---
title: "2 Rのセットアップ"
subtitle: "シミュレーション・データの準備とR言語の基本的な機能"
date: 2026/04/17
format:
html: default
revealjs:
output-file: 2_setup_slide.html
---
## Accounting 101(教科書第1.1節) {data-name="Accounting 101"}
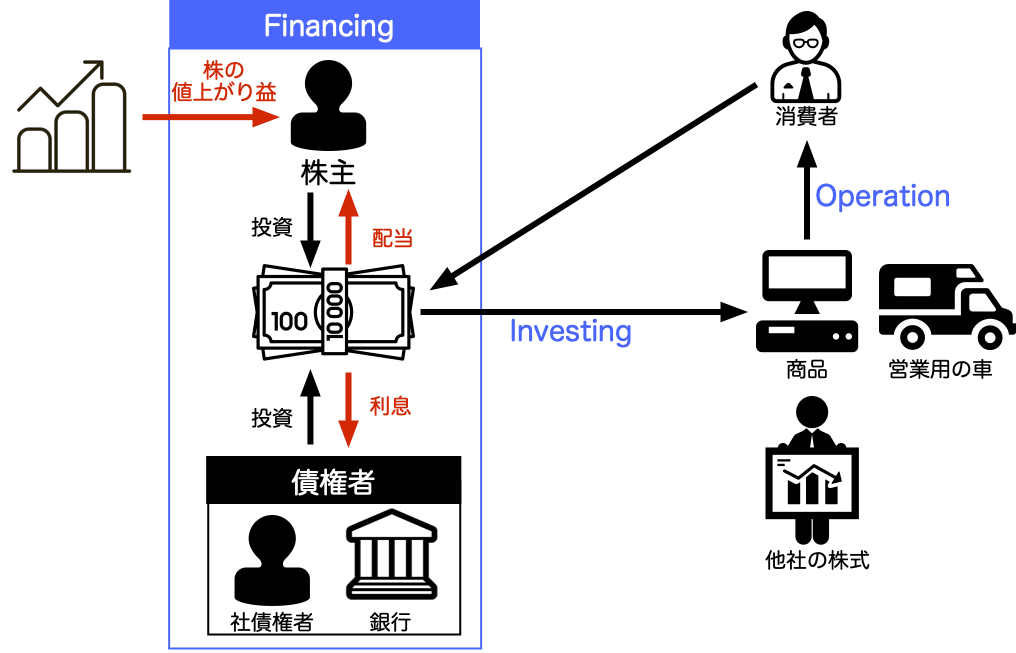
### 企業が営む経済活動
- 資金調達活動 (Financing)
- 資金投下(投資)活動 (Investing)
- 営業活動 (Operation)
<p align="center" style="font-size: 20px;">
<strong><u>単純な小売業を例に</u></strong>
</p>
{width="80%"}
------------------------------------------------------------------------
### 経済活動を要約するツール $=$ 財務諸表
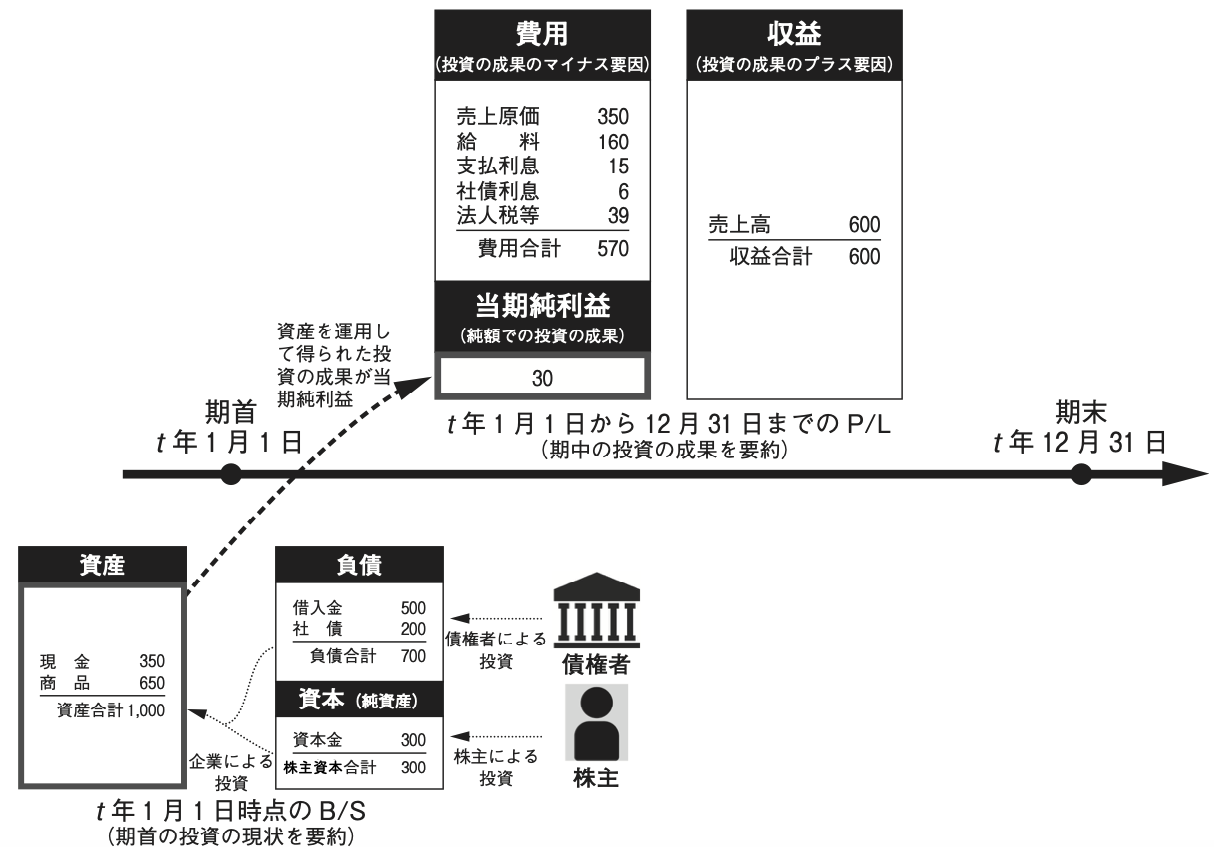
