2 Rのセットアップ
シミュレーション・データの準備とR言語の基本的な機能
2026/04/17

1 Accounting 101(教科書第1.1節)
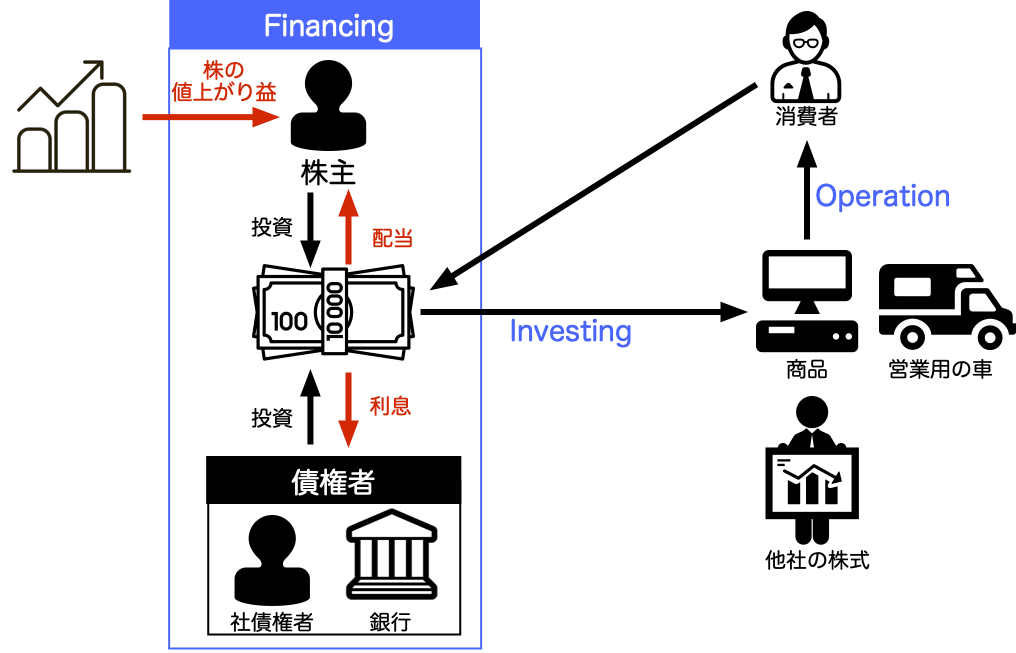
1.1 企業が営む経済活動
- 資金調達活動 (Financing)
- 資金投下(投資)活動 (Investing)
- 営業活動 (Operation)
