Code
- 1
-
複数のパッケージを一度に読み込める
pacmanパッケージが入っていない場合は,インストールする - 2
- パッケージの読み込み
2024/07/08
調査者が何らかの操作をして行う調査・研究
.svg)
参加者をランダムに2つ(以上)のグループに割り振って,片方には新しい薬を,片方には薬ではないもの(プラセボ)を投与して,新薬の効果を検証する

同じ場所に並べた複数の植木のうち,ランダムに選んだいくつかには肥料を与え,残りには与えないことで,肥料の効果を検証する

アクセスしてくる人のうち一定割合に別のデザインの画面を表示し,クリックする先やクリック率等を比較する。(どちらのデザインの方が良いか?)



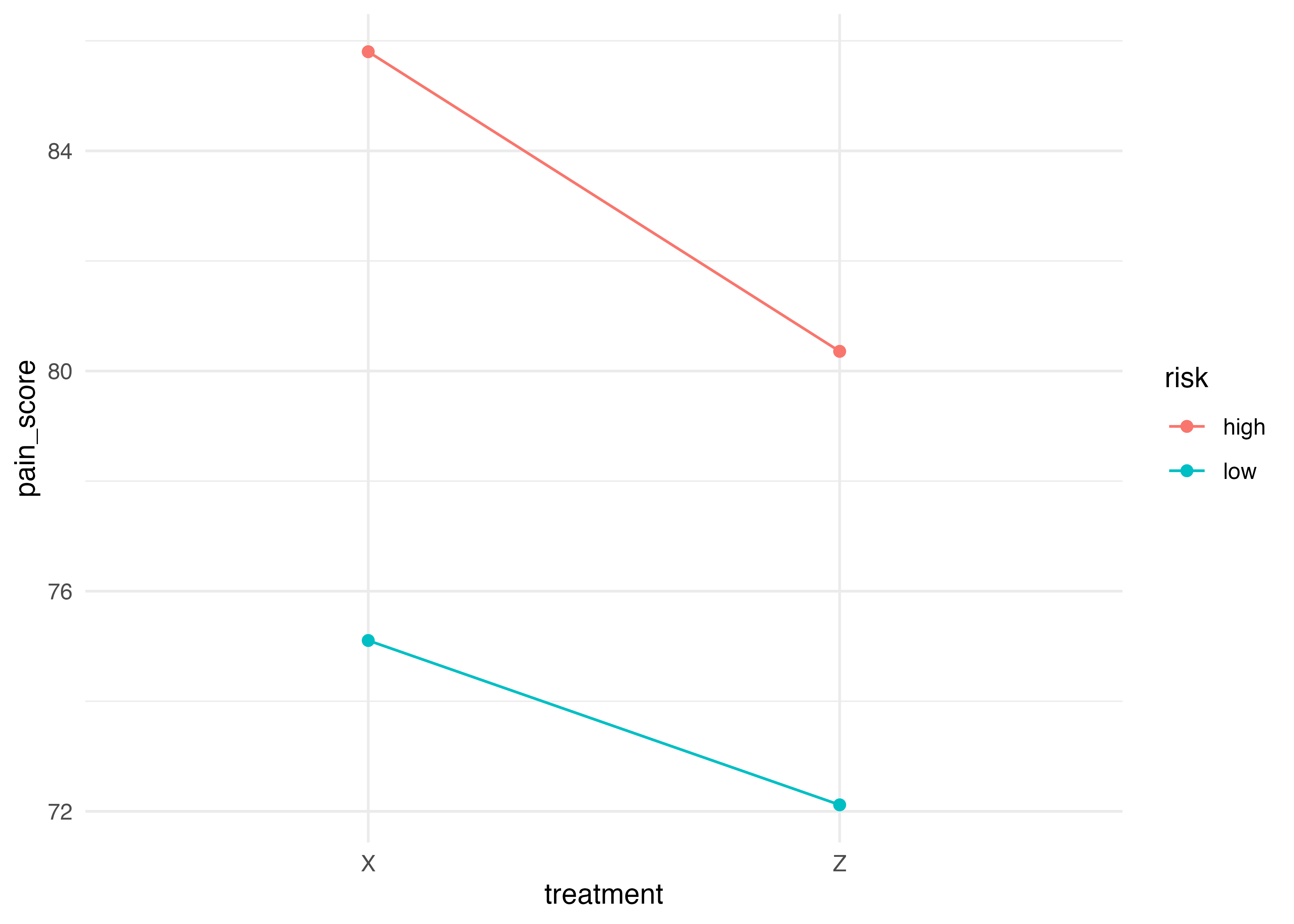
記述統計を見ると,gender(男女)とrisk(高い低い)は各条件に均等に配分されている。
