Code
- 1
- 前の作業など,rのメモリに入っているものをリセットするコマンド
- 2
-
パッケージ管理用のパッケージである
pacmanが入っていない場合はインストール - 3
- 複数のパッケージを一度に呼び出す
2024/05/20

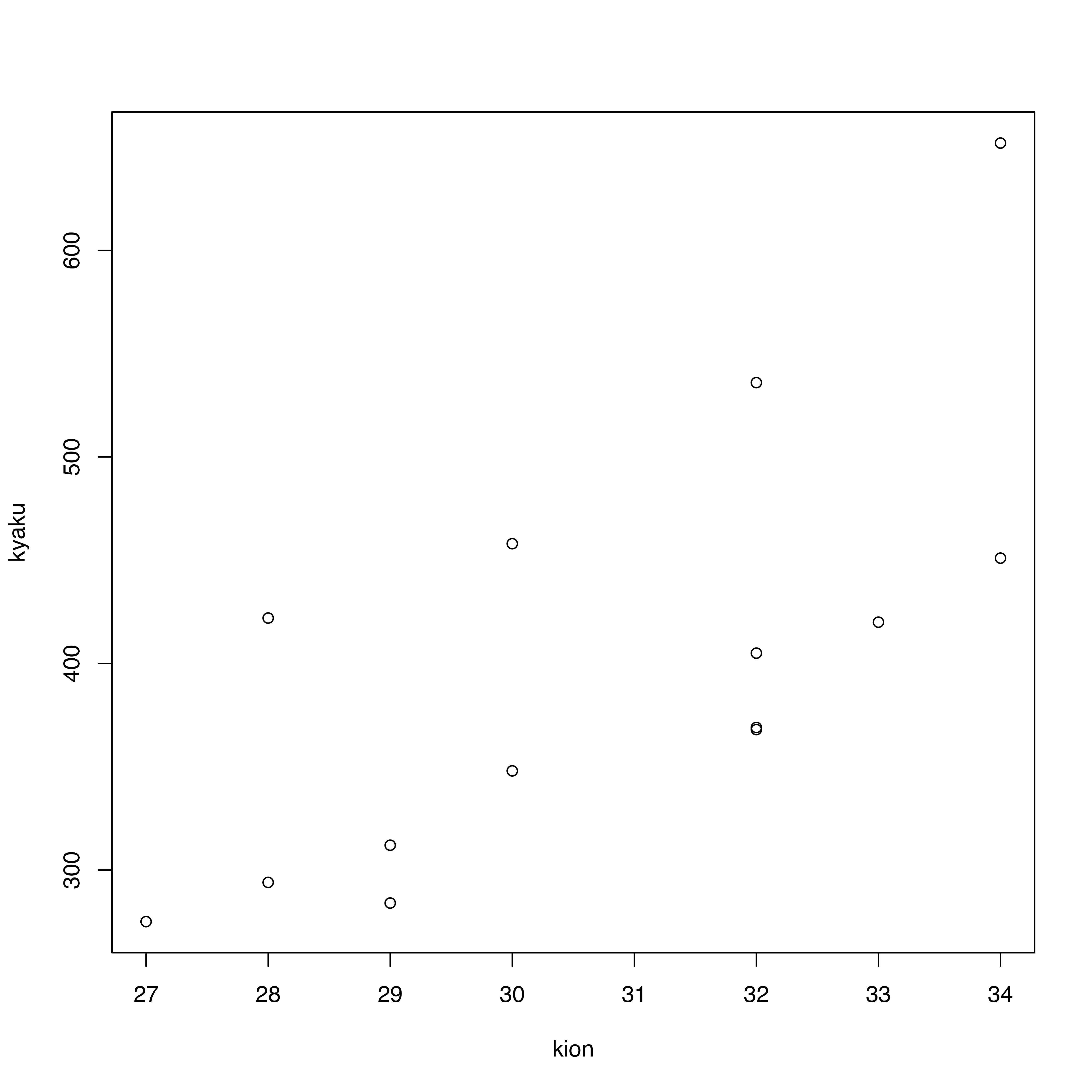
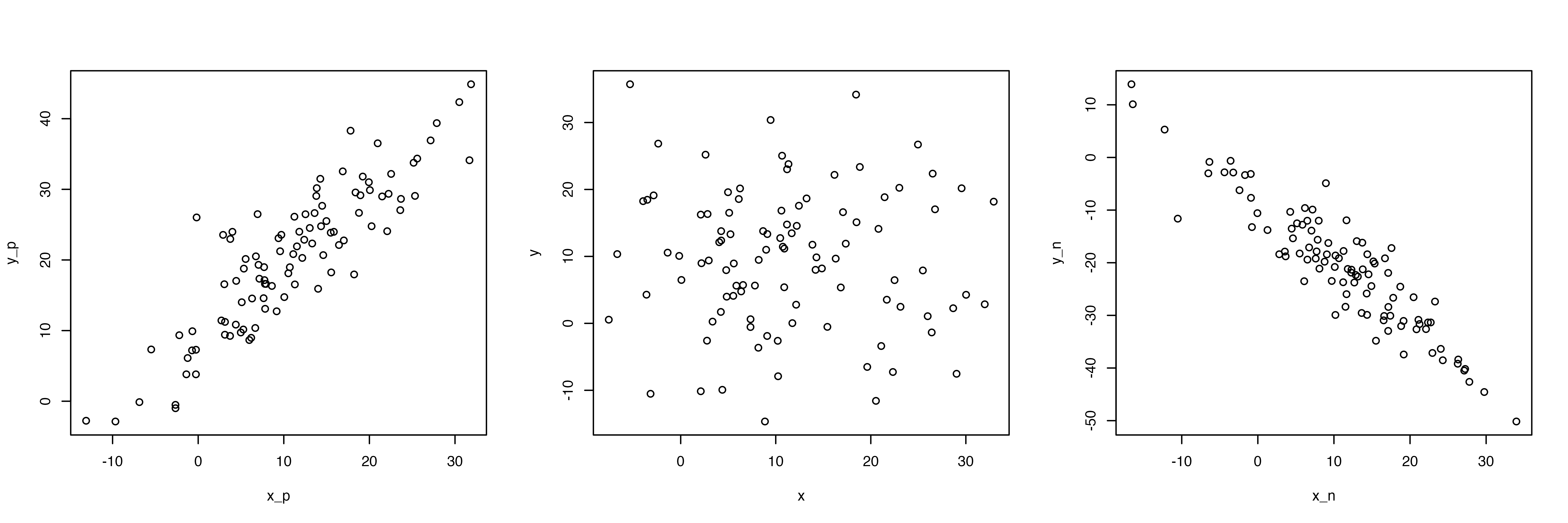