単純な小売業を例に
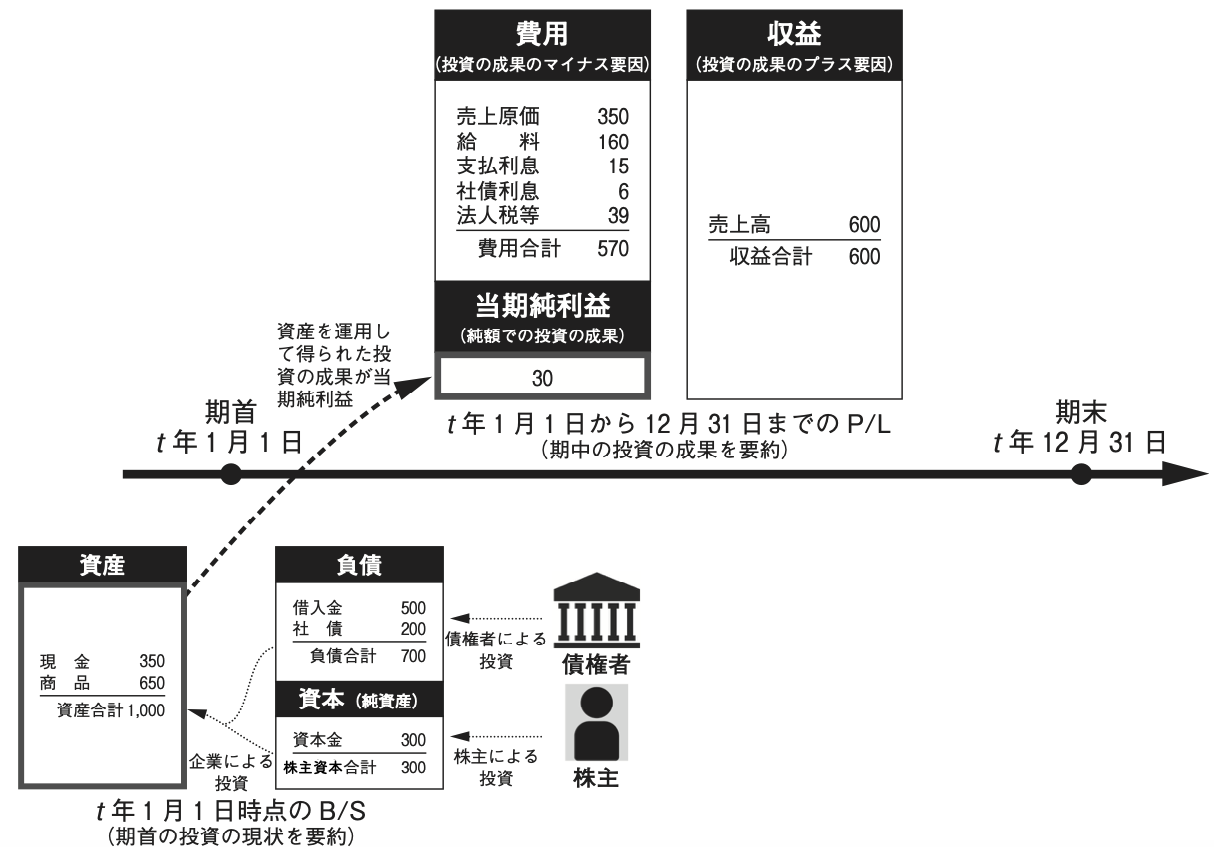
1.2 経済活動を要約するツール \(=\) 財務諸表
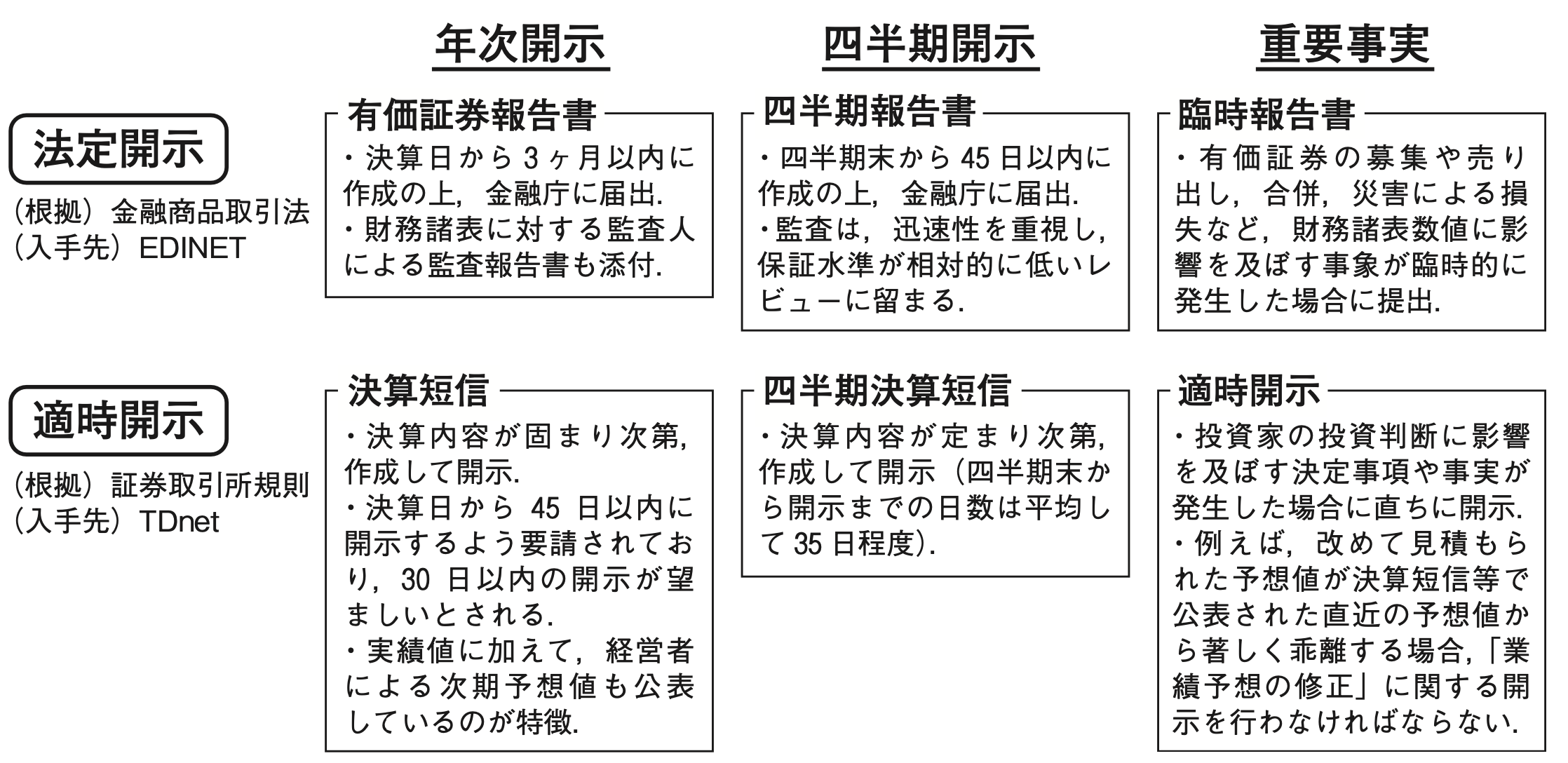
2 上場企業のディスクロージャー制度(教科書第4.1節)
2.1 法定開示と適時開示
2.2 四半期財務報告制度の制度改革
