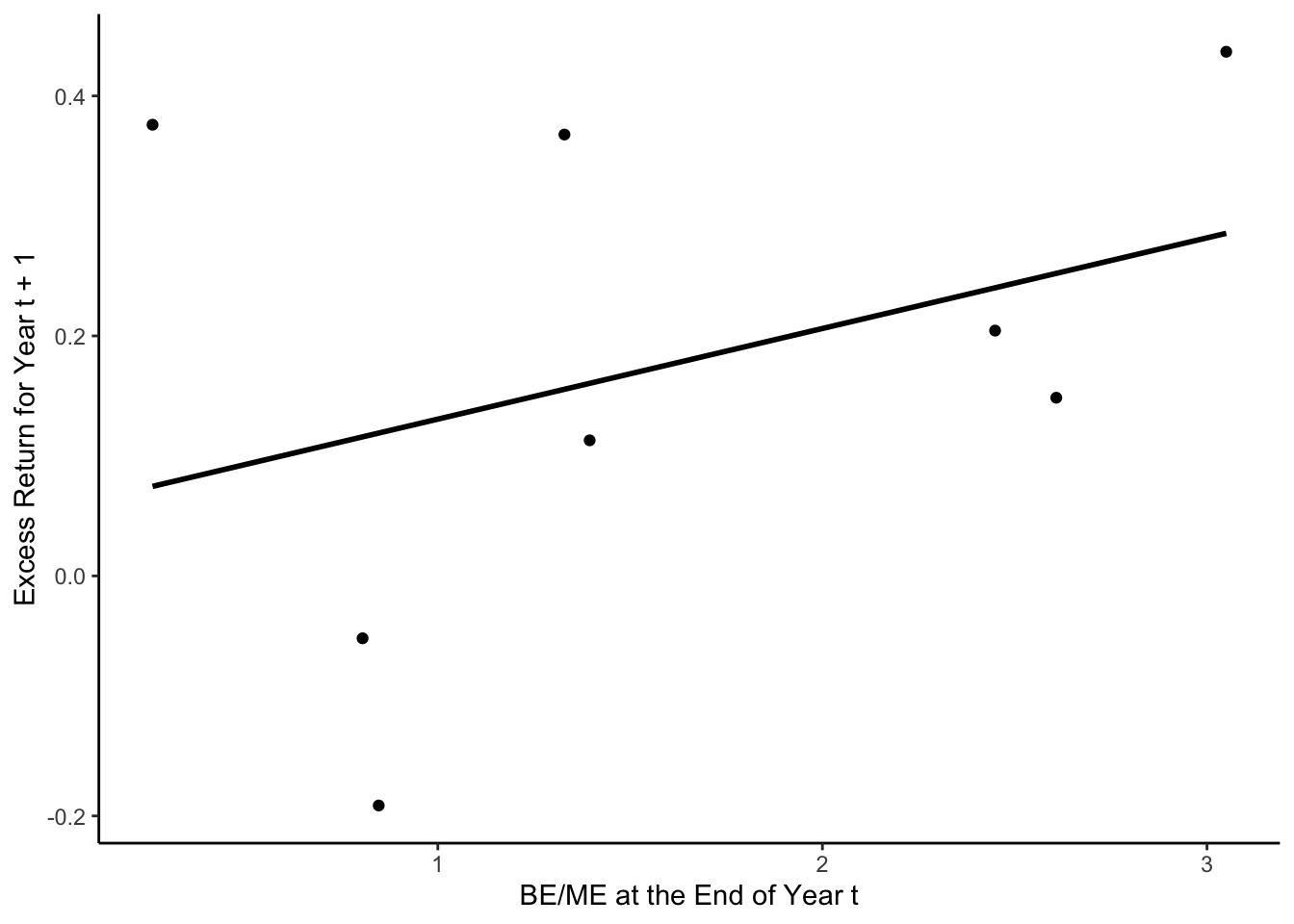
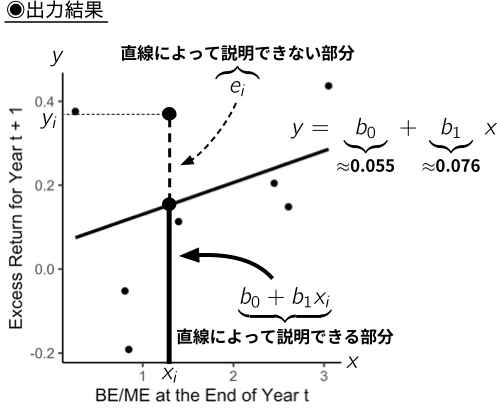
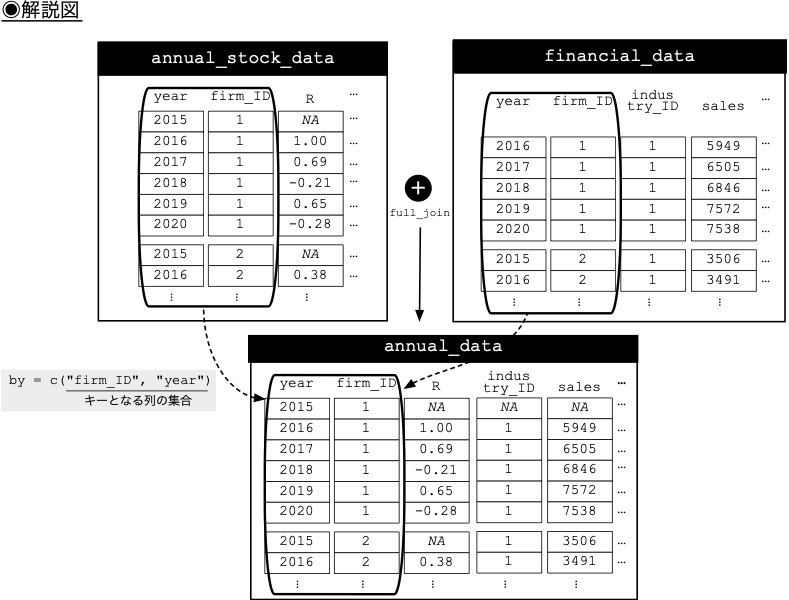
# 両データフレームの結合
annual_data <- annual_stock_data %>%
full_join(financial_data, by = c("firm_ID", "year")) # firm_IDとyearのペアをキーとして設定