------------------------------------------------------------------------
## 上場企業のディスクロージャー制度(教科書第4.1節) {data-name="ディスクロージャー制度"}
### 法定開示と適時開示
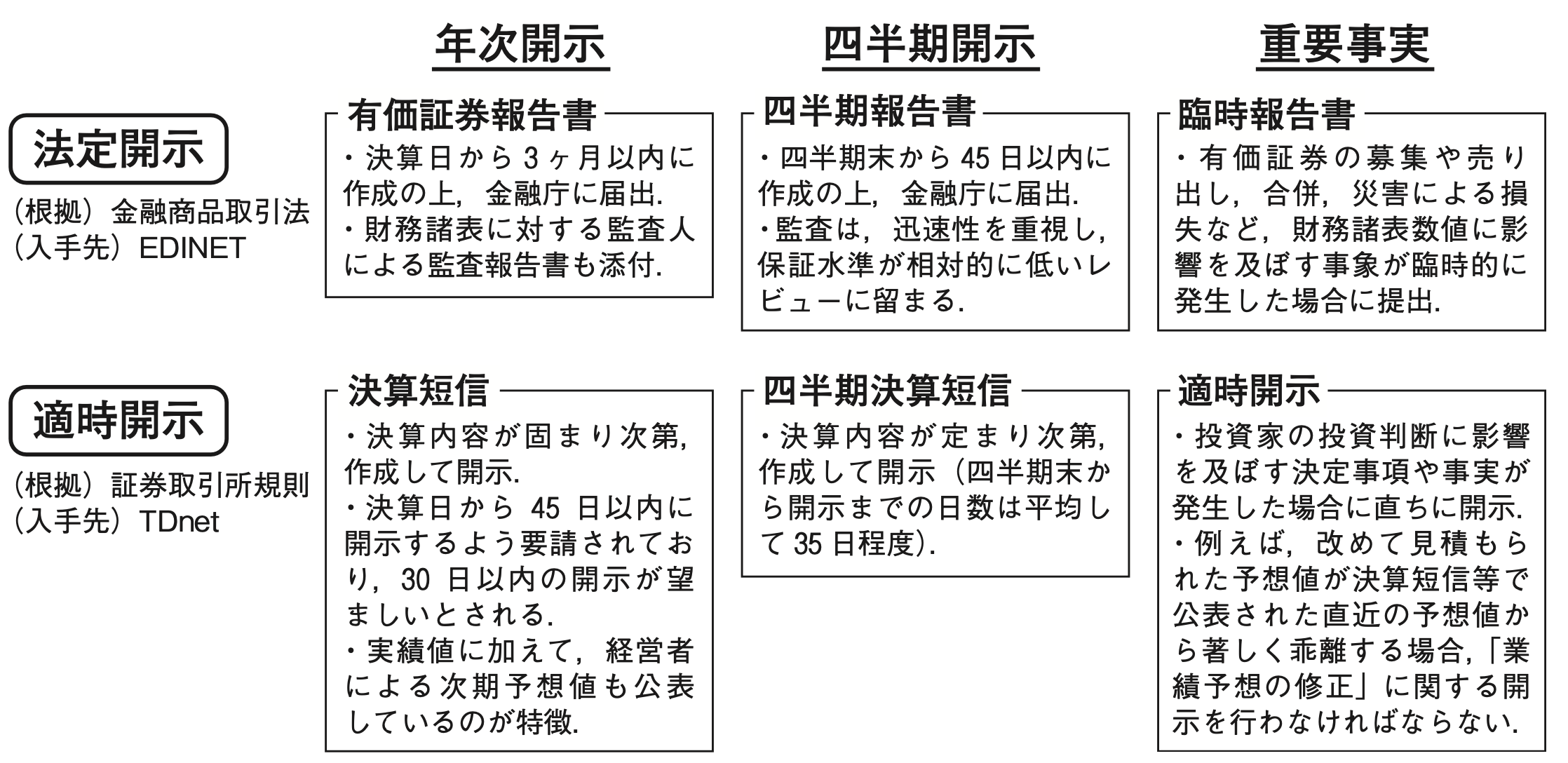
------------------------------------------------------------------------
### 四半期財務報告制度の制度改革
- 2023年11月の金商法改正により,四半期財務報告制度が変革したことに伴い,2024年4月以降開始の1Q/3Qから四半期報告書は順次廃止.
- 1Q/3Q決算短信について,[**監査人によるレビューは原則任意**]{style="color: blue"}.
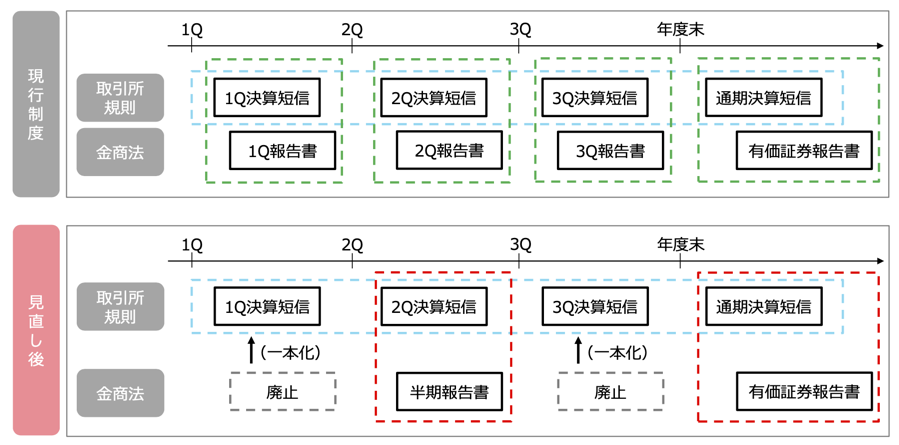
(引用)東京証券取引所上場部「四半期開示の見直しに関する実務の方針」2023年11月22日.