- 2023年11月の金商法改正により,四半期財務報告制度が変革したことに伴い,2024年4月以降開始の1Q/3Qから四半期報告書は順次廃止.
- 1Q/3Q決算短信について,監査人によるレビューは原則任意.
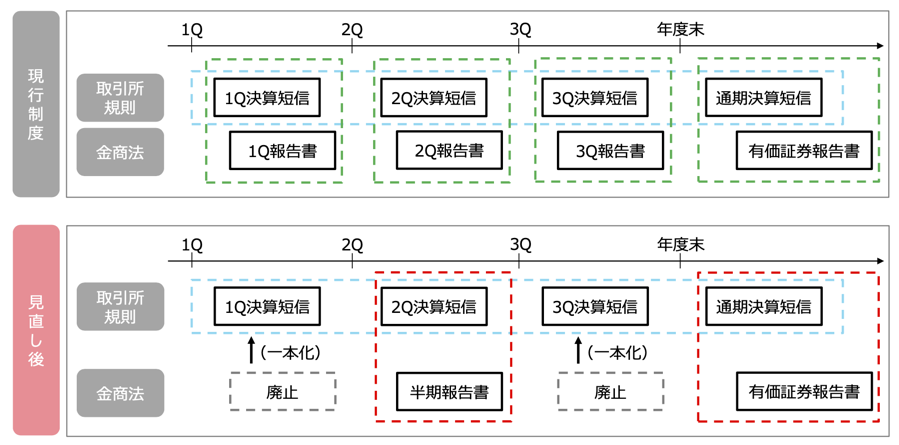
(引用)東京証券取引所上場部「四半期開示の見直しに関する実務の方針」2023年11月22日.
