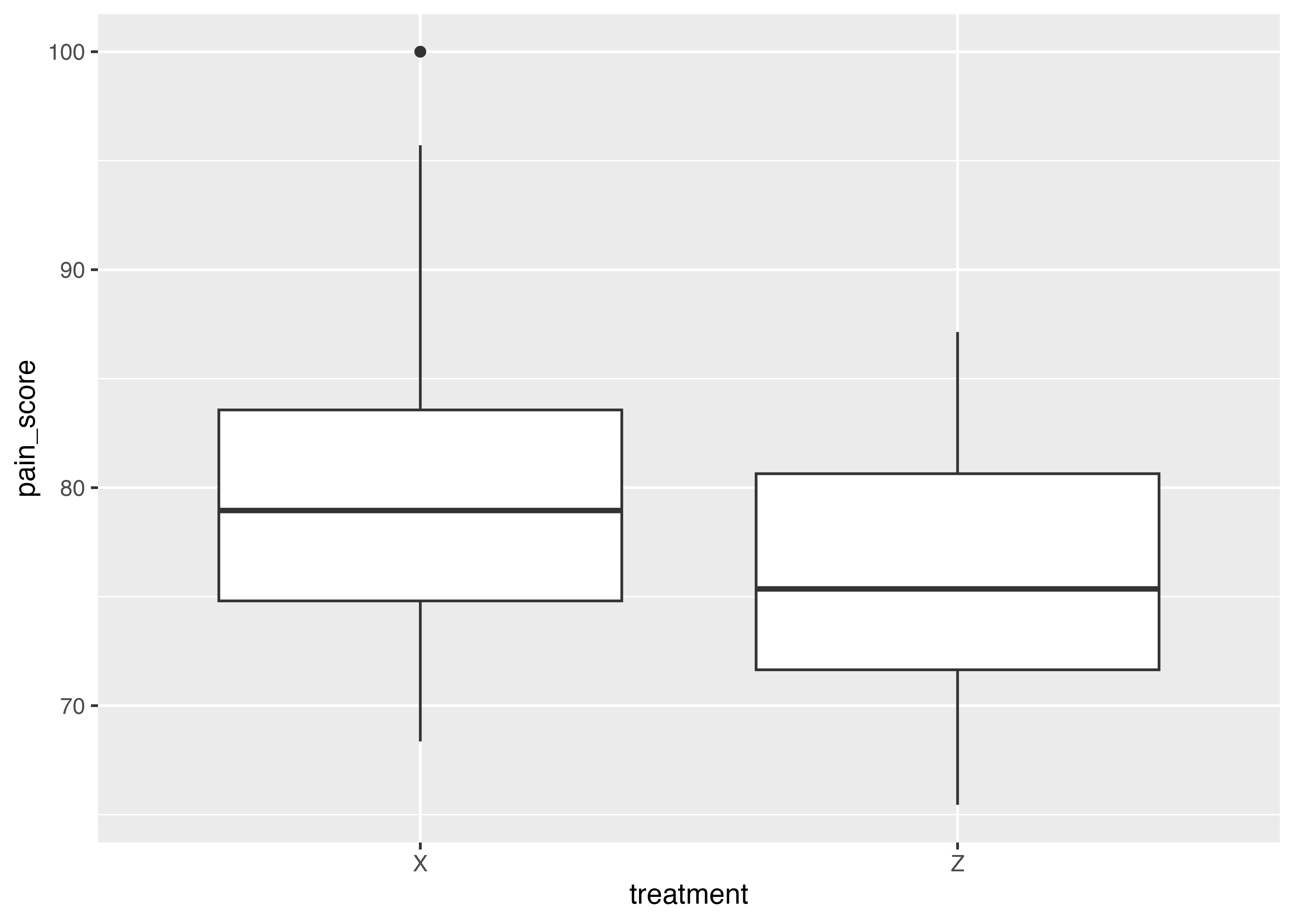
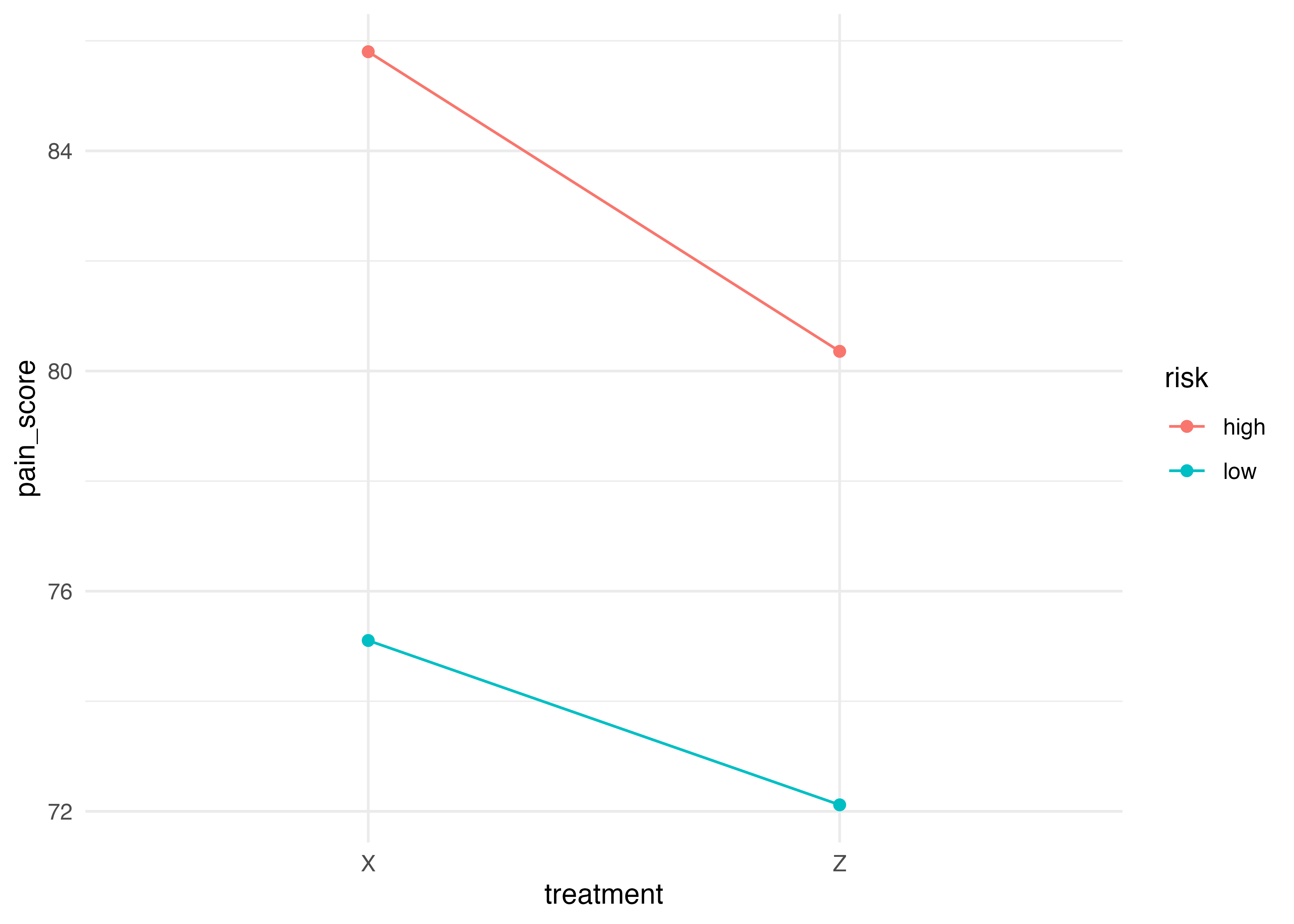
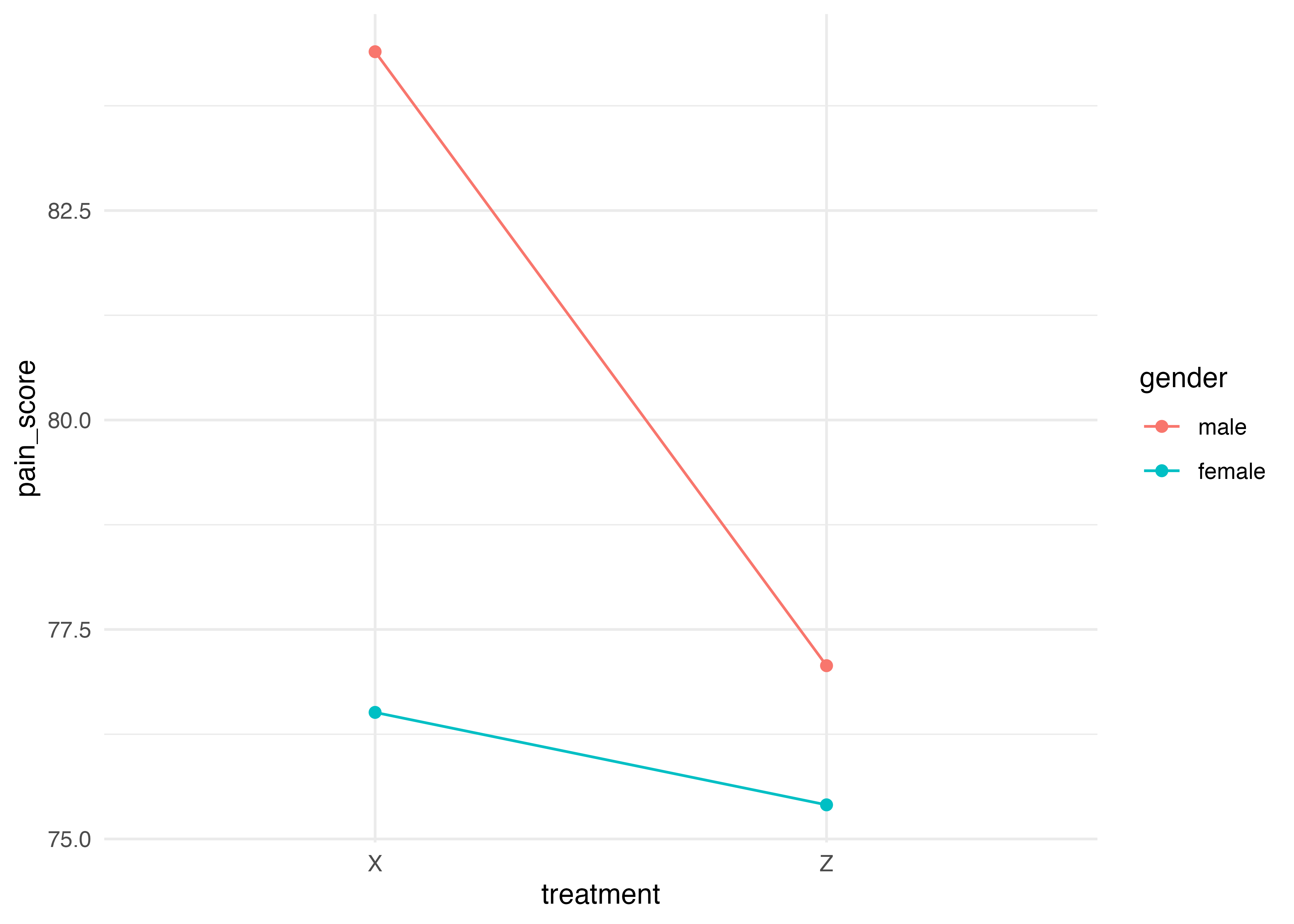
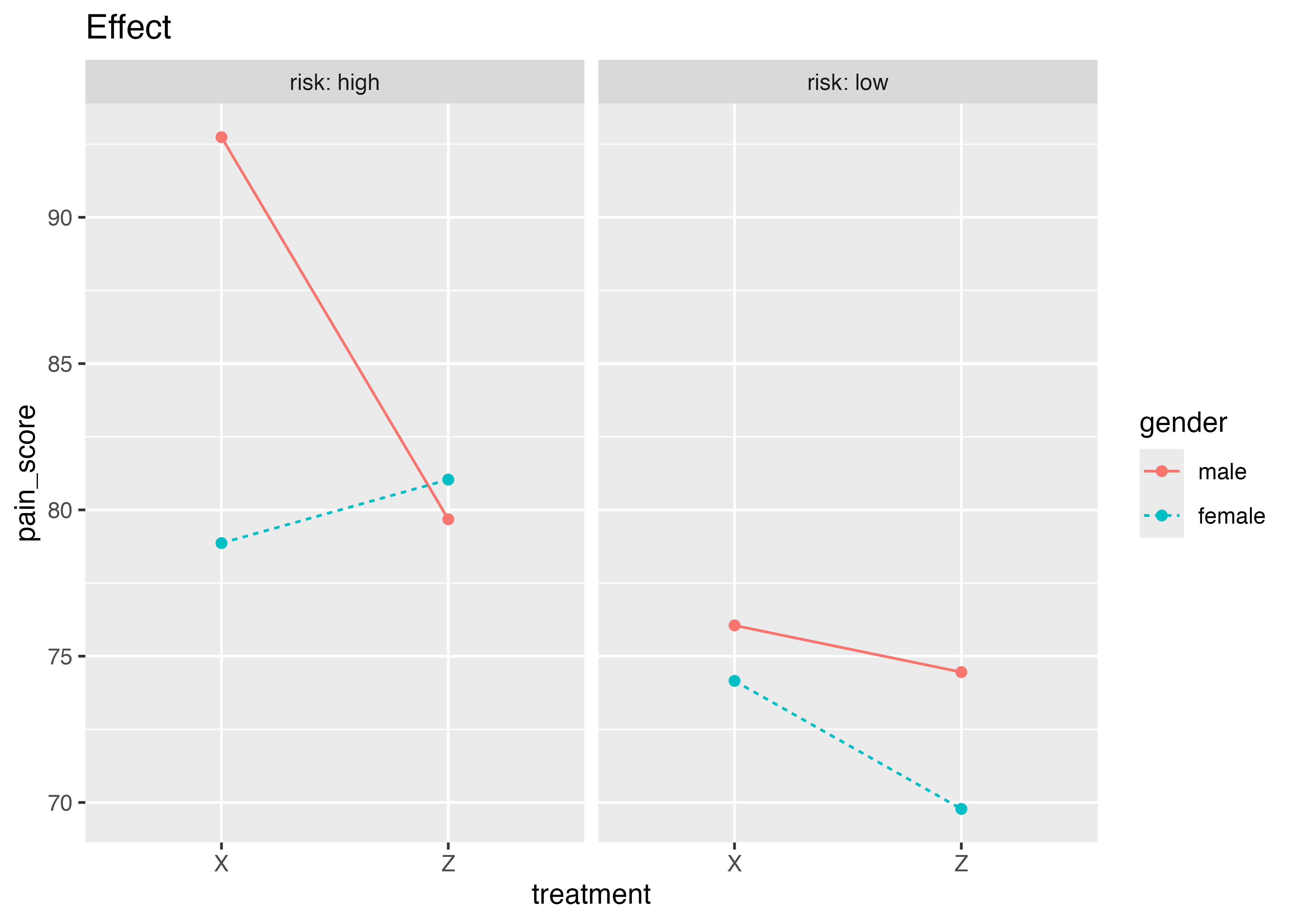
list(
m1 <- lm(pain_score ~ treatment ,data = headache),
m2 <- lm(pain_score ~ treatment + gender,data = headache),
m3 <- lm(pain_score ~ treatment * gender,data = headache),
m4 <- lm(pain_score ~ treatment + risk,data = headache),
m5 <- lm(pain_score ~ treatment * risk,data = headache),
m6 <- lm(pain_score ~ treatment + gender + risk ,data = headache),
m7 <- lm(pain_score ~ treatment * gender * risk ,data = headache)
) %>%
msummary(.,stars = TRUE,
gof_omit = "Log.Lik.|AIC|BIC|RMSE|F",
statistic = NULL
)
.svg)