------------------------------------------------------------------------
### 事前の予想に反して,実際のレビュー実態は…
:::{.callout-warning icon="false"}
#### 事前の予想の代表例— 企業会計審議会第54 回監査部会【白川委員】
現実問題として,おそらくプライム市場に上場される名立たる企業は,レビューをつけられるのではないかと勝手ながら想像する(後略)
:::

(引用)日本経済新聞,2024年9月5日付朝刊.
------------------------------------------------------------------------
### EdinetとTDnetから情報を入手してみよう!
::: {.callout-note icon="false"}
#### Exercise 1
- EDINETより任天堂の2025年3月期 (2024/04/01-2025/03/31)の有価証券報告書をダウンロードしてみよう.
- [任天堂の公式サイト](https://www.nintendo.com/jp/)から2025年3月期の決算短信を探し,ダウンロードしてみよう.
- 有価証券報告書と決算短信の相違点を考えてみよう.
:::
------------------------------------------------------------------------
## コードとシミュレーション・データの準備 {data-name="本講義の準備"}
### コードのダウンロード
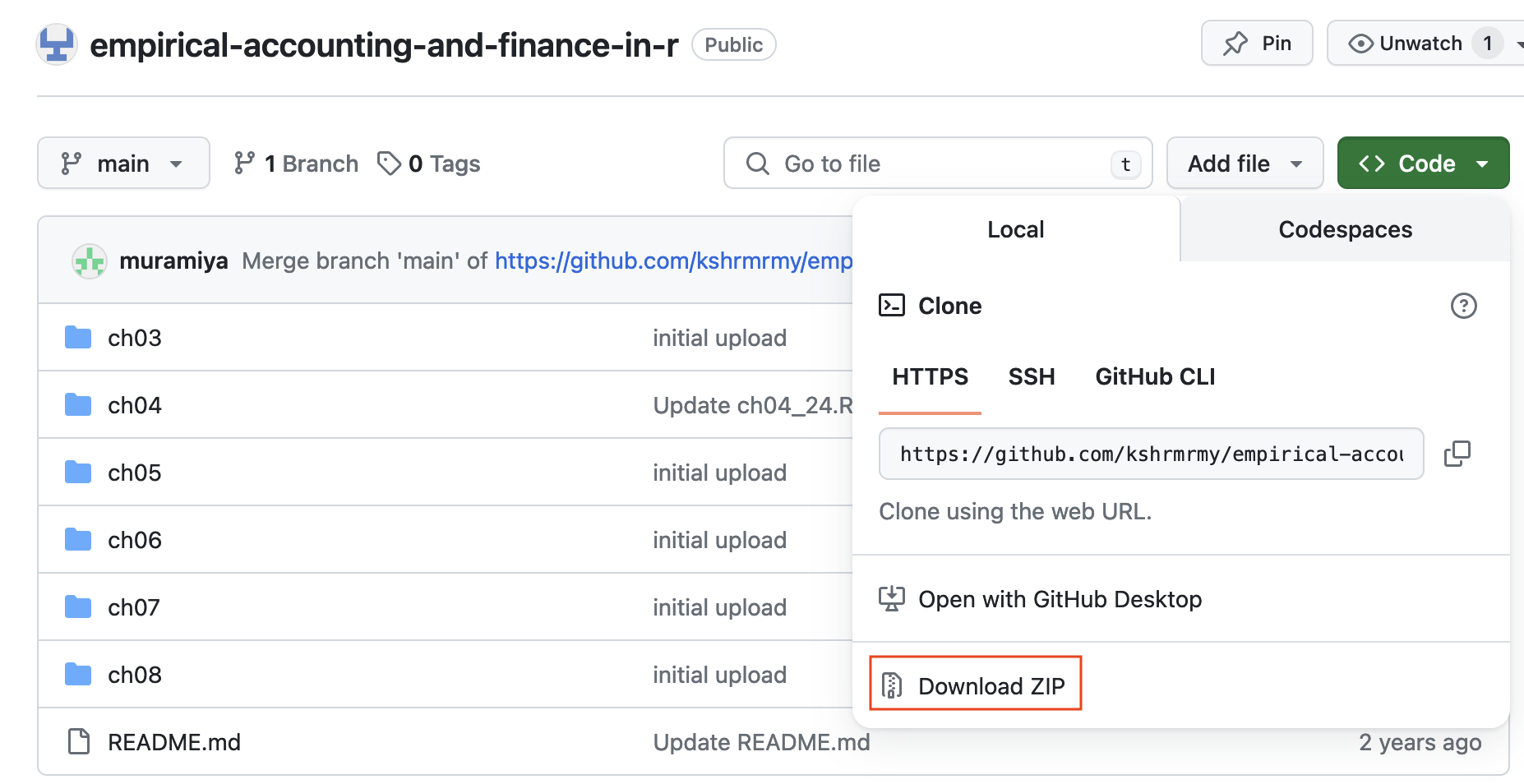
**Step 1.** [本書のサポートサイトのS3](https://www2.econ.osaka-u.ac.jp/~eaafinr/sect-3.html)にアクセス.
**Step 2.** Zipファイルをダウンロード. 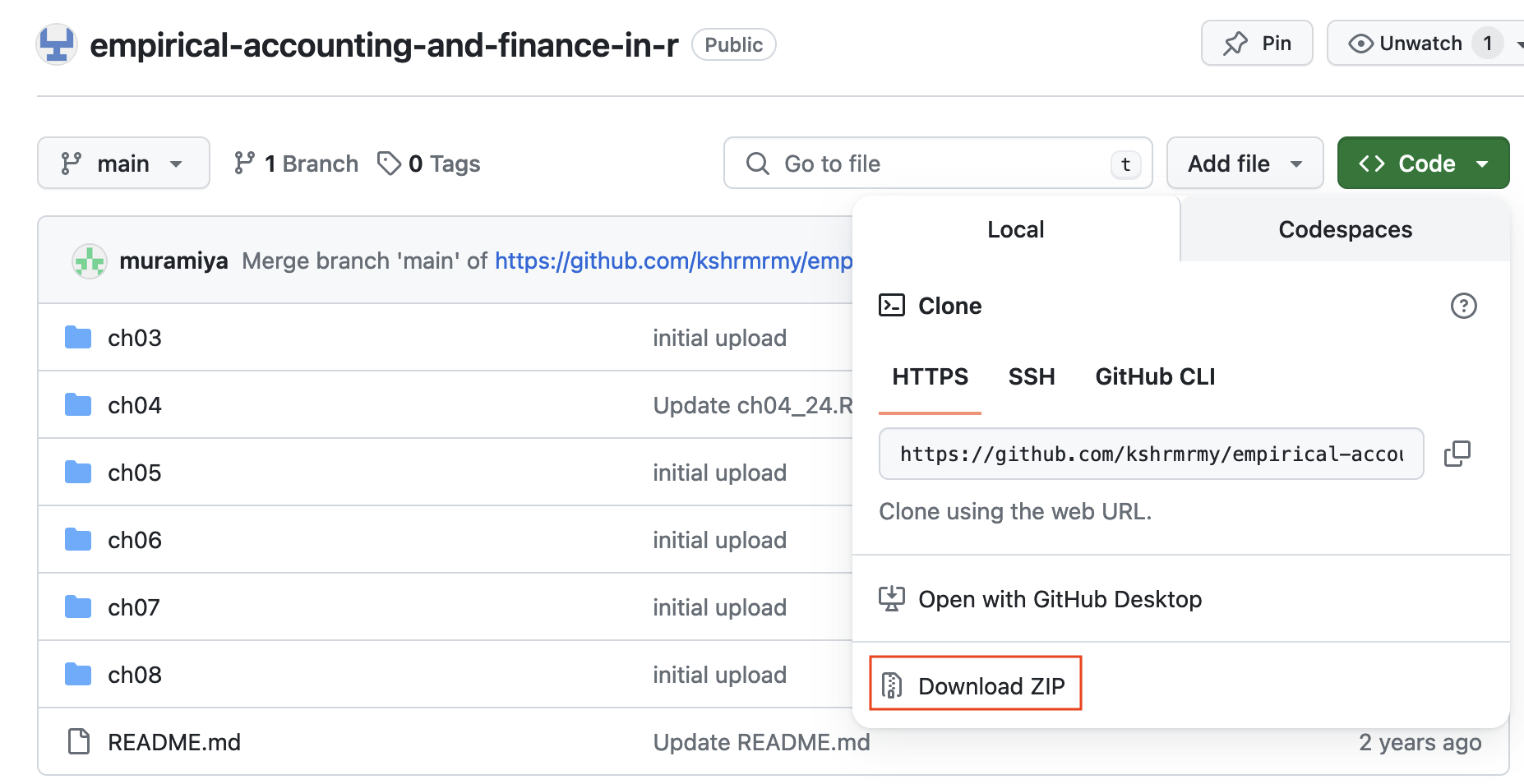
------------------------------------------------------------------------
### Posit Cloudへのコードのアップロード
::: larger
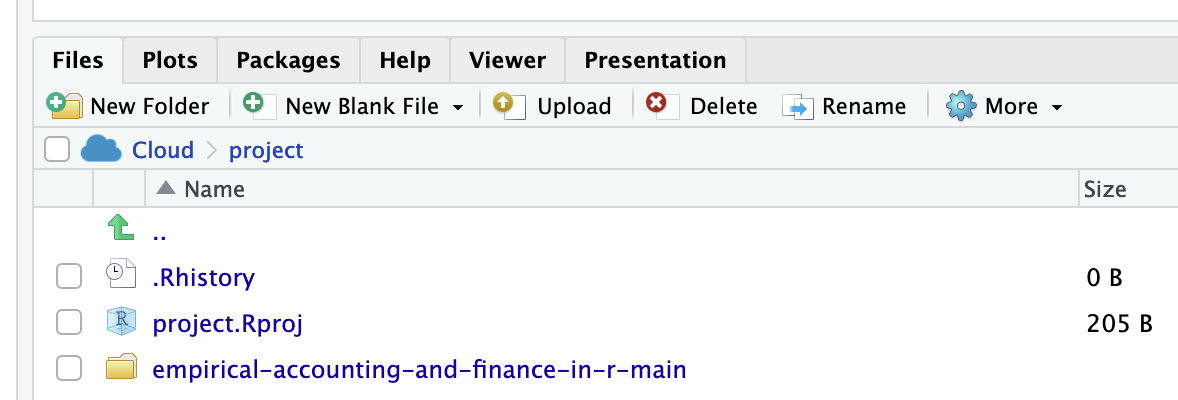
**Step 3.** Posit CloudにダウンロードしたZipファイルをアップロード.
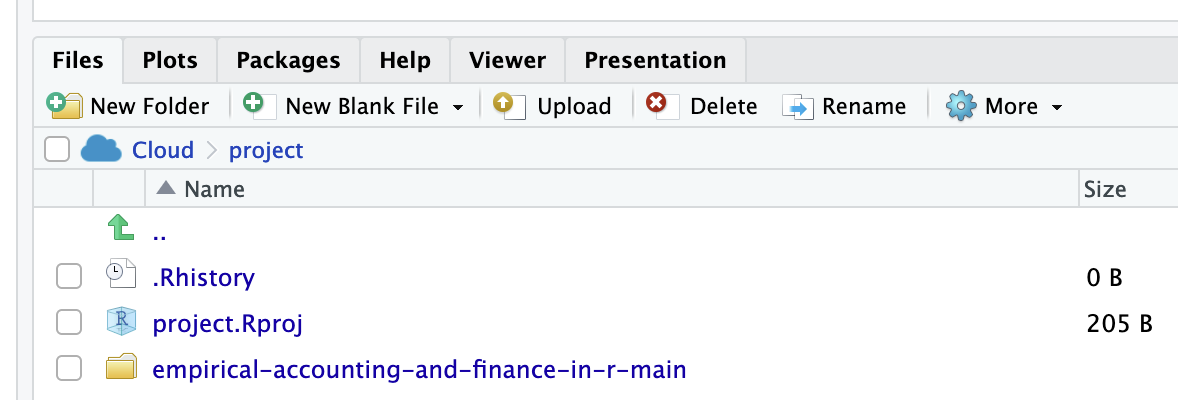
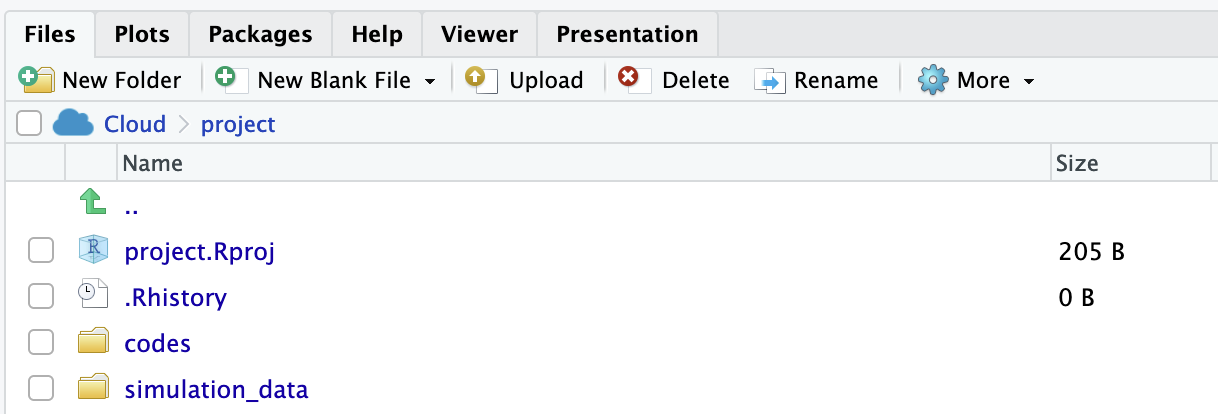
**Step 4.** `empirical-accounting-and-finance-in-r-main`フォルダを選択し,Renameにより`codes`フォルダへと識別可能性の観点から名前変更.
:::
------------------------------------------------------------------------
