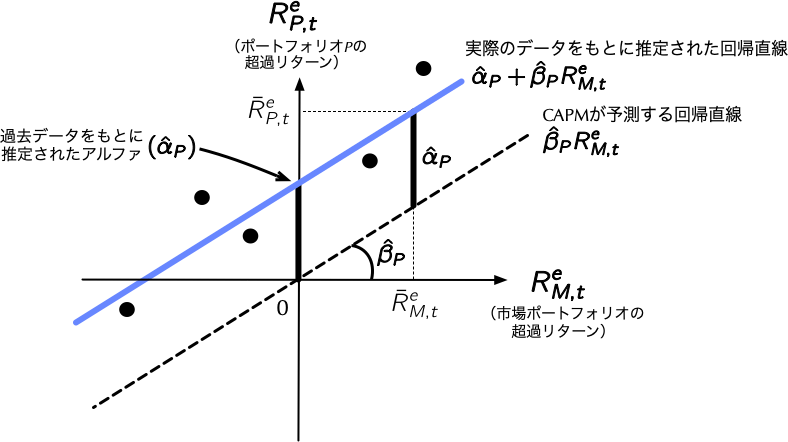
--- title: "14 最終レポートの説明" date: 2024/07/12 format: html: default --- ## 概要 {data-name="概要"} - 提出期限は,2024年8月2日(金)23:55とし,提出先はBEEF+の指定された場所(財務会計・管理会計別々)とします.- ファイル形式は,`.qmd` ファイル(あるいは`.Rmd` ファイル)とし,ファイル名は`ID_学籍番号` とすること.- 採点基準は,(1)指示通りのことを実現するコードが書けているか否か,及び(2)コードの可読性,(3) 結果の解釈である。(2) は,第三者が提出されたコードを見たとき,なぜそのようなコードを書いているかのが一目瞭然に分かるかどうかにより評価する.したがって,適宜適切にコード内にコメントを付すこと.適切なコメントは,第三者による可読性を高めるほか,再現可能性の向上にも寄与するものである.## 課題1(財務会計) {data-name="課題1"} - 本課題の目的は,会計研究の金字塔とも呼ぶのに相応しい @1996_Sloan の分析をシミュレーション・データにより追試するを通じて,実践的な財務・株式データのハンドリング,及び会計情報の株式市場での役立ちに精通することである.### 問題1 - 現行の発生主義会計によって計算される会計利益は,二つの構成要素に分けることができる.すなわち,(1)営業活動によるキャッシュ・フロー要素と(2)それ以外のアクルーアルズ(会計発生高)要素である.前者は,当期純利益のうち営業活動によって現金増加の裏付けのある金額を示し,他方,後者は,それ以外の金額を表す.したがって,同額の当期純利益を計上する二つの企業があったとしても,前者が多く,後者が少ない企業の当期純利益は質が高い一方で,後者が大部分を占める企業の当期純利益は質が低いと見なすことができる.- シミュレーション・データ[ `financial_data.csv` ](https://www.dropbox.com/scl/fi/g6qqm3faxt5t2j9258r79/financial_data.csv?rlkey=1wk1t1a437itez5j89jo9cam8&dl=0) を利用し、以下で定義される各変数を計算し、 @1996_Sloan のTABLE 1のPanel Aを再現し、自身で作成した`output` フォルダに`table1.csv` として出力せよ.\\ \\ - ただし,$\text{Cash-Flow from Operation}_{j,t}$は企業$j$の$t$期の営業活動によるキャッシュ・フロー,$\text{X}_{j,t}$は当期純利益,$\text{TA}_{j,t-1}$は$t-1$時点(すなわち,$t-1$期末)の資産合計をそれぞれ表す.- 本課題全体を通じて,分析対象は,上記の三変数が計算可能で,かつ,3月末決算企業としよう.- 表の形式は問わない(例えば,1列目にポートフォリオ・ランキング,2列目以降に各変数の平均値と中央値を配置する形式でも構わない)一方,年度ごとに$\text{Accruals}_{j,t}$に応じてポートフォリオ・ソートを行い,十個のポートフォリオのそれぞれについて,各変数の平均値と中央値を報告すること.また,桁数は小数第三位まで表示すること.- `financial_data.csv` に収録されている各項目の概要は,以下の通りである.財務項目については,全て百万円単位で収録されている.### 問題2 - @1996_Sloan の仮説1は,次の通りである.- これは,かみ砕いて言うと,「当期利益の質が低い高アクルーアルズ企業(裏を返せば,低営業キャッシュ・フロー企業)ほど,将来の利益が相対的に低迷する」という仮説である.この仮説を検証するために,`ggplot2` を用いて,\cite{1996_Sloan}のFIGURE 1を再現せよ.図の形式は問わない一方,それぞれの折れ線グラフが,いずれのポートフォリオのものを指すかが明確になるように,凡例を適切に設定すること.また,$x$軸と$y$軸のラベルは,原論文に従い,それぞれ`Event Year` と`Mean Earnings` としよう.- 2005年から2012年のそれぞれの年度において,$\text{Net Income}_{j,t}$,$\text{Accruals}_{j,t}$,$\text{Cash-Flow}_{j,t}$の大きさに応じてポートフォリオ・ソートを行い,両極端なポートフォリオ,すなわち,第1十分位と第10十分位ポートフォリオに属する企業の平均的な$\text{Net Income}_{j,t}$を前後5期にわたって計算し,それを描画すること.したがって,手順としては年度$t$において各変数の大きさに応じて十分位ポートフォリオを作成し,各企業の$\text{Net Income}_{j,t - 5}$から$\text{Net Income}_{j,t + 5}$を求める.あとは,$t-5$期から$t+5$期の11期間にわたって,それをポートフォリオごとに集計することでグラフを描画することができる.