二つの変数,例えば気温とアイスクリーム屋さんの客数との関係を知りたい場合,最も単純な図示の方法は,x軸を気温,y軸を客数として,日毎や時間毎のデータを書き込んでいくこと。これを散布図と言います。
散布図を書いています。散布図を書く一番簡単なコマンドはplot(x軸にしたい変数, y軸にしたい変数)です。
ggplot2というパッケージ(tidyverseの中に入っている)を使うと高度にカスタマイズしたグラフが書けます。
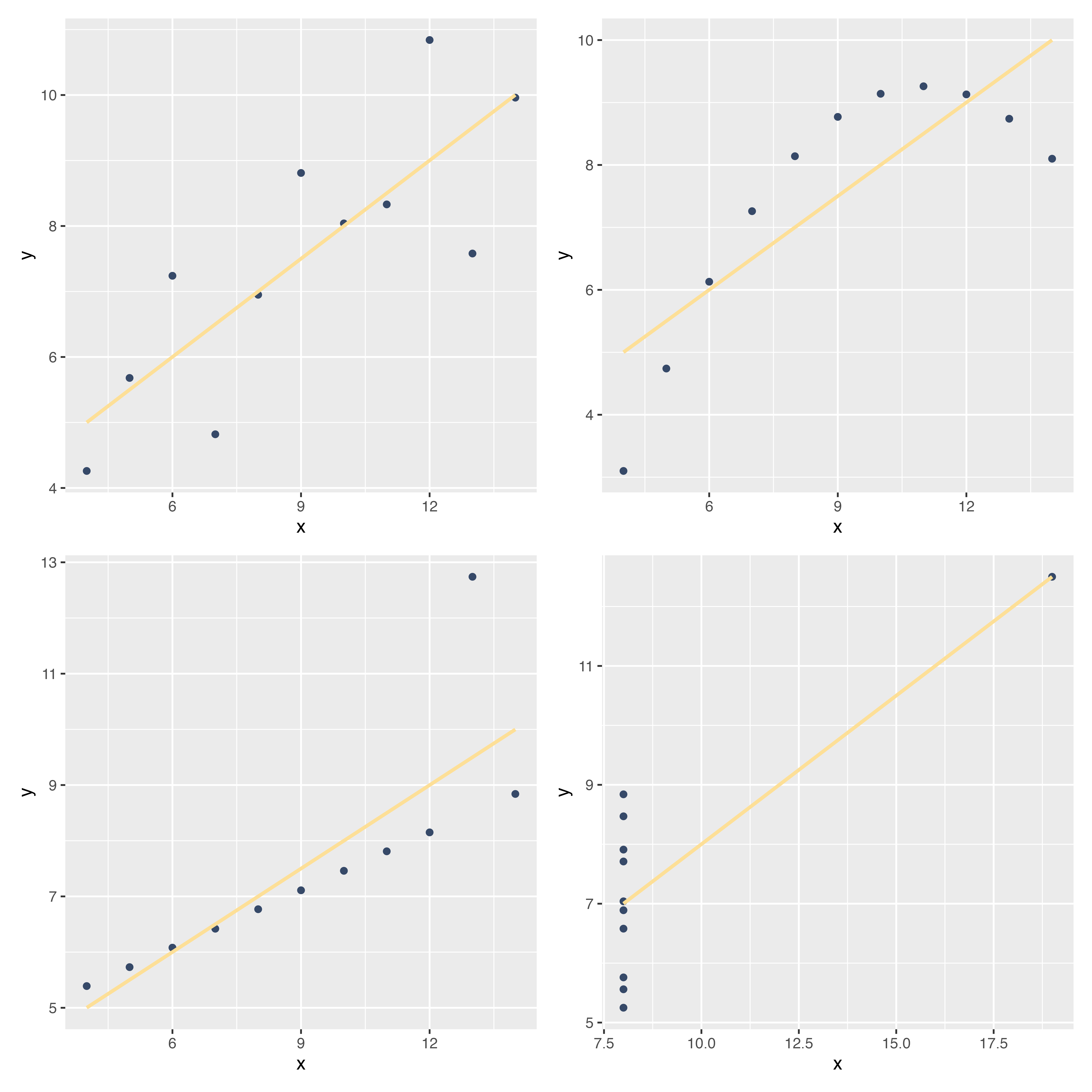
ここで,散布図から視覚的にわかることとして,右肩上がりだと正の関係(片方が高いともう片方も高い),右肩下がりだと負の関係,バラバラに散らばっていると関係がなさそう,ということ。
左は正の関係(xが増えるとyも増える),真ん中は関係なし(xとyに特段の関係が見て取れない),右は負の関係(xが増えるとyが減る)
相関係数(correlation)は,cor()関数でできます。先ほどの3つの例の相関係数はそれぞれ以下の通り
