Code
- 1
-
複数のパッケージを一度に読み込める
pacmanパッケージが入っていない場合は,インストールする - 2
- パッケージの読み込み
2024/05/27
データ解析の目的は,母集団がどんな形になっているのか,標本を発生させた母集団はそもそもどんな形をしているのかを知ることにあります。
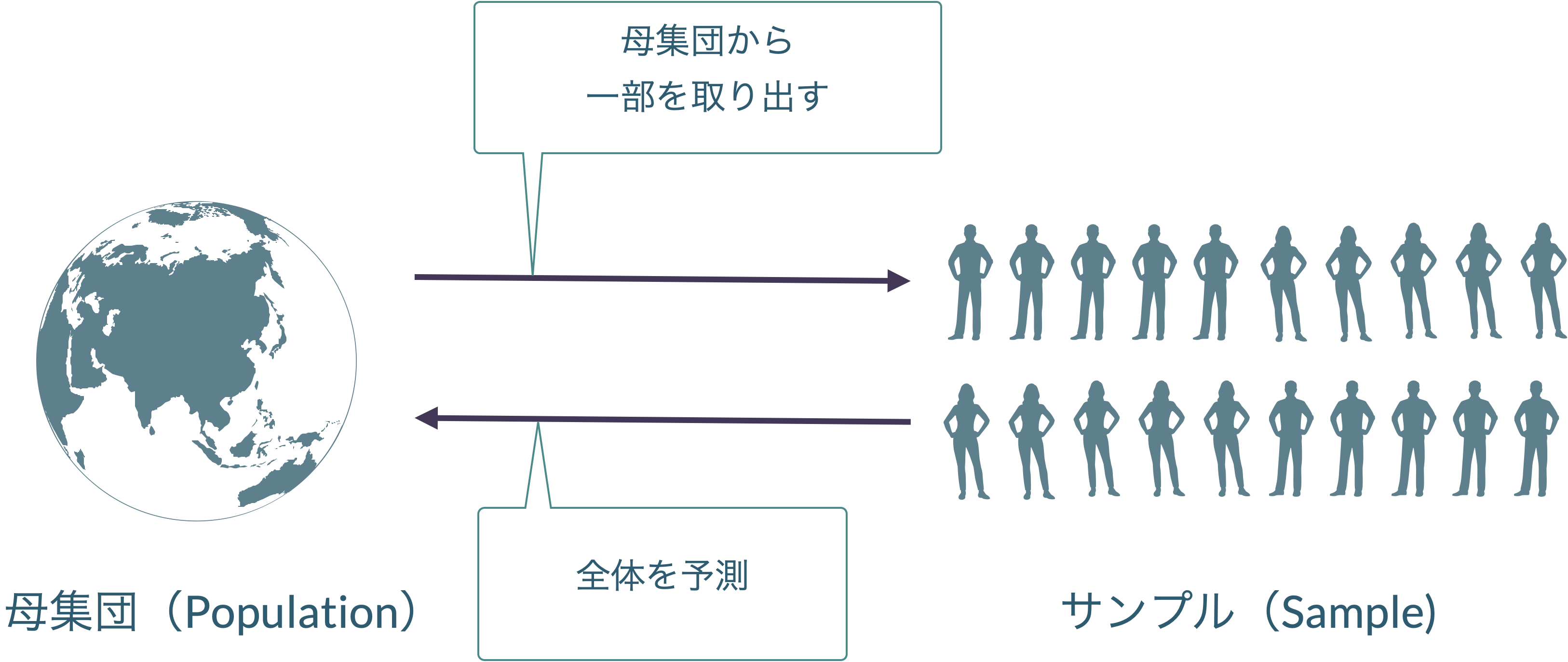
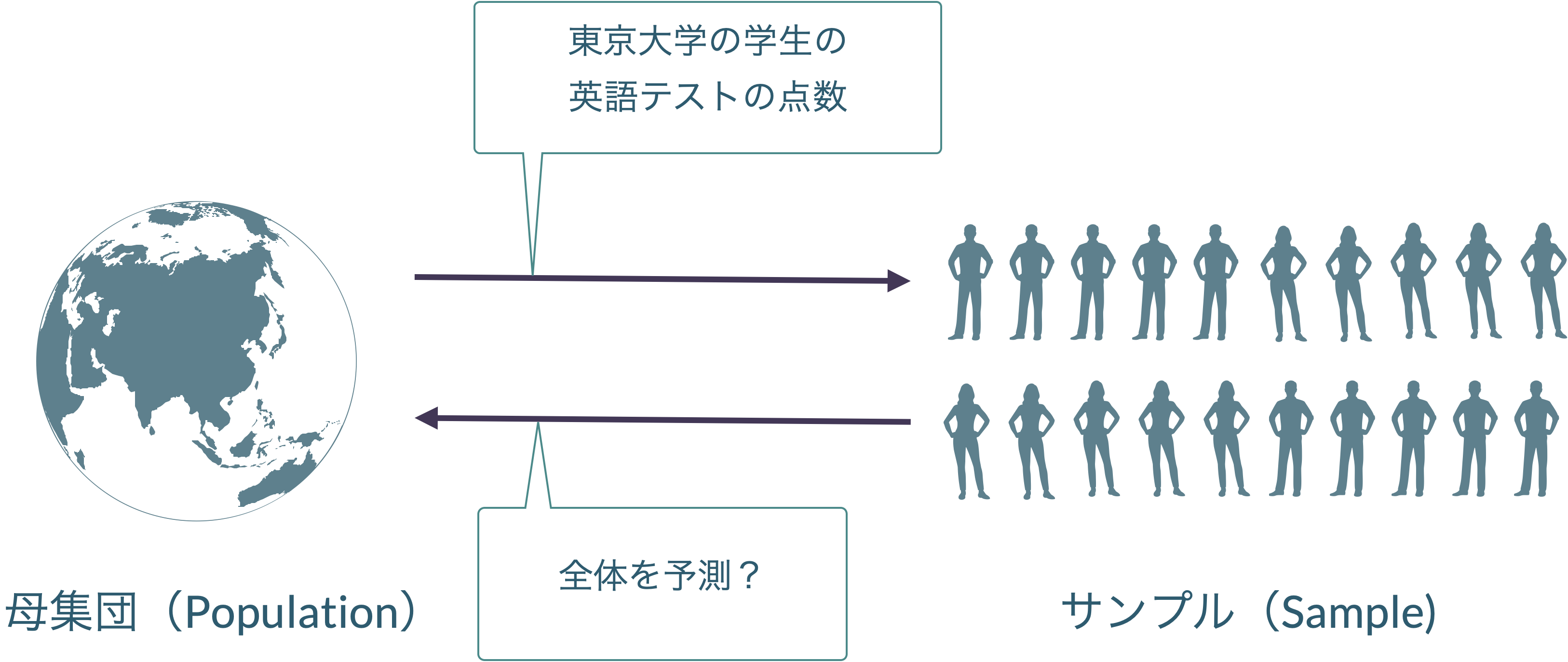
適切にデータを選ぶ,という際に重要なのが,標本が,母集団から偏りなく抽出されているということです。
データ解析の目的は,無作為標本(母集団からすると限られた情報)を使って,母集団全体の傾向を推測することにあります。
その際,母集団をモデル(様々な仮定を置いた数式)で表します。
例
\[ P(X=k) = {}_n C_k p^k(1-p)^{n-k} \]

標本の数値と確率モデルを利用して,母集団の分布の形を把握したい

確率モデル(確率分布)にはいくつかの便利な性質があり,それを利用することで未知の母集団の分布の形が推測できる
\[ P(X=k) = {}_n C_k p^k(1-p)^{n-k} \]
打率3割5分の人と1割5分の人がそれぞれ10回打席に立ってヒットが何本出るか?
