Code
rm(list=ls()); gc(); gc();
if (!require("pacman")) install.packages("pacman")
pacman::p_load(tidyverse, magrittr,
estimatr ,modelsummary)- 1
-
複数のパッケージを一度に読み込める
pacmanパッケージが入っていない場合は,インストールする - 2
- パッケージの読み込み
rm(list=ls()); gc(); gc();
if (!require("pacman")) install.packages("pacman")
pacman::p_load(tidyverse, magrittr,
estimatr ,modelsummary)pacmanパッケージが入っていない場合は,インストールする
pacman複数のパッケージを読み込めるパッケージ。そのパッケージの中のp_loadコマンドを使うと,()内に指示したパッケージを読み込める。さらにそのパッケージがそもそもインストールされていない場合にはインストールした後に読み込んでくれる
tidyverseRのコードを楽にするたくさんのパッケージをパッケージにしたもの
magrittrtidyverseに含まれる%>%などのコードをさらに拡張するもの。これがあると%$%とか%<>%が使える
データを分析する際に,知りたい人やもののすべてのデータを使うことは稀です。
代わりに,知りたい集団の一部のデータを使って全体を予測します。
これがなぜ達成可能なのかについてその背後の論理を説明します。
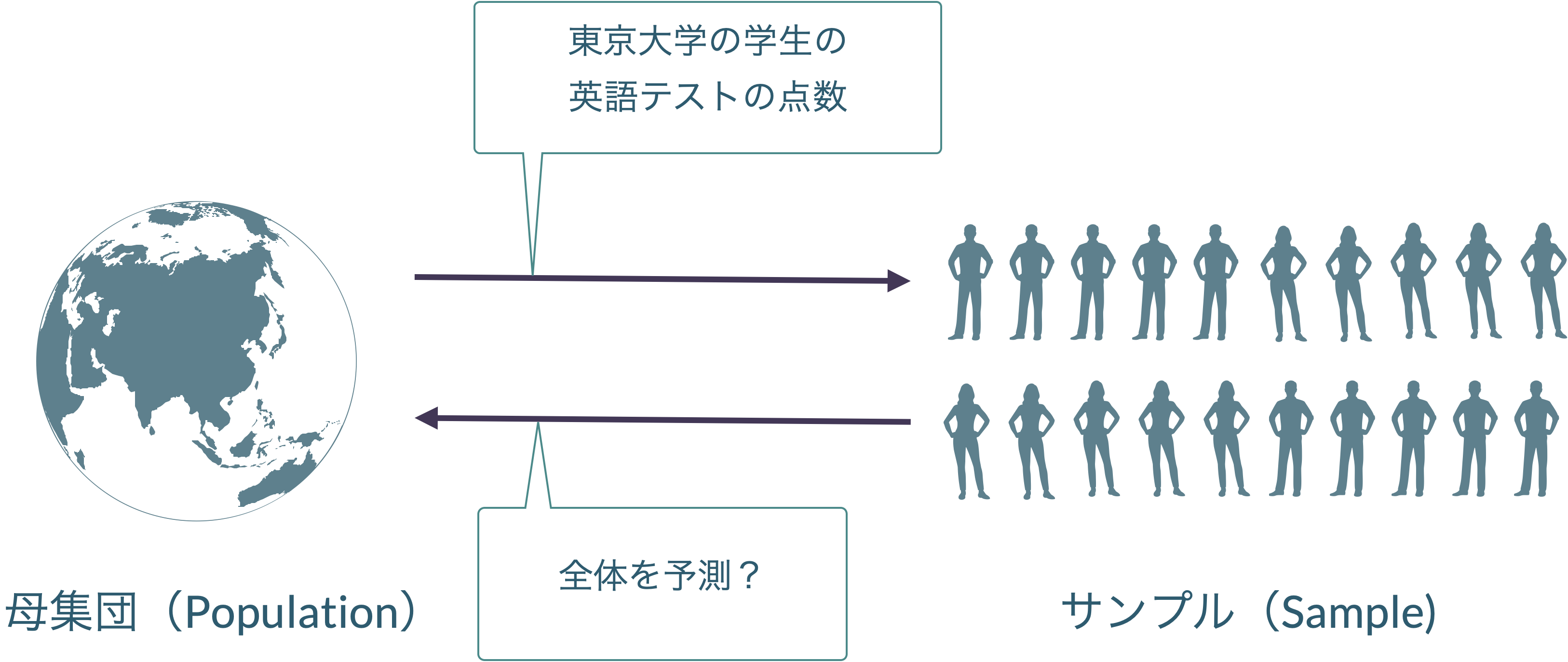
メディアでは,選挙の日に出口調査を行い,開票完了前に「当選確実」を出します。出口調査はすべての選挙会場(総務省によると全国47,000箇所以上あるそうです)に調査員を配置して,投票したすべての有権者(5,000万人以上)に投票内容を聞くのは現実的ではありません。全国の限られた数の投票所の限られた数の有権者からの意見でなぜ「当選確実」を出せるのでしょうか?
データ解析の目的は,母集団がどんな形になっているのか,標本を発生させた母集団はそもそもどんな形をしているのかを知ることにあります。
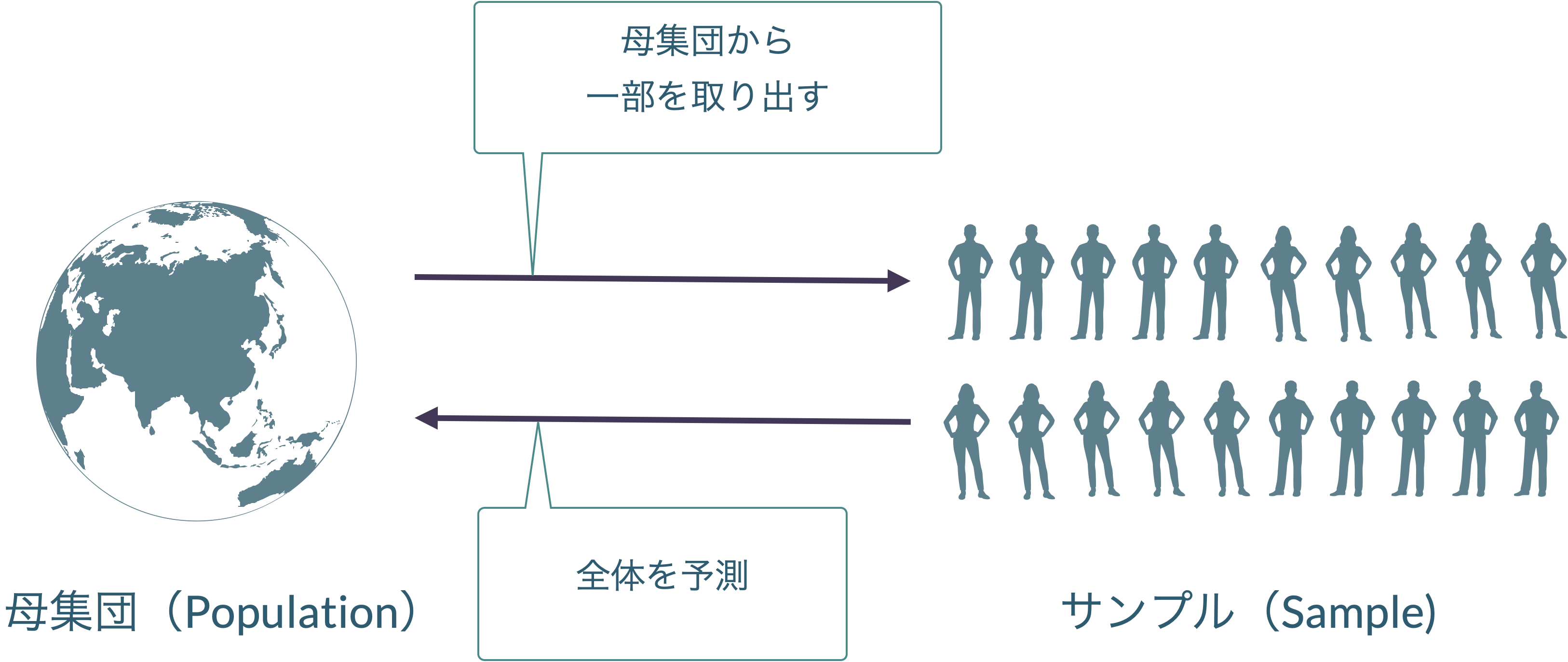
適切にデータを選ぶ,という際に重要なのが,標本が,母集団から偏りなく抽出されているということです。
データ解析の目的は,無作為標本(母集団からすると限られた情報)を使って,母集団全体の傾向を推測することにあります。
その際,母集団をモデル(様々な仮定を置いた数式)で表します。
\[ P(X=k) = {}_n C_k p^k(1-p)^{n-k} \]

標本の数値と確率モデルを利用して,母集団の分布の形を把握したい

確率モデル(確率分布)にはいくつかの便利な性質があり,それを利用することで未知の母集団の分布の形が推測できる
母集団を数学的に表現する確率分布には,様々な種類があります。
後述する理由で,一般的な分析はほとんど正規分布とそれを元にできる分布(t, \(\chi^2\), Fなど)を使います。
\[ P(X=k) = {}_n C_k p^k(1-p)^{n-k} \]
打率3割5分の人と1割5分の人がそれぞれ10回打席に立ってヒットが何本出るか?
