[1] 79204 財務データの加工,集計,及び可視化
2026/05/01

4 データの加工から可視化まで(教科書第4.4節)
4.1 dplyrのパイプ演算子の使い方


- パイプ演算子
%>%は,左側で処理されたデータフレームを,右側の関数の第一引数として受け渡す役割を果たす.
4.6 2015年度のデータを抽出して一気に可視化まで処理
- わざわざ
financial_data_2015を作らなくても,目標を達成するだけであれば,filter()関数を適用した後のデータをggplot()関数に引き渡してあげれば良い.

4.7 ヒストグラムを描画し,体裁を整える
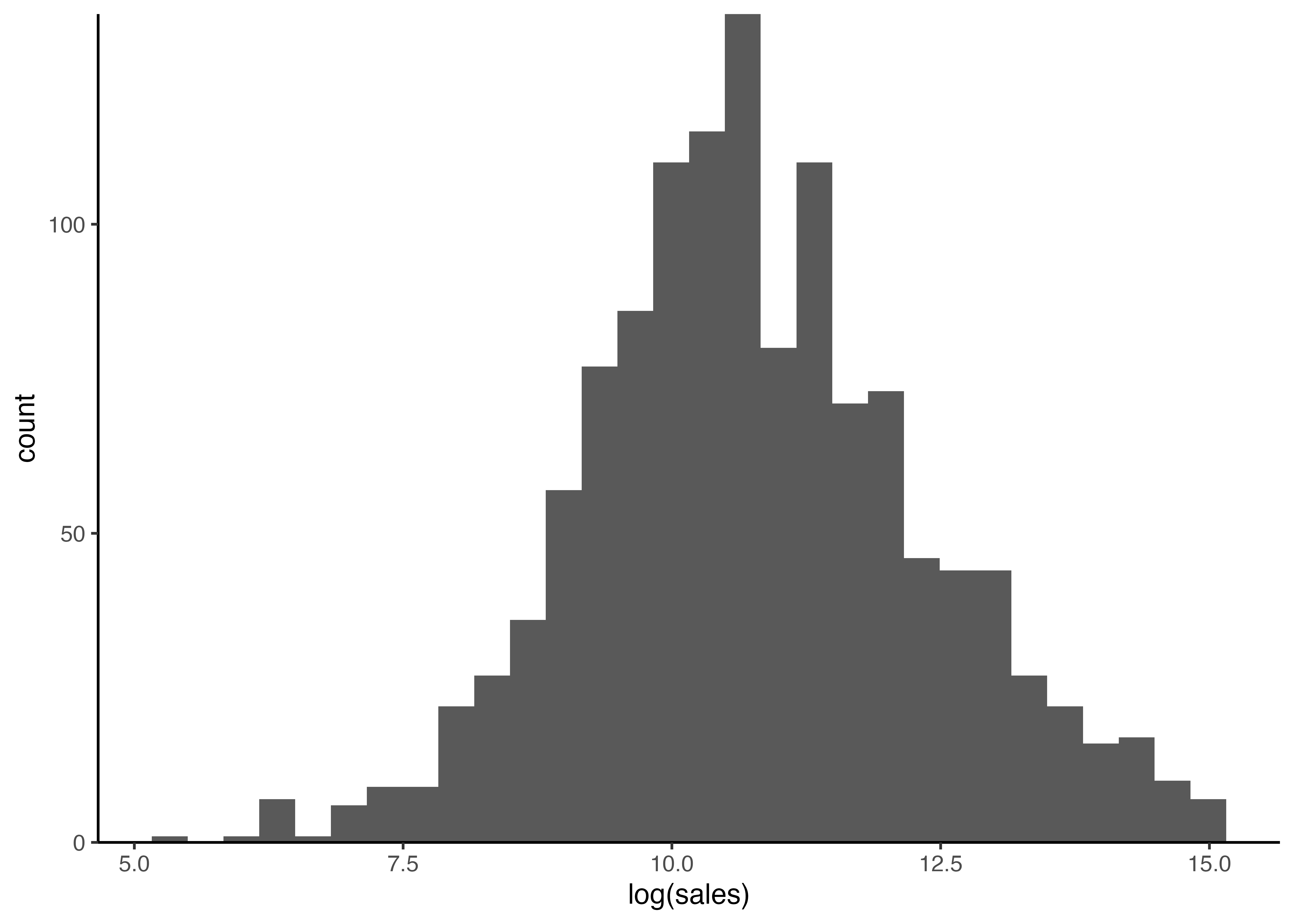
ggplot2でヒストグラムを描くには,geom_histogram()関数を用いる.aes()引数には,\(x\)軸の値としてlog(sales)を指定する.scale_y_continuous(expand = c(0,0))はヒストグラムが\(x\)軸にぴったりくっ付くよう調整する役割を果たす.
