Code
pacman::p_load(tidyverse)
# 株式データの読み込み
stock_data <- read_csv("../simulation_data/ch05_stock_data.csv") simulation_dataフォルダ内に格納している株式データch05_stock_data.csvを読み込もう.pacman::p_load(tidyverse)
# 株式データの読み込み
stock_data <- read_csv("../simulation_data/ch05_stock_data.csv") stock_dataに格納されている各変数head(stock_data)stock_price: 月末時点での終値DPS: 一株当たり配当額 (Dividend Per Share; DPS)shares_outstanding: 月末時点での発行済株式数adjustment_coefficient: 調整係数R_F: 月次無リスク金利
stock_data %>%
filter(firm_ID == 1 & month_ID %in% 27:30)month_ID %in% 27:30はmonth_IDが27, 28, 29, 30を含んでいるという意味.DPSであるが,権利確定月,及び一株当たりの受け取り配当を記録するデータである.firm_IDが1の企業について見てみると,2017年6月の月末時点の株主に対して,一株当たり43円の配当が支払われたことが分かる.1以外の値を取る例stock_data %>%
filter(firm_ID == 74 & month_ID %in% 29:32)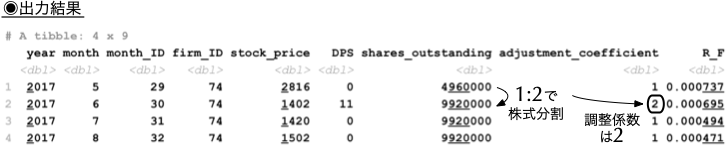
adjustment_coefficientは,株式分割や併合などに伴う株式数の変化を調整するためのデータである.2として,リターンを計算する際に調整する必要がある.stock_dataに時価総額ME列をmutate()関数を使って追加してみよう.stock_data <- stock_data %>%
mutate(ME = stock_price * shares_outstanding)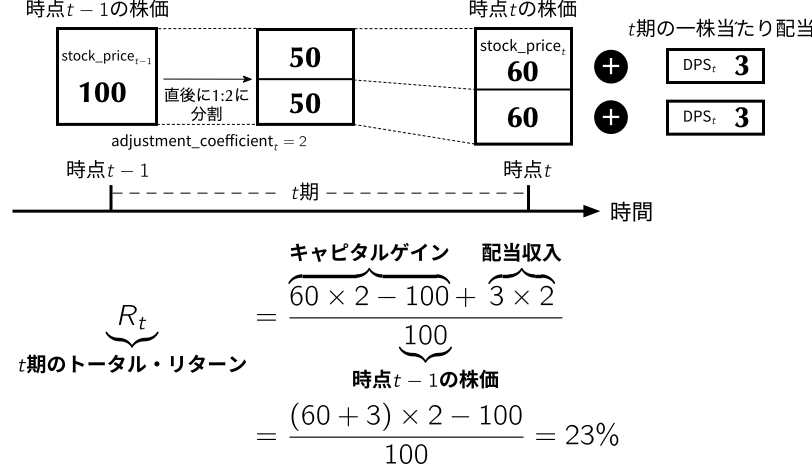
lagged_stock_priceを定義してから,(5.1)式に基づいて月次のトータル・リターンRをデータフレームstock_dataに追加している.# 月次リターンの追加
stock_data <- stock_data %>%
group_by(firm_ID) %>%
mutate(lagged_stock_price = lag(stock_price)) %>% # 前月株価をlagged_stock_priceと定義
ungroup() %>%
mutate(R = ((stock_price + DPS) * adjustment_coefficient - lagged_stock_price) / lagged_stock_price) # (5.1)式に従って月次リターンを計算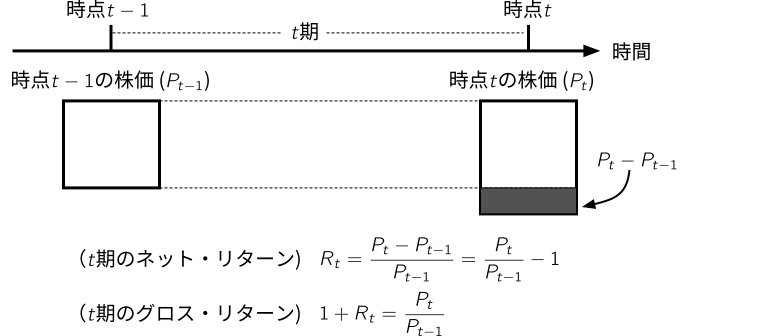
ここで,\(R_{F,t}\)は同期間に安全資産で運用した場合のネット・リターンを指し,\(R_{t}^e\)の\(e\)は超過を意味するexcessの略である.
