--- title: "10 管理会計で用いるデータとその分析" date: 2024/06/14 author: 佐久間智広 format: html: df-print: paged code-fold: true revealjs: output-file: 10_mgt_slide.html df-print: paged echo: true --- ## 管理会計って何だった? {data-name="管理会計って"} > 企業の構想実現のために会社で使われる仕組み - 組織の構想実現のために企業内で整備される仕組み- 企業のデータを構想実現に役立てる仕組み- 会計データをはじめとしたデータを経営管理のために使う### 企業のデータを経営管理に使う #### 企業のデータ? #### 財務データ {.unnumbered} - 売上原価原価- 人件費- 研究開発費- 広告宣伝費- 売上高#### 非財務データ {.unnumbered} - 人事評価データ- 良品率(不良品率)- 顧客満足度- 従業員満足度- 研修参加率 {fig-align="right" width="350"}#### 経営管理に使う? [ @luft2009; @grafton2010; @itami2016 ] \- 目標数値を設定- 目標を達成したかどうかで評価- 評価に応じて昇給やボーナス,昇進を決める- 新規事業AとBどちらに参入する?- 新しい工場・設備を導入する?- 自社で作る?外注する?- 撤退する?継続する?- 広告宣伝費にいくらかける?### 経営管理 ### 会計の中の管理会計(再掲)  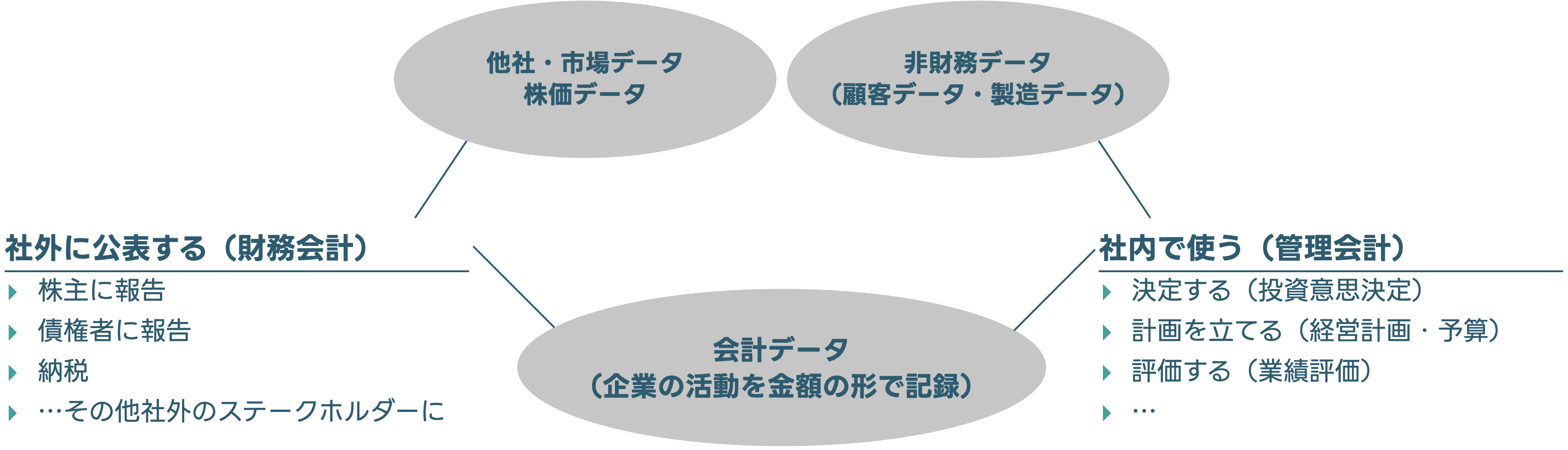 ## 管理会計に使われるデータ {data-name="データ"} ### 役立てられるデータの種類が増えている - 昔は原価計算・予算管理など財務的な指標を使うことに注目していました。- 財務指標(だけ)を使った管理会計システムの不具合,限界が指摘され [ @johnson1992 ] ,より多くの社内のデータを組み合わせた経営管理が提唱されるように [ 例えば,Balanced Scorecard @kaplan1992; @kaplan2001; @kaplan2004 ] ### データは企業内に散在 - フォーマットも会社によってバラバラです。- 使われている用語や分類方法もバラバラです。