5 mutate()関数を使って新たな列の追加(教科書第4.6節)
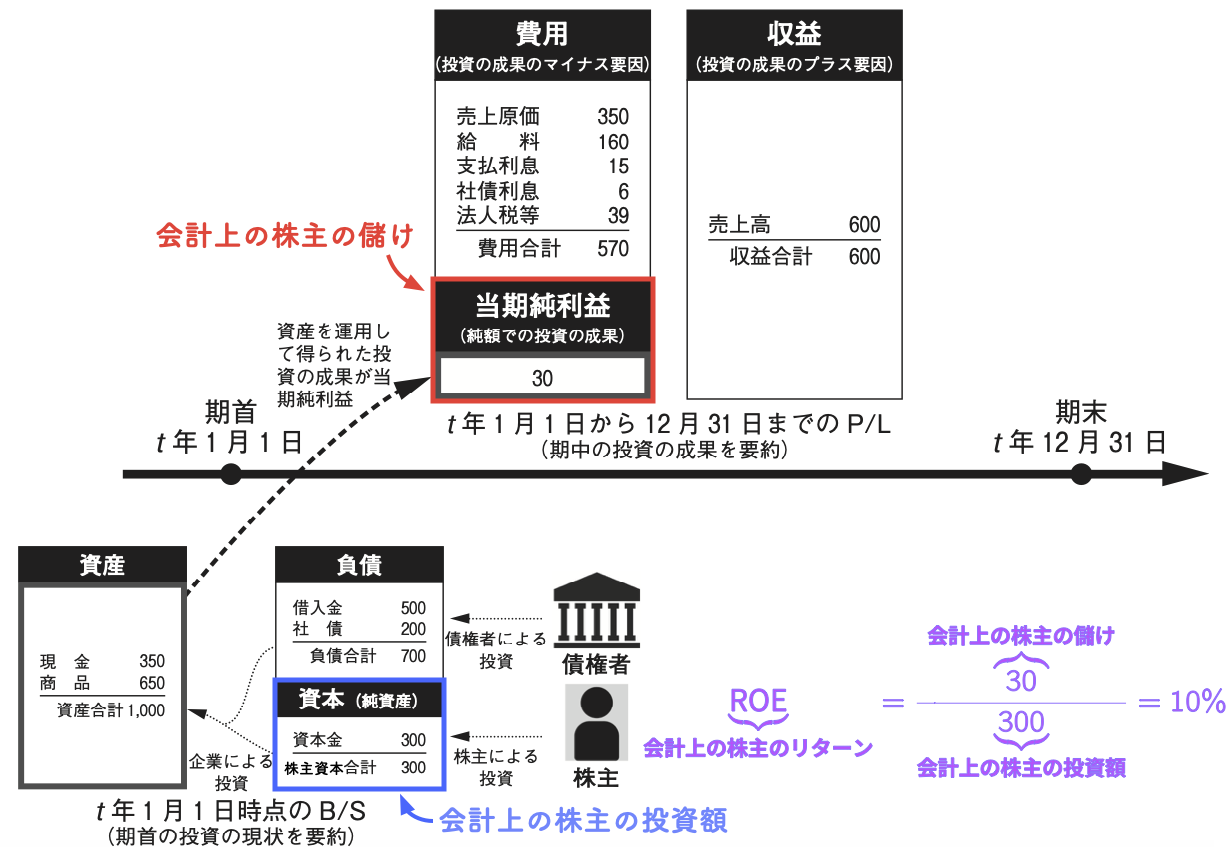
5.1 会計上の株主のリターン \(=\) ROE
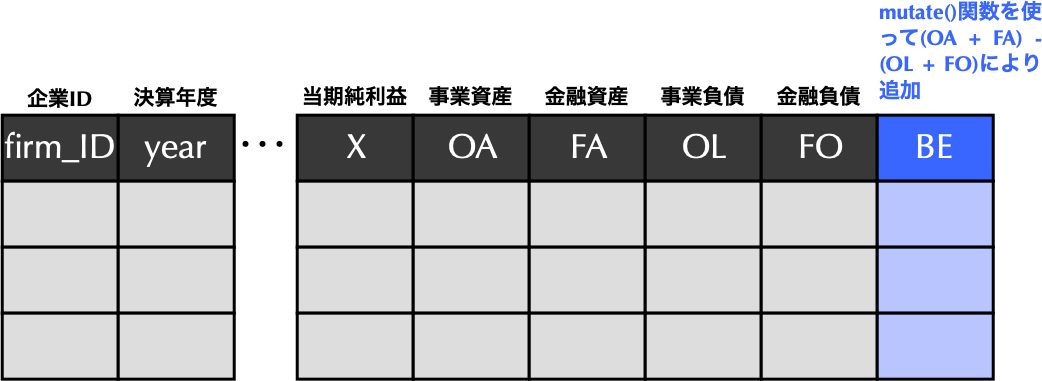
5.4 目標1: BE列の追加
dplyrでは新しい列を追加するのにmutate()関数を用いる.
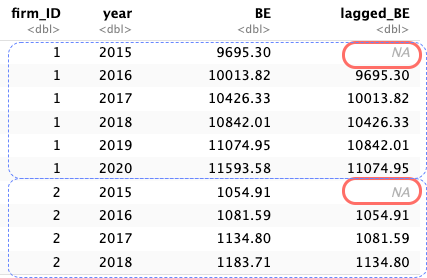
5.5 目標2: lagged_BE列の追加
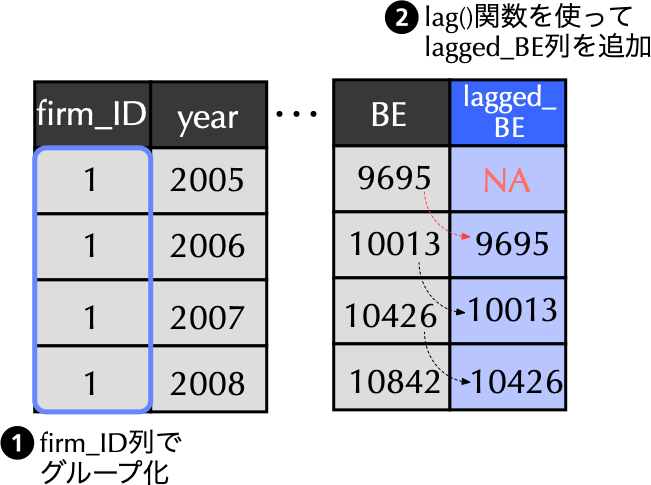
5.6 先のコードの概要
- 2行目: 以下の処理により作成されるデータフレームを
financial_dataに上書き. - 3行目:
group_by()関数を用いて,firm_IDに基づくグループ化情報を付与. - 4行目:
mutate()関数内でlag()関数を使うことで,lagged_BE列を作成し,そこに一期前のBEを格納. - 5行目:
ungroup()関数を用い,不要になったグループ化情報を消去.これを忘れると,変数にグループ化情報が付与されたままになって,その後の処理も意図せずグループごとに行われてしまうので注意しよう.