a<-ggplot(mapping = aes(x_p, y_p)) + #グラフを作成
geom_point() + #書く数値を点(point)で書く
theme(aspect.ratio = 1)
b<-ggplot(mapping = aes(x, y)) + #グラフを作成
geom_point() + #書く数値を点(point)で書く
theme(aspect.ratio = 1)
c<-ggplot(mapping = aes(x_n, y_n)) + #グラフを作成
geom_point() + #書く数値を点(point)で書く
theme(aspect.ratio = 1)
plot_grid(a, b, c, nrow = 1)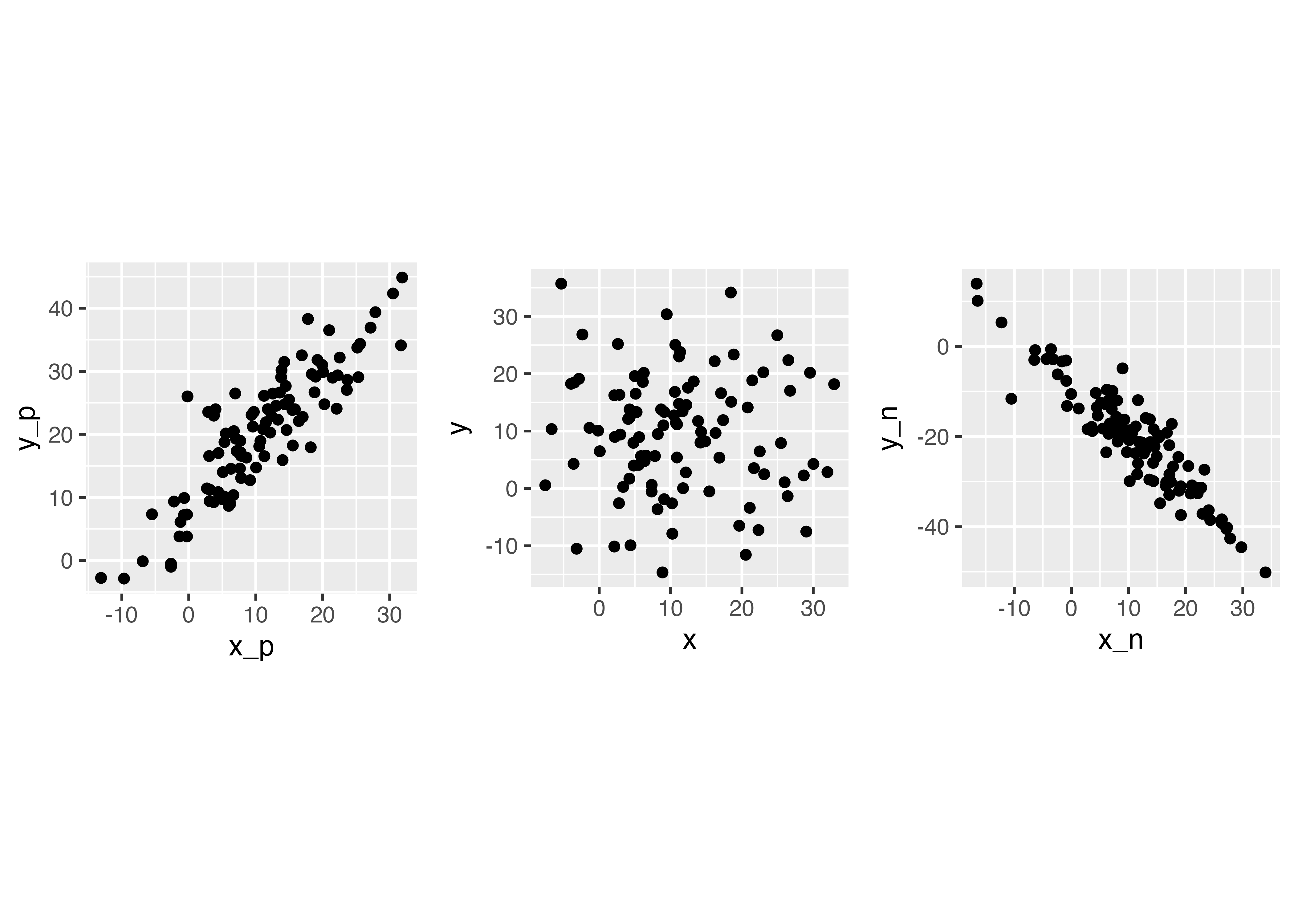
質的変数と量的変数の関係は一部すでに前回やっています。
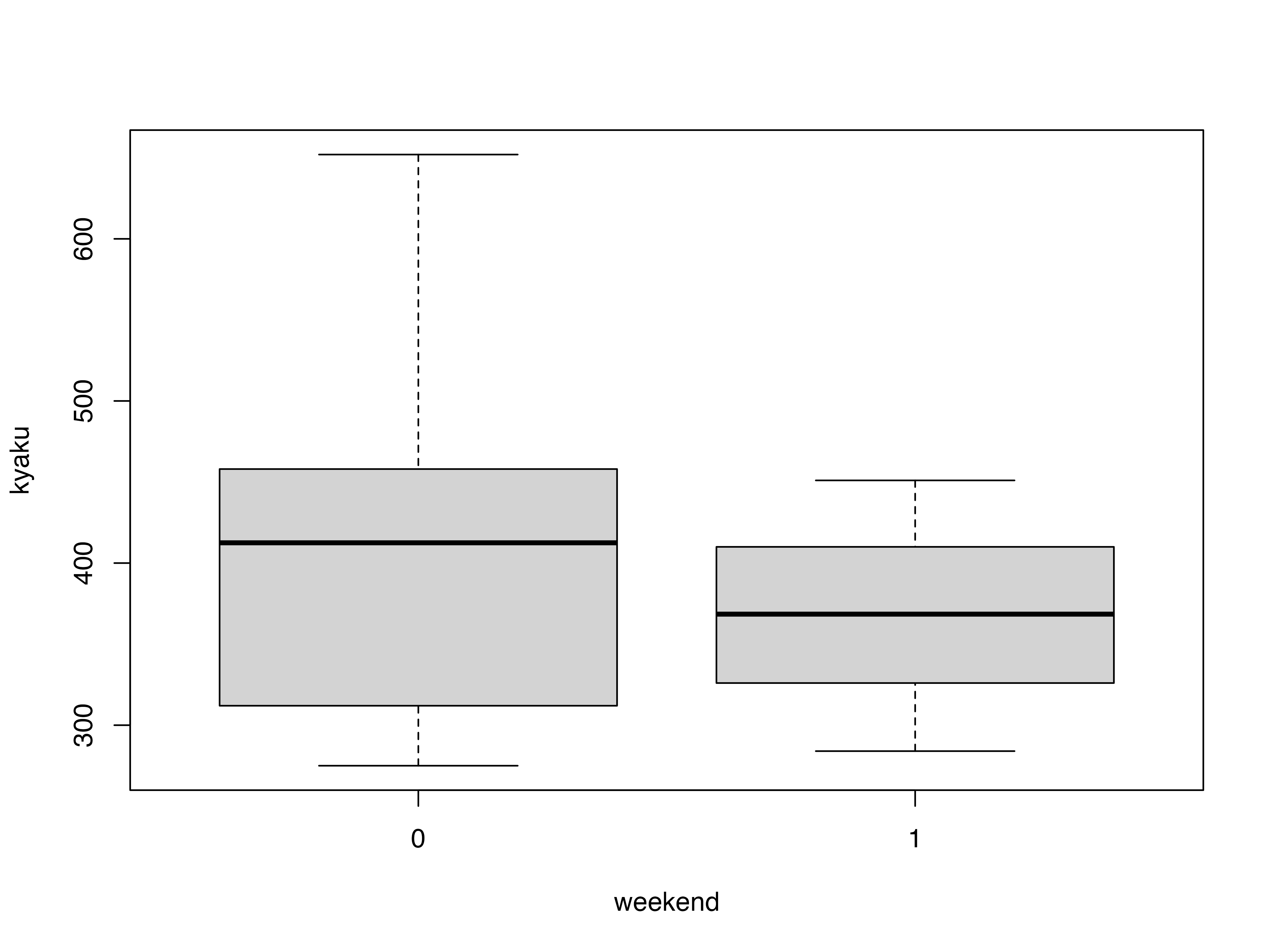