2.3 事前の予想に反して,実際のレビュー実態は…

(引用)日本経済新聞,2024年9月5日付朝刊.
3 コードとシミュレーション・データの準備
3.1 コードのダウンロード
Step 1. 本書のサポートサイトのS3にアクセス.
Step 2. Zipファイルをダウンロード. 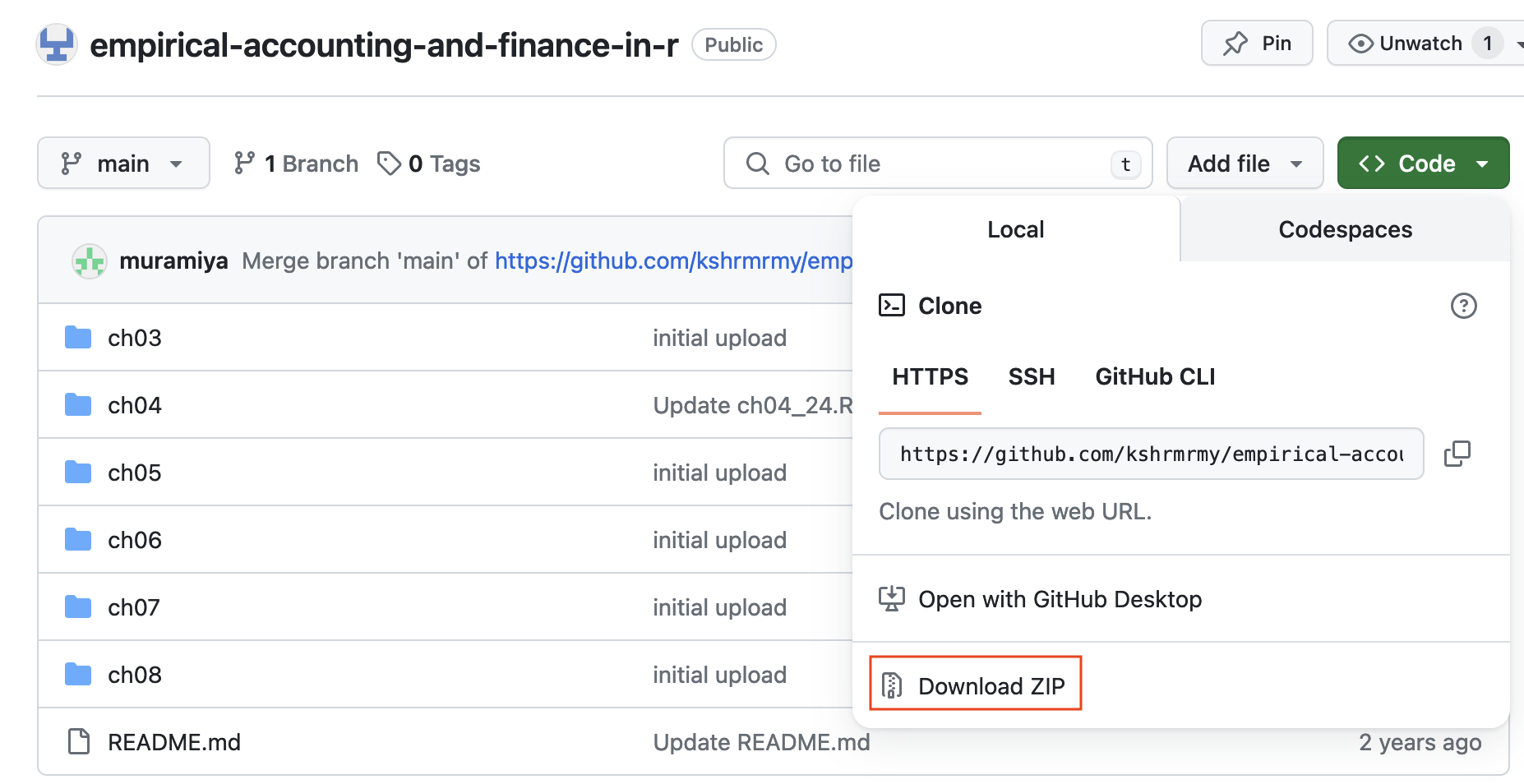
3.2 Posit Cloudへのコードのアップロード
Step 3. Posit CloudにダウンロードしたZipファイルをアップロード.