5.7 目標3: ROE列を追加
- 最後に
mutate()関数を使って,ROE列を追加しよう.
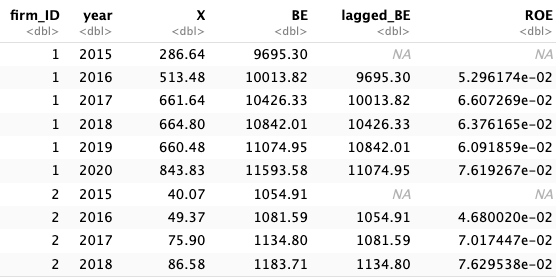
5.8 実践上はパイプ演算子を繋げて書く
5.9 目標4: ROEのヒストグラム
- 最終目標として,
ggplot2を利用し,ROEをヒストグラムにより描画しよう.
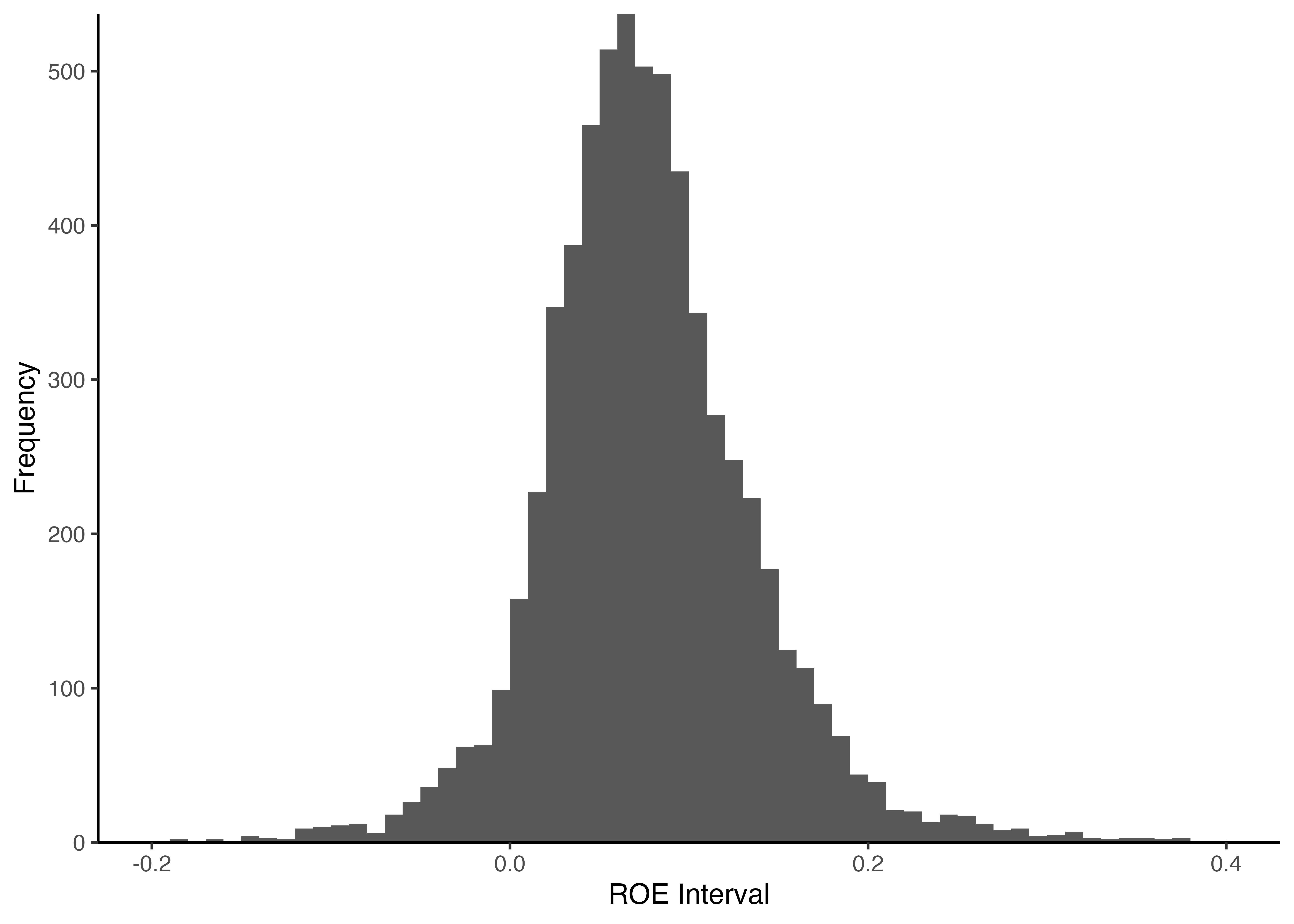
geom_histogram()関数のbreaks引数により\(x\)軸の範囲とビン幅を調整している.seq()関数は等差数列を作成するための関数であり,第一引数に始点,第二引数に終点,第三引数に等差数列の差分を取る(教科書84頁).- ここでは-0.2から0.4までの
ROEを描画することを考え,ビン幅に相当する等差数列の差分は0.01としてみよう. - なお,
breaks引数で指定した範囲外の観測値(ROEが-0.2未満や0.4超の企業)はヒストグラムに描画されない点に注意しよう.つまり,breaks引数はビン幅の設定と同時に,描画対象のデータ範囲の指定も兼ねている.
6 集計作業(教科書第4.7.1節の応用)
6.1 summarize関数の使い方
6.2 先のコードの概要
- 3行目:
tidyrに含まれるdrop_na()関数は,第二引数で指定した変数(この場合であればROE列)に欠損値が存在しない行のみを抽出して返す(教科書152頁). - 4行目:
group_by()関数を用いて,年度yearに基づいてグループ化. - 5行目: そして
summarize()関数1を用いて,各グループ(年度)ごとに平均ROEを計算し,mean_ROE列に保存する.- (注意点)
summarize()関数を適用することにより,グループ化は解除される.ただし,summarize()関数は1つのグループしか解除しないため,複数の変数でグループ化した場合は注意が必要である.以下の例で確認してみよう.
- (注意点)
# A tibble: 50 × 3
# Groups: year [5]
year industry_ID mean_ROE
<dbl> <fct> <dbl>
1 2016 1 0.0786
2 2016 2 0.107
3 2016 3 0.0771
4 2016 4 0.0723
5 2016 5 0.0908
6 2016 6 0.0812
7 2016 7 0.0555
8 2016 8 0.0874
9 2016 9 0.0863
10 2016 10 0.0646
# ℹ 40 more rows- 上のコードでは
.groups引数を指定していないため,yearによるグループ化が残ったままになっている.これを防ぐには,以下のように.groups = "drop"を指定し,明示的にグループ化を解除する.