| X | Z | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| mean | sd | N | Percent | mean | sd | N | Percent | ||
| pain_score | 80.45 | 8.57 | 24 | 50.00 | 76.24 | 5.88 | 24 | 50.00 | |
| gender | male | 12 | 25.00 | 12 | 25.00 | ||||
| female | 12 | 25.00 | 12 | 25.00 | |||||
| risk | high | 12 | 25.00 | 12 | 25.00 | ||||
| low | 12 | 25.00 | 12 | 25.00 | |||||
また,ggline()コマンドを使うと,効果を図に表せる
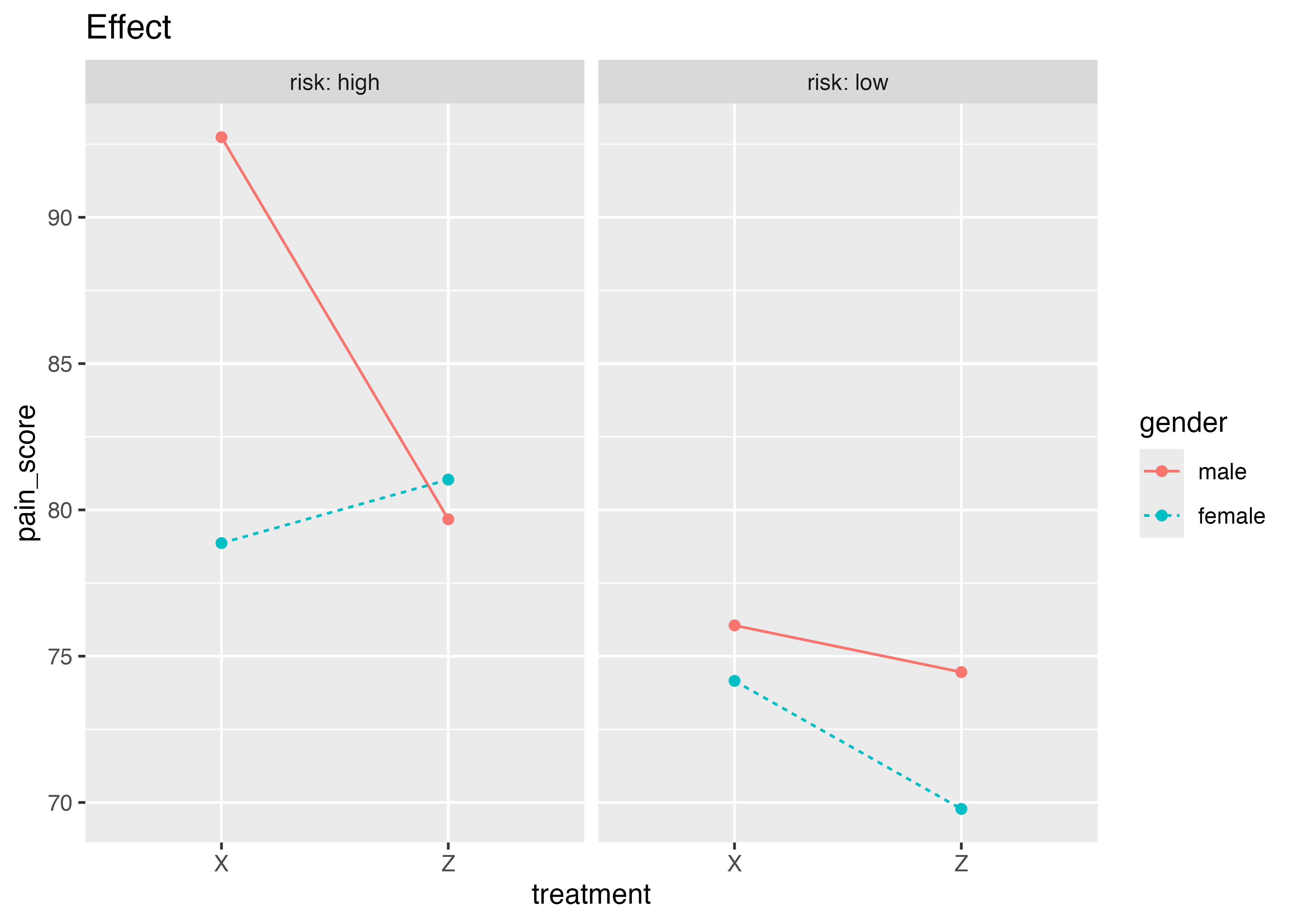
男女で効き目が違うか
Df Sum Sq Mean Sq F value Pr(>F)
treatment 1 213.2 213.21 4.475 0.0401 *
gender 1 273.4 273.36 5.738 0.0209 *
treatment:gender 1 116.2 116.20 2.439 0.1255
Residuals 44 2096.2 47.64
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1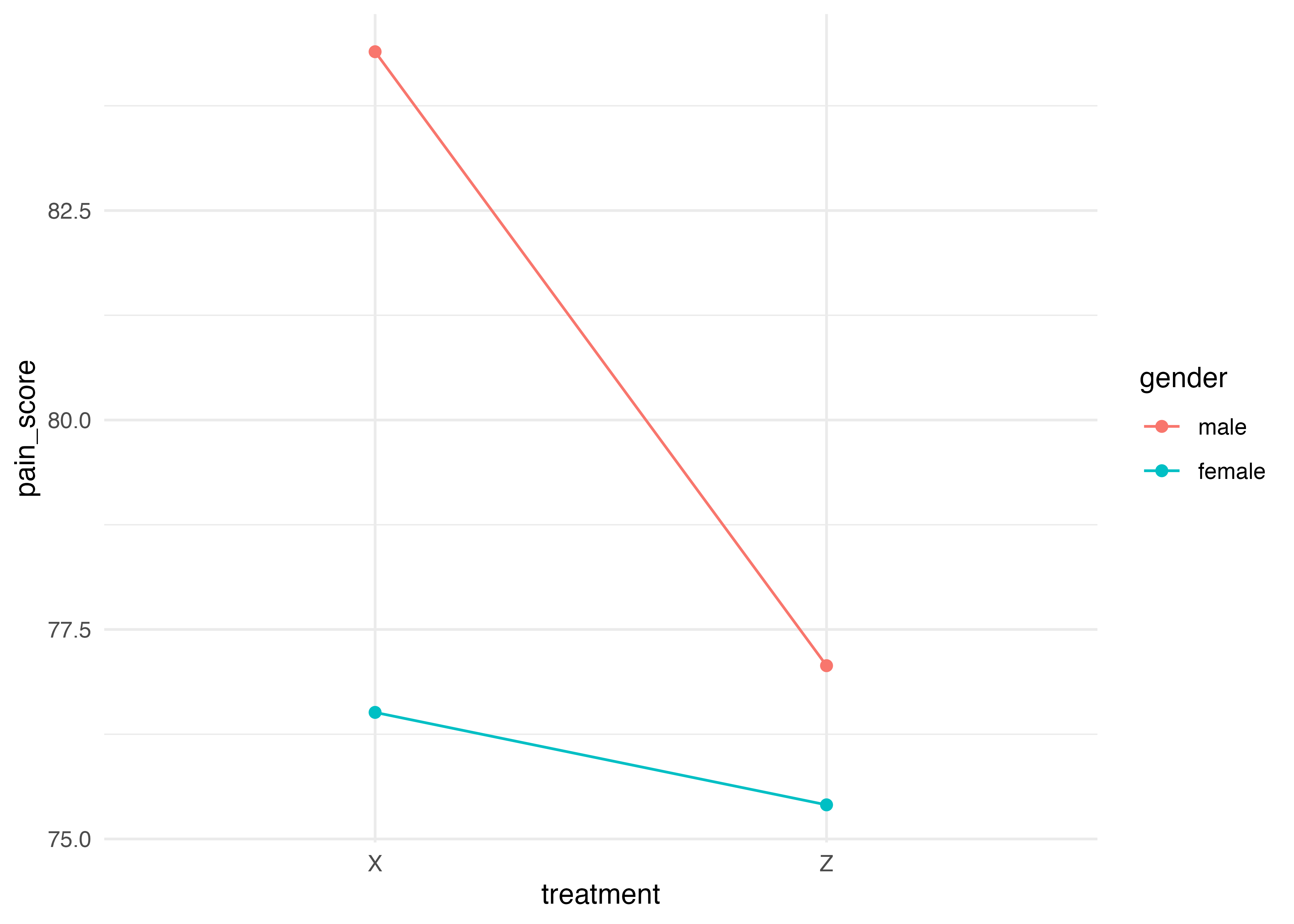
男性の方が効果が大きい。ただし,交互作用が有意とまではいかない(p < 0.123)