# パラメータを指定
phi <- 0.35
# 試行回数を指定
M <- 10
x_vals <- 0:M
prob_df <- tidyr::tibble(
x = x_vals, # 確率変数
probability = dbinom(x = x_vals, size = M, prob = phi) # 確率
)
ggplot(data = prob_df, mapping = aes(x = x, y = probability)) + # データ
geom_bar(stat = "identity", position = "dodge", fill = "#00A968") + # 棒グラフ
scale_x_continuous(breaks = x_vals, labels = x_vals) + # x軸目盛
labs(title = "Binomial Distribution",
subtitle = paste0("phi=", phi, ", M=", M), # (文字列表記用)
#subtitle = parse(text = paste0("list(phi==", phi, ", M==", M, ")")), # (数式表記用)
x = "x", y = "probability") # ラベル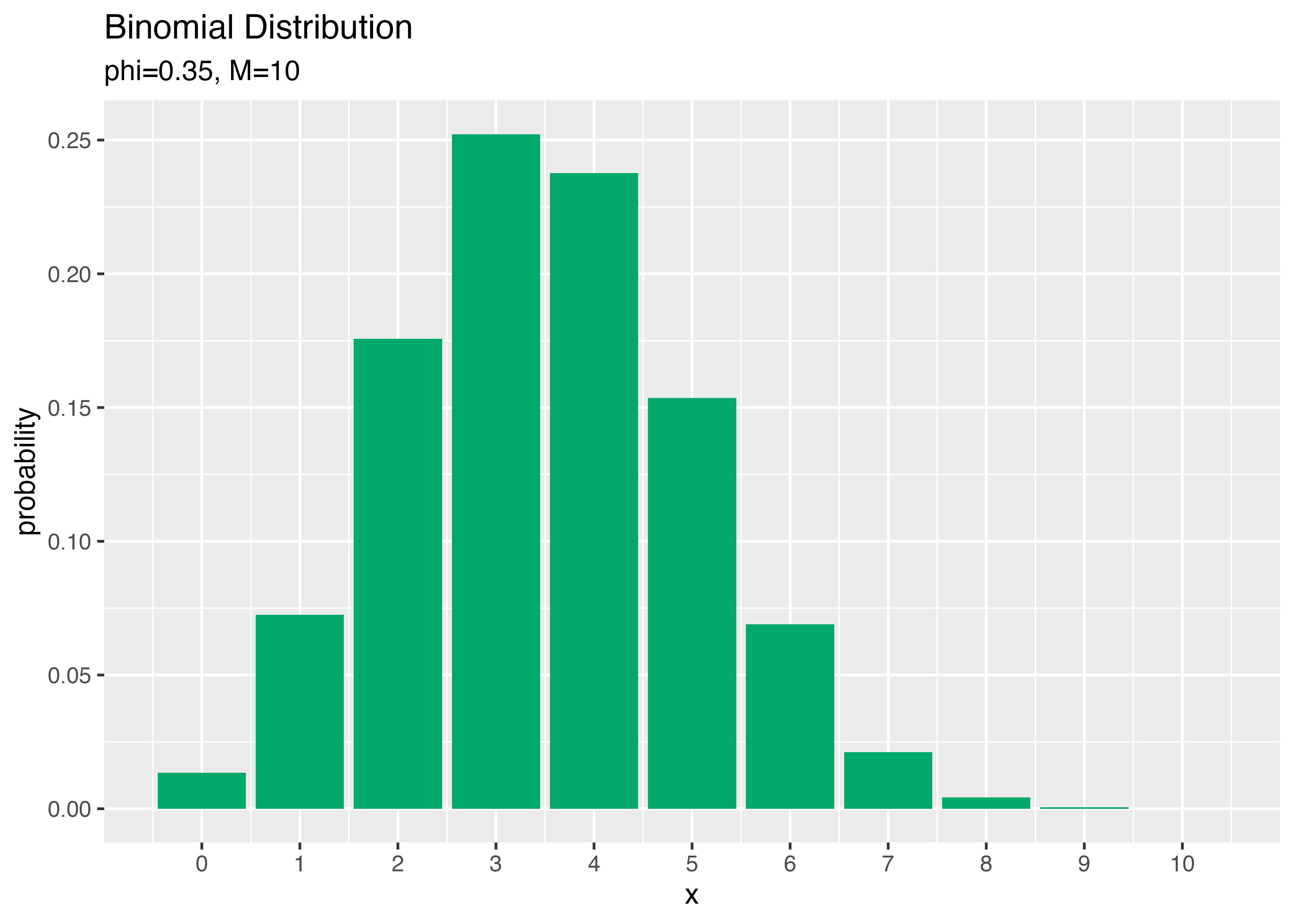
# パラメータを指定
phi <- 0.15
# 試行回数を指定
M <- 10
x_vals <- 0:M
prob_df <- tibble(
x = x_vals, # 確率変数
probability = dbinom(x = x_vals,
size = M,
prob = phi) # 確率
)
ggplot(data = prob_df,
mapping = aes(x = x,
y = probability)) + # データ
geom_bar(stat = "identity",
position = "dodge",
fill = "#00A968") + # 棒グラフ
scale_x_continuous(breaks = x_vals,
labels = x_vals) + # x軸目盛
labs(title = "Binomial Distribution",
subtitle = paste0("phi=", phi, ", M=", M), # (文字列表記用)
#subtitle = parse(text = paste0("list(phi==", phi, ", M==", M, ")")), # (数式表記用)
x = "x", y = "probability") # ラベル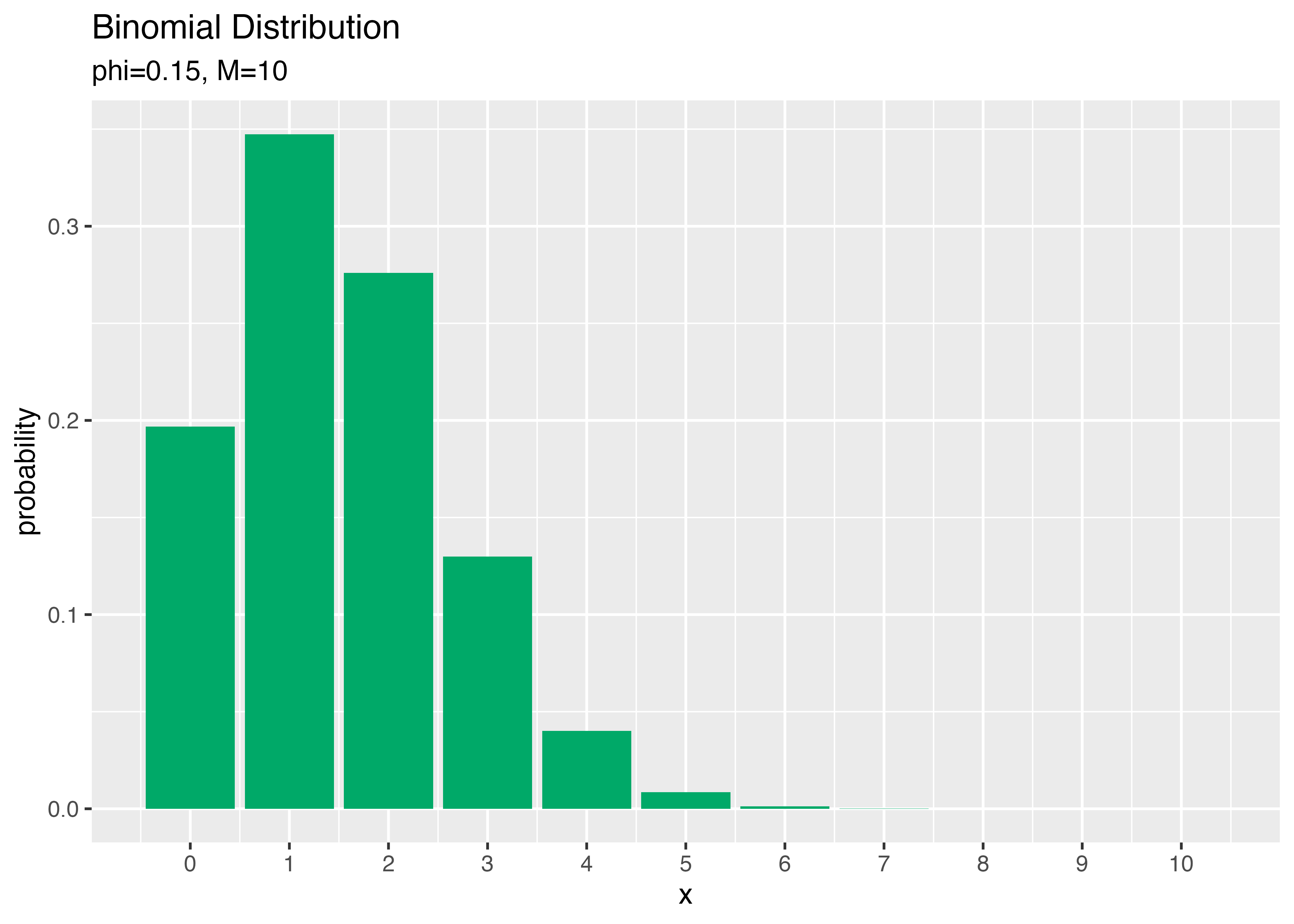
身長などの身体測定値や測定誤差など様々な場面に現れる分布。あとで使う望ましい性質がある。平均 \(\mu\),分散\(\sigma^2\) として,\(\mathcal{N}(\mu,\sigma^2)\) と標記
\[ f(x)= \frac{1}{\sqrt {2 \pi \sigma^2 }} \exp \left(- \frac{(x- \mu)^2}{2\sigma^2} \right) \]
特に平均0、分散1の正規分布を標準正規分布と呼ぶ
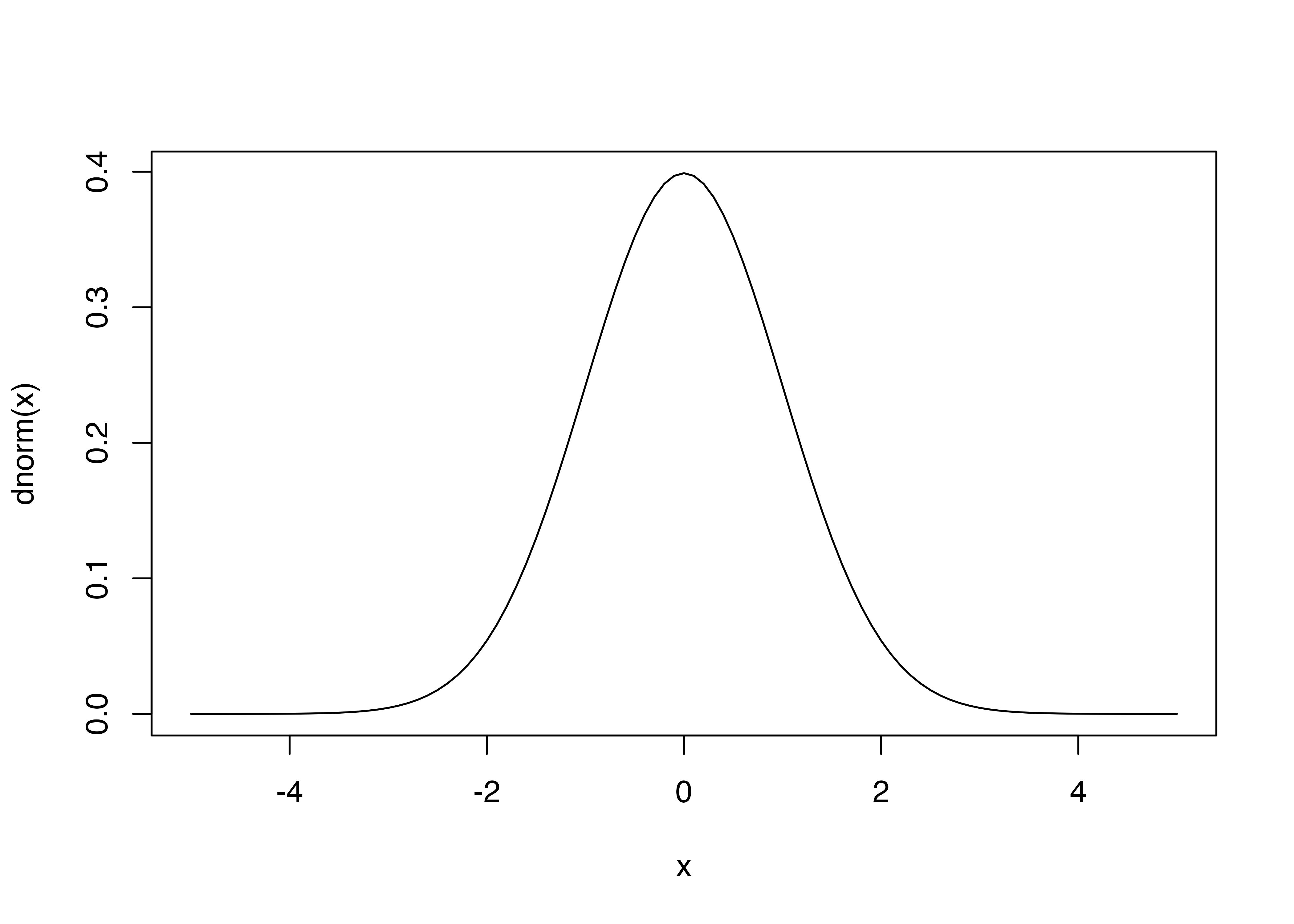
例えば,小学校1年生の児童の身長が,平均\(\mu=118\), 分散\(\sigma^2=6^2\)の正規分布に従っているとすると, \(118 \pm 6 cm\)の範囲に68.3%, \(118 \pm 12 cm\)の範囲に95.4%の児童が入ることが予測できる。
あるテストの結果が平均点が55点,標準偏差15の正規分布に従っているとすると,\(55 \pm 15\)つまり偏差値40-60の範囲内に68.3%が入る。55+15 = 70点の人は偏差値60で,上位15.85%あたり( %6%)。85点の人は,偏差値70で,上位2.3%あたり。
サンプリングをうまくやって,確率分布の望ましい性質を使って解決する!