# パラメータを指定
phi <- 0.35
# 試行回数を指定
M <- 10
x_vals <- 0:M
prob_df <- tidyr::tibble(
x = x_vals, # 確率変数
probability = dbinom(x = x_vals, size = M, prob = phi) # 確率
)
ggplot(data = prob_df, mapping = aes(x = x, y = probability)) + # データ
geom_bar(stat = "identity", position = "dodge", fill = "#00A968") + # 棒グラフ
scale_x_continuous(breaks = x_vals, labels = x_vals) + # x軸目盛
labs(title = "Binomial Distribution",
subtitle = paste0("phi=", phi, ", M=", M), # (文字列表記用)
#subtitle = parse(text = paste0("list(phi==", phi, ", M==", M, ")")), # (数式表記用)
x = "x", y = "probability") # ラベル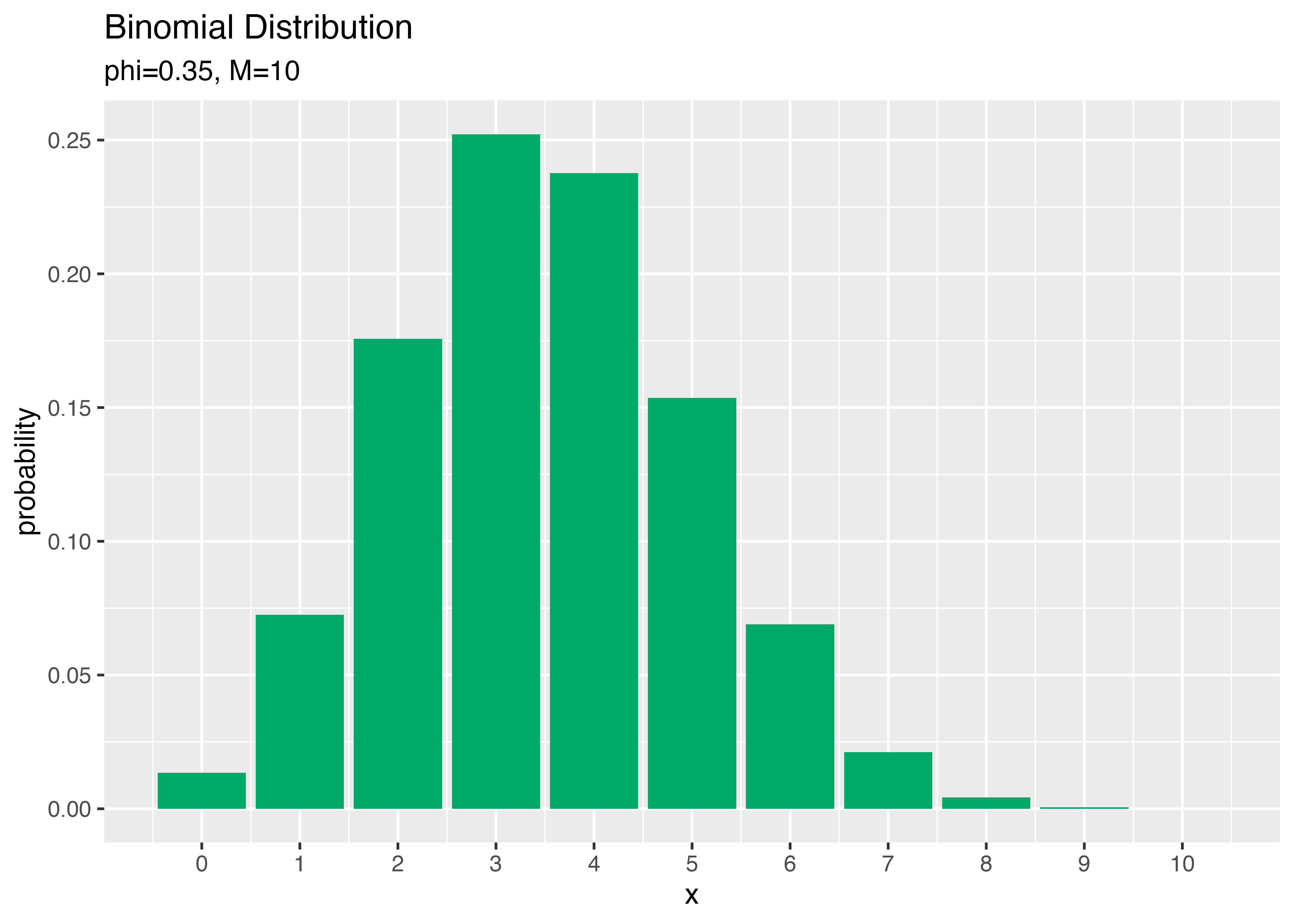
# パラメータを指定
phi <- 0.15
# 試行回数を指定
M <- 10
x_vals <- 0:M
prob_df <- tibble(
x = x_vals, # 確率変数
probability = dbinom(x = x_vals,
size = M,
prob = phi) # 確率
)
ggplot(data = prob_df,
mapping = aes(x = x,
y = probability)) + # データ
geom_bar(stat = "identity",
position = "dodge",
fill = "#00A968") + # 棒グラフ
scale_x_continuous(breaks = x_vals,
labels = x_vals) + # x軸目盛
labs(title = "Binomial Distribution",
