Code
- 1
- 前の作業など,rのメモリに入っているものをリセットするコマンド
- 2
-
パッケージ管理用のパッケージである
pacmanが入っていない場合はインストール - 3
- 複数のパッケージを一度に呼び出す
2024/05/13
データの中から条件に適合する要素を取り出したい,みたいなことはよくあります(Excelだとピボットテーブル機能とかを使う場合です)。そんな際に役に立つ関数を2種類ご紹介しておきます。
課題には使っても使わなくても大丈夫ですが,うまく使えば同じことを便利にできる場合があります。
紹介する関数は,どちらもtidyverseパッケージの使用を前提としています。
第4回でも使った,学生のテストデータです。
filter()関数filter()関数は,条件に合った行だけを取り出す関数です。例えば,男性だけのデータを取り出したい場合,以下のように指定します。
|>で,次の行に渡すfilter()の()内に条件を書く。
==」のように,イコールを2回重ねて表記する!=」で表すテストが80点以上の人だけを取り出す場合は以下のようにできます。
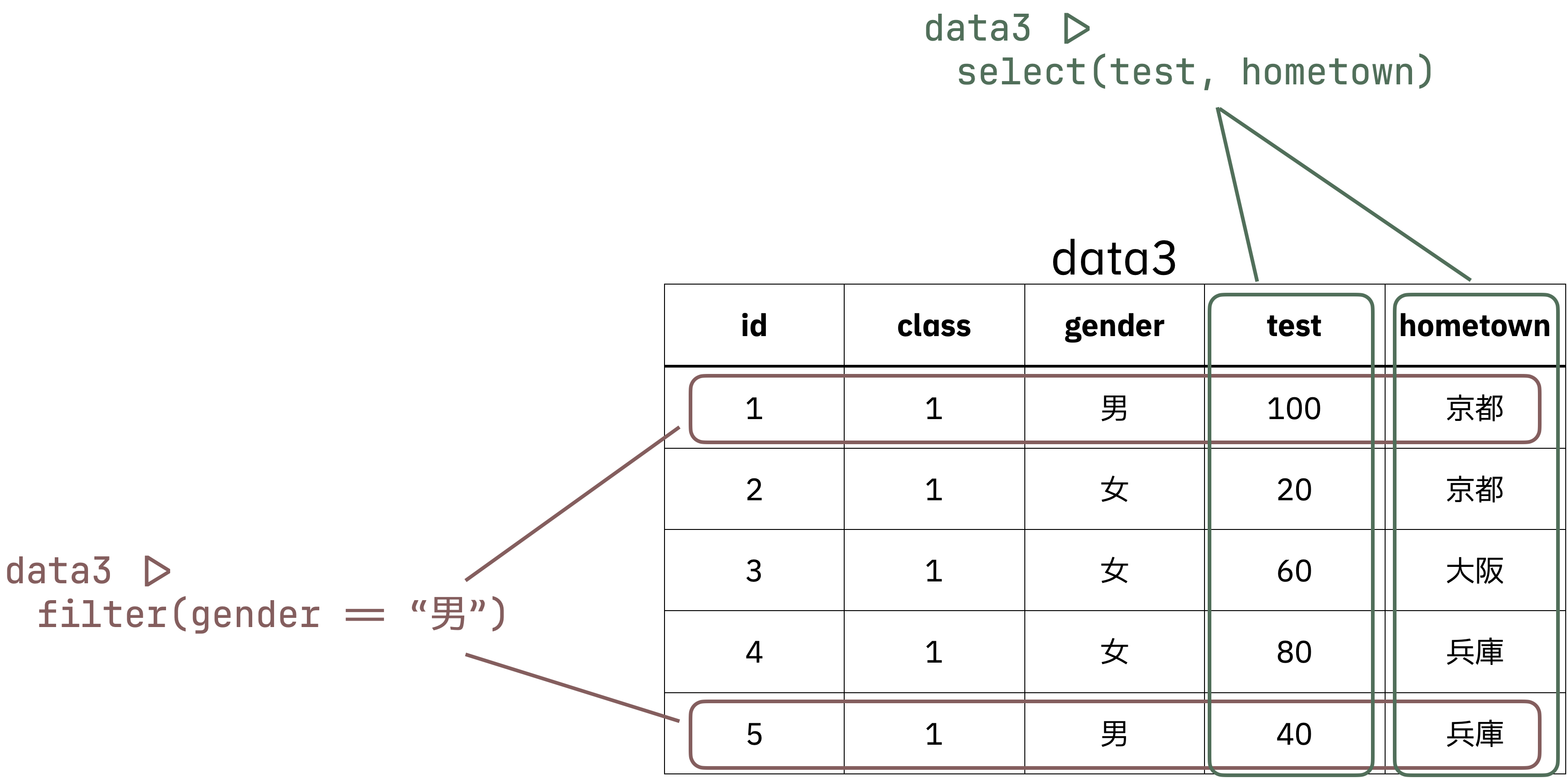
select()関数select()関数は,指定した列だけを取り出す関数です。
特定の列だけ取り出して計算したいときなどに便利です
test
Min. : 10
1st Qu.: 45
Median : 60
Mean : 60
3rd Qu.: 85
Max. :100 上のコードでは,女性のデータ(行)のみを取り出し,test列だけを持ってきて,平均や中央値を算出(summary()関数)しています。
4_population.csvデータは都道府県別の2020年の人口データです(e-statより)
ken: 都道府県名population: 人口male: 男性人口female: 女性人口japanese: 日本人人口foreign: 外国人人口birth: 出生数death: 死亡数in-population: 転入out-population: 転出household: 世帯数dual-income: 共働世帯数solo: 単身世帯数marriage: 婚姻件数divorce: 離婚件数here()は,プロジェクト内のファイルがある場所を指定します。もし第2回授業の通りにプロジェクトを作成し,その中にdataフォルダを作成できていて,さらにそこに4_population.csvを入れられていたら,このコードで場所を正確に指定できます。
データの読み込みについて詳細は第2回資料を参照してください。
上の通り,4_population.csvデータをpopulationという名前をつけて読み込んで,以下の計算をしてください。(平均値・最大値・中央値等や,ヒストグラムの内容,プログラム方法は第4回資料,データの読み込み方やその他Rの使い方全般は第2回資料にあります)
which.min()とwhich.max()関数は,()内の変数の最大値が何行目なのかを教えてくれる関数です。これを使って,外国人人口が最小の都道府県と最大の都道府県を特定してください。コードと結果を記載してください。genderを作成してください。その上でgenderの平均値・中央値を算出してください(変数の作り方は第2回資料にあります)。コードとその結果を記載してください。2024社会調査法(立命館大学)