\[ \bar X = (X_1 + X_2 + ... X_n )/n = \frac{1}{n} \sum_{i=1}^{n} X_i \]
\[ \begin{split} s_X^2 &= \frac{1}{n-1}\{(X_1 - \bar X)^2+(X_2 - \bar X)^2+(X_3 - \bar X)^2+...(X_n - \bar X)^2 \} \\ &= \frac{1}{n-1}\Sigma (X_i - \bar X)^2 \end{split} \]
ある母集団から得た標本があります。母集団全体の平均(母平均)を \(\mu\) とします。この \(\mu\) は未知です。
ここで,標本観測と母平均との関係を以下のように想定します。
\[ X_i = \mu+u_i, u_i \sim N(0,\sigma ^2) \]
ただし\(u_1,u_2,u_3...u_n\)は互いに独立(前の数字に後からでてくる数字が影響を受けない)
このとき,以下の性質が知られています。
標本平均の不偏性は,どんな分布でも成り立つことがわかっています。
要するに…うまくサンプルをとることができれば,標本平均を使って母平均を推測できるということです。
要するに…うまくサンプルをとることができれば,不偏分散を使って母分散を推測できるということです。
母集団から無作為に抽出された標本の平均値は,標本の大きさが大きいほど,母集団平均に近い値を取る法則
\(n\)を大きくすると,標本平均\(\bar X = (X_1 + X_2 + ... X_n )/n = \frac{1}{n} \sum_{i=1}^{n} X_i\) は真の平均に近づく
\[ \bar X \to \mu \]
サイコロには1から6までの目があり,それぞれが出る確率は1/6です。したがって,母集団の平均は,
\[ \frac{1}{6}\sum^6_{i=1}i=\frac{21}{6}=3.5 \]
サイコロを10回振った時
s10 <- sample(1:6, 10, replace = TRUE)
mean(s10)sample()は,決められた数の標本を無作為に選び出す関数です。ここでは,1から6までの数を無作為に10個選び出しています。replaceは復元抽出をするかしないかを指定するオプションです。「1から6までの数を無作為に10個復元抽出で選び取る」という命令をしていることになり,これをs10と名づけて保存しています。
s10の平均を計算しています。
[1] 3.3同じように,1,000回サイコロを振ることを以下のように再現してみます。
s1000 <- sample(1:6, 1000, replace = TRUE)
mean(s1000)[1] 3.508(無作為抽出しているので,結果は個々人で違うと思いますが)おそらく10回の時よりも1,000回の時の方が期待値である3.5に近いはずです。
これをさらに以下のように検討してみます。
#サイコロを10回振るのを1000回繰り返す
S <- 1000
rec10 <- numeric(S)
for(i in 1:S){
rec10[i] <- sample(1:6, 10, replace = TRUE)|>
mean()
}
summary(rec10)numericというコマンドで空(0)の行をSの数だけ作って,rec10と名付けています。
rec10のi行目に入れる,という作業をS回(1000行分)繰り返しています。
rec10の最小値,最大値,平均,中央値等を出しています。
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.800 3.200 3.500 3.523 3.900 5.200 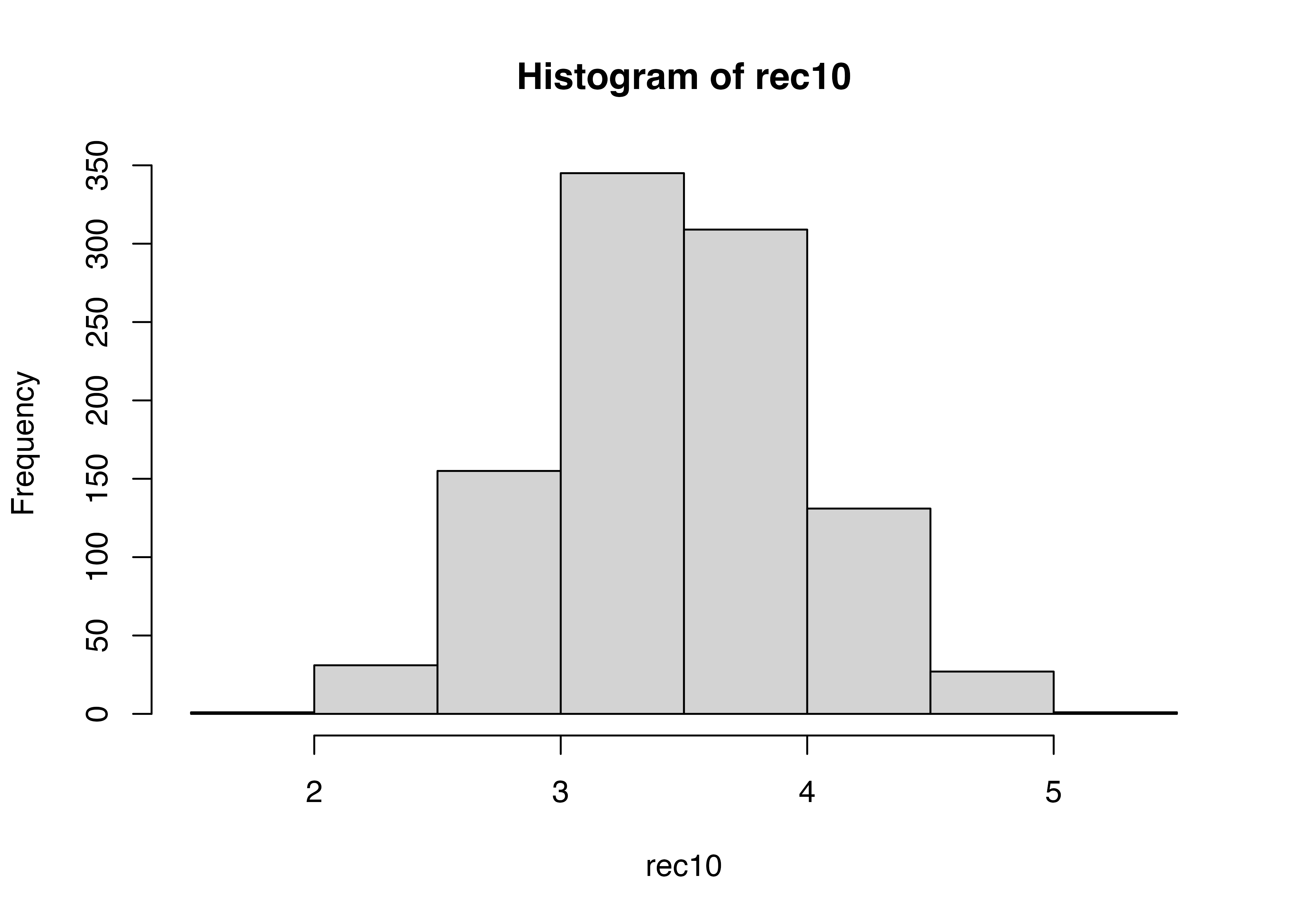
これをサイコロを10000回振るのを1000回繰り返すのに変えてみます。
#サイコロを10000回振るのを1000回繰り返す
rec10000 <- numeric(S)
for(i in 1:S){
rec10000[i] <- sample(1:6, 10000, replace = TRUE)|>
mean()
}
summary(rec10000) Min. 1st Qu. Median Mean 3rd Qu. Max.