# A tibble: 50 × 3
year industry_ID mean_ROE
<dbl> <fct> <dbl>
1 2016 1 0.0786
2 2016 2 0.107
3 2016 3 0.0771
4 2016 4 0.0723
5 2016 5 0.0908
6 2016 6 0.0812
7 2016 7 0.0555
8 2016 8 0.0874
9 2016 9 0.0863
10 2016 10 0.0646
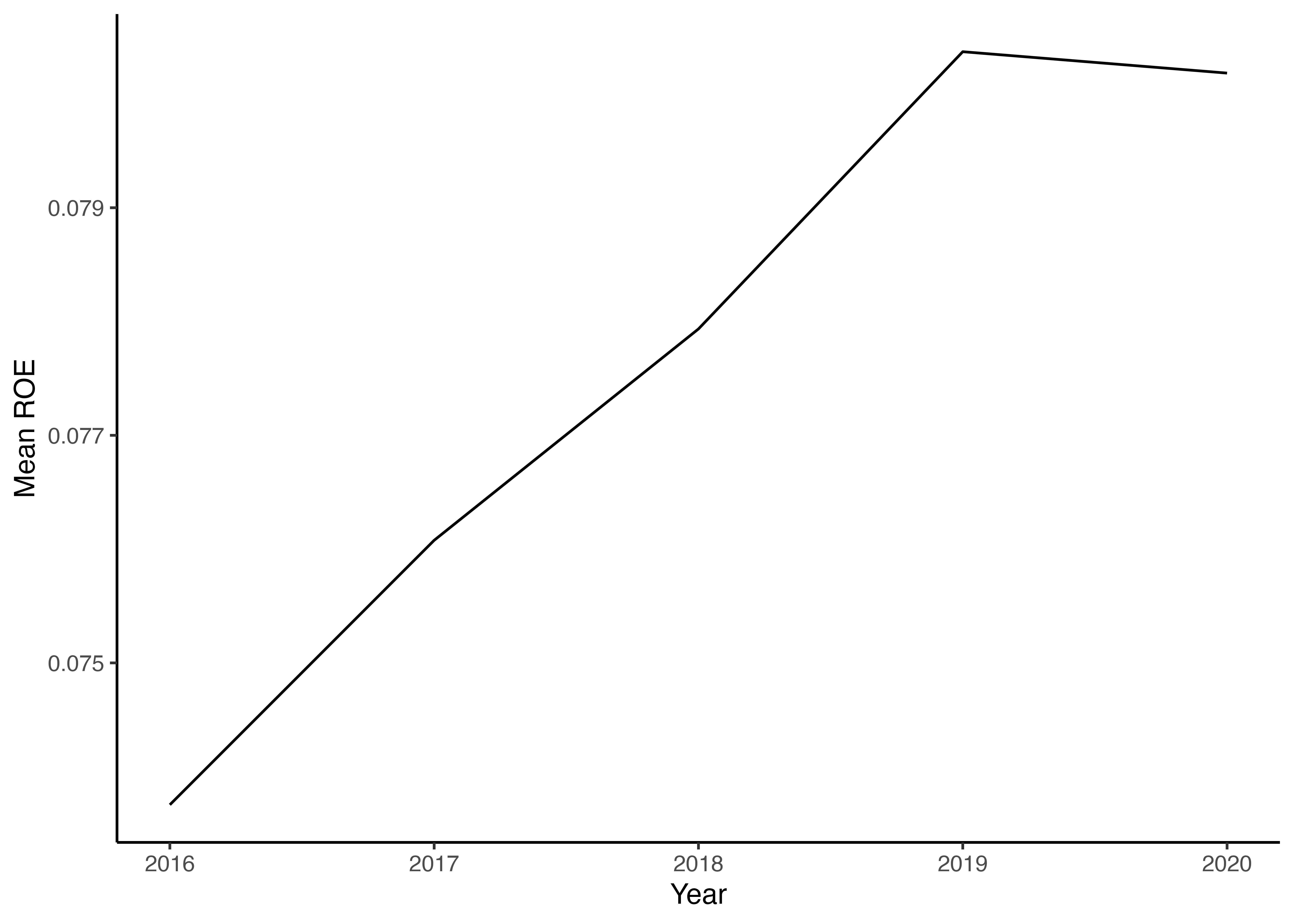
# ℹ 40 more rows6.3 平均値計算から可視化までを一度に処理
# 年度ごとにROEの平均値を求め,折れ線グラフにより描画
financial_data %>%
drop_na(ROE) %>%
group_by(year) %>% # 年でグループ化
summarize(mean_ROE = mean(ROE)) %>% # 各年のROEの平均値を計算
ggplot() + # ggplot()関数にデータを引き渡す
geom_line(aes(x = year, y = mean_ROE)) +
# 折れ線グラフを描くにはgeom_line()関数を用いる
labs(x = "Year", y = "Mean ROE") + # 両軸のラベルを設定
theme_classic() # グラフ全体の体裁を設定