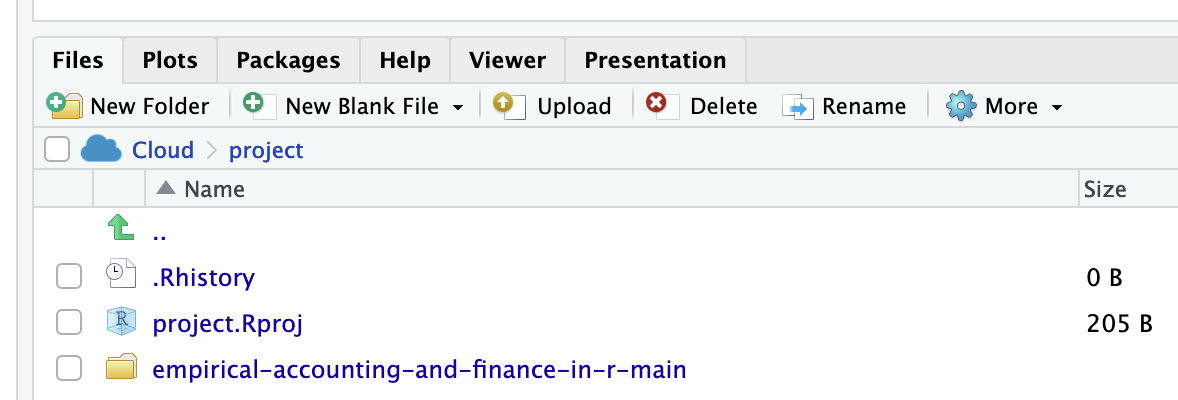
Step 4. empirical-accounting-and-finance-in-r-mainフォルダを選択し,Renameによりcodesフォルダへと識別可能性の観点から名前変更.
3.3 シミュレーション・データのダウンロード
Step 1. 本書のサポートサイトのS2にアクセス.
Step 2. Zipファイルをダウンロード. 
Step 3. 教科書「まえがき」ivページに記載のパスワードを入力して解凍.
Step 4. 解凍されたファイルを再度圧縮し,改めてZipファイルを作成.
3.4 シミュレーション・データのアップロード
Step 5. Posit Cloudに先の手順により作成されたZipファイルをアップロード.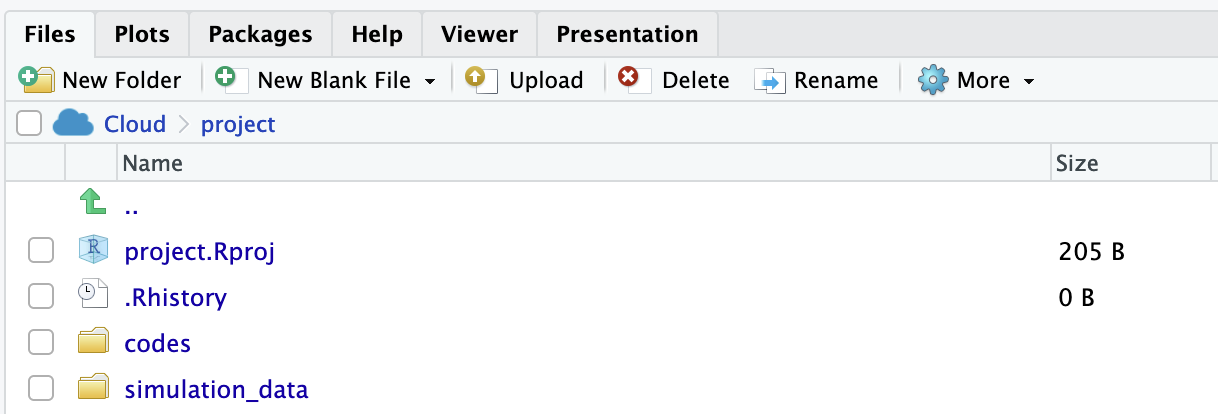
5 引数とは?(教科書第3.1節)
5.1 0.1から0.2まで0.01刻みのRベクトルを作ってみよう!