3.436 3.490 3.500 3.500 3.511 3.559 hist(rec10000)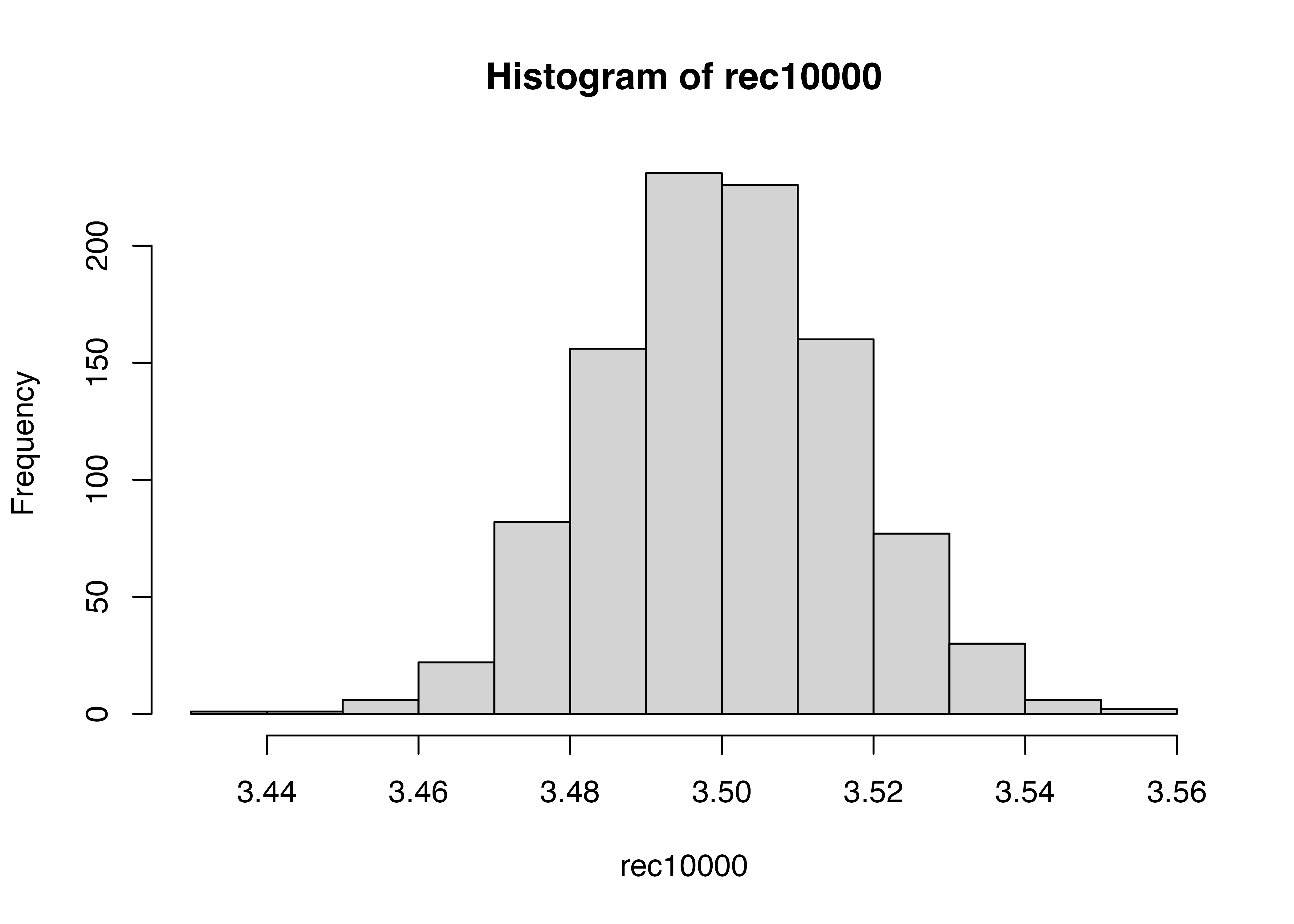
3.5にかなり収束しました。
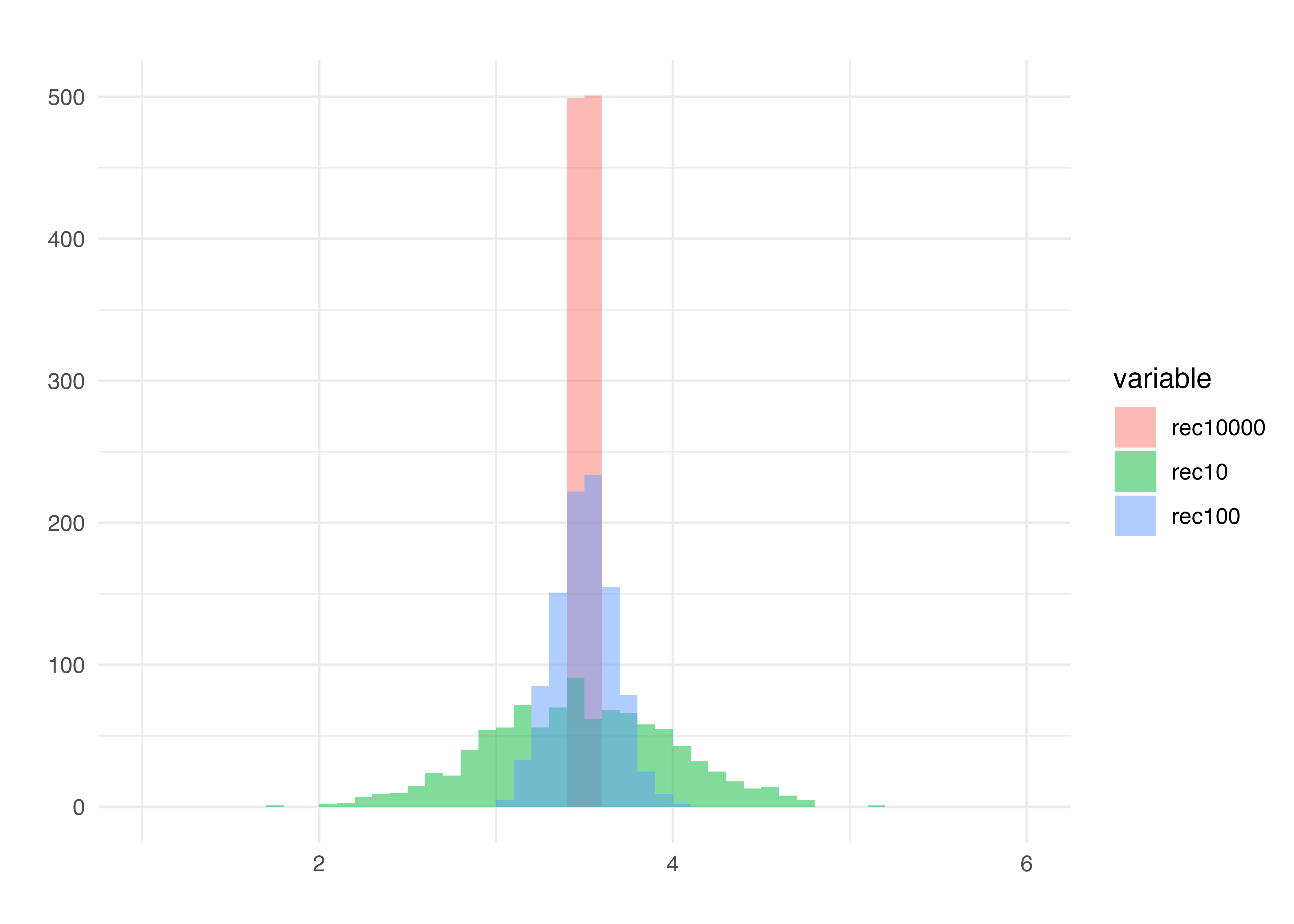
サンプルサイズ100のものも加えてヒストグラムを書きました。一回一回のサンプルサイズが大きいほど,母平均に近い値を取っていることが見えます。
母集団が正規分布であれば
\(X_1, X_2,X3,\cdot\cdot ,X_n\)は正規分布\(N(\mu,\sigma^2)\)からの無作為標本であるとする。このとき標本平均\(\bar X =(X_1+ X_2+X_3+\cdot\cdot +X_n)/n\)の分布は正規分布\(N(\mu,\sigma^2/n)\)
つまり,母集団が正規分布の時は,標本平均も正規分布に従うということが知られています。
20代男性の身長の母集団が正規分布\(N(\mu,5^2)\) として,無作為に選ばれた100人の身長の測定値が\(X_1, X_2,X_3,\cdot\cdot ,X_{100}\)とする。標本平均\(\bar X\)で母集団の平均\(\mu\)を推定したい時の測定誤差\(|\bar X - \mu|\)は,上の定理から正規分布\(N(\bar X,0.5^2)\) に従う。これがわかると,2σ区間が \(\mu - 1 \le \bar X \le \mu + 1\)。正規分布で2σ区間に入る確率は95.4%だったので,95.4%の確率で測定誤差が1cm以下となることがわかります。
重要なことはこの「標本平均が正規分布になる」という性質は母集団が正規分布じゃなくてもデータが十分に大きい時には成り立つ,ということです。これを中心極限定理と言います。
\(X_1, X_2,X3,\cdot\cdot ,X_n\)は母平均が\(\mu\)母分散が\(\sigma^2\)からの大きさ\(n\)の無作為標本とする。
\(n\)が大きくなるに従って,標本平均\(\bar X=(X_1+ X_2+X_3+\cdot\cdot +X_n)/n\) の分布は,\(N(\mu,\sigma^2/n)\)に近づく(収束する)
中心極限定理を使うと,母集団が正規分布でなくとも,データが大きくなる時は標本平均が正規分布に従うとして計算できる
サイコロには1から6までの目があり,それぞれが出る確率は1/6です。したがって,母集団の平均は,
\[ \frac{1}{6}\Sigma^6_{i=1}i=\frac{21}{6}=3.5 \]
これも,標本が大きくなると,平均が正規分布になる?