### シミュレーション・データのダウンロード
**Step 1.** [本書のサポートサイトのS2](https://www2.econ.osaka-u.ac.jp/~eaafinr/sect-2.html)にアクセス.
**Step 2.** Zipファイルをダウンロード. {width="75%"}
**Step 3.** 教科書「まえがき」ivページに記載のパスワードを入力して解凍.
**Step 4.** 解凍されたファイルを再度圧縮し,改めてZipファイルを作成.
------------------------------------------------------------------------
### シミュレーション・データのアップロード
**Step 5.** Posit Cloudに先の手順により作成されたZipファイルをアップロード.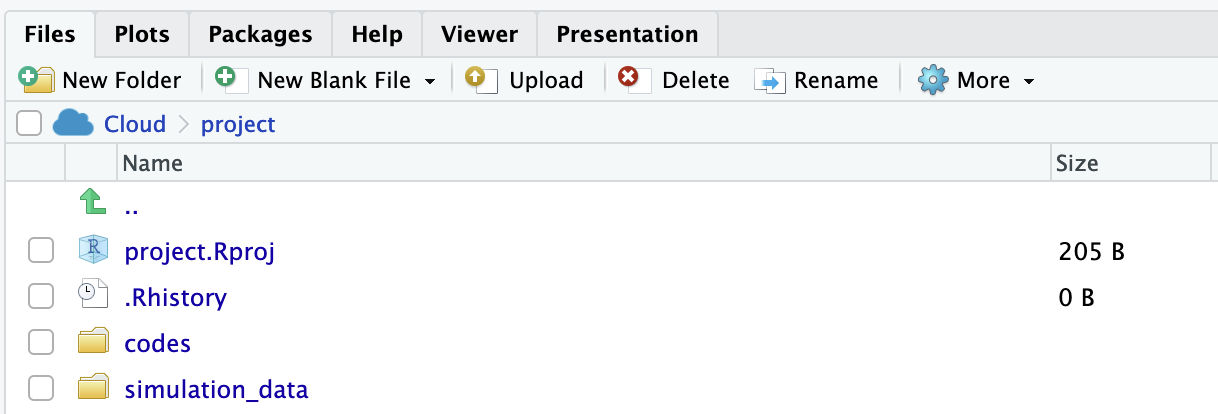
------------------------------------------------------------------------
## R言語入門 {data-name="R言語入門"}
### 変数という考え方
- [**変数**]{style="color: red"}とは,データを読み書きする「名前付き」の記憶域 (storage)のことで,データを一定期間記憶しておいてくれるので,プログラムによりいつでも参照(または更新)することができる.例えば,3.14というスカラーを`my_pi`という変数として記憶したい場合は,以下のように書けば良い.