subtitle = paste0("phi=", phi, ", M=", M), # (文字列表記用)
#subtitle = parse(text = paste0("list(phi==", phi, ", M==", M, ")")), # (数式表記用)
x = "x", y = "probability") # ラベル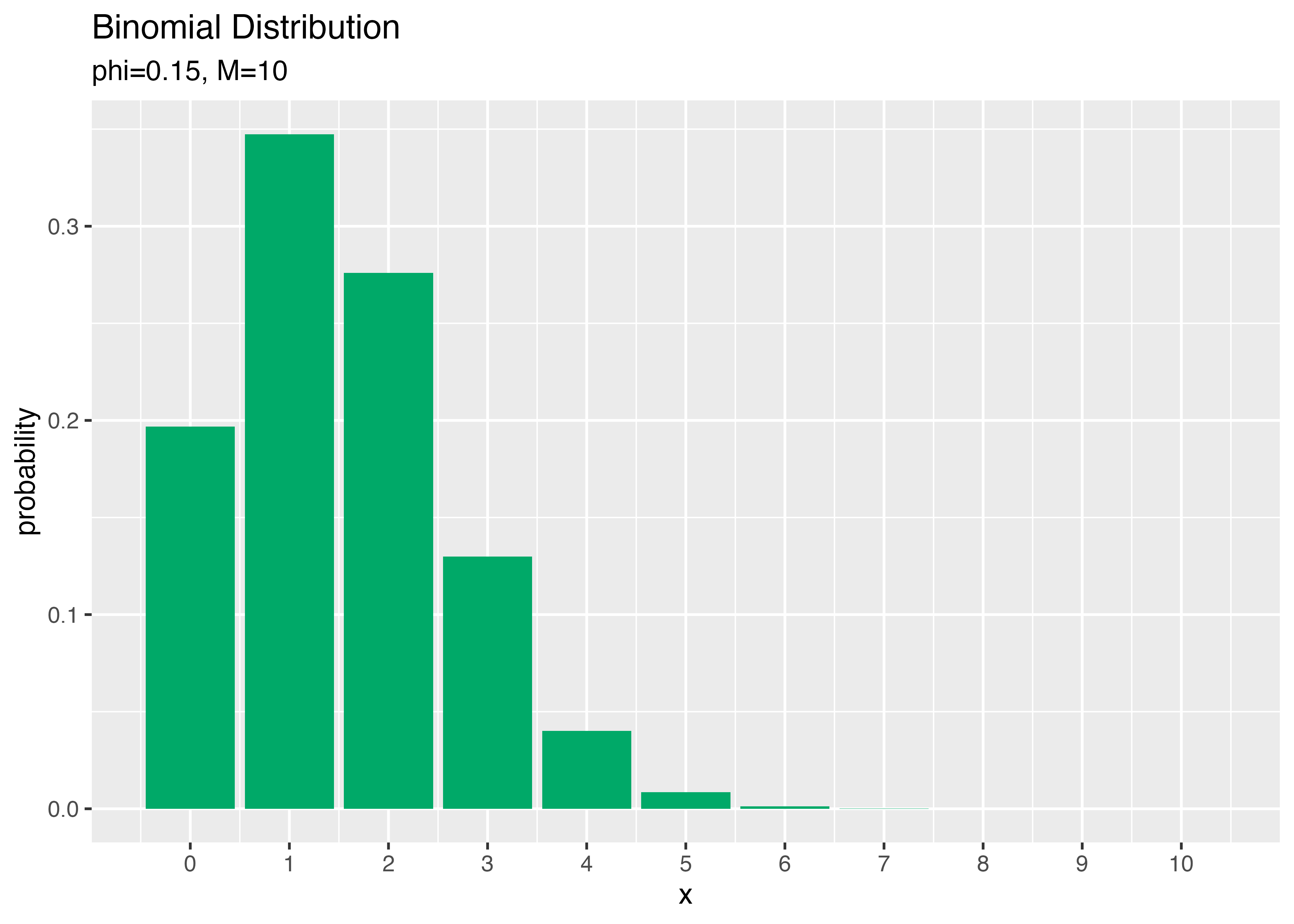
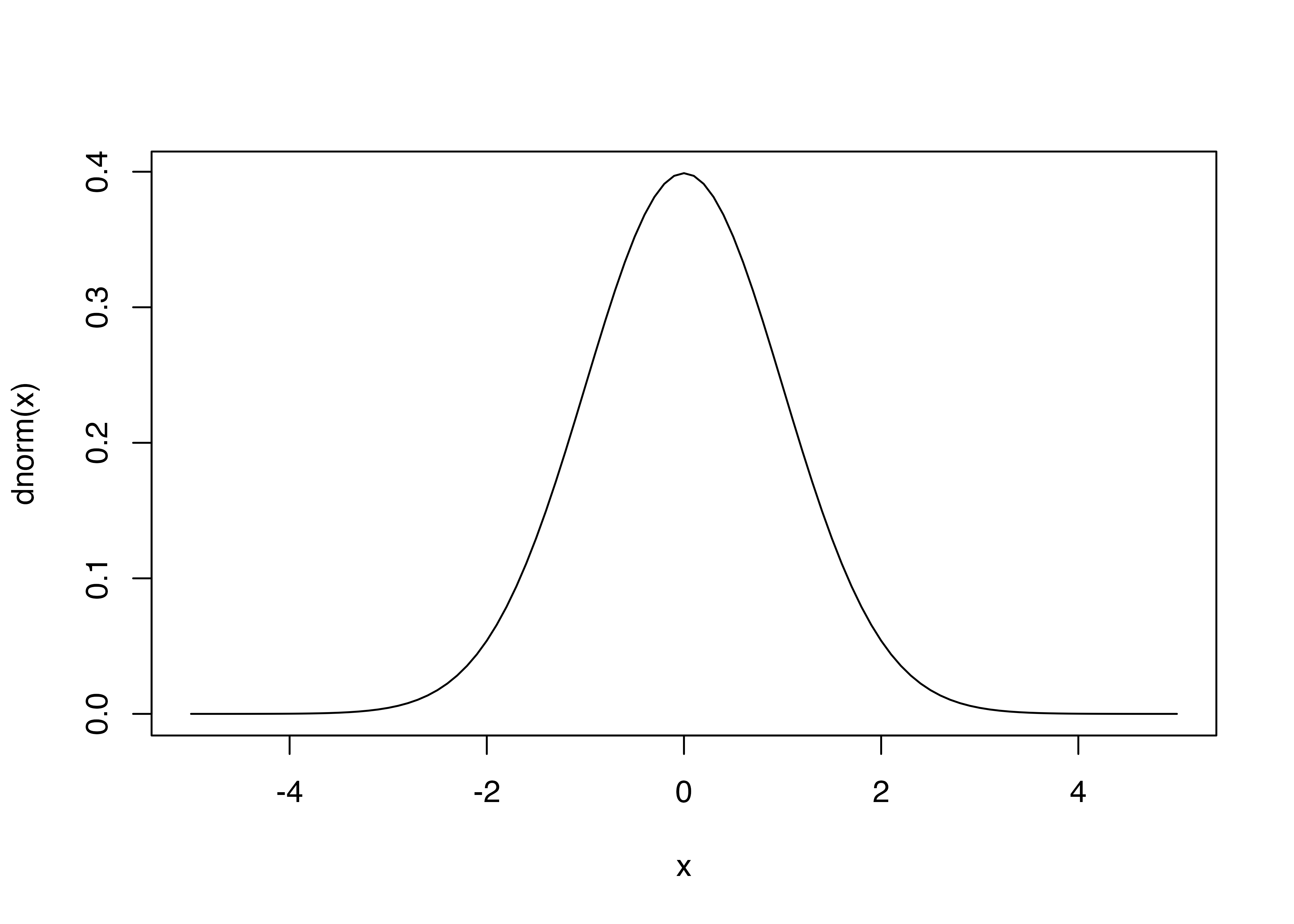
身長などの身体測定値や測定誤差など様々な場面に現れる分布。あとで使う望ましい性質がある。平均 \(\mu\),分散\(\sigma^2\) として,\(\mathcal{N}(\mu,\sigma^2)\) と標記
\[ f(x)= \frac{1}{\sqrt {2 \pi \sigma^2 }} \exp \left(- \frac{(x- \mu)^2}{2\sigma^2} \right) \]
特に平均0、分散1の正規分布を標準正規分布と呼ぶ
サンプリングをうまくやって,確率分布の望ましい性質を使って解決する!