R <- seq(0.1, 0.2, 0.01)は,R <- seq(from = 0.1, to = 0.2, by = 0.01)の省略形である.- R言語の関数には位置指定という概念があり,例えば
seq()関数の場合,引数名が省略されていると,最初の三つの引数はそれぞれ等差数列の始点 (from),終点 (to),差分 (by)と解釈し,実行してくれる.
5.3 要素へのアクセス

- 例えば
R[2]とすれば,2番目の要素が参照できる.要素の指定は変数を用いて行うこともでき,i <- 2と定義しておけば,R[i]は2番目の要素を表す.
6 行列・リスト・データフレーム(教科書コラム3.4)
6.1 行列
- ここまではスカラーとベクトルが登場した.Rでは,行列 (matrix)も扱うことができる.


6.2 リスト
- リスト (list)とは,任意のオブジェクトや変数をまとめたもの.
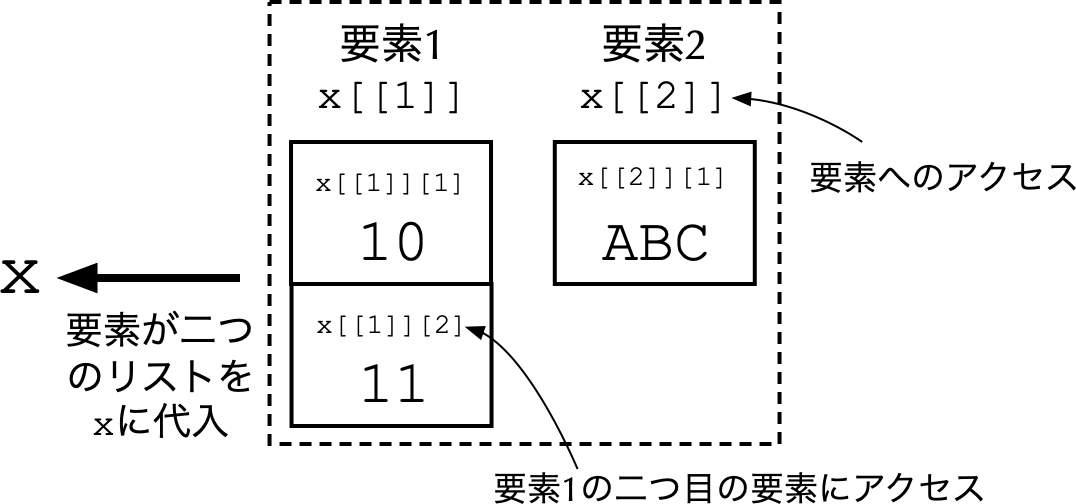
- このリストは,
(10, 11)という2次元ベクトルと,ABCという文字列をそれぞれの要素として含んでいる.リストは要素の参照方法が通常のベクトルと異なり,カッコを二重にする. - 例えば,
xの1番目の要素を参照するには,x[[1]]と指定.上の例だと,x[[1]]は(10, 11)というベクトルであるため,そのうち11を参照したければ,x[[1]][2]と指定.
6.3 データフレーム
- データフレーム (data frame)とは,異なるサンプルのデータを表形式にして一つのデータとして扱うためのオブジェクトである.
- 外観は行列と同じ2次元配列であるが,各行・列がラベルを持ち,それらがどのサンプルの何に関するデータなのかを表す.