# 月次超過リターンの追加も加える
stock_data <- stock_data %>%
group_by(firm_ID) %>%
mutate(lagged_stock_price = lag(stock_price)) %>% # 前月株価をlagged_stock_priceと定義
ungroup() %>%
mutate(R = ((stock_price + DPS) * adjustment_coefficient - lagged_stock_price) / lagged_stock_price, # (5.1)式に従って月次リターンを計算
Re = R - R_F) # 月次超過リターンを計算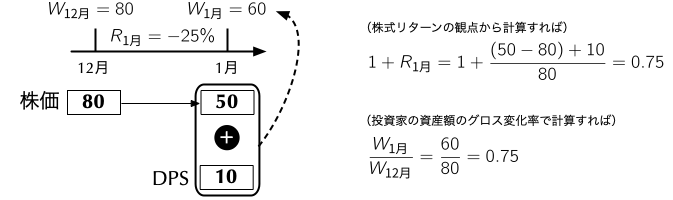
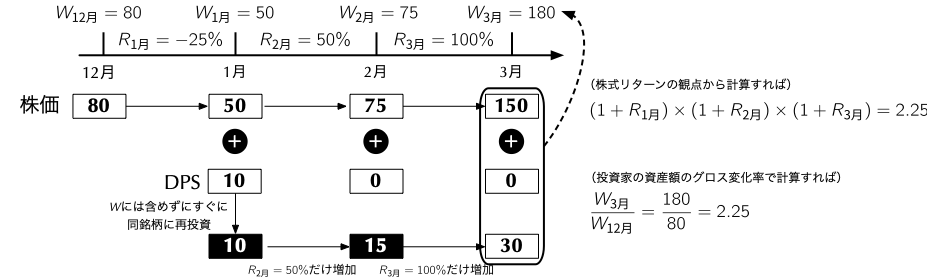
\[ \begin{align*} \underbrace{\left(\frac{W_{\text{3月}}}{W_{\text{12月}}}\right)}_{\textbf{グロスの3ヶ月間のリターン}} = \underbrace{\left(\frac{\cancel{W_{\text{1月}}}}{W_{\text{12月}}}\right)}_{1 + R_{\text{1月}}} \times \underbrace{\left(\frac{\cancel{W_{\text{2月}}}}{\cancel{W_{\text{1月}}}}\right)}_{1 + R_{\text{2月}}} \times \underbrace{\left(\frac{W_{\text{3月}}}{\cancel{W_{\text{2月}}}}\right)}_{1 + R_{\text{3月}}} \end{align*} \]
\[ \begin{align*} \underbrace{\left(\frac{W_{\text{翌年12月末}}}{W_{\text{12月末}}}\right)}_{\textbf{グロスの年次リターン}} & = (1 + R_{\text{1月}})\times (1 + R_{\text{2月}})\times \cdots \times (1 + R_{\text{12月}}) \nonumber\\ & = \prod_{t = \text{1月}}^{\text{12月}}(1 + R_{t}) \end{align*} \]
以下のコードでは,group_by()関数を用いてfirm_ID,及びyearの各ペアに関して,stock_dataをグループ化し,summarize()関数を用いて年次リターンR,及びそれに対応する年次無リスク金利R_Fを計算した後,年次超過リターンReを定義している.
# 月次リターンを累積して年次リターンを計算
annual_stock_data <- stock_data %>%
group_by(firm_ID, year) %>% # firm_IDとyearのペアでグループ化
summarize(R = prod(1 + R) - 1, # バイ・アンド・ホールドの年次リターン
R_F = prod(1 + R_F) - 1) %>%
mutate(Re = R - R_F) %>% # 年次超過リターンの計算
select(firm_ID, year, R, Re, R_F) %>% # 必要な変数のみ選択
ungroup()
# head()関数により確認
head(annual_stock_data)# write_csv()関数を用いて出力
write_csv(annual_stock_data, "../simulation_data/annual_stock_data.csv")drop_na()関数を利用して欠損値を除去した後の月次超過リターンのベクトルをRe_firm_ID_1として定義している.# 月次超過リターンの期待値に関するt検定 (1)
Re_firm_ID_1 <- stock_data %>%
filter(firm_ID == 1) %>% # firm_IDが1の企業のみ抽出
select(Re) %>% # 月次超過リターンのみ抽出
drop_na() %>% # 欠損値を削除
unlist() # データフレームからベクトルに変換
mu0 <- 0 # 帰無仮説を期待値0と設定
n <- length(Re_firm_ID_1) # 標本サイズ
t_value <- (mean(Re_firm_ID_1) - mu0) / sqrt(var(Re_firm_ID_1) / n) # 定義に従ってt値を計算
## [1] 2.121296t.test()関数が用意されている.# 月次超過リターンの期待値に関するt検定 (2)
t.test(Re_firm_ID_1) # t.test()関数で第二引数以降を省略