```{r}
my_pi <- 3.14
```
::: {.callout-warning}
#### 組み込み変数の上書きに注意
Rには`pi`(= 3.141593...),`T`,`F`,`Inf`(無限大)など,あらかじめ定義された組み込み変数が存在する.`pi <- 3.14`のように同名の変数に代入すると組み込みの値が上書きされてしまい,思わぬバグの原因となる.変数名を付ける際は,`my_pi`のようにこれらと重ならない名前を選ぶようにしよう.
:::
- 変数に[**何かを代入するときは`=`演算子は使わず,`<-`演算子を使う**]{style="color: blue"}のがポイント!R言語では`=`でも代入は動作するが,関数の引数指定(例: `seq(from = 1, to = 10)`)と混同しやすいため,代入には`<-`を使うのがRコミュニティの慣習である.演算子を素早く出したい人は,以下のショートカットを利用すれば良い.
- macOS: Option(⌥) + -
- Windows / Linux: Alt + -
- ひとたび`my_pi`を定義すれば,例えば,半径4の円の面積`S`を求めるとき,`my_pi`を使って計算することができる.
```{r}
S <- my_pi * 4^2
print(S) # Sの中身を表示
```
------------------------------------------------------------------------
### R言語の作法
::: callout-tip
#### 可読性の高いコードを目指して
Rは「半角スペース」を無視するので,あってもなくてもコード上は一緒.ただし,可読性の観点から様々な作法が存在する.[GoogleのRユーザー・コミュニティ](https://google.github.io/styleguide/Rguide.html)では,例えば,二項演算子 (binary operators)の前後には半角スペースを挿入することが徹底されている.
```{r}
# 良い例
S <- my_pi * 4^2
# 悪い例
S<-my_pi*4^2
```
:::
- もちろんスカラー以外にも,ベクトルや行列などの変数も作成することができる.例えば,$(1,2,6)$という3次元のベクトルを`x`として定義する場合は,以下の通りである.
```{r}
x <- c(1, 2, 6)
```
- `c()`関数はベクトルを作成する関数であり,`c`はconcatenate(連結する)の略である.
------------------------------------------------------------------------
### 変数の命名規則
- 変数の名前は自由に付けることができる.このようなプログラマが自由に付けて良い名前を[**識別子**]{style="color: red"} (identifier)という.
識別子に使える文字
: - アルファベット,数字,`_`(アンダースコア),`.`(ピリオド)
具体例
: - `sales_growth`(売上高増加率), `FY2020.EARNINGS`(2020年度の利益)
------------------------------------------------------------------------
### 変数命名に関する注意点
- 数字からははじまる変数は付けられない (ダメな例: `2020_earnings`, `001Variable`)
- 大文字と小文字は区別されるので,`Sales`と`sales`は別々の変数として認識される.
::: callout-tip
#### プログラミング全般での名前の付け方の作法
- キャメルケース (camelCase)・・・ `salesGrowth`, `annualStockData`
- パスカルケース (PascalCase)・・・ `SalesGrowth`, `AnnualStockData`
- [**スネークケース (snake_case)**]{style="color: red"}・・・ `sales_growth`, `annual_stock_data`
- ケバブケース (kebab-case)・・・ `sales-growth`, `annual-stock-data`
:::
------------------------------------------------------------------------
### 問題をやってみよう! {#Exercise2}
::: {.callout-note icon="false"}
#### Exercise 2
1. 20点,35点,40点,70点,95点という5人の成績を示したテストの点数 (Test Score)を表すベクトルを作成してみよう.なお,命名規則はスネークケースによること(例: `test_score`).
2. 平均点を求めてみよう.
- **(ヒント)** `mean()`関数の第一引数に先に作成したTest Scoreのベクトルを代入すればオッケー!
3. 学生の人数を`N`とする新たな変数を作成しよう.
- **(ヒント)** `mean()`関数は平均値を返すが,同様に,`length()`関数はベクトルの次元を返す.
:::
------------------------------------------------------------------------
## 引数とは?(教科書第3.1節) {data-name="引数"}
### 0.1から0.2まで0.01刻みの`R`ベクトルを作ってみよう! {#ここ}
```{r}
R <- seq(0.1, 0.2, 0.01)
```
{width="75%"}
::: callout-tip
#### 引数 (arguments)とは
関数に受け渡す値を指し,例えば三つの引数を取る関数 `example_function(A, B, C)`に関して,`A`を第一引数,`B`を第二引数,`C`を第三引数と呼ぶ.関数ごとに引数の数や指定の仕方は異なる.
:::
- `R <- seq(0.1, 0.2, 0.01)`は,`R <- seq(from = 0.1, to = 0.2, by = 0.01)`の省略形である.
- R言語の関数には[**位置指定**]{style="color: red"}という概念があり,例えば`seq()` 関数の場合,引数名が省略されていると,最初の三つの引数はそれぞれ等差数列の始点 (`from`),終点 (`to`),差分 (`by`)と解釈し,実行してくれる.
------------------------------------------------------------------------
### 関数名や引数は憶えないといけない?(教科書コラム3.3)
- 現実的には,自分が使う頻度が高い関数に関しては,使い方を積極的に覚えるようにし,そうでない関数はその都度インターネット検索などで使い方を確認するのが良いだろう.
- それぞれの関数ごとに,引数の指定の仕方や結果の形態が異なっており,それらは全て [RDocumentation](https://www.rdocumentation.org/)というサイトに一覧で載っている.