例えば平日と休日の客数平均,標準偏差,最大値,最小値を分けて
| 0 | 1 | |||||||
|---|---|---|---|---|---|---|---|---|
| mean | sd | max | min | mean | sd | max | min | |
| kyaku | 412.20 | 116.47 | 652.00 | 275.00 | 368.00 | 68.18 | 451.00 | 284.00 |
平日と休日で分けた箱ひげ図も
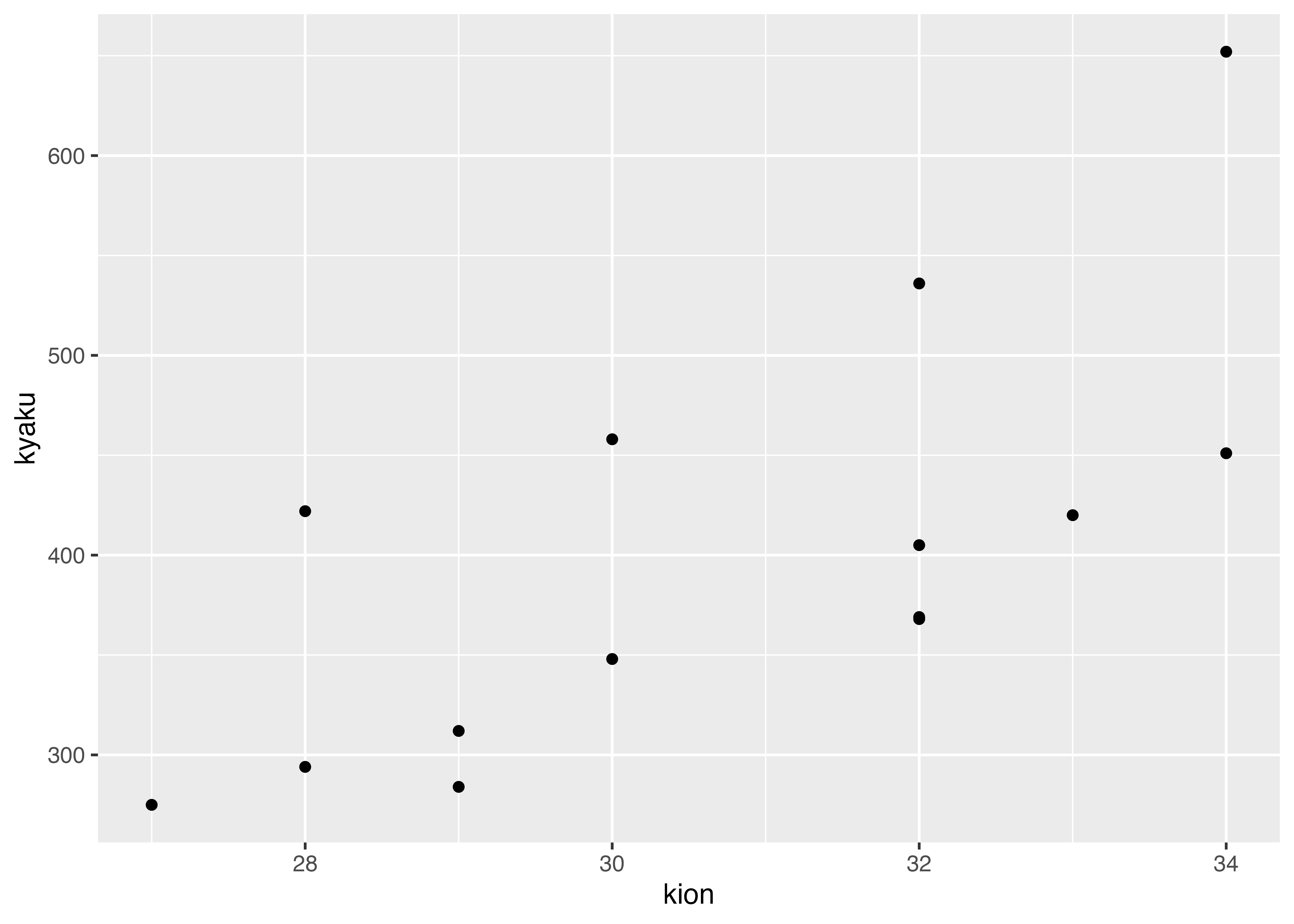
以下は,気温と客数の散布図(再掲)です。
この変数間の関係を直線関係
\[ 客数 = a + b \times気温 \]
を当てはめることを考えます。この当てはめかたとして,最もよく使われるのが最小二乗法で,それによって求められた直線を回帰直線と言います。