これをさらに以下のように検討してみます。
numericというコマンドで空(0)の行をSの数だけ作って,rec10と名付けています。
rec10のi行目に入れる,という作業をS回(1000行分)繰り返しています。
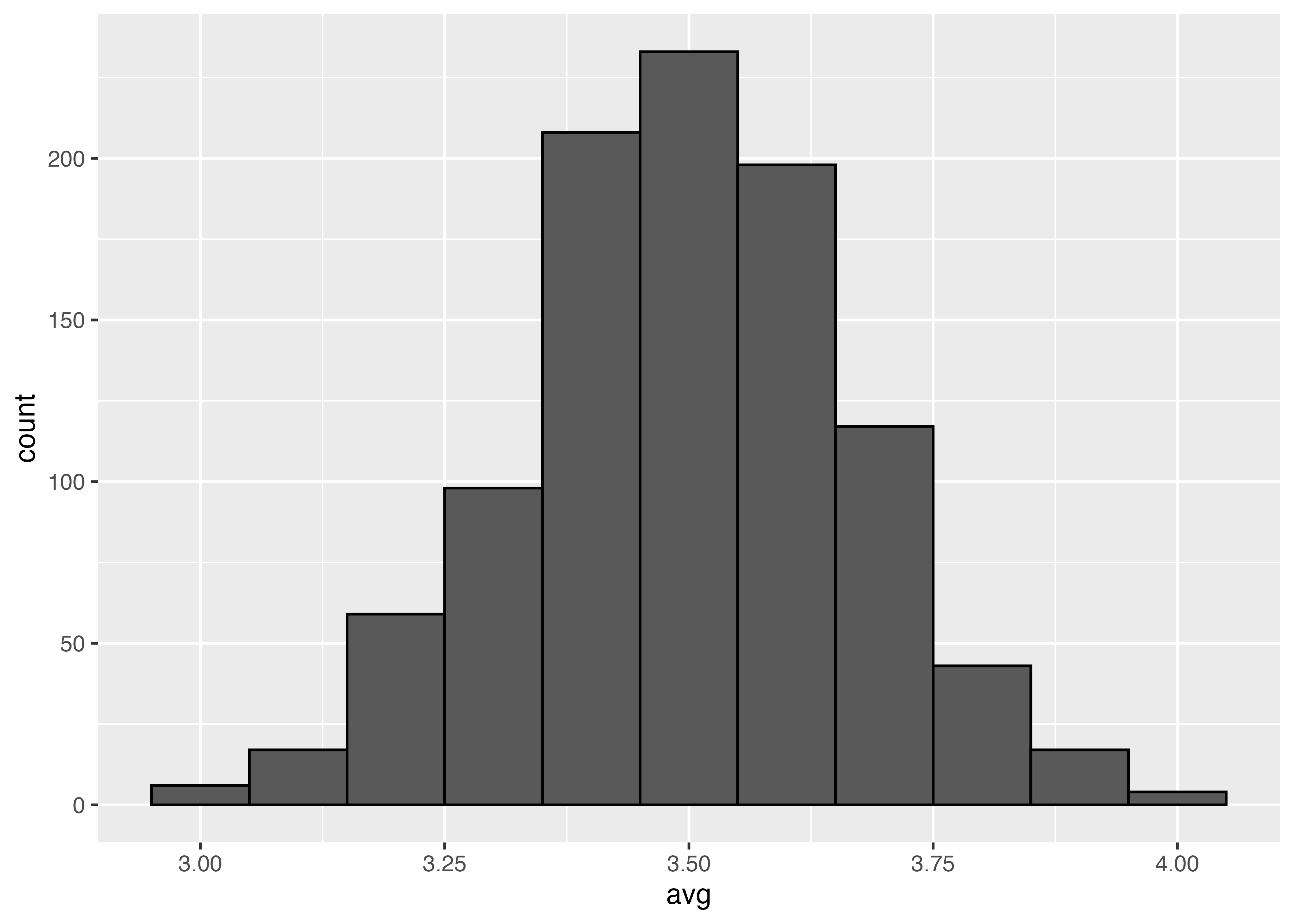
rec10の最小値,最大値,平均,中央値等を出しています。
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.800 3.100 3.500 3.517 3.900 5.100 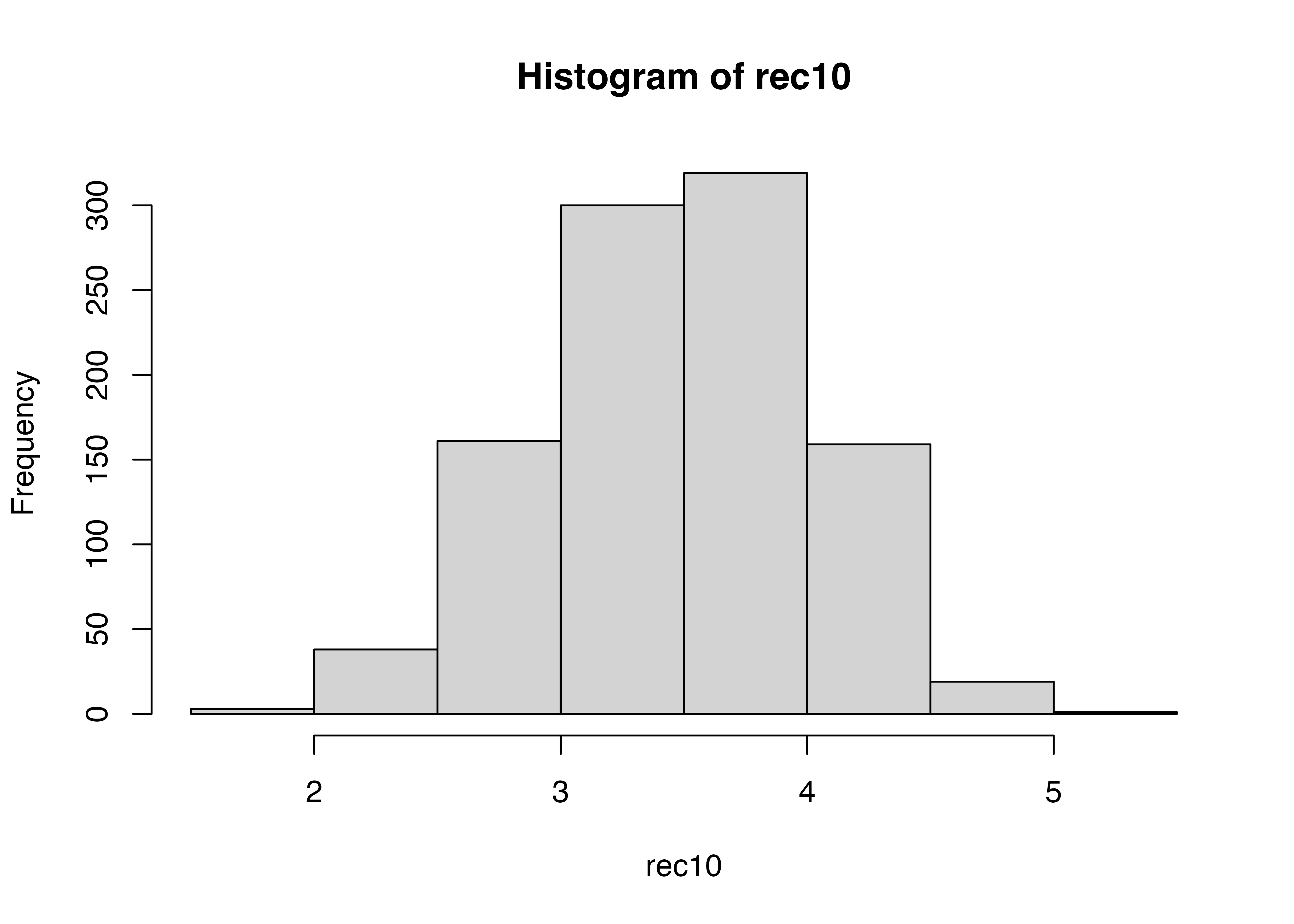
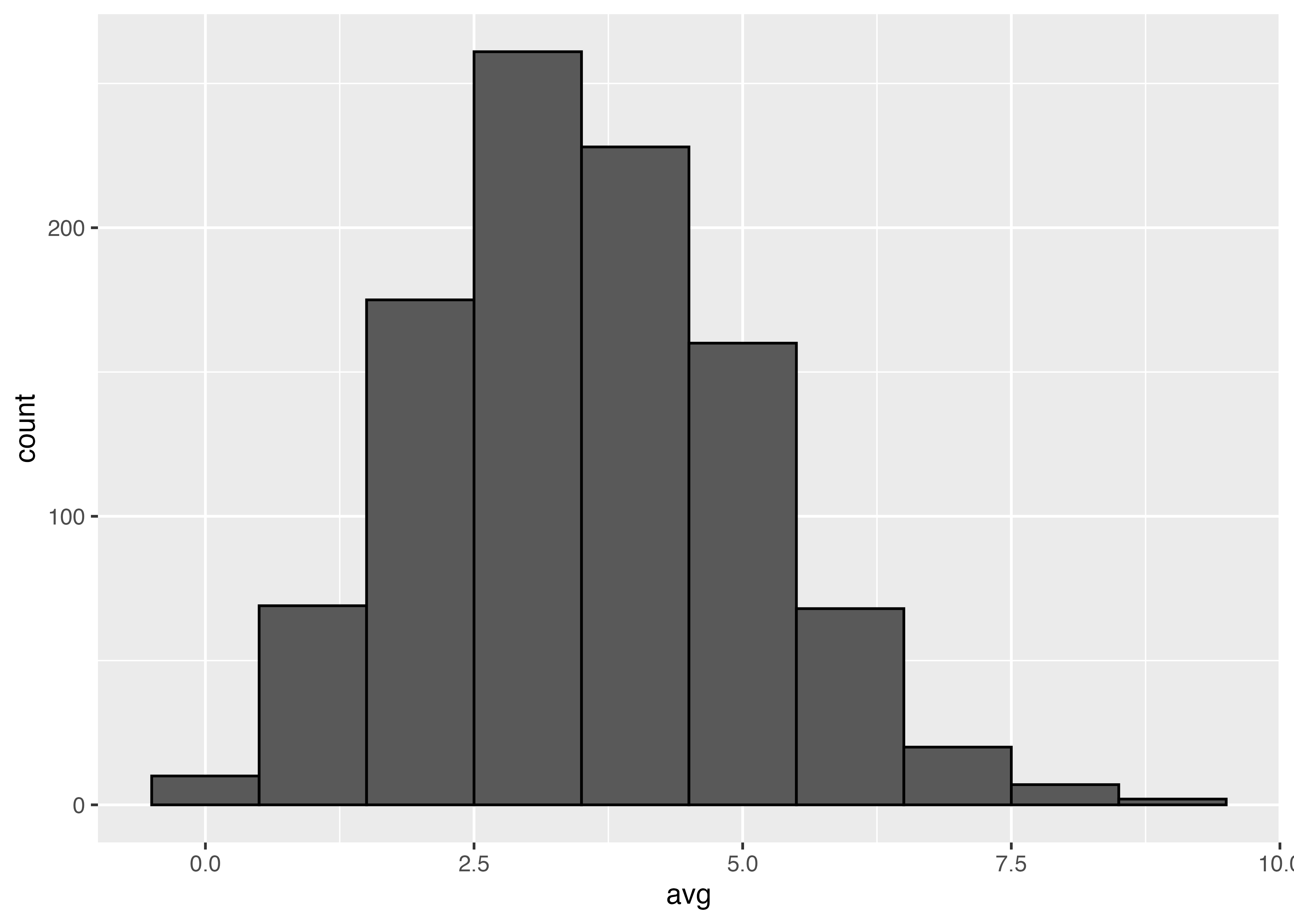
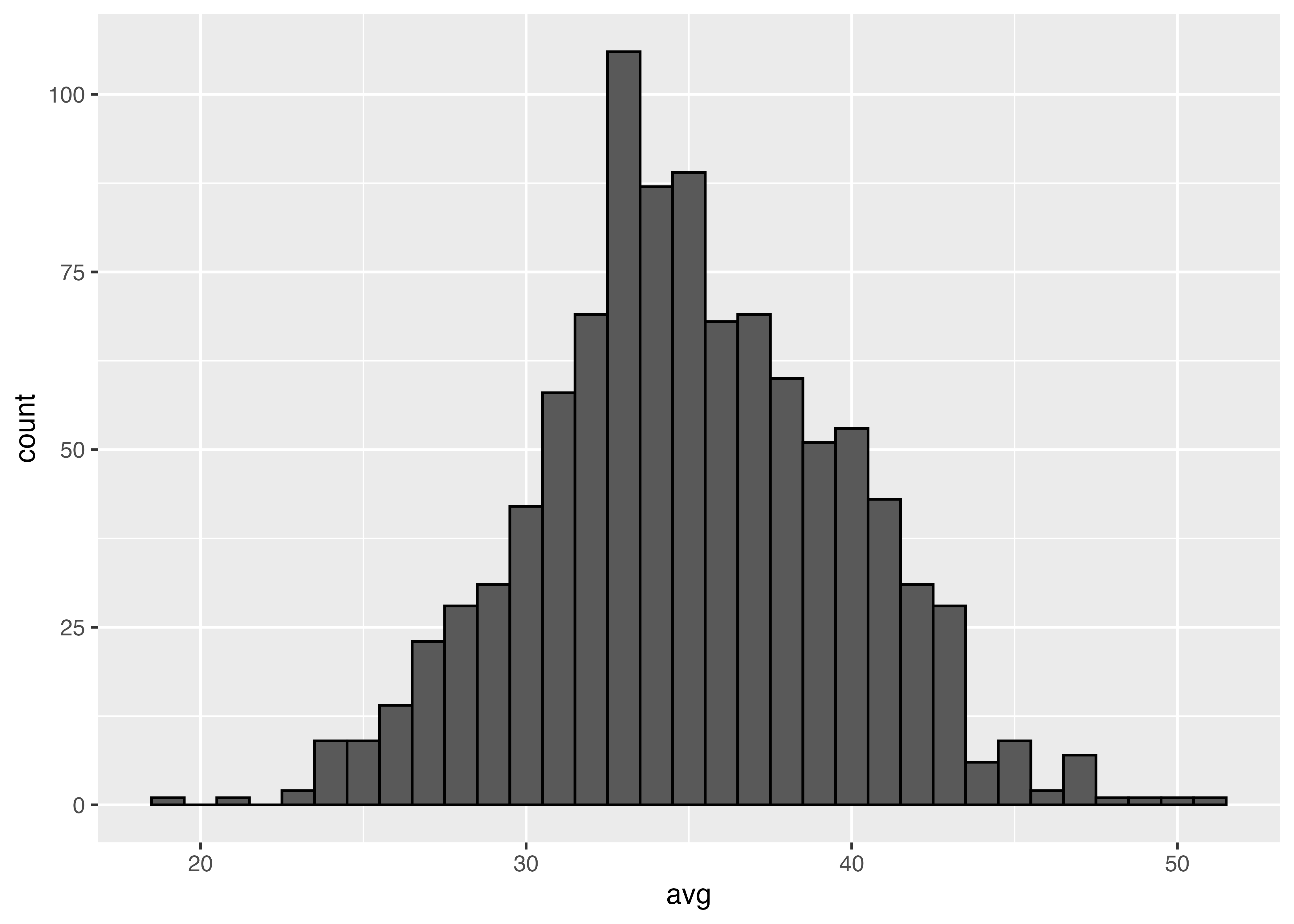
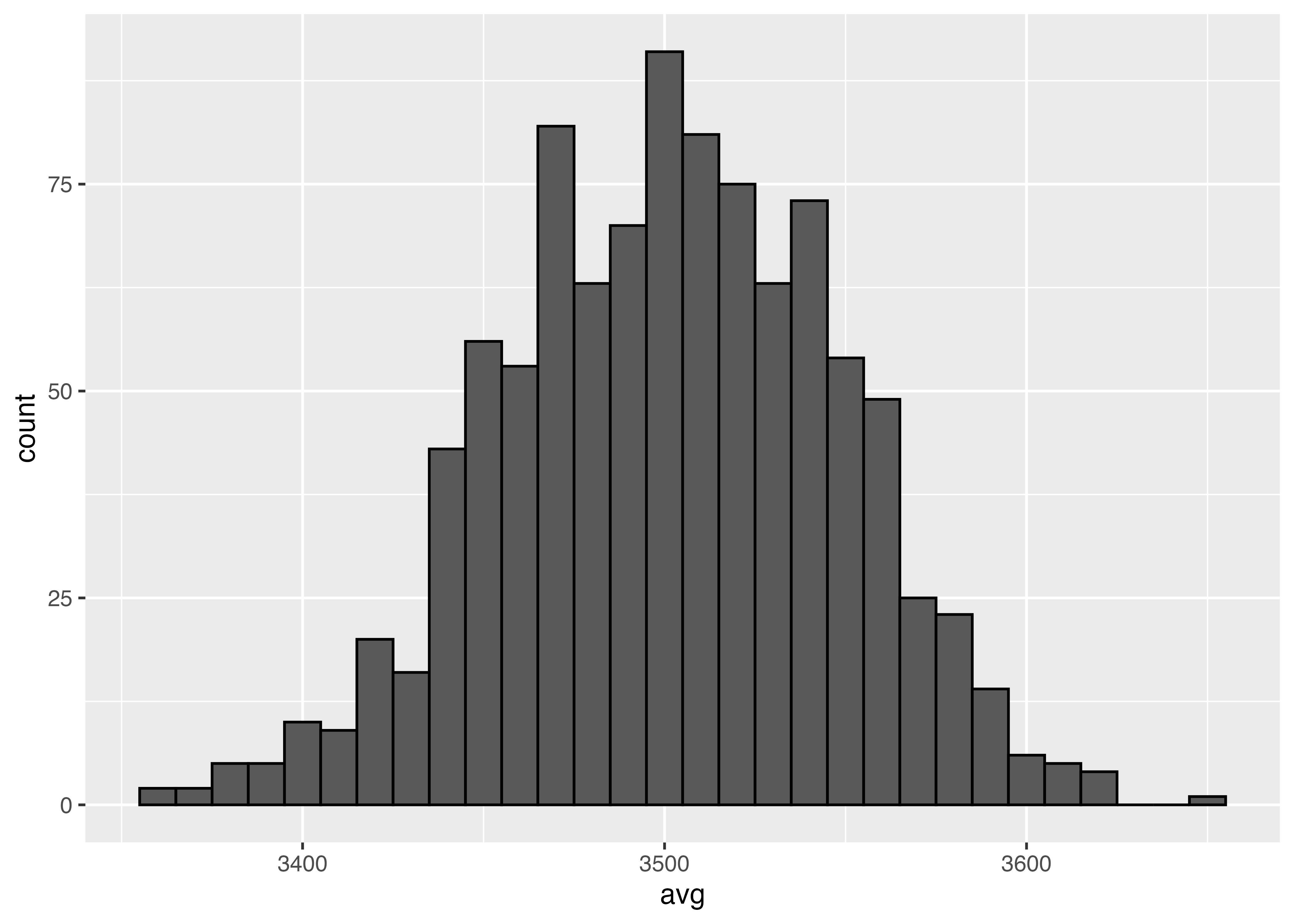
これをサイコロを10000回振るのを1000回繰り返すのに変えてみます。
Min. 1st Qu. Median Mean 3rd Qu. Max.