- 三つのグラフが完成したら,それを一つの`png` ファイルへと集約し,自身で作成した`output` フォルダに`figure1.png` として出力せよ.### 問題3 - 仮説1が示唆する通り,高アクルーアルズ企業ほど,将来的に利益が低迷するという現象は,実は国を問わず,広く観察される.このようなアクルーアルズの性質は,広く知られた事実であり,投資家が合理的である限り,高アクルーアルズ企業の株価は低く付され,反対に低アクルーアルズ企業の株価は高く付されるはずである.ただし,もし投資家が,利益の質を考慮せず(アクルーアルズの多寡を無視して),当期純利益だけを見てナイーブに投資しているとすれば,高アクルーアルズ銘柄も低アクルーアルズ銘柄も同じように評価されることになる.結果として,当初,高(低)アクルーアルズ銘柄の株価,割高(割安)に形成され,将来的にその銘柄のリターンは低下(上昇)することになる.こうした背景から, @1996_Sloan は,仮説2(ii)の仮説を提示している.- この仮説を検証するため, @1996_Sloan は,年度ごとに$\text{Accruals}_{j,t}$に基づいてポートフォリオ・ソートを行い,ポートフォリオ内の各銘柄に等金額を配分する等加重ポートフォリオを形成した.ポートフォリオ形成後,12ヶ月間にわたるリターンを計算しては,またポートフォリオを組み直す(これを**リバランス**と言う)という戦略を分析対象期間を通じて行い,確かに高(低)アクルーアルズ・ポートフォリオほど,将来リターンが低い(高い)傾向にあることを明らかにし,仮説2(ii)を支持する証拠を得た.- その分析に用いられているのが,CAPMアルファである.各ポートフォリオについて,分析対象期間にわたって実現超過リターン$R_{P,t}^{e}$が毎月得られるわけであるから,CAPMを前提として**時系列回帰**\footnote{講義資料第9回参照.} (time-series regression)を実行することにより,各ポートフォリオのCAPMアルファ$\alpha_{P}$を推定することができる.- 教科書第6.4節で述べているように,証券投資の実務においては,アルファはファンド運用者の運用スキルの評価基準として利用される.その理由は,CAPMを始めとするファクター・モデルは,ファンド運用のリスクに応じた適切なリターンのベンチマークとして利用されており,アルファはファンド運用者の固有の付加価値を表すものとして,彼らの報酬決定の基準となるからである.すなわち,実現超過リターンの平均値は,(1)CAPMを前提として,そのポートフォリオのリスクに応じたリターン$\hat{\beta}_{P}\bar{R}_{M}^{e}$と(2)それを更に超えたリターン$\hat{\alpha}_{P}$に分解することができるので,正のアルファが得られるポートフォリオに投資したファンド運用者はリスクに応じたリターンを超える異常なリターンを獲得したと賞賛されることになるのである.- 高(低)アクルーアルズ・ポートフォリオほど,低い(高い)アルファが得られるのかを分析することで仮説2(ii)を検証してみよう.最初に各$t$年3月期の$\text{Accruals}_{j,t}$を基に十分位ポートフォリオを作成しよう.有価証券報告書は一般的に決算期末から起算して90日以内に公表されることを鑑み,実際にポートフォリオを運用する期間は$t$年7月から$t+1$年6月の12ヶ月間とする.このように,決算期末からポートフォリオの運用を始めるまで三ヶ月のラグを置くことによって,投資家が決算短信や有価証券報告書を通じて,間違いなくアクルーアルズ情報を知っていることを保証する.それでもなお,既知のアクルーアルズが,将来リターンを予測できるか否かがこの問題の焦点である.- 各銘柄への投資ウェイトは同額としよう.分析対象期間にわたって,年一回リバランスを行い,各月各ポートフォリオの実現超過リターンをベースにCAPMアルファを推定すると共に,各ポートフォリオの平均実現超過リターンとCAPMアルファを報告すると共に,それぞれの$t$値を一覧表にまとめ,`output` フォルダに`table2.csv` として出力せよ.表の形式は問わないが,平均実現超過リターンとCAPMアルファは小数第三位まで,$t$値は小数第二位まで表示すること.- それに加えて,ポートフォリオごとのCAPMアルファを棒グラフにより描画し,それを`output` フォルダに`figure2.png` として出力せよ.なお,$x$軸と$y$軸のラベルは,それぞれ`Portfolio Accruals Ranking` と`CAPM alpha` とすること.- なお,各月の無リスク金利`R_F` や市場ポートフォリオの超過リターン$R_{M} - R_{F}$ (`R_Me` )に関する情報は[ `factor_data.csv` ](https://www.dropbox.com/scl/fi/mnh5q4bfghpnfocmd1f0o/factor_data.csv?rlkey=0blq5aymoas8h0b78m4n2scls&dl=0) に,個別銘柄の株式データは[ `stock_data.csv` ](https://www.dropbox.com/scl/fi/d6txxkv0f0gfy455l9bwp/stock_data.csv?rlkey=00150yd219v20rfyyrlaympa9&dl=0) に収録されている.