- 加えて,インターネット上には,個人ブログなどの数多くの有益な情報源が存在しているので,それらの調べ方もRを使いこなす上で重要なスキルである.
- 最後に,コンソール上で[`help(関数名)`]{style="color: red"}あるいは[`?関数名`]{style="color: red"}と打つことで,関数のヘルプを表示できることも知っておこう.
```{r}
help(seq)
?seq
```
------------------------------------------------------------------------
### 要素へのアクセス {#要素へのアクセス}

- 例えば`R[2]`とすれば,2番目の要素が参照できる.要素の指定は変数を用いて行うこともでき,`i <- 2`と定義しておけば,`R[i]`は2番目の要素を表す.
```{r}
# 第2要素へのアクセス方法1
R[2]
# 第2要素へのアクセス方法2
i <- 2 # iを2として定義
R[i] # ベクトルRの第i要素へのアクセス
```
------------------------------------------------------------------------
### 連続した要素へのアクセス
- ベクトルの中から連続する一部分を取り出すためにはコロンを使う.例えば,2番目から5番目の要素のみを取り出す場合,`R[2:5]`と入力すれば良い.一般にコロン (`:`)は**公差が1の等差数列**を作成するために用いられ,`2:5`は`c(2, 3, 4, 5)`という4次元ベクトルを作成する.
```{r}
# 第2-第5要素へのアクセス
R[2:5]
```
- もし2番目から最後までの要素を取り出したければ,`R[2:length(R)]`と入力する.`length()`関数は,[Exercise 2](#Exercise2)で学習したように,ベクトルの次元を返すので,ここでは`length(R)`は`11`となる.
```{r}
# 第2-第11要素へのアクセス
R[2:length(R)] # length(R)はRの次元11を返す
```
------------------------------------------------------------------------
## 行列・リスト・データフレーム(教科書コラム3.4) {data-name="行列・リスト・データフレーム"}
### 行列
- ここまではスカラーとベクトルが登場した.Rでは,[**行列**]{style="color: red"} (matrix)も扱うことができる.
::::: columns
::: {.column width="50%"}
{width="95%"}
:::
::: {.column width="50%"}
```{r}
# 3×2行列の作成
x <- matrix(1:6, nrow = 3, ncol = 2)
print(x)
```
:::
:::::
::::: columns
::: {.column width="50%"}
{width="95%"}
:::
::: {.column width="50%"}
```{r}
# 文字を要素とする行列の作成
y <- matrix(c("a", "b", "c", "d"), nrow = 2, ncol = 2)
print(y)
```
:::
:::::
------------------------------------------------------------------------
### リスト
::: goal
- [**リスト**]{style="color: red"} (list)とは,任意のオブジェクトや変数をまとめたもの.
:::
::::: columns
::: {.column width="60%"}
{width="95%"}
:::
::: {.column width="40%"}
```{r}
# リストの作成
x <- list(10:11, "ABC")
print(x[[1]])
print(x[[1]][2])
print(x[[2]])
```
:::
:::::
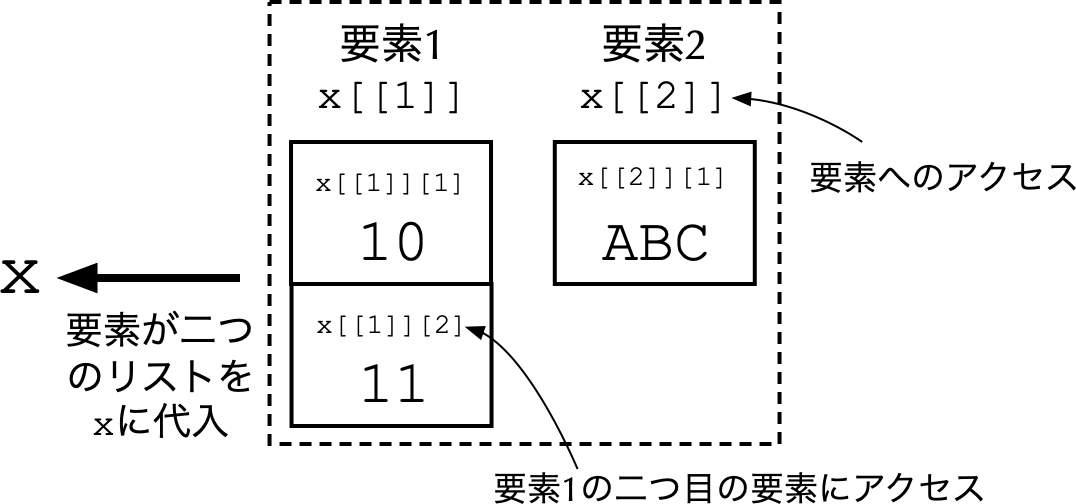
- このリストは,`(10, 11)`という2次元ベクトルと,`ABC`という文字列をそれぞれの要素として含んでいる.リストは要素の参照方法が通常のベクトルと異なり,[**カッコを二重**]{style="color: blue"}にする.
- 例えば,`x`の1番目の要素を参照するには,`x[[1]]`と指定.上の例だと,`x[[1]]`は`(10, 11)`というベクトルであるため,そのうち`11`を参照したければ,`x[[1]][2]`と指定.
------------------------------------------------------------------------
### データフレーム
::: goal
- [**データフレーム**]{style="color: red"} (data frame)とは,異なるサンプルのデータを表形式にして一つのデータとして扱うためのオブジェクトである.
- 外観は行列と同じ2次元配列であるが,各行・列がラベルを持ち,それらがどのサンプルの何に関するデータなのかを表す.