サイコロを1回振った時,平均=出た目。これを1000回繰り返す
S <- 1000
rec1 <- numeric(S)
for(i in 1:S){
rec1[i] <- sample(1:6, 1, replace = TRUE)|>
mean()
}
sim1 <- tibble(avg = rec1)
ggplot(sim1, aes(x = avg)) +
geom_histogram(binwidth = 1,
color = "black") 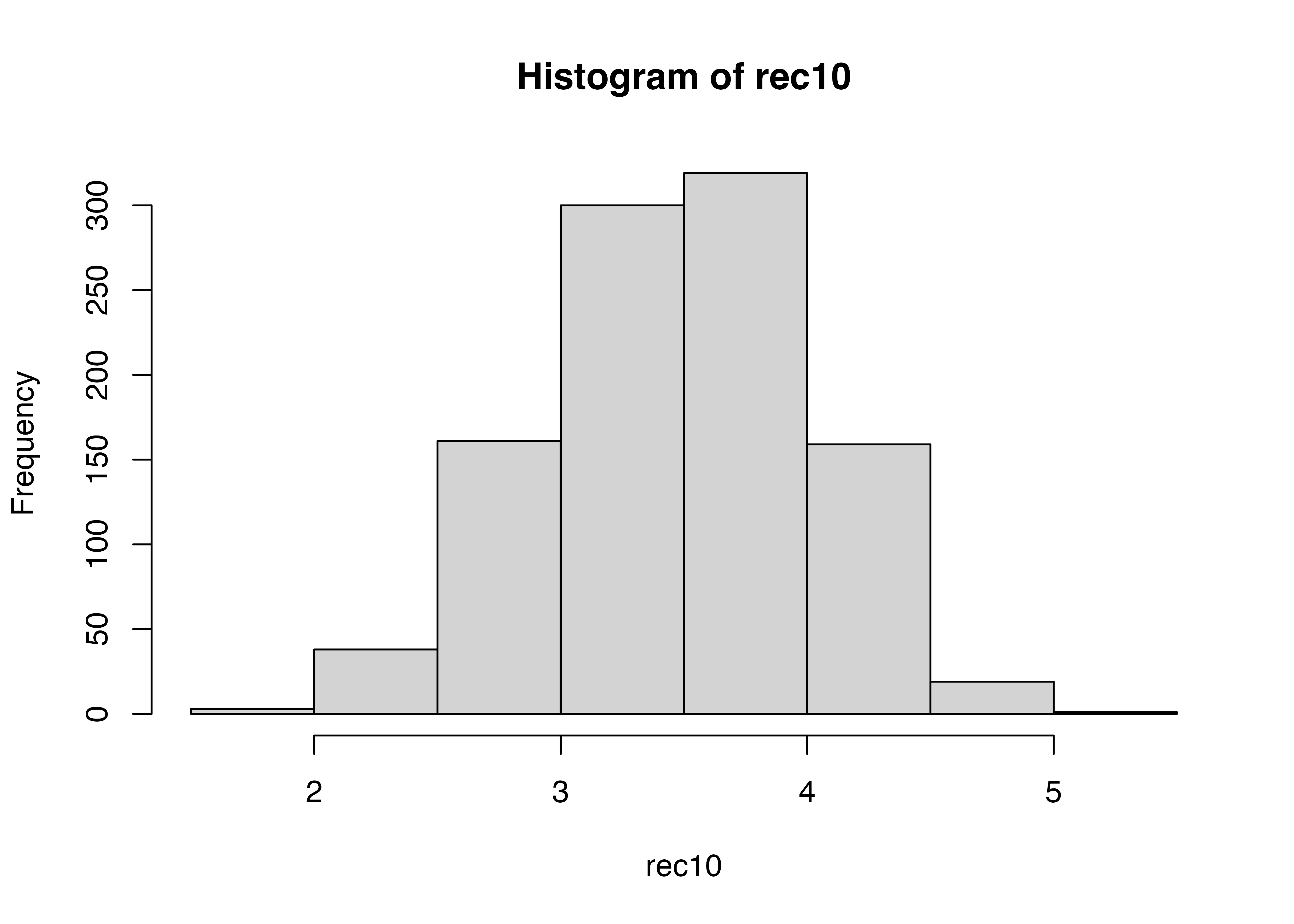
同様にサイコロを2回振って平均を取る
S <- 1000
rec2 <- numeric(S)
for(i in 1:S){
rec2[i] <- sample(1:6, 2, replace = TRUE)|>
mean()
}
sim2 <- tibble(avg = rec2)
ggplot(sim2, aes(x = avg)) +
geom_histogram(binwidth = 0.5,
color = "black") 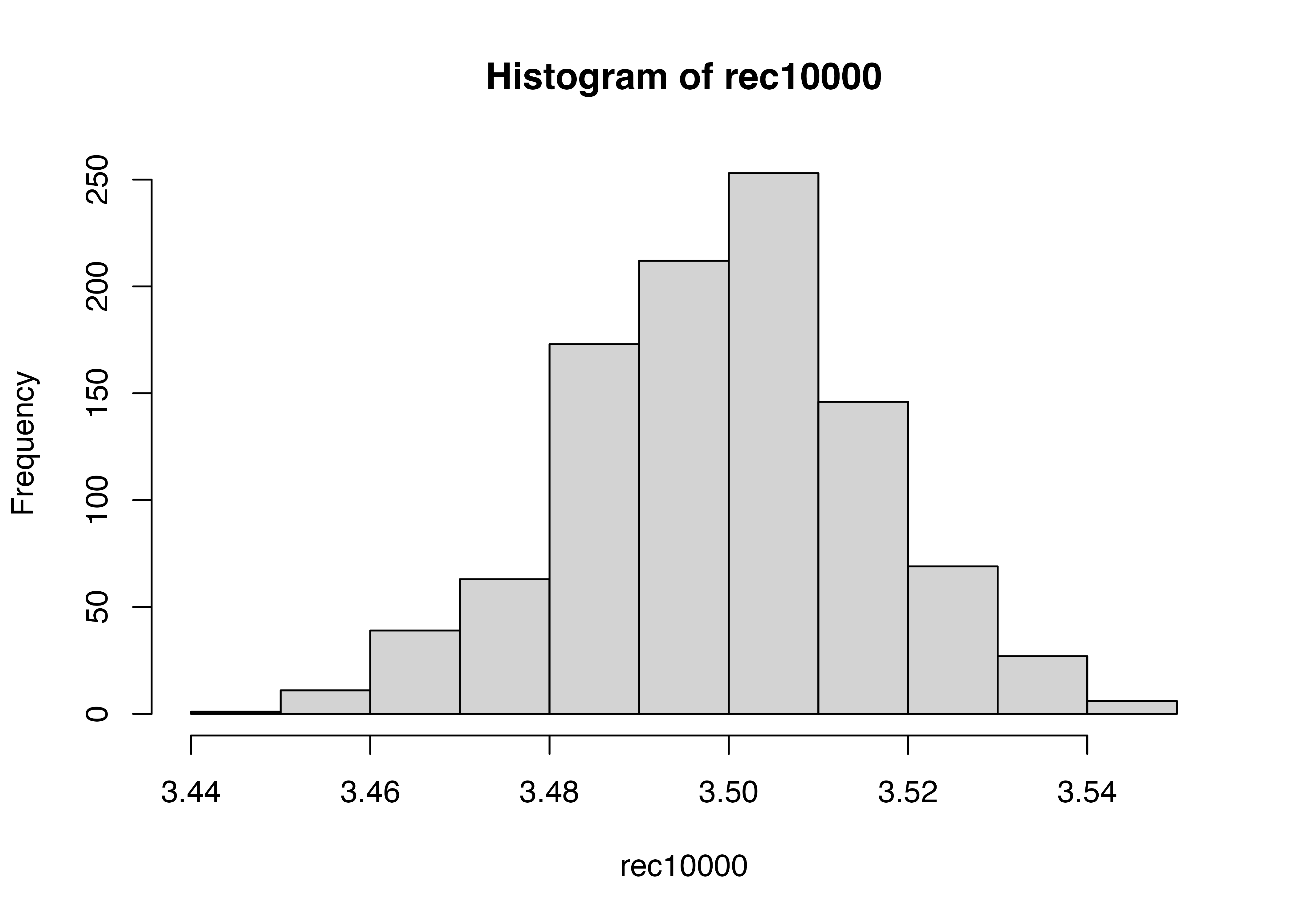
10回
S <- 1000
rec10 <- numeric(S)
for(i in 1:S){
rec10[i] <- sample(1:6, 10, replace = TRUE)|>
mean()
}
sim10 <- tibble(avg = rec10)
ggplot(sim10, aes(x = avg)) +
geom_histogram(binwidth = 0.5,
color = "black") 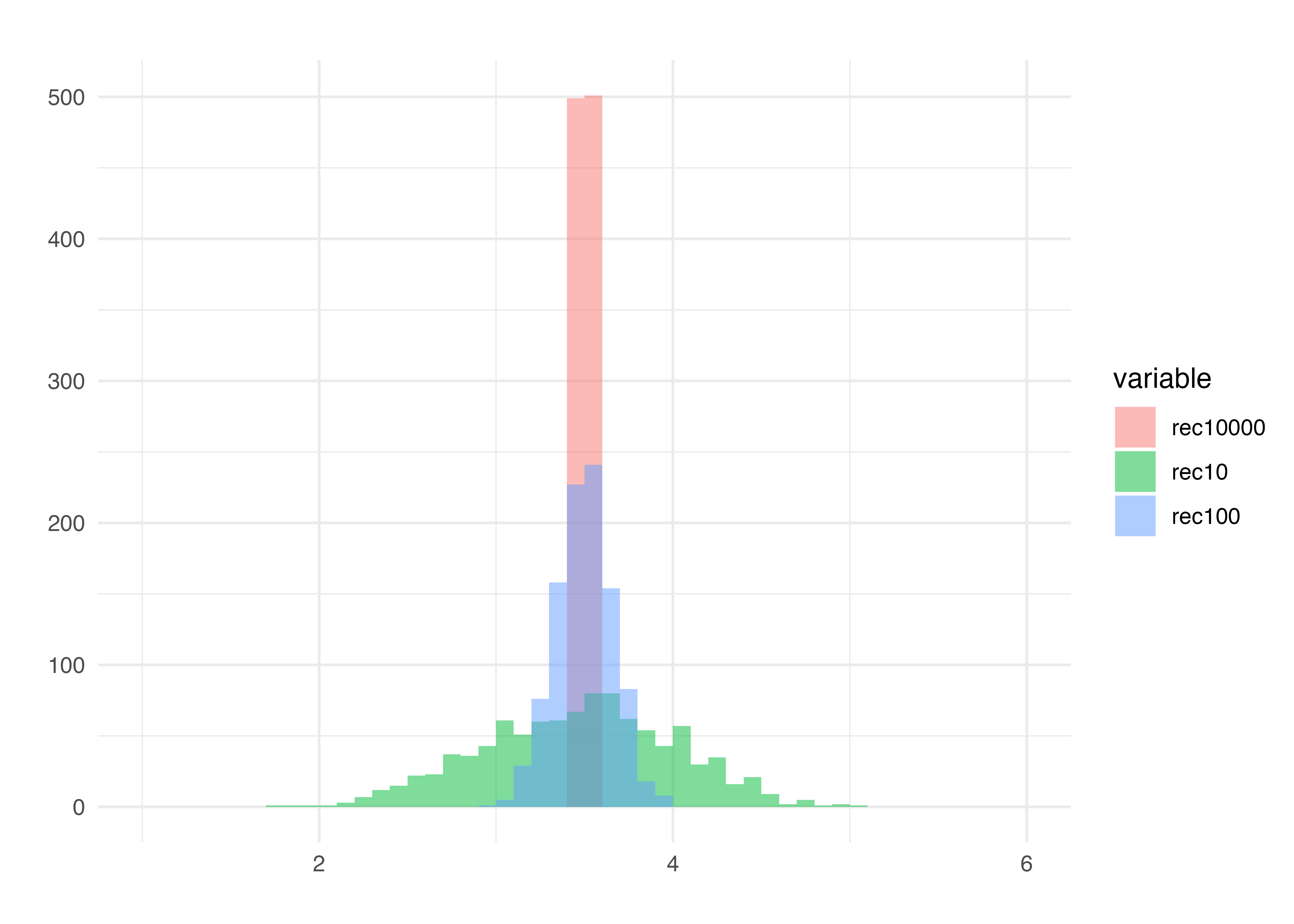
100回
S <- 1000
rec100 <- numeric(S)
for(i in 1:S){
rec100[i] <- sample(1:6, 100, replace = TRUE)|>