`stock_data.csv` 内に収録されている各項目は,以下の通りである.なお,各CSVファイルに収録されているリターンは,全て%表示であることに注意すること.`month` | 年月 (YYYY-MM形式) |`stock_price` | 株価 |`shares_outstanding` | 発行済株式数 |`R` | トータル・リターン |#### ヒント! - **`lubridate`を利用した日付処理:** 日付データを扱う際には,`financial_data.csv` の`acc` や`stock_data.csv` の`month` のようなデータを処理するために,`lubridate` パッケージが非常に便利である.このパッケージは日付操作を簡略化し,分析をより効率的に遂行するのを手助けしてくれる.- **決算月数が12ヶ月の観測値のフィルタリング:** Accrualsのようなフロー測定を計算する際には,必ず12ヶ月の会計年度を持つ企業のみを分析に含めることが重要である.企業は会計期末をしばしば変更するため,このステップを踏むことにより,各変数について,全社横並びでの比較ができるようになる.- **ラグ変数の取り扱い:** ラグ変数を計算する際には,前期の会計基準フラグ`secflg` に特に注意を払う必要がある.`secflg` が一貫している場合にのみラグ変数を計算することが重要である.これを怠ると,誤った解釈や歪んだ結果を招く可能性があるので,注意が必要である.## 課題2(管理会計) {data-name="課題2"} [ データのページ ](/data/index.qmd) 第14回にあります。### 設定 ```{r} #| echo: false #| output: false options (scipen = 999 ):: p_load (tidyverse, magrittr, readxl, kableExtra,modelsummary,tinytable, here, patchwork, ggpubr)set.seed (1 )<- function (n) {# 各月に各工場が各製品を1つだけ作るようにするための組み合わせを生成 <- expand.grid (month = 1 : 12 , # 月を数字にする factory = c ("Factory1" , "Factory2" , "Factory3" ),product = c ("A" , "B" , "C" )# 必要な数の行をランダムに選択 <- combinations[sample (nrow (combinations), min (n, nrow (combinations))), ]tibble (month = selected_combinations$ month,factory = selected_combinations$ factory,product = selected_combinations$ product,quantity = round (runif (nrow (selected_combinations), 1000 , 5000 )), # 生産量を増やす material_cost = case_when (== "A" ~ round (runif (nrow (selected_combinations), 50 , 100 ) * quantity + runif (nrow (selected_combinations), 10000 , 20000 )),== "B" ~ round (runif (nrow (selected_combinations), 60 , 110 ) * quantity + runif (nrow (selected_combinations), 12000 , 22000 )),== "C" ~ round (runif (nrow (selected_combinations), 70 , 120 ) * quantity + runif (nrow (selected_combinations), 15000 , 25000 ))labor_cost = case_when (== "A" ~ round (runif (nrow (selected_combinations), 30 , 60 ) * quantity + runif (nrow (selected_combinations), 10000 , 20000 )),== "B" ~ round (runif (nrow (selected_combinations), 40 , 70 ) * quantity + runif (nrow (selected_combinations), 12000 , 22000 )),== "C" ~ round (runif (nrow (selected_combinations), 50 , 80 ) * quantity + runif (nrow (selected_combinations), 15000 , 25000 ))overhead_cost = case_when (== "A" ~ round (runif (nrow (selected_combinations), 20 , 40 ) * quantity + runif (nrow (selected_combinations), 15000 , 25000 )),== "B" ~ round (runif (nrow (selected_combinations), 30 , 50 ) * quantity + runif (nrow (selected_combinations), 18000 , 28000 )),== "C" ~ round (runif (nrow (selected_combinations), 40 , 60 ) * quantity + runif (nrow (selected_combinations), 20000 , 30000 ))other_cost = case_when (== "A" ~ round (runif (nrow (selected_combinations), 10 , 20 ) * quantity + runif (nrow (selected_combinations), 5000 , 10000 )),== "B" ~ round (runif (nrow (selected_combinations), 15 , 25 ) * quantity + runif (nrow (selected_combinations), 6000 , 12000 )),== "C" ~ round (runif (nrow (selected_combinations), 20 , 30 ) * quantity + runif (nrow (selected_combinations), 7000 , 15000 ))%>% mutate (total_cost = material_cost + labor_cost + overhead_cost + other_cost)<- generate_data (180 )<- data |> arrange (factory, month)<- unique (data$ factory)for (factory in factories) {<- data %>% filter (factory == !! factory)# 費目が行、月が列になるように変形し、製品ごとに分割 <- factory_data %>% select (month, product, quantity, material_cost, labor_cost, overhead_cost, other_cost, total_cost) %>% pivot_longer (cols = c (quantity, material_cost, labor_cost, overhead_cost, other_cost, total_cost), names_to = "cost_type" , values_to = "cost" ) %>% unite ("item" , product, cost_type, sep = "_" ) %>% pivot_wider (names_from = month, values_from = cost, values_fill = list (cost = 0 )) |> separate (item, into = c ("product" , "cost_type" ), sep = "_" ) |> arrange (product)# ファイルに保存 write_csv (transformed_data, here (paste0 ("data/" ,factory, ".csv" )))# 予算データの生成関数 <- function (data) {%>% mutate (material_budget = round (material_cost * runif (nrow (data), 0.9 , 1.1 )),labor_budget = round (labor_cost * runif (nrow (data), 0.9 , 1.1 )),overhead_budget = round (overhead_cost * runif (nrow (data), 0.9 , 1.1 )),other_budget = round (other_cost * runif (nrow (data), 0.9 , 1.1 ))%>% mutate (total_budget = material_budget + labor_budget + overhead_budget + other_budget)# 実績データから予算データを生成 <- generate_budget (data) |> select (factory, product, ends_with ("_budget" ))<- c (A = 180 , B = 235 , C = 300 )``` ### 問題1 `data` とし,各費目の列名は`cost_type` 列に入っている費目名をそのまま使ってください。