:::
::::: columns
::: {.column width="50%"}
{width="95%"}
:::
::: {.column width="50%"}
```{r}
# データフレームの作成
ID <- c(1001, 1002, 1003)
name <- c("Firm A", "Firm B", "Firm C")
ROE <- c(0.08, 0.12, 0.15)
x <- data.frame(ID, name, ROE)
print(x)
```
:::
:::::
::: {.callout-tip}
#### `tibble`:データフレームの改良版
データフレームには,列名の空白を勝手に`.`(ピリオド)に変換したり,`print()`関数で表示すると膨大な行数を全て表示してしまったりと,いくつかの不便な点がある.`tibble`はそれらを改良したデータ構造であり,次回以降に学ぶ`tidyverse`パッケージ群で標準的に用いられる.`tibble`はあくまでデータフレームの改良版なので,実際のデータ分析では両者の区別を意識する場面は少ない.まずは`data.frame`の基本をしっかり押さえておこう.
:::
------------------------------------------------------------------------
### (続)データフレーム {#続データフレーム}
- Rの内部ではデータフレームはリストの一種として認識されているので,[**リスト同様の参照が可能**]{style="color: blue"}である.
- データフレーム特有の参照方法として,`x[[1]]`と同じ内容を参照するのに,`x$ID`と指定することもできる.
- R特有の文法として,仮に`x[, 1]`として[**特定の次元を空白とする**]{style="color: red"}と,その次元は全ての要素が指定される.したがって,`x[, 1]`は`x$ID`と全く同じ参照となる.
```{r}
print(x[, 1])
print(x$ID)
```
------------------------------------------------------------------------
## `for`文の使い方 {data-name="for文"}
### `for`文の概要
::: callout-note
### `for`文とは?
`for (`[**Variable Name**]{style="color: blue"} `in` [**Sequence**]{style="color: green"}`) {` <br> [**Do Something**]{style="color: orange"} <br> `}`
- `for`文のように,コードのどの行が実行されるか順序を制御する構文のことを,一般に[**制御構文**]{style="color: red"}と呼ぶ.
:::
```{r}
for (i in 1:4) {
j <- i + 10 # iに10を足したものをjとして定義
print(j) # jを出力
}
```
------------------------------------------------------------------------
### `for`文の練習問題
::: {.callout-note icon="false"}
#### Exercise 3
- `for`文を使って,3の段の掛け算($3 \times 1, 3 \times 2, \ldots, 3 \times 9$)の結果を順番に表示してみよう!
:::
::: goal
**(ヒント!)**
1. `i in 1:9`として,`i`が1から9まで順番に変化するようにする.
:::
------------------------------------------------------------------------
### `for`文を使った発展問題
::: {.callout-note icon="false"}
#### Exercise 4
- 初項が2,公差が3の等差数列 $a = (2, 5, 8, \ldots, 29)$ の各項を,`for`文を使って順番に表示せよ.
:::
**(ヒント!)**
1. 等差数列は`seq()`関数を使えば作成することができる.忘れている人は,[ここ](#ここ)を参照.
2. 初項から第10項までのベクトルを`a`として定義すれば,初項は`a[1]`,第2項は`a[2]`で参照することができる.忘れている人は,[要素へのアクセス](#要素へのアクセス)を確認しよう.
------------------------------------------------------------------------
## 自習課題 {data-name="自習課題"}
- 以下の課題に取り組み,今回学んだ内容の理解度を自分で確認しよう.
### 準備:自分だけのデータを生成する
- 以下のコードをRコンソールで実行しよう.`set.seed()`関数の引数には,**自分の学籍番号の末尾4桁の数字**(末尾の英字を除く)を入力すること.
```{r}
#| eval: false
# 自分の学籍番号の末尾4桁の数字を入力(例: 学籍番号が2001234Bの場合は1234)
set.seed(1234)
# ランダムなテストの点数データを生成
score <- round(rnorm(10, mean = 60, sd = 20))
score # 中身を確認
```
- `set.seed()`関数は乱数の種(seed)を固定する関数であり,同じ種を指定すれば何度実行しても同じ乱数が生成される.学籍番号の末尾4桁の数字が異なれば,生成されるデータも異なるため,**各自固有のデータ**で練習することになる.
------------------------------------------------------------------------
### Q1: ベクトルの要素へのアクセス
::: {.callout-note icon="false"}
#### 問題
- `score`の3番目と7番目の要素をそれぞれ表示し,その合計を計算せよ.
:::
------------------------------------------------------------------------
### Q2: ベクトルの基本的な計算
::: {.callout-note icon="false"}
#### 問題
- `score`の全要素の合計と平均値を,それぞれ`sum()`関数と`mean()`関数を使って求めよ.
:::
------------------------------------------------------------------------
### Q3: for文を使った条件付きカウント
::: {.callout-note icon="false"}
#### 問題
- `for`文と`if`文を組み合わせて,`score`の中から70点以上の要素の個数を数えよ.
:::
::: goal
**(ヒント!)**
1. カウント用の変数`count`を最初に`0`で用意する.
2. `for`文で`score`の各要素を順番に見ていき,`if`文で70以上かどうかを判定し,該当すれば`count`に1を加える.
3. `for`文の書き方には二つのスタイルがある.どちらを使っても結果は同じなので,自分が読みやすい方を選ぼう.
```{r}
#| eval: false
# スタイル1: インデックス(番号)でループする方法
for (i in 1:length(score)) {
# score[i] で i 番目の要素にアクセス
}
# スタイル2: 要素そのものでループする方法
for (s in score) {
# s に score の各要素が順番に入る(s は好きな変数名でOK)
}
```
:::
------------------------------------------------------------------------
### Q4: 行列の作成とアクセス
::: {.callout-note icon="false"}
#### 問題
- `score`を2行5列の行列`score_matrix`に変換し,1行3列目と2行4列目の値をそれぞれ表示せよ.
- **(ヒント)** `matrix()`関数の`nrow`引数を使えば行数を指定できる.
:::