3.441 3.489 3.500 3.499 3.510 3.546 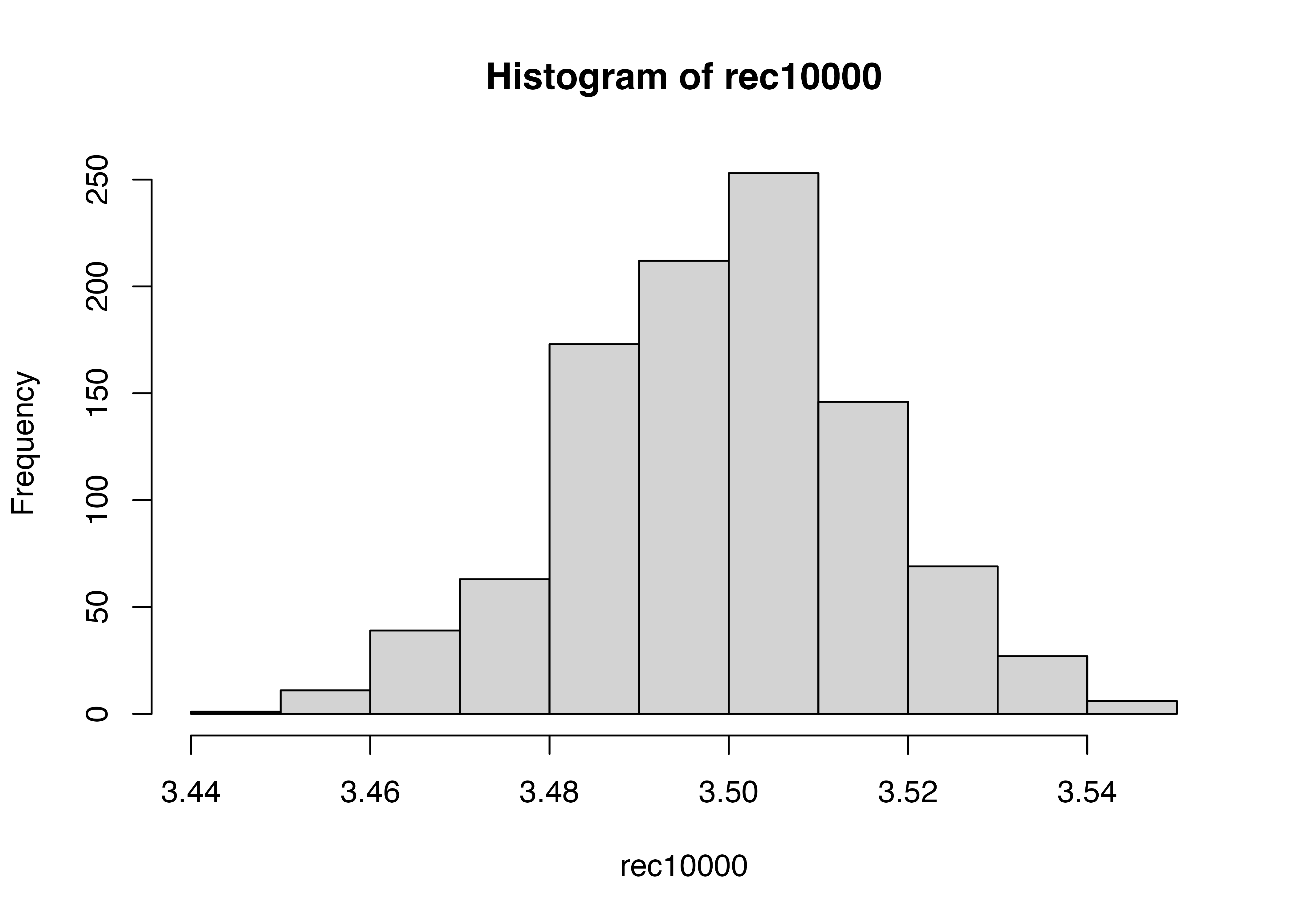
3.5にかなり収束しました。
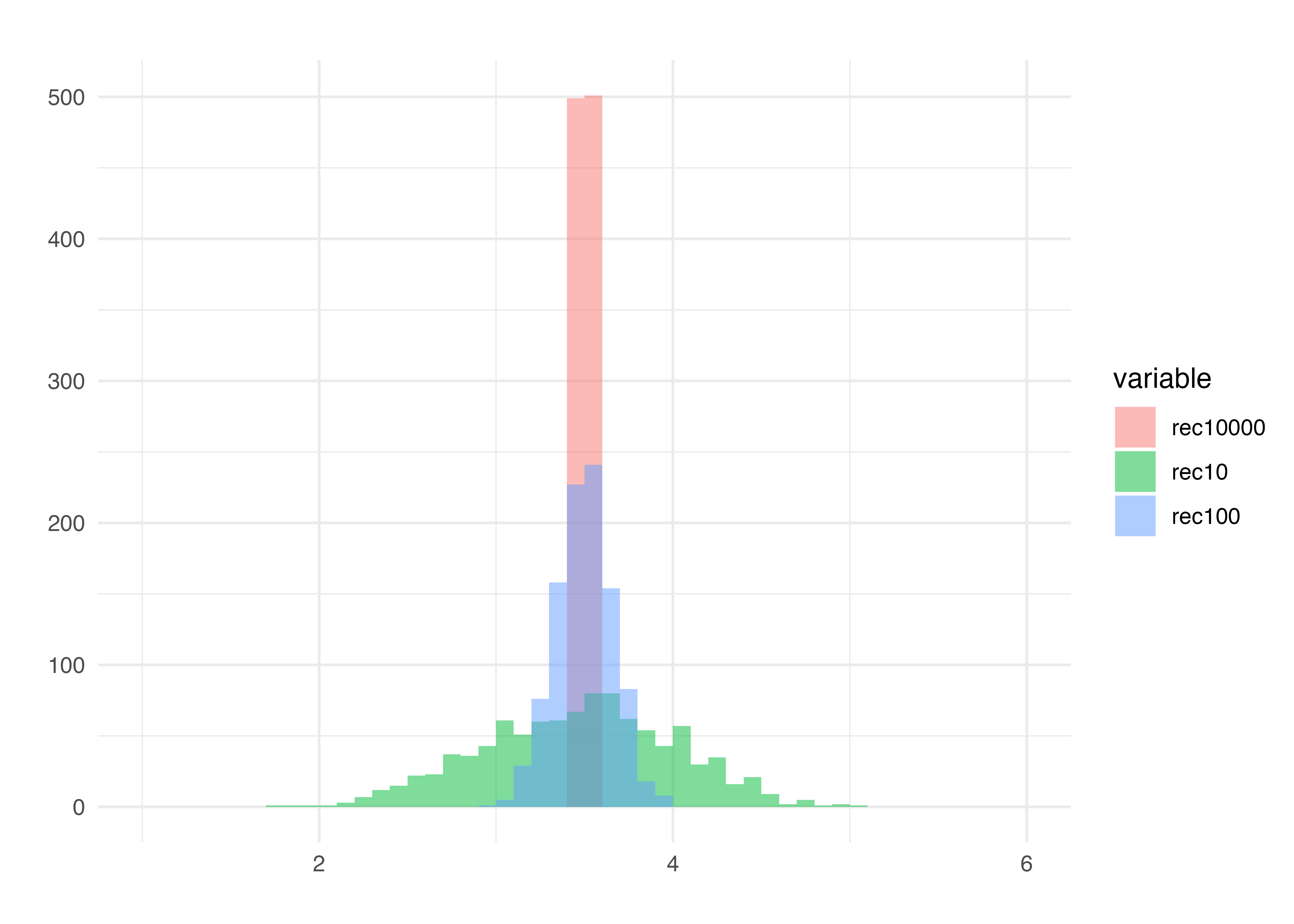
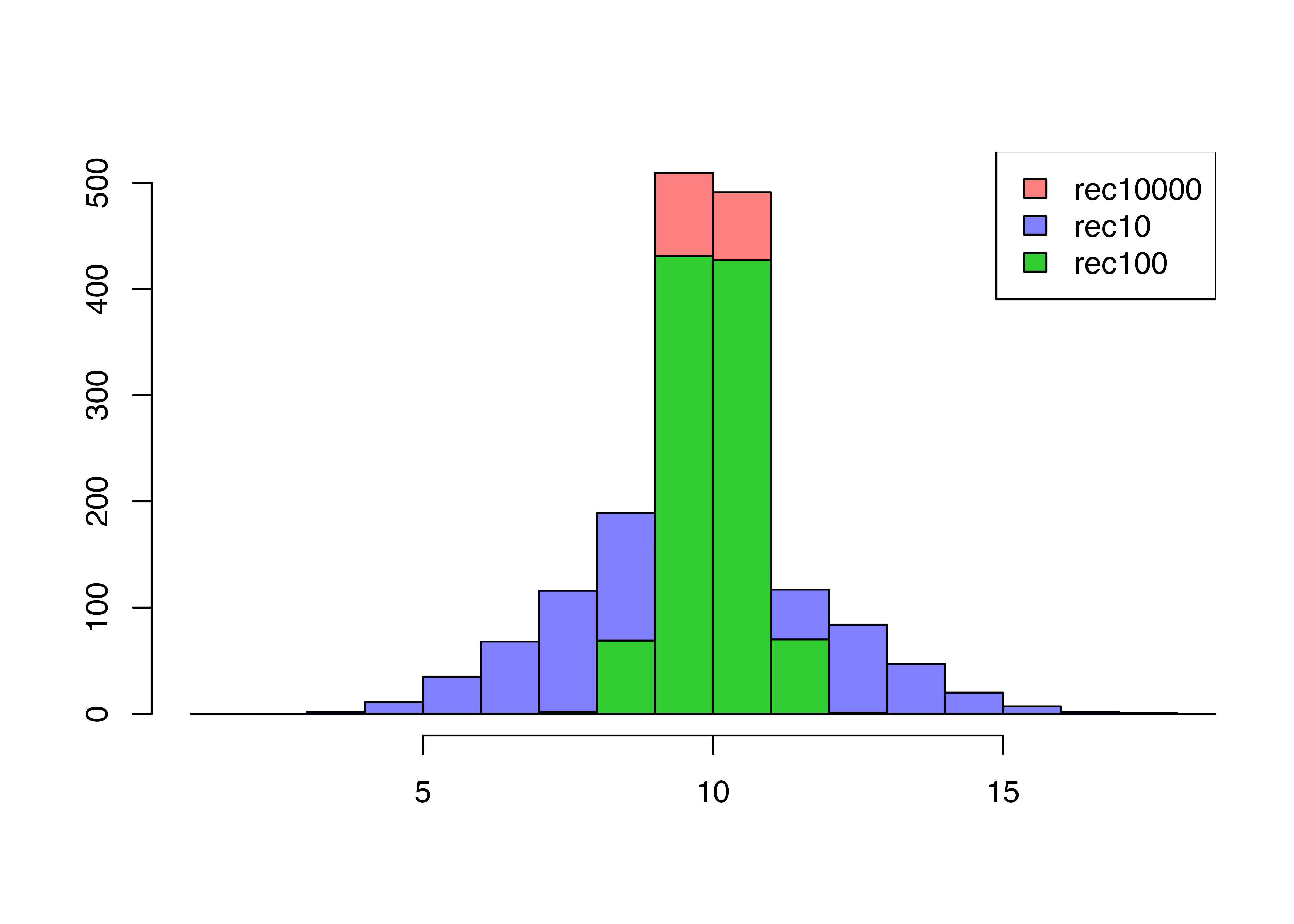
サンプルサイズ100のものも加えてヒストグラムを書きました。一回一回のサンプルサイズが大きいほど,母平均に近い値を取っていることが見えます。
母集団が正規分布であれば
\(X_1, X_2,X3,\cdot\cdot ,X_n\)は正規分布\(N(\mu,\sigma^2)\)からの無作為標本であるとする。このとき標本平均\(\bar X =(X_1+ X_2+X_3+\cdot\cdot +X_n)/n\)の分布は正規分布\(N(\mu,\sigma^2/n)\)
つまり,母集団が正規分布の時は,標本平均も正規分布に従うということが知られています。
例
20代男性の身長の母集団が正規分布\(N(\mu,5^2)\) として,無作為に選ばれた100人の身長の測定値が\(X_1, X_2,X_3,\cdot\cdot ,X_{100}\)とする。