月は`month` ,工場は`factory` という名前の列名をつけてください。`product` | 製品を識別する変数 | `overhead` | 間接費 |`quantity` | 生産量 | `other` | その他費用 |`material` | 原材料費 | `total` | 総費用 |`labor` | 人件費 | | |`cost_type` に入っている変数`month` | 月 | `factory` | 工場を識別する変数 |#### ヒント - 各ファイルでは,列が月,製品別の生産量・費目が行になっています。これを修正する必要があります。- データの中に,どの工場のデータかを識別する情報は入っていません。各工場のデータを結合する前に,工場を識別するための変数を作っておく必要があります。```{r} # 工場ごとのファイルを読み込み、元の形式に戻す <- c ("Factory1" , "Factory2" , "Factory3" )<- list ()for (factory in factories) {# ファイルを読み込む <- read_csv (here ("data" , paste0 (factory, ".csv" )))# データを元の形式に戻す <- factory_data %>% pivot_longer (cols = c (- product,- cost_type), names_to = "month" , values_to = "cost" ) |> pivot_wider (names_from = cost_type, values_from = cost)# 工場名を追加 <- factory_data_modified %>% mutate (factory = factory)# データをリストに追加 <- factory_data_modified# リストのデータを結合 <- bind_rows (all_data)``` ### 問題2 1. まず,企業全体の固定費と変動費の構造を推定します。その準備として全工場での各月の合計生産量(`quantity_month` )と総費用(`total_month` )を算出し,企業・月単位のデータ(`data_month` )を作ってください。2. 最小二乗法で固定費と変動費率を推定してください。推定結果から,この企業のコスト構造について説明してください。3. この企業の製品の平均価格を,1年間で作った各製品の生産量と製品価格を使った加重平均で算出してください。4. 費用関数と売上関数を図示してください。x軸は生産量(`quantity_month` ),y軸は総費用(`total_month` )としてください。x軸は"`Quantity` " y軸は"`Amount of Money` "というラベルをつけてください。5. 損益分岐点を計算してください。6. この企業の目標売上高利益率(利益は売上高 - 総費用で計算)は10%です。目標を達成するために必要な数量を計算してください。7. 損益分岐点の数量,目標利益率の数量と実績を見比べて現状を分析してください。#### ヒント `data` は月×工場×製品単位ですが,`data_month` は,月単位のデータです。なので,加工前のデータは12ヶ月×3工場×3製品の108行あるはずですが,`data_month` の行数は12になるはずです。重複した行を削除するコマンドとしては,`distinct()` などがあります。#### 2-1. ```{r} #月毎の業績変数を作成 <- data |> group_by (month) |> summarise (total_month = sum (total),quantity_month = sum (quantity)) |> ungroup () <- data_month |> mutate (month = as.numeric (month)) <- data_month |> arrange (month)``` #### 2-2. ```{r} ##回帰分析 <- lm (total_month ~ quantity_month, data = data_month)summary (cost_line)``` #### 2-3. ```{r} <- c ("A" , "B" , "C" )<- c (A = 180 , B = 235 , C = 300 )# 各製品の数量と価格を計算して合計 <- data |> filter (product %in% products) |> group_by (product) |> summarise (total_quantity = sum (quantity, na.rm = TRUE ),total_value = sum (quantity * product_prices[product], na.rm = TRUE )) |> ungroup ()# 全製品の合計数量と合計価格を計算 <- sum (total_summary$ total_quantity)<- sum (total_summary$ total_value)# 平均価格を計算 <- total_value / total_quantity``` #### 2-4. ```{r} |> ggplot (aes (x = quantity_month, y = total_month)) + geom_smooth (method = "lm" , se = FALSE ,fullrange = TRUE ) + geom_abline (slope = av_price, intercept = 0 ,linetype = "dashed" ) + scale_x_continuous (limits = c (15000 , 30000 ),breaks = seq (15000 , 30000 , by = 2000 )) + scale_y_continuous (limits = c (4000000 , 7000000 )) + xlab ("Quantity" ) + ylab ("Amount of Money" )``` #### 2-5. ```{r} <- matrix (c (coef (cost_line)["quantity_month" ], - 1 ,- 1 ), nrow = 2 , byrow = TRUE )<- matrix (c (- coef (cost_line)["(Intercept)" ], 0 ), nrow = 2 , byrow = TRUE )<- solve (a,b)<- ceiling (ans[1 ])``` `{r} ans_1` #### 2-6. \\ \\ \\ \\ \\ ```{r} <- matrix (c (coef (cost_line)["quantity_month" ], - 0.9 ,- 1 ), nrow = 2 , byrow = TRUE )<- matrix (c (- coef (cost_line)["(Intercept)" ], 0 ), nrow = 2 , byrow = TRUE )<- solve (a,b)<- ceiling (ans[1 ])``` `{r} ans_2` #### 2-7. ```{r} |> ggplot (aes (x = quantity_month, y = total_month)) + geom_point ()+ geom_smooth (method = "lm" , se = FALSE ,fullrange = TRUE ) + geom_abline (slope = av_price, intercept = 0 ,linetype = "dashed" ) + scale_x_continuous (limits = c (19000 , 32000 ),breaks = seq (19000 , 32000 , by = 1000 )) + scale_y_continuous (limits = c (4000000 , 7000000 )) + geom_vline (xintercept = ans_2) + geom_vline (xintercept = ans_1)``` ### ### 問題3 1. 製品別の固定費・変動費を最小二乗法で推定してください。2. それぞれの製品の損益分岐点を計算してください。3. 製品ごとの特徴を考察してください。#### 3-1. ```{r} #月毎の業績変数を作成 <- data |> group_by (month, product) |> summarise (total_month = sum (total),quantity_month = sum (quantity)) |> ungroup () # 製品名を指定するベクトル <- c ("A" , "B" , "C" )<- list ()# 製品ごとに回帰分析をループして,リストに追加 for (p in products) {<- data_month_p |> filter (product == p) |> lm (total_month ~ quantity_month, data = _)msummary (models_p)``` #### 3-2. ```{r} <- coef (models_p[["A" ]])["(Intercept)" ] / "A" ] - coef (models_p[["A" ]])["quantity_month" ])<- coef (models_p[["B" ]])["(Intercept)" ] / "B" ] - coef (models_p[["B" ]])["quantity_month" ])<- coef (models_p[["C" ]])["(Intercept)" ] / "C" ] - coef (models_p[["C" ]])["quantity_month" ])<- unname (bep_A)<- unname (bep_B)<- unname (bep_C)``` #### 3-3. ### 問題4 (ボーナス点) ## 必須問題ではありません ## 参考文献 {data-name="参考文献"}