- 場合によっては単位も違います(社内通貨など)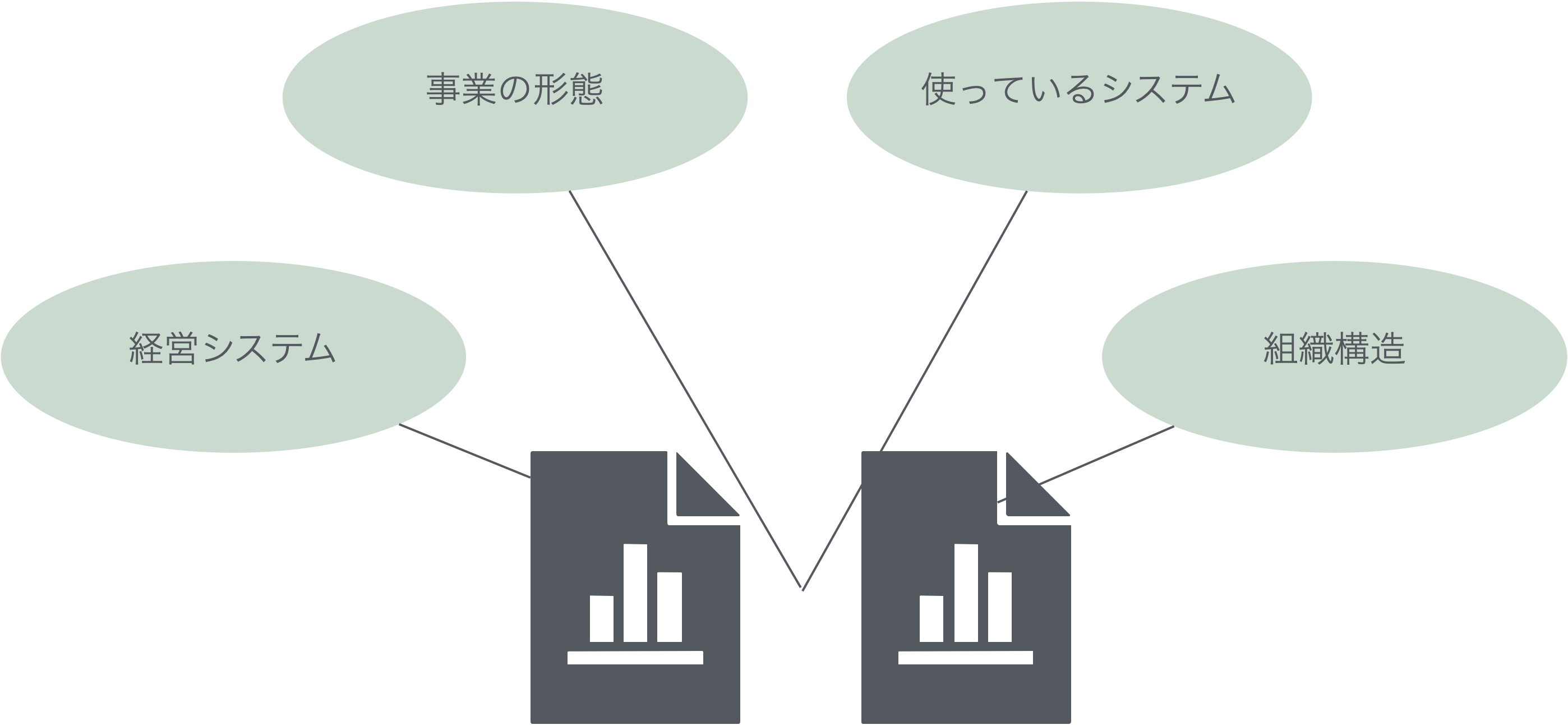 {fig-align="center" width="974"}#### 例: アメーバ経営 > 京セラで生まれ,関連企業だけでなく,KCCSマネジメントコンサルティングを通して多くの企業に導入されている経営の仕組み > > - 小集団(例えば5人とか10人とか) > - それぞれが社内外と取引する形にする > - 社内外での売り買いがあるので利益計算が可能 > > 結果として,それぞれの小集団が小さい会社のように利益追求できるように 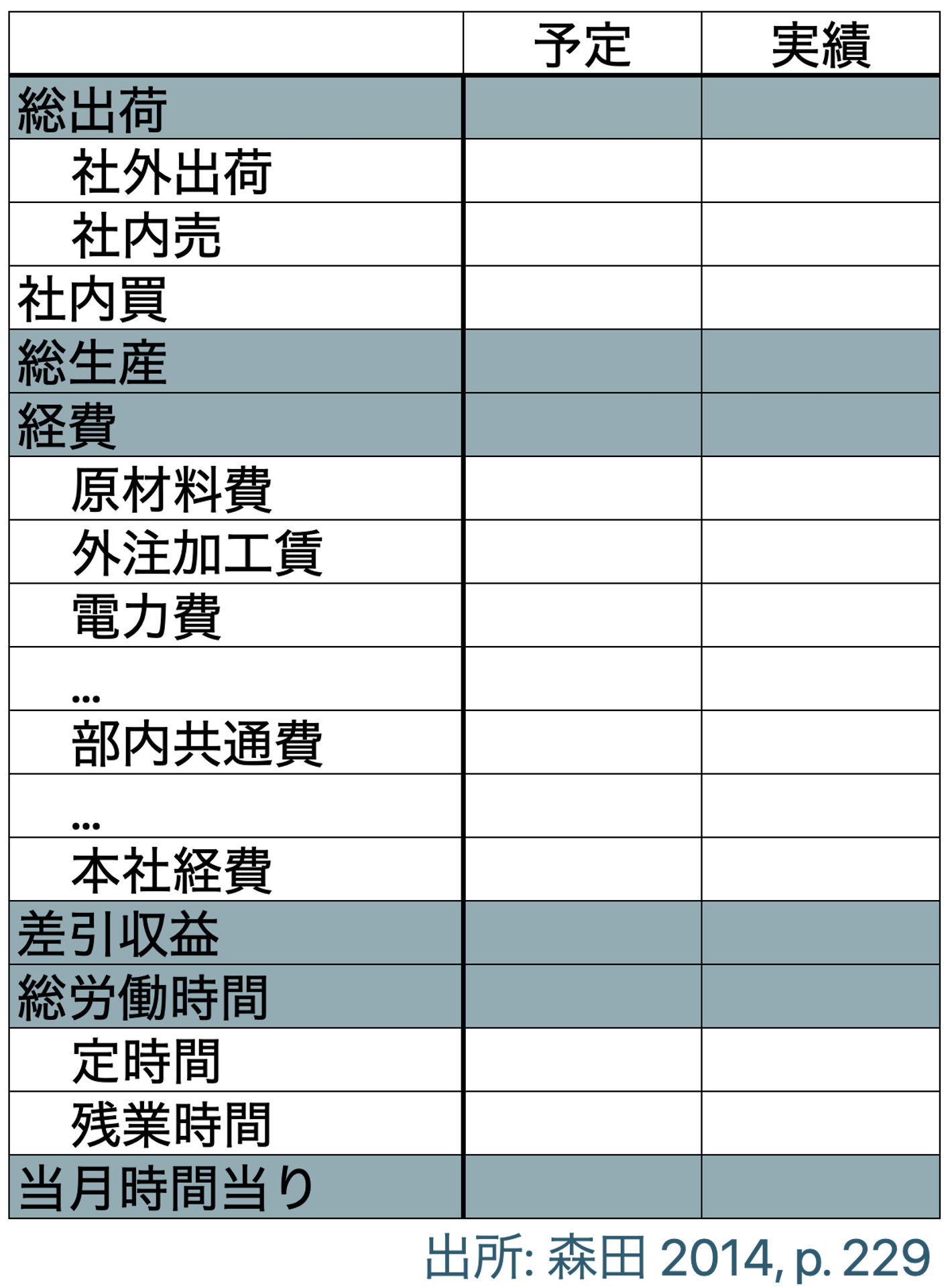 {fig-align="center" width="441"}- 収益は社外出荷と社内売- そこから社内買を差し引いて総生産- 総生産から経費(部門共通費や本社経費等を含むけれど人件費は含まない)を差し引いて差引収益- 差引収益を総労働時間で割って時間当り採算[ 一般的(簿記の仕組みで出てくる)費目の分け方や,利益の計算方法とは違う ] {.red}### 「一般的な方法」? - そもそもどんなデータをどんなふうに蓄積しているかがバラバラです。- データの役立て方も産業や企業によってバラバラです。- データを分析できる形に整形すること- 教科書的な知識になっているような分析を実装すること- 企業が本当はやりたい(けど難しい)いくつかの分析## 企業に蓄積されているデータとその形状 {data-name="形状"} - 企業内のデータは様々なフォーマットで様々な部署に点在しています。- 前半の授業では,分析に向いた形に整形されたものが使われていました。- しかし,管理会計データは大抵,分析に不向きな形で集計されています。- そこでまずデータの代表的な形について考えます。### データセットの並び方 #### 例:田中兄弟の身長 {.unnumbered} #### (分析するにあたって)よくない形 - 時系列の身長データが月ごとに別の列になっている - m1からm12は,**全て身長の数値**```{r} :: p_load (tidyverse, magrittr, readxl, kableExtra,rmarkdown,tinytable, here)<- here ("data" ,"case_wide.xlsx" ) |> read_excel ()kable (case_wide)``` #### 望ましい形 - 列が変数,行が測定単位になっている```{r} <- case_wide |> pivot_longer (starts_with ("m" ),names_to = "month" ,names_prefix = "m" ,values_to = "height" ) |> mutate (month = as.numeric (month))kable (case_widel)``` ## データセットの種類 {data-name="種類"}  {fig-align="right"}- [ クロスセクションデータ ](#クロスセクションデータ) [^1] (cross section data)- [ 時系列データ ](#時系列データ) (time-series data)- [ パネルデータ ](#パネルデータ) [^2] (panel data)[^1]: 分野によっては横断データと呼ぶこともあるようです[^2]: 分野によっては縦断データと呼ぶこともあるようです。### クロスセクションデータ {#クロスセクションデータ} - 例えば, - 1回だけとったアンケート - 1回だけやった学力テスト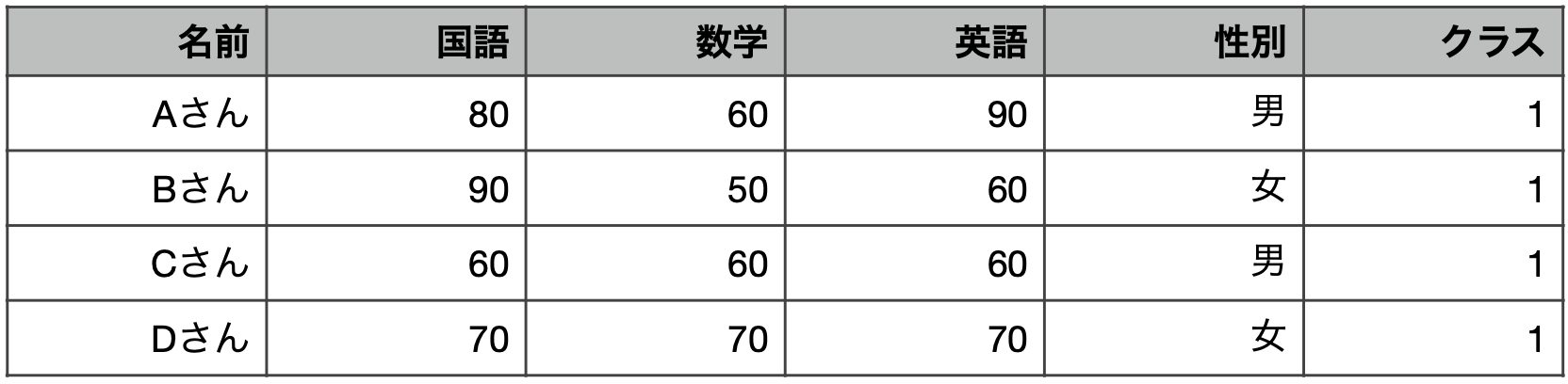 ### 時系列データ {#時系列データ} - 時系列変化がわかる](images/t3-5.png) ### パネルデータ {#パネルデータ} - クロスセクション × 時系列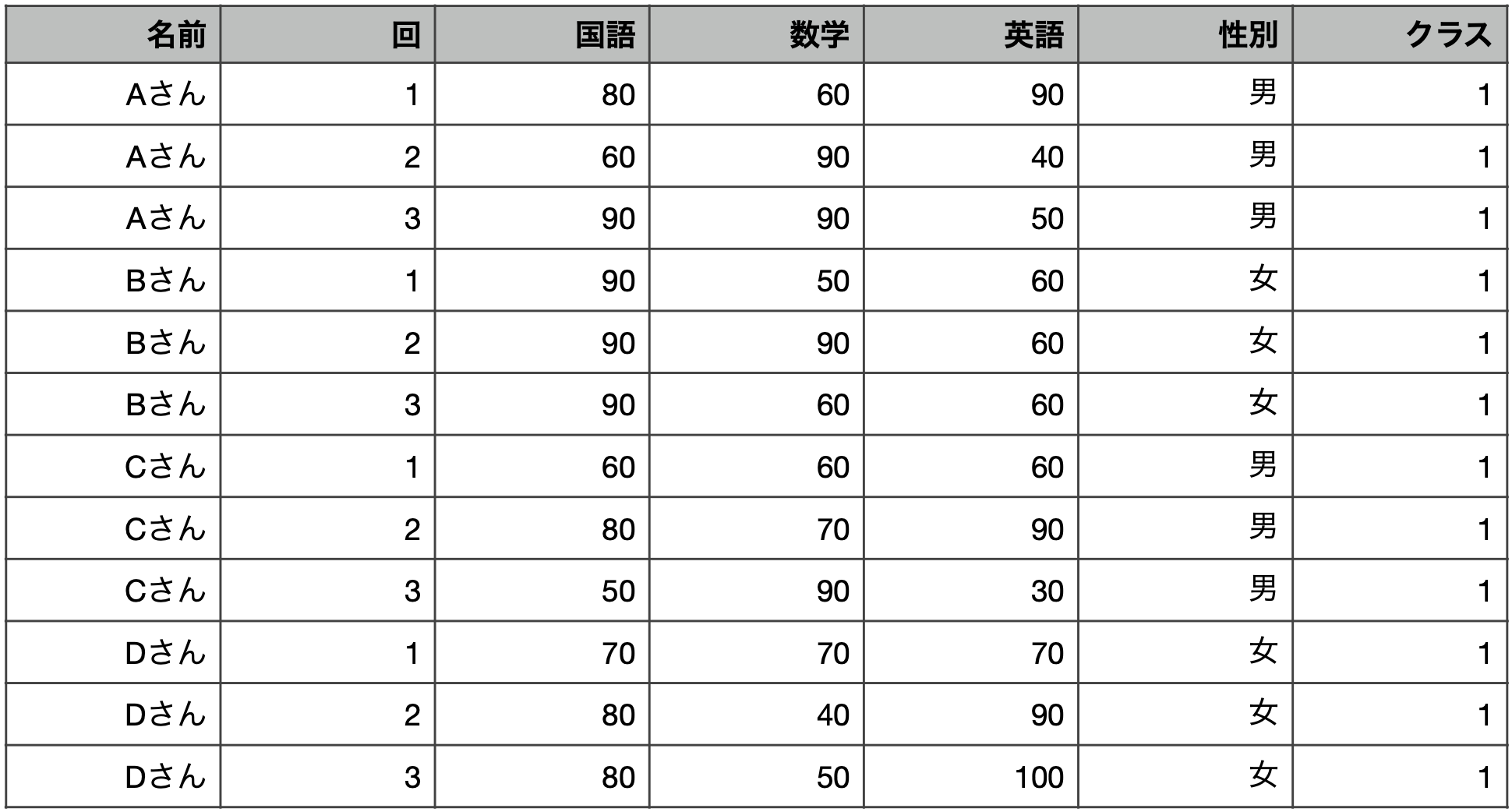 {fig-align="center" width="931"}### まとめ(データセットの種類) - データは列が変数名,行が個々のサンプルになるように並んでて欲しい- データの種類によってクロスセクション・時系列・パネルデータがある ## データの整形 {data-name="整形"} ### Case 1 : 財務諸表的並び {#case-1-財務諸表的並び} - 店舗ごとにエクセルに分かれている- 1年度の業績が費目が縦,年月が横に並んでいる- 分析可能な形に加工したい```{r} <- here ("data" ,"case1_a.xlsx" ) |> read_excel () <- here ("data" ,"case1_b.xlsx" ) |> read_excel ()<- here ("data" ,"case1_c.xlsx" ) |> read_excel ()``` - 列が変数(店舗名や費目)- 行が各月の業績数値- それが3店舗分下につながっている状態```{r} <- case1a |> select (- 合計) |> pivot_longer (cols = c (- shop_id, - shop, - himoku), names_to = "yearmonth" ) |> #<1> pivot_wider (id_cols = c (shop_id, shop, yearmonth),names_from = himoku, values_from = value) #<2> ``` 1. データを縦に伸ばす2. データを横に開く```{r} ``` #### データを縦に伸ばす - 1604から1703までの部分を結合して伸ばす`pivot_longer()` 関数を使う- ()の中で`cols =` として,結合したい列を指定する。今回は結合”**したくない**”列を取り除く形で指定してる```{r} <- case1a |> select (- 合計) |> pivot_longer (cols = c (- shop_id, - shop, - himoku), names_to = "yearmonth" )``` #### データを横に開く `pivot_wider()` 関数を使う- `id_cols` はそのまま残したい列- `names_from` 列名にしたい(引き伸ばしたい)情報が入った列- `values_from` は,列に入れたい情報が入った列```{r} <- case1al |> pivot_wider (id_cols = c (shop_id, shop, yearmonth),names_from = himoku, values_from = value)``` #### これを年数分繰り返す - ここでは,`for` ループを使って繰り返しを自動化します```{r} #| code-fold: show <- c ("data/case1_a.xlsx" , "data/case1_b.xlsx" , "data/case1_c.xlsx" )<- list ()for (file in file_list) {<- here (file) |> read_excel () #<1> <- data |> #<2> select (- 合計) |> pivot_longer (cols = c (- shop_id, - shop, - himoku), names_to = "yearmonth" ) |> pivot_wider (id_cols = c (shop_id, shop, yearmonth),names_from = himoku,values_from = value)<- bind_rows (data_list) #<3> ``` 1. データを読み込む2. 