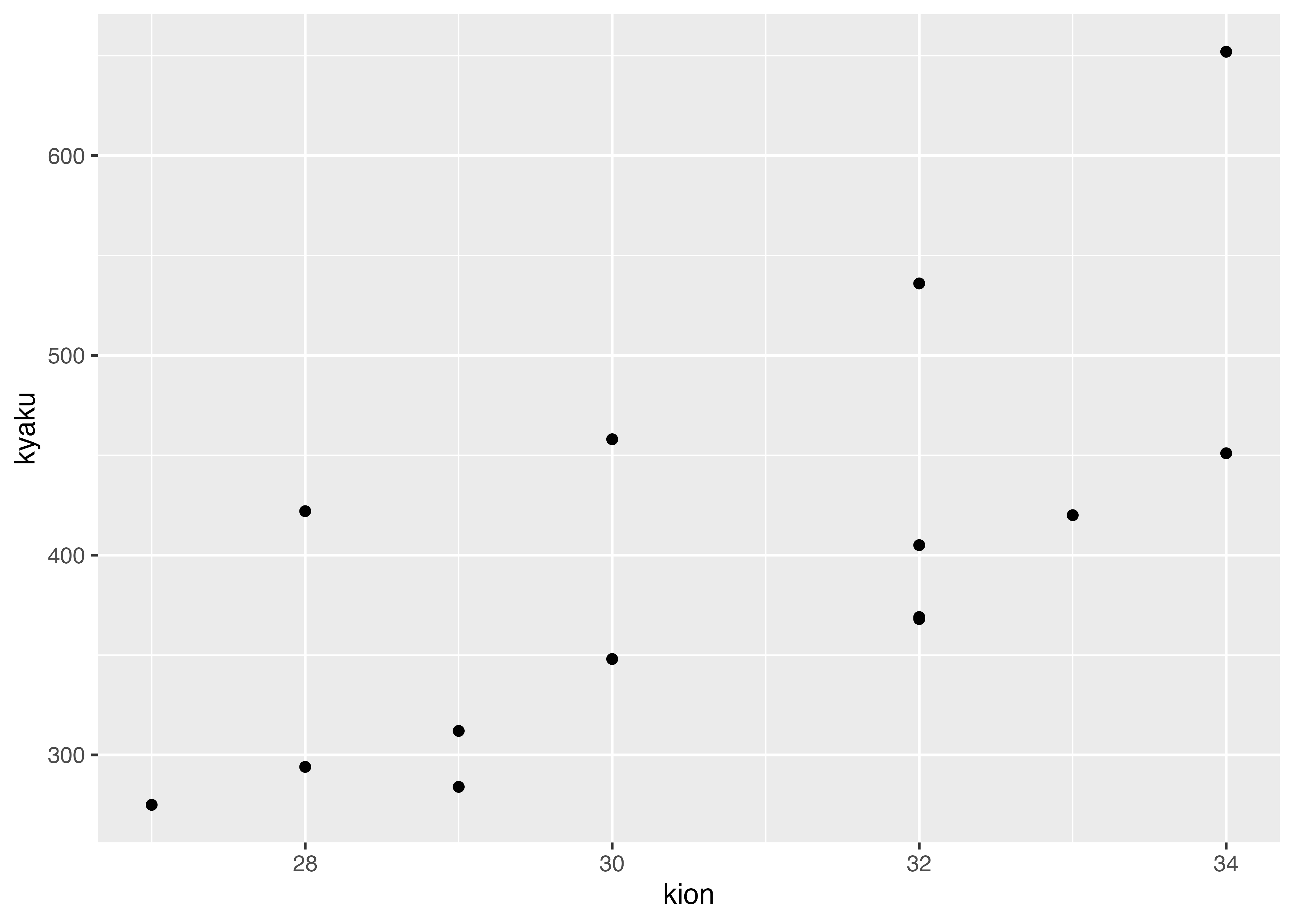
計算方法等詳しくは第8回でお話ししますが,このデータを使って推定すると
\[ 客数 = -572.52 + 31.65気温 \]
と求まります。
傾き31.65は,気温が1度上がった時に客数が31.65人増えるということを意味しています。
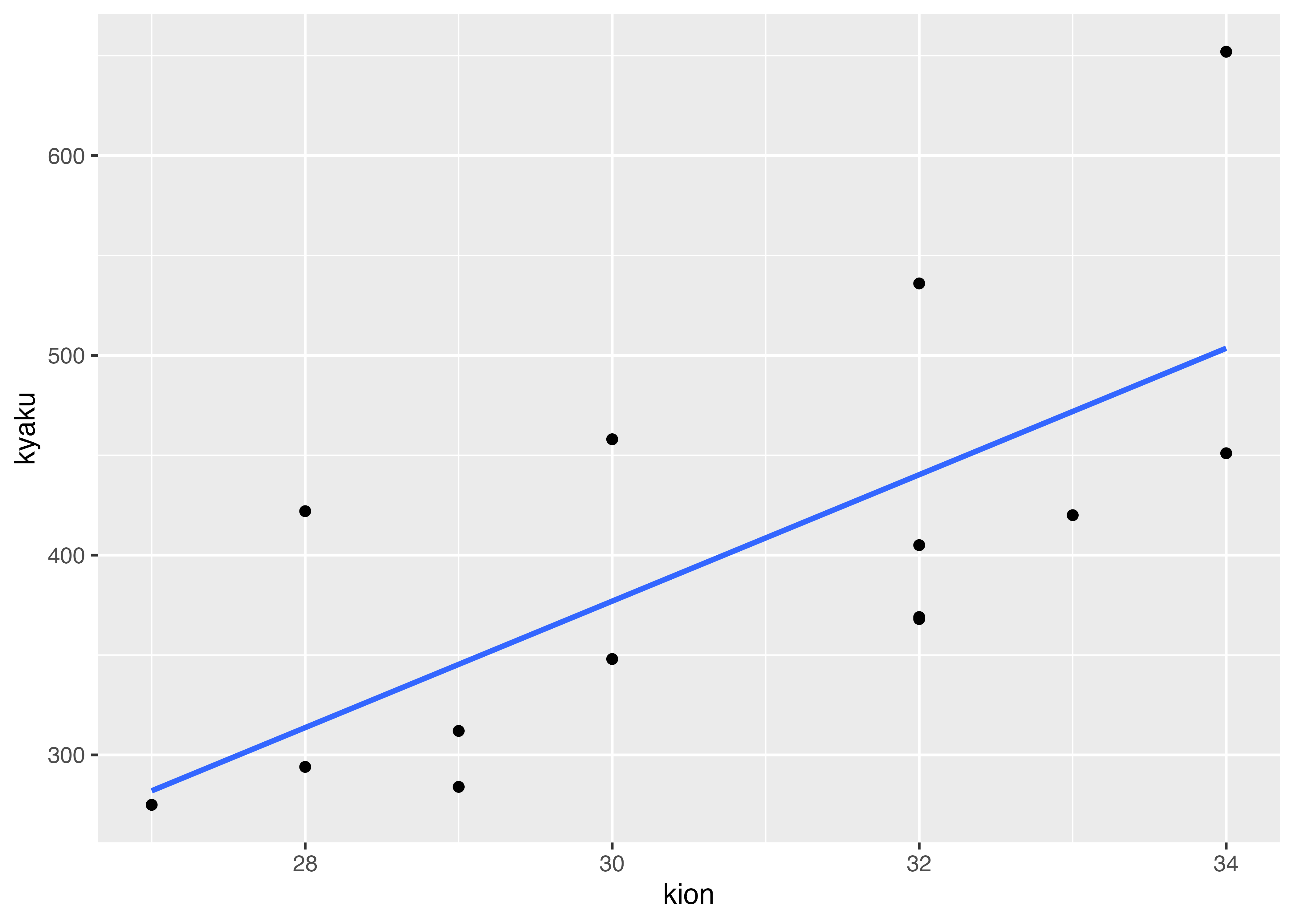
ただし,回帰分析は,時に真の関係とは違った線を引いてしまうことがあります。