標本平均\(\bar X\)で母集団の平均\(\mu\)を推定したい時の測定誤差\(|\bar X - \mu|\)は,上の定理から正規分布\(N(\bar X,0.5^2)\) に従う。これがわかると,2σ区間が \(\mu - 1 \le \bar X \le \mu + 1\)。正規分布で2σ区間に入る確率は95.4%だったので,95.4%の確率で測定誤差が1cm以下となることがわかります。
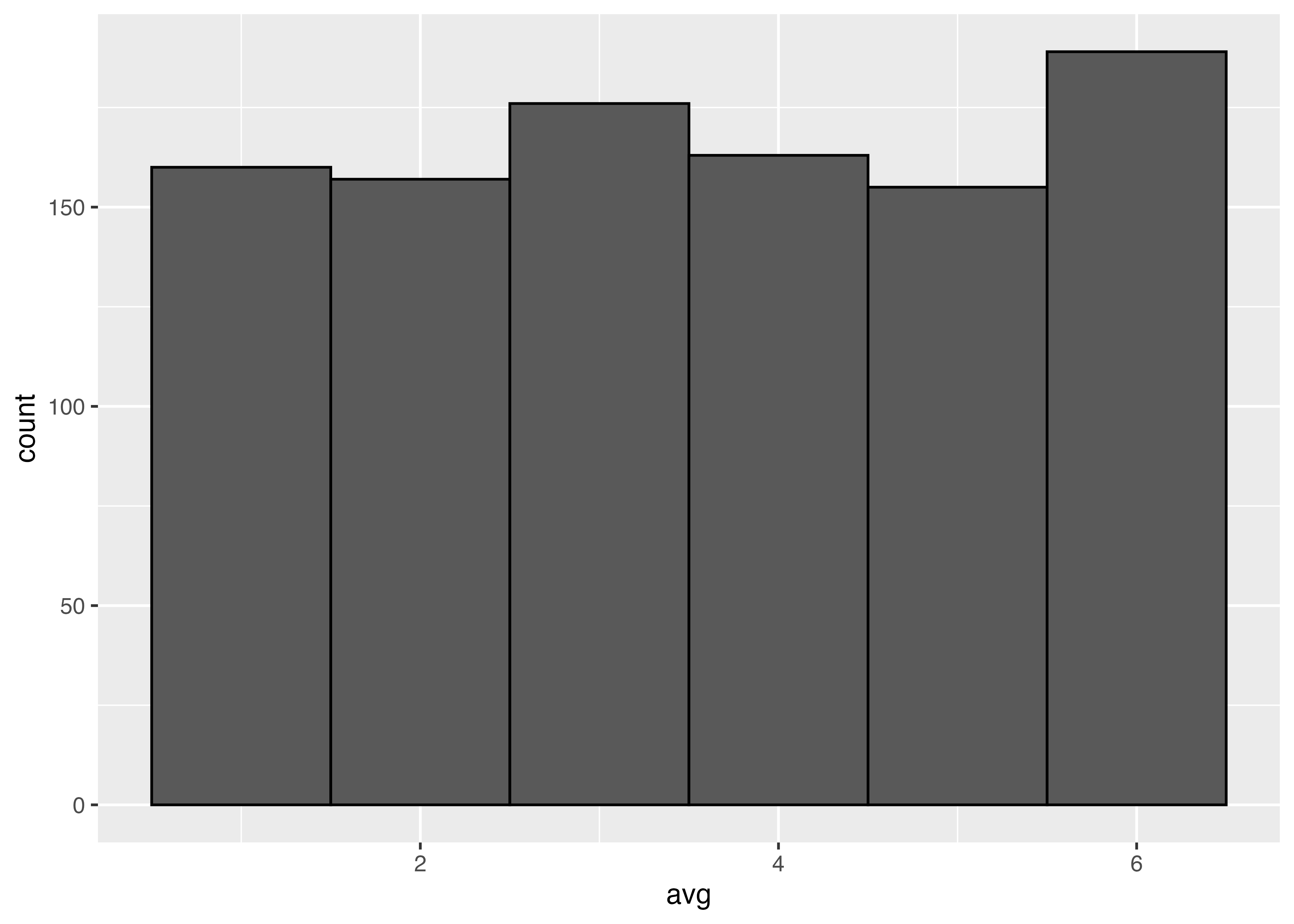
サイコロを1回振った時,平均=出た目。これを1000回繰り返す
同様にサイコロを2回振って平均を取る
10回
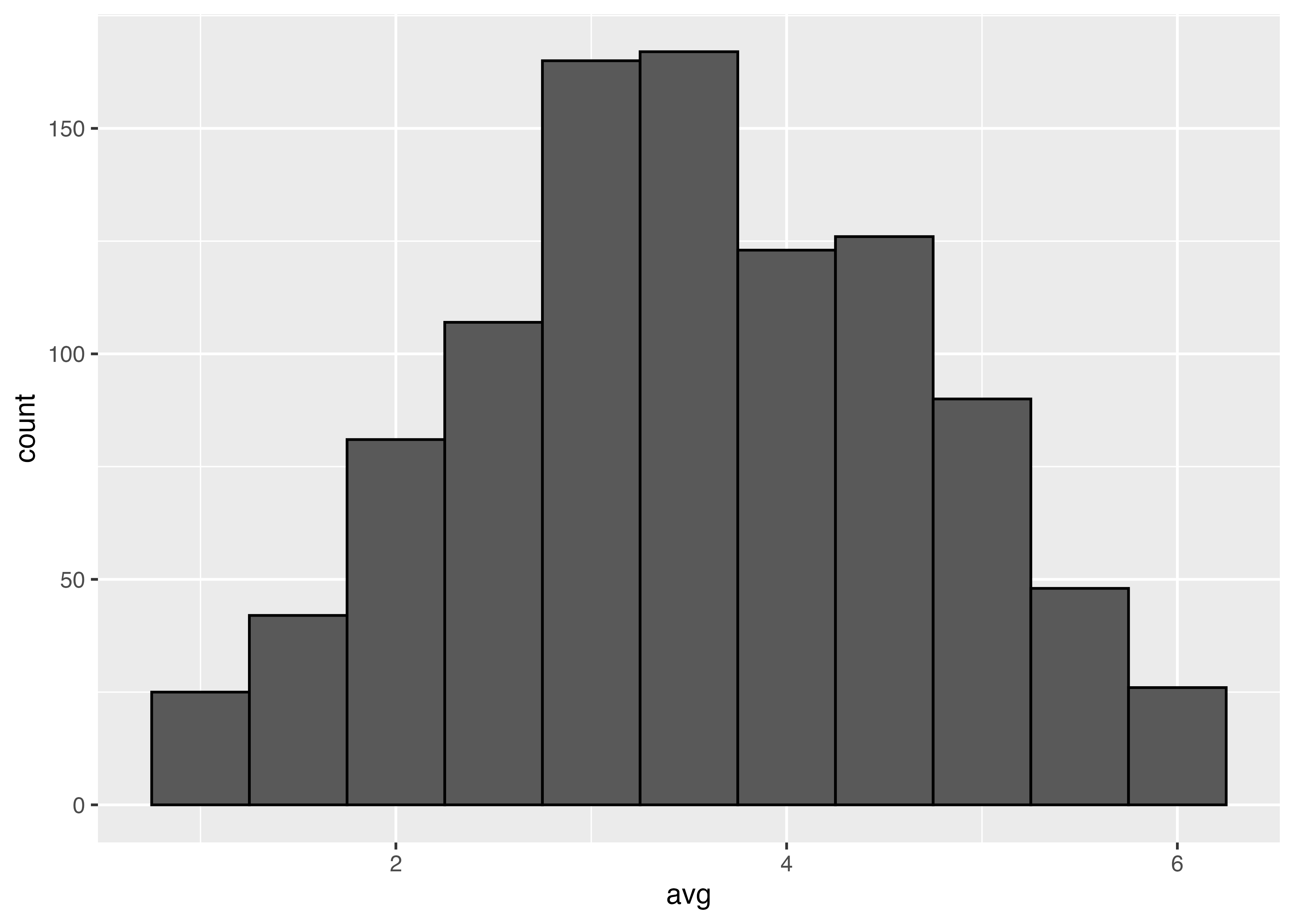
(高校までの確率では「歪みのないコイン」が使われますが)あるコインは,表が出る確率が35%になるような歪み方をしています。
コインを1回投げる,という作業を1000回繰り返してみます。
コインを2回投げて平均をとります。プログラムのsizeの部分を2に変えています。
同様に10回投げた平均
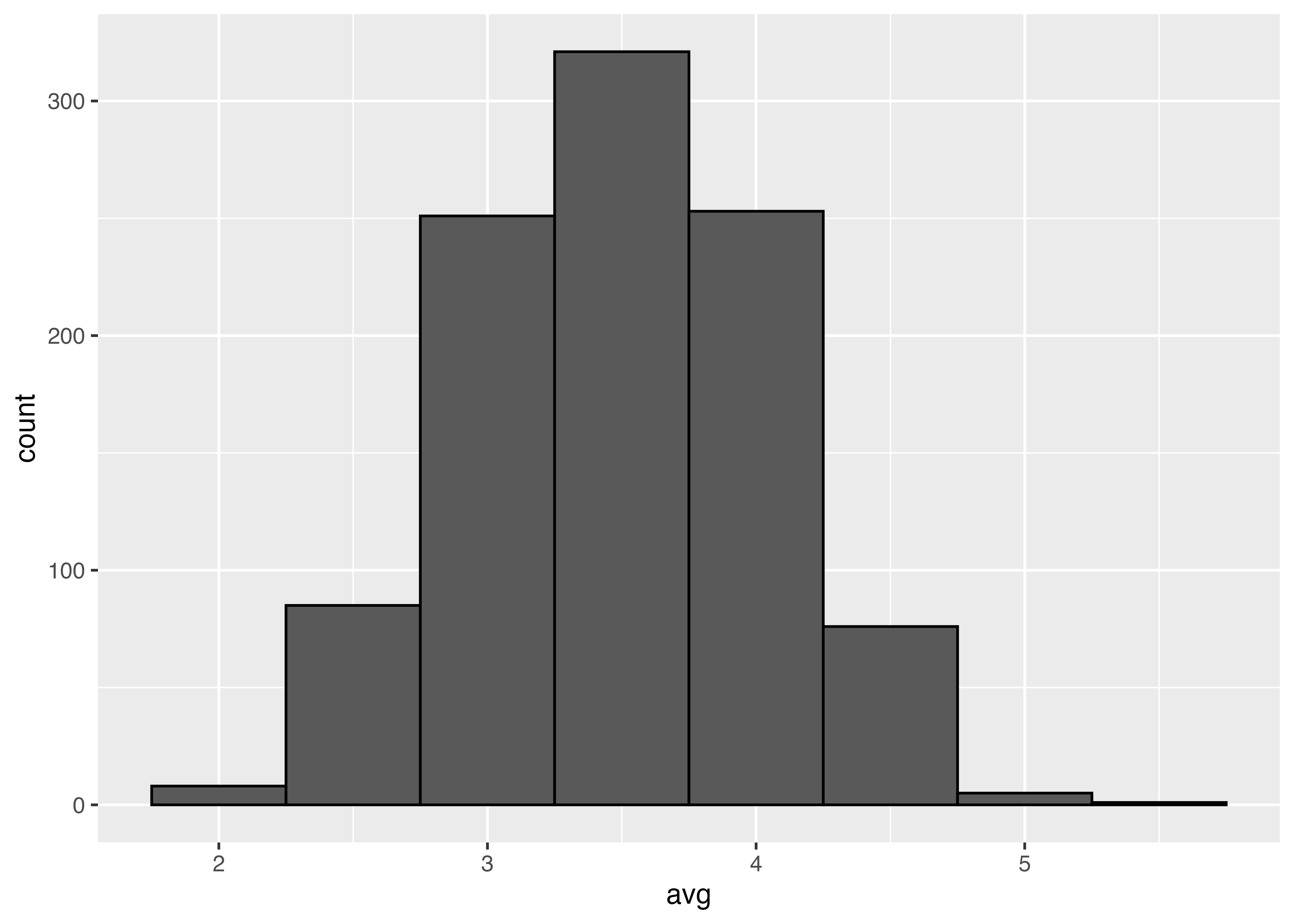
100回
10000回
ここまでをまとめると
無作為抽出という手順と,確率の性質を組み合わせて利用することで,未知の母集団を推測できる!

標本分散や標準偏差についても大数の法則が成立します
S <- 1000
srec10 <- numeric(S)
for(i in 1:S){
srec10[i] <- sd(rnorm(10,50,10))}
srec100 <- numeric(S)
for(i in 1:S){
srec100[i] <- sd(rnorm(100,50,10))}
srec10000 <- numeric(S)
for(i in 1:S){
srec10000[i] <- sd(rnorm(10000,50,10))}
hist(srec10000,
col="#FF00007F",
xlim=c(1,18),ann=F, main="", xlab=""
,breaks=seq(1,20,1))
par(new=T)
hist(srec10,
breaks=seq(1,20,1),
col="#0000FF7F",ann=F, add=T)
hist(srec100,
breaks=seq(1,20,1),
col="#32CD32",ann=F, add=T)
legend("topright",
legend=c("rec10000", "rec10", "rec100"),
fill=c("#FF00007F", "#0000FF7F","#32CD32"))