繰り返したい作業3. ファイルごとに作ったものを,縦方向に繋げる(`bind_rows()` 関数)### Case2: 財務データと人事データの結合 - 大抵の場合,店舗や支店の業績は月次で管理されるけれど,業績評価は半年単位とかで決まる- 業績評価は年度単位で期間が区切られる - 2016/4-2016/9までが前半 - 2016/10-2017/3までが後半1. 人事データを結合2. 財務データの年度と前半・後半を作成3. 財務データに人事データを結合```{r} #| echo: false <- here ("data/case2.xlsx" ) |> read_excel ()<- case2 |> select (- 合計) |> pivot_longer (cols = c (- shop_id, - shop, - himoku),names_to = "yearmonth" )|> pivot_wider (id_cols = c (shop_id, shop, yearmonth),names_from = himoku,values_from = value)<- findata |> mutate (year = as.numeric (str_sub (yearmonth, start = 1 , end = 2 )) + 2000 , #<1> month = as.numeric (str_sub (yearmonth,start = 3 ,end = 4 ))) #<2> write.csv (findata, here ("data/findata.csv" ))``` `findata.csv` と,`case3_p1.xlsx` , `case3_p2.xlsx` という三つのデータを使います```{r} <- here ("data/findata.csv" ) |> read.csv ()<- here ("data/case3_p1.xlsx" ) |> read_excel ()<- here ("data/case3_p2.xlsx" ) |> read_excel ()``` #### 人事データを結合 - 人事データ2期分は別のファイルになっている。- データを縦方向に結合する - `bind_rows()` 関数は,変数名が同じ2つのデータセットを縦方向に結合してくれる。