mean()
}
sim100 <- tibble(avg = rec100)
ggplot(sim100, aes(x = avg)) +
geom_histogram(binwidth = 0.1,
color = "black") 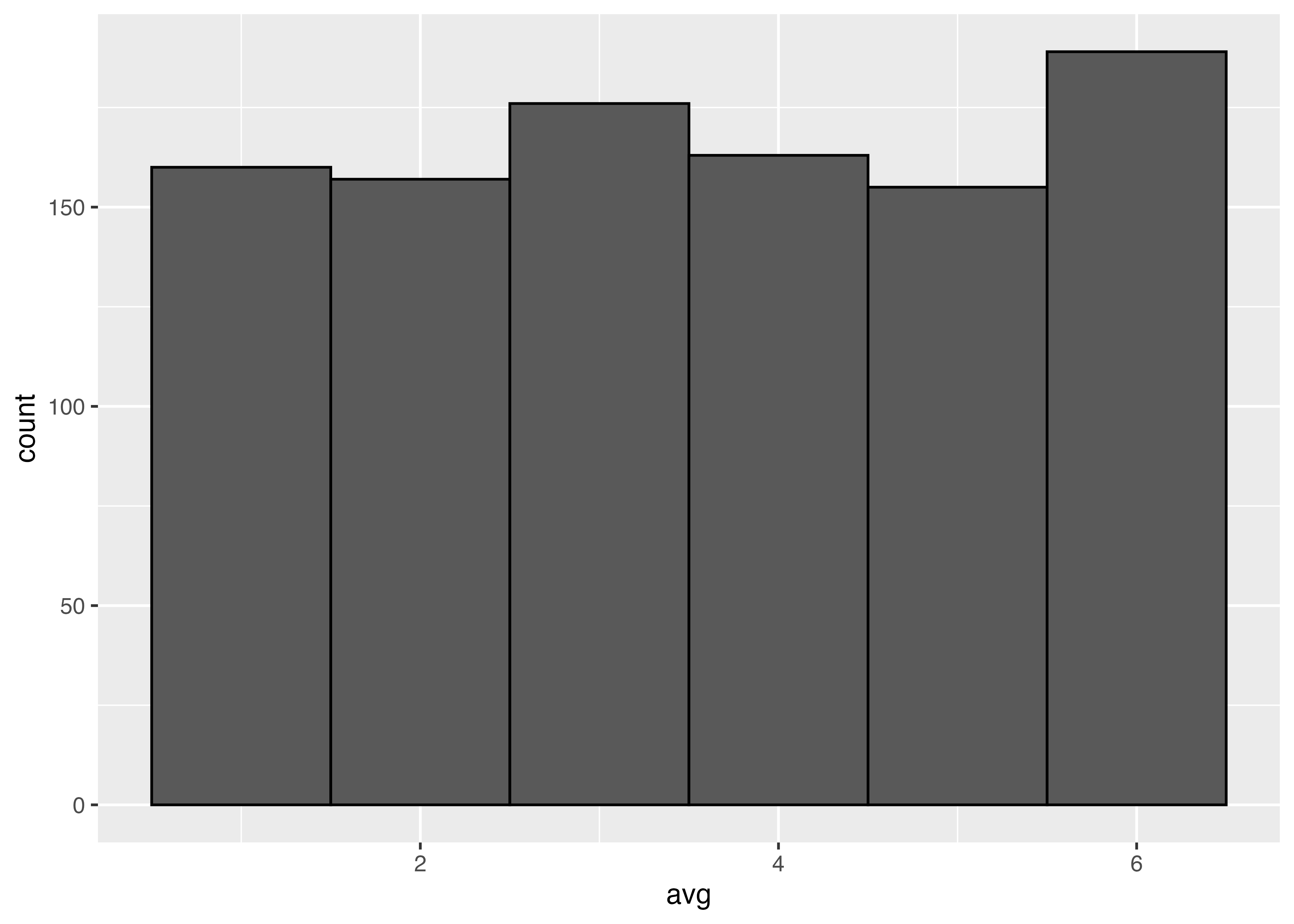
(高校までの確率では「歪みのないコイン」が使われますが)あるコインは,表が出る確率が35%になるような歪み方をしています。
コインを1回投げる,という作業を1000回繰り返してみます。
# パラメータを指定
phi <- 0.35
# データ数を指定
N <- 1
S <- 1000
rec1 <- numeric(S)
for(i in 1:S){
rec1[i] <- rbinom(n = N, size = 1, prob = phi)|>
mean()
}
sim1 <- tibble(avg = rec1)
ggplot(sim1, aes(x = avg)) +
geom_histogram(binwidth = 1,
color = "black") 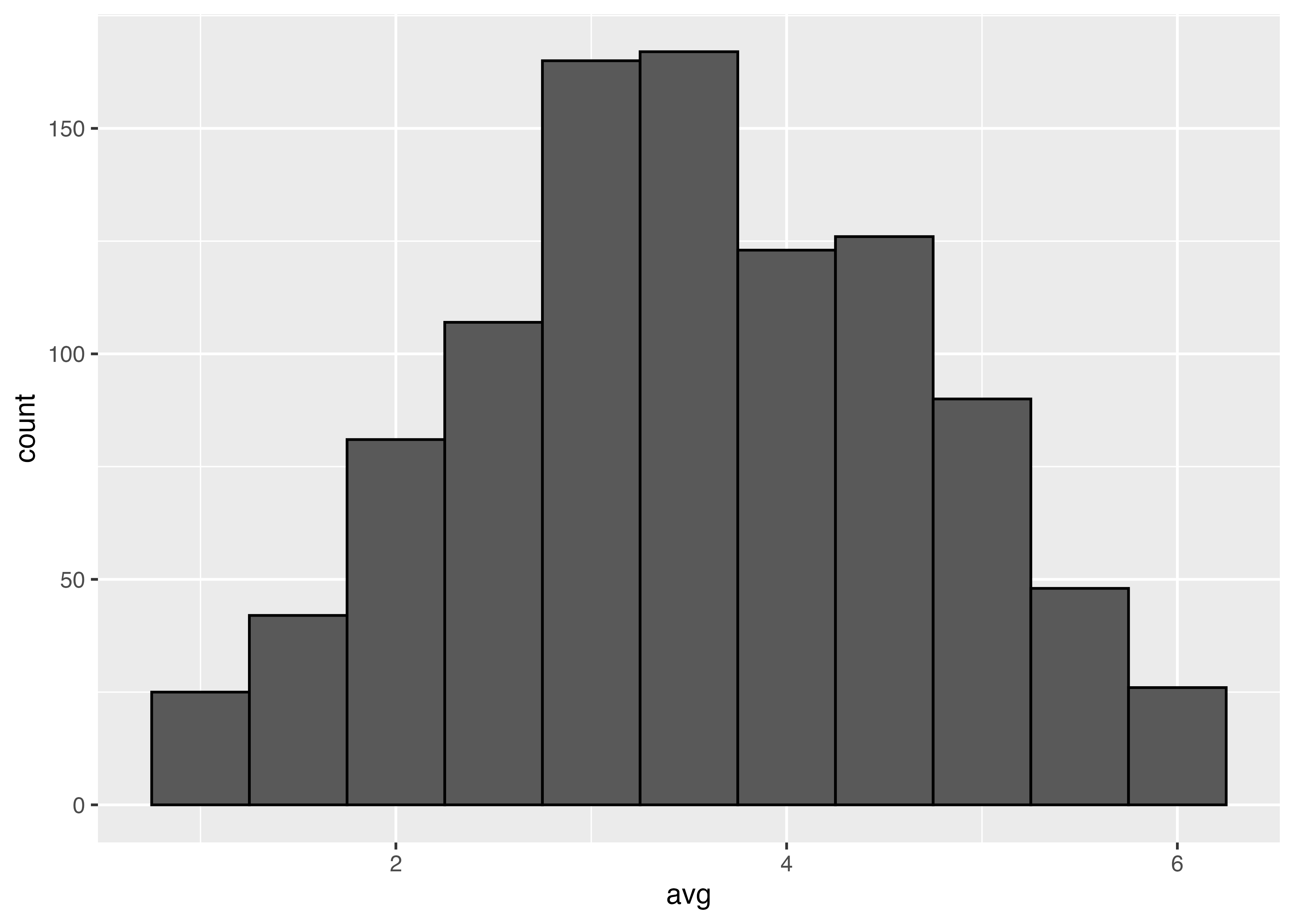
コインを2回投げて平均をとります。プログラムのsizeの部分を2に変えています。
rec2 <- numeric(S)
for(i in 1:S){
rec2[i] <- rbinom(n = N, size = 2, prob = phi)|>
mean()
}
sim2 <- tibble(avg = rec2)
ggplot(sim2, aes(x = avg)) +
geom_histogram(binwidth = 1,
color = "black") 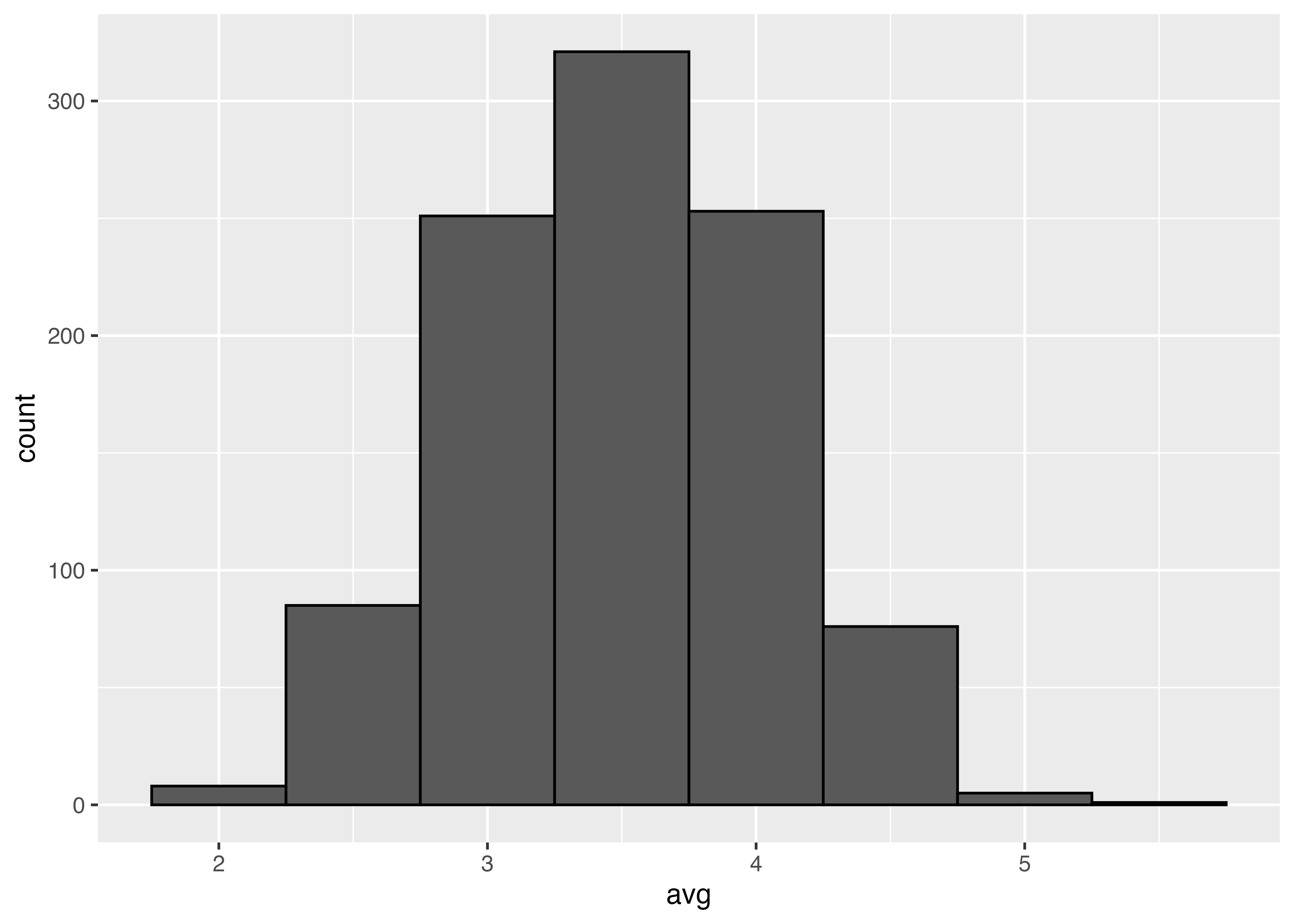
同様に10回投げた平均
rec10 <- numeric(S)