- (企業のデータだと,ある年から名前が変わってたり,全角と半角が変わってたりする)```{r} <- bind_rows (case3_p1,case3_p2)<- person |> rename (fiscalyear = year) #<1> ``` 1. 財務データ側は暦年をyearとしているので,年度だとわかるように名前を変える#### 財務データに年度と半期識別データを作成 - `case_when()` 関数は,条件分岐させて処理を変えるための関数。 - 1, 2, 3月は前年度なので,暦年から1を差し引く- `ifelse()` 関数も条件分岐。 - 2条件ならこっちでも良い```{r} <- findata |> mutate (fiscalyear = case_when (month %in% c (1 , 2 , 3 ) ~ year - 1 ,TRUE ~ year),half = ifelse (month >= 4 & month < 10 , 1 ,2 ))``` #### データを結合 - `left_join()` 関数はExcelのvlookupみたいな挙動。- `by =` で指定した変数をキーにして,2つのデータを横向きに結合```{r} <- left_join (findata, person ,by = c ('fiscalyear' ,'half' ,'shop' ))``` ## 課題: 半パネルデータ {data-name="課題"} - `case2.xlsx` は企業の財務データです。 - [ Case 1 : 財務諸表的並び ](#case-1-財務諸表的並び) との違いは,すでに各店舗のデータがくっついている点です。- データ分析に適した形(パネルデータ)に加工してください- **コードのみ記載してください**```{r} <- here ("data/case2.xlsx" ) |> read_excel ()tt (kadai)``` ### 答え ```{r} <- kadai |> select (- 合計) |> pivot_longer (cols = c (- shop_id, - shop, - himoku),names_to = "yearmonth" )|> pivot_wider (id_cols = c (shop_id, shop, yearmonth),names_from = himoku,values_from = value)``` ## 参考文献 {.unnumbered} 






](images/t3-5.png)