for(i in 1:S){
rec10[i] <- rbinom(n = N, size = 10, prob = phi)|>
mean()
}
sim10 <- tibble(avg = rec10)
ggplot(sim10, aes(x = avg)) +
geom_histogram(binwidth = 1,
color = "black") 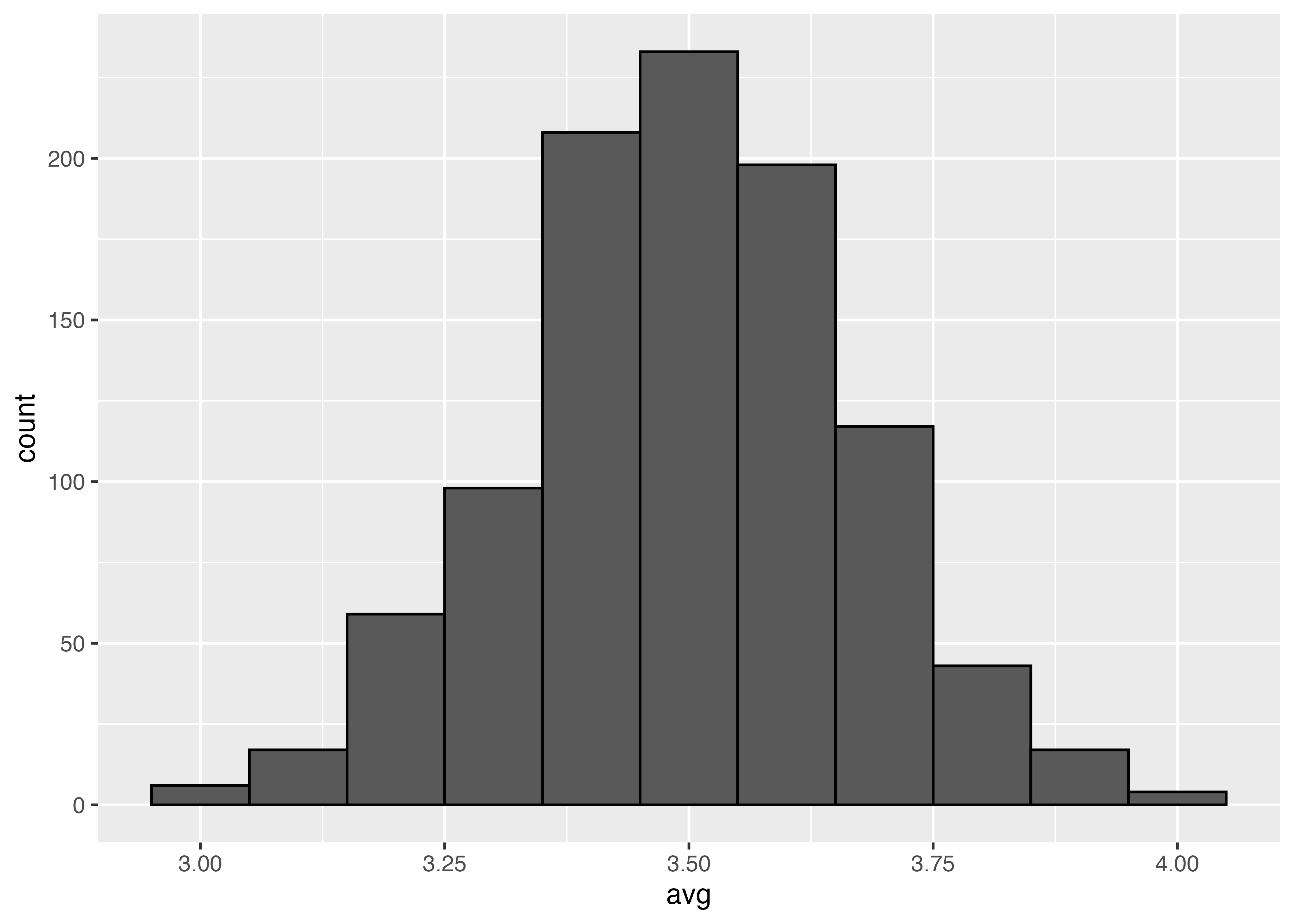
100回
rec100 <- numeric(S)
for(i in 1:S){
rec100[i] <- rbinom(n = N, size = 100, prob = phi)|>
mean()
}
sim100 <- tibble(avg = rec100)
ggplot(sim100, aes(x = avg)) +
geom_histogram(binwidth = 1,
color = "black") 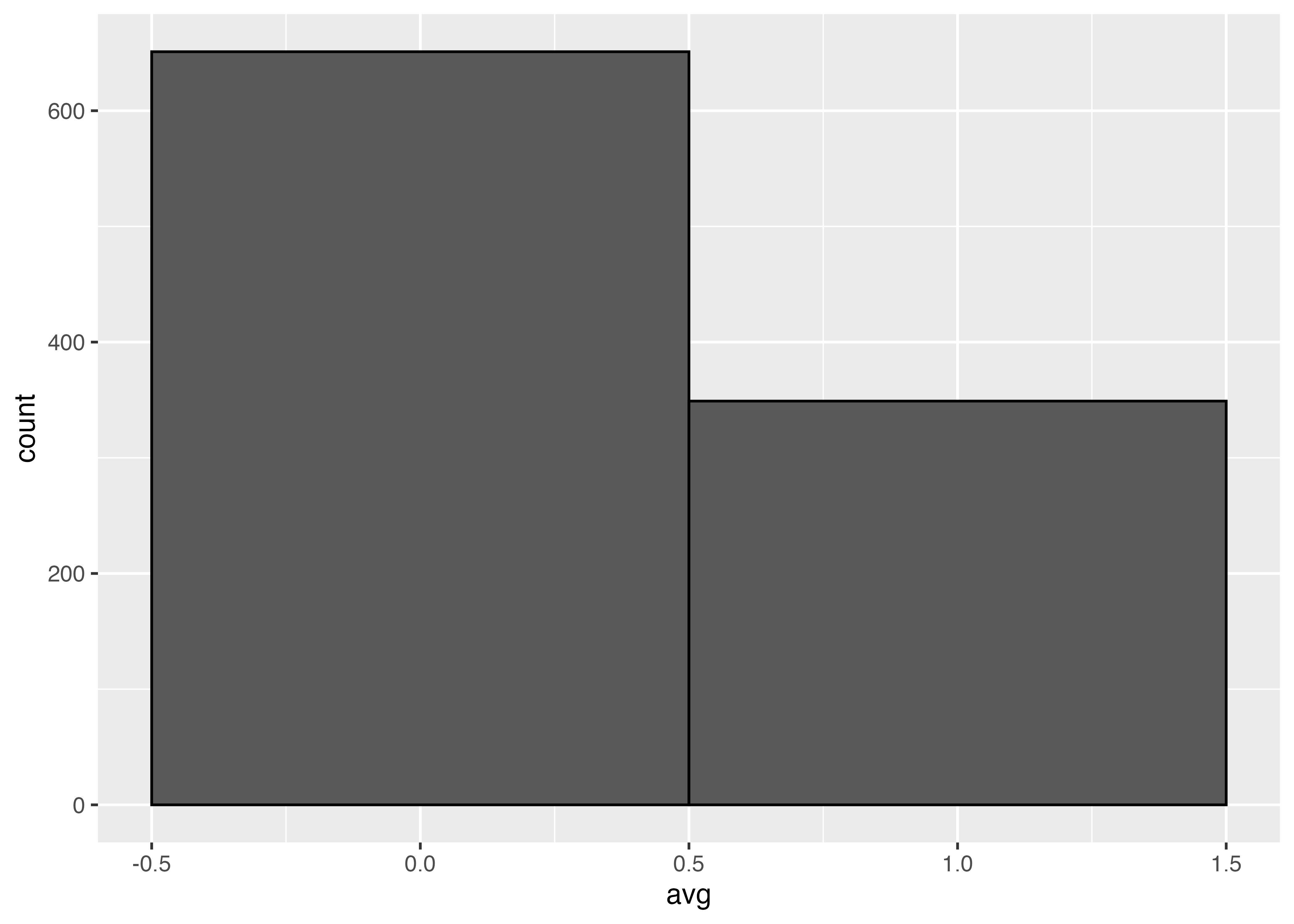
10000回
rec1000 <- numeric(S)
for(i in 1:S){
rec1000[i] <- rbinom(n = N, size = 10000, prob = phi)|>
mean()
}
sim1000 <- tibble(avg = rec1000)
ggplot(sim1000, aes(x = avg)) +
geom_histogram(binwidth = 10,
color = "black") 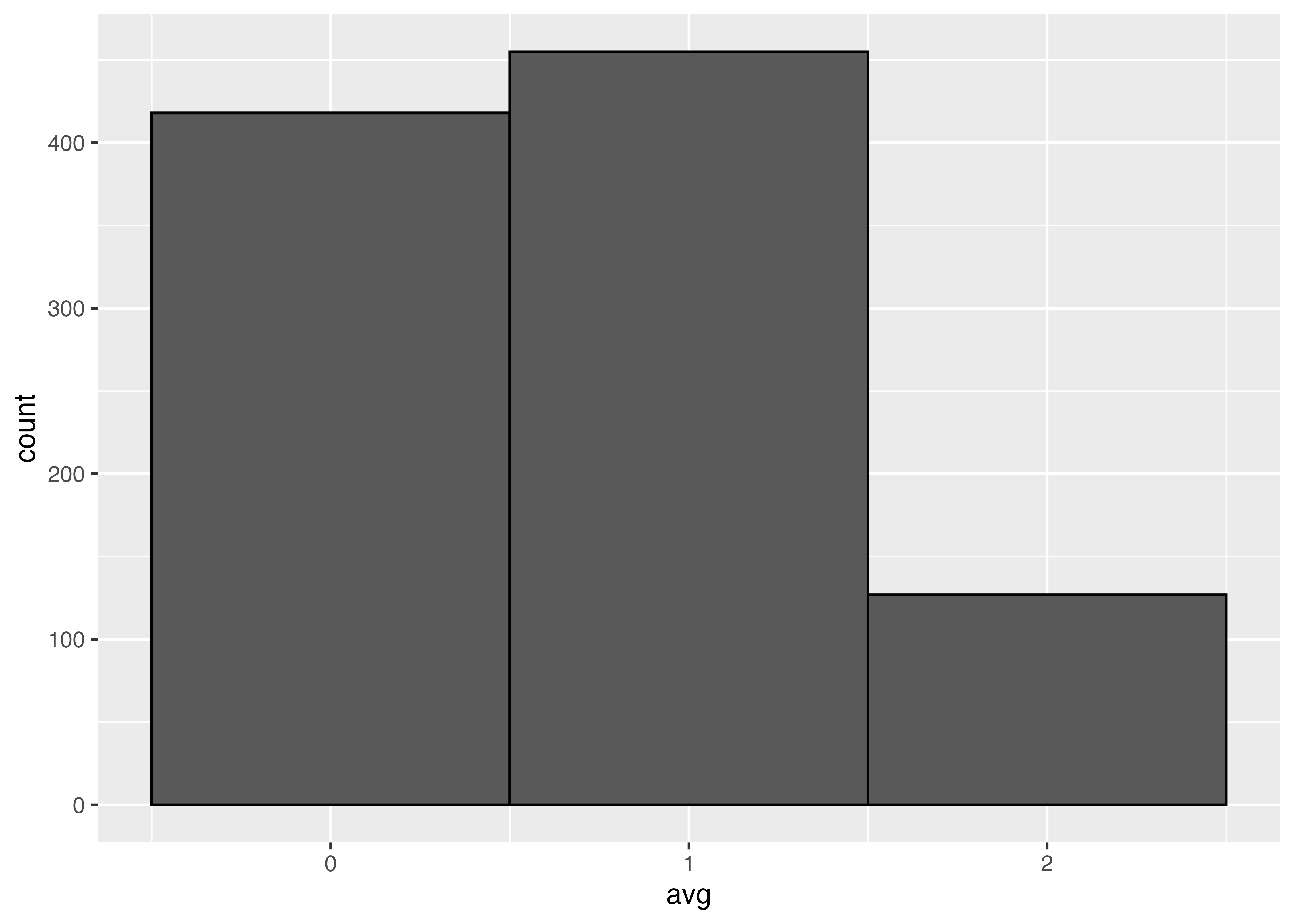
ここまでをまとめると
無作為抽出という手順と,確率の性質を組み合わせて利用することで,未知の母集団を推測できる!

母集団から無作為に抽出された標本の平均値は,標本の大きさが大きいほど,母集団平均に近い値を取る法則。
標本分散や標準偏差についても大数の法則が成立します
S <- 1000
srec10 <- numeric(S)
for(i in 1:S){
srec10[i] <- sd(rnorm(10,50,10))}
srec100 <- numeric(S)
for(i in 1:S){
srec100[i] <- sd(rnorm(100,50,10))}
srec10000 <- numeric(S)
for(i in 1:S){
srec10000[i] <- sd(rnorm(10000,50,10))}
hist(srec10000,
col="#FF00007F",
xlim=c(1,18),ann=F, main="", xlab=""
,breaks=seq(1,20,1))
par(new=T)
hist(srec10,
breaks=seq(1,20,1),
col="#0000FF7F",ann=F, add=T)
hist(srec100,
breaks=seq(1,20,1),
col="#32CD32",ann=F, add=T)
legend("topright",
legend=c("rec10000", "rec10", "rec100"),
fill=c("#FF00007F", "#0000FF7F","#32CD32"))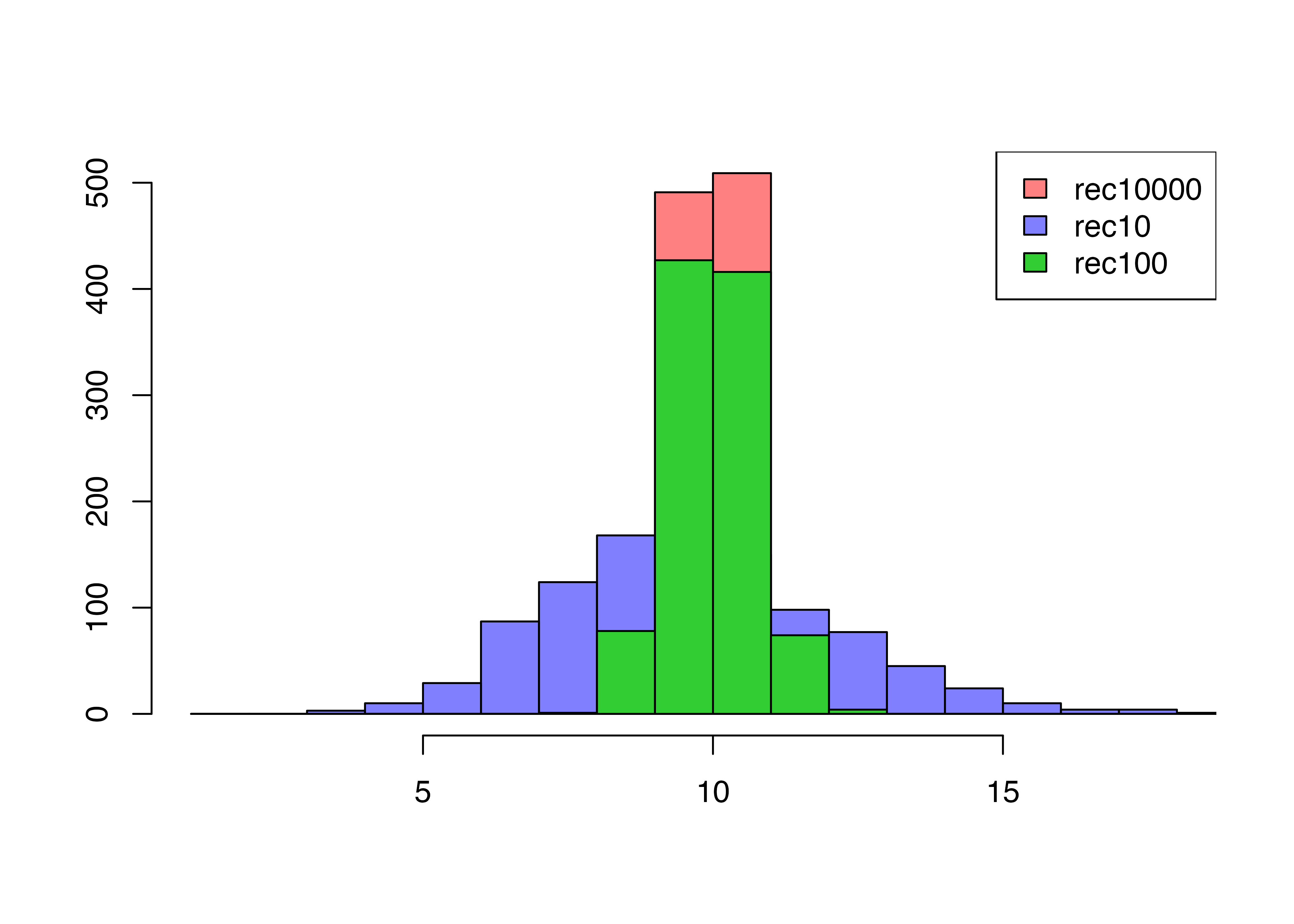
あるサンプルデータを用いて推定を行う時,その推定の良さを考える上で重要な性質が2つあります。
母数\(\theta\)の推定量を\(\hat \theta_n\)とする。任意の\(\epsilon>0\)に対して
\[ \lim_{n\to \infty}Pr\{|\hat{\theta}_n-\theta|>\epsilon\}=0 \]が成立するとき,推定量\(\hat \theta_n\)を一致推定量(consisent estimator)という。これは
とも言い換えられる。↩︎