Code
pacman::p_load(tidyverse, magrittr, tinytable)
test <- read_csv("data/3_test.csv")- 1
- パッケージの読み込み
- 2
-
3_test.csvというファイルをtestという名前でRに読みこませる



| Level | 内容 |
|---|---|
| 1a | ランダム化比較試験のメタアナリシス |
| 1b | 少なくとも一つのランダム化比較試験 (RCT) |
| 2a | ランダム割付を伴わない同時コントロールを伴うコホート研究(前向き研究、prospective study, concurrent cohort study) |
| 2b | ランダム割付を伴わない過去のコントロールを伴うコホート研究 (historical cohort study, retrospective cohort study) |
| 3 | 症例対照研究(ケースコントロール、後ろ向き研究) |
| 4 | 処置前後の比較の前後比較、対照群を伴わない研究 |
| 5 | 症例報告、ケースシリーズ |
| 6 | 専門家個人の意見(専門家委員会報告を含む) |
得られたデータは,解析され,色々な役に立てられます。 大きく分けて,予測と発見があると言われています。


現在のデータを使って,別の場所・時間の傾向を予測するのに役立つ
予測をするには,データを使った原因と結果の特定が必要
例えば,データをいくつかのグループに分ける。
あらかじめ分け方が決まっていない場合には,データ自身にグループを作成させるクラスタリングを行う
定量的データを使った社会調査では,知りたいものを数値の形をとったデータに置き換えます。言い換えると背後に一般的な概念を想定した代理変数がデータです。
このように,抽象的な概念を客観的な数値で表現することが,定量的データを使った社会調査の1つの利点です。
一方で,概念とそれの代理変数である数値は必ずしも一対一対応しているわけではない点に注意が必要です。
知りたい概念のどの側面をどの程度反映した指標なのかを考えながら使う必要が。。
データ(変数)はその性質に応じて分類が可能です。
「分類する」変数
数字の大小比較に意味がない
数字そのものが意味を持っている
数字の大小比較に意味がある

| 種類 | 尺度 | 説明 | 例 |
|---|---|---|---|
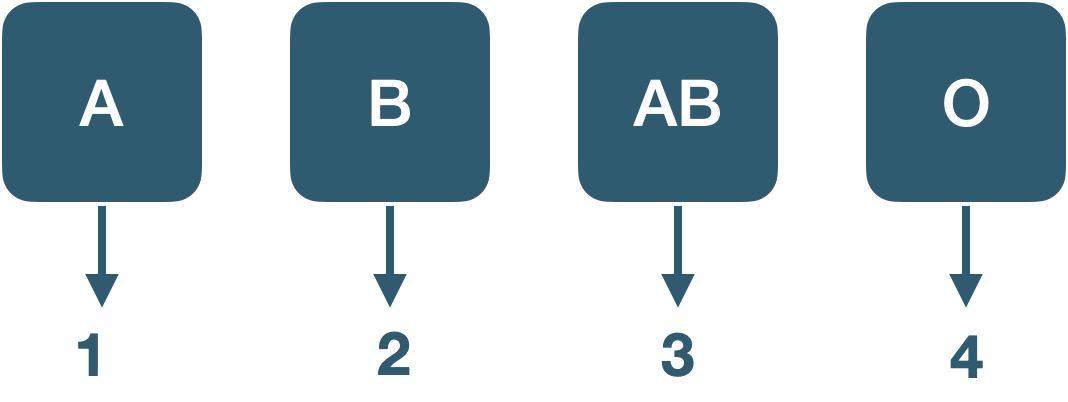
| 質的変数 | 名義尺度 | 性質を分類するために使われる(男 = 0, 女 = 1,のように性質に数値を割り当てる)。数値に意味はない。比較も計算もできない | 性別,学籍番号 |
| 質的変数 | 順序尺度 | 並び順に意味がある尺度。大小関係はあるが,計算はできない。 | 人気ランキング,成績(秀優良可不可) |
| 量的変数 | 間隔尺度 | 大小関係に加えて間隔にも意味がある。足し算はできるけど掛け算には意味がない(西暦1000年の2倍は西暦2000年,という計算に意味はある?) | 西暦・温度 |
| 量的変数 | 比例尺度 | 比較・足し算・掛け算全てできる | 身長・体重・価格・売上高・利益 |
データがそれぞれどの種類の尺度なのかによってまとめ方や分析での使い方が変わります。
以下のデータの各列はそれぞれどの尺度ですか。ただし
id: 学籍番号class: クラスgender: 性別test: テストの点hometown: 出身地pacman::p_load(tidyverse, magrittr, tinytable)
test <- read_csv("data/3_test.csv")3_test.csvというファイルをtestという名前でRに読みこませる
データの種類にはいくつかあるということでしたが,rにもそれに(完全にではないけれど)対応したデータの種類があります。
num数値型):数値データchr文字列型):文字データfctr因子型):カテゴリデータlgl論理値型):trueかfalseの2択データエクセルやcsvファイルを読み込んだとき,Rは自動でこれらのうちのどれかとして読み取ります。どの種類として読み込まれたかは,画面右上のEnvironmentタブにあるDataウインドウから確認可能です。また,単にデータ名を実行するもしくはstr(データ名)でも確認可能です。
str(test)spc_tbl_ [30 × 5] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
$ id : num [1:30] 1 2 3 4 5 6 7 8 9 10 ...
$ class : num [1:30] 1 1 1 1 1 1 1 1 1 1 ...
$ gender : chr [1:30] "男" "女" "女" "女" ...
$ test : num [1:30] 100 20 60 80 40 90 30 60 90 30 ...
$ hometown: chr [1:30] "京都" "京都" "大阪" "兵庫" ...
- attr(*, "spec")=
.. cols(
.. id = col_double(),
.. class = col_double(),
.. gender = col_character(),
.. test = col_double(),
.. hometown = col_character()
.. )
- attr(*, "problems")=<externalptr> 初期状態では,genderとhometownがchr(文字列),それ以外がnum(数値)になっています。しかし,例えばidやclassは名義尺度であるべきです。
後で使うclassをカテゴリデータに変えてみます。使うコマンドはas.factor(変えたい変数)です。
testa <- test %>%
mutate(class = as.factor(class))1行目は,testaという新しいデータを作って,その中に以下の処理をしたものを入れるということを意味しています。
2行目のmutate(新しい変数名 = 指示) は,新しい変数(列)を足すコマンドです。現在ある列名と同じものを指定すると上書きされます。今回は,classという数値変数をカテゴリ変数に変えたものを,元と同じclassという名前で作成(上書き)しています。
文字列については,分析の際には自動的にカテゴリ変数として扱われるので,特段の変更処理は必要ありません。

データを集計して,表にまとめるときには,いくつかの方法があります。が,データ分析上望ましいのは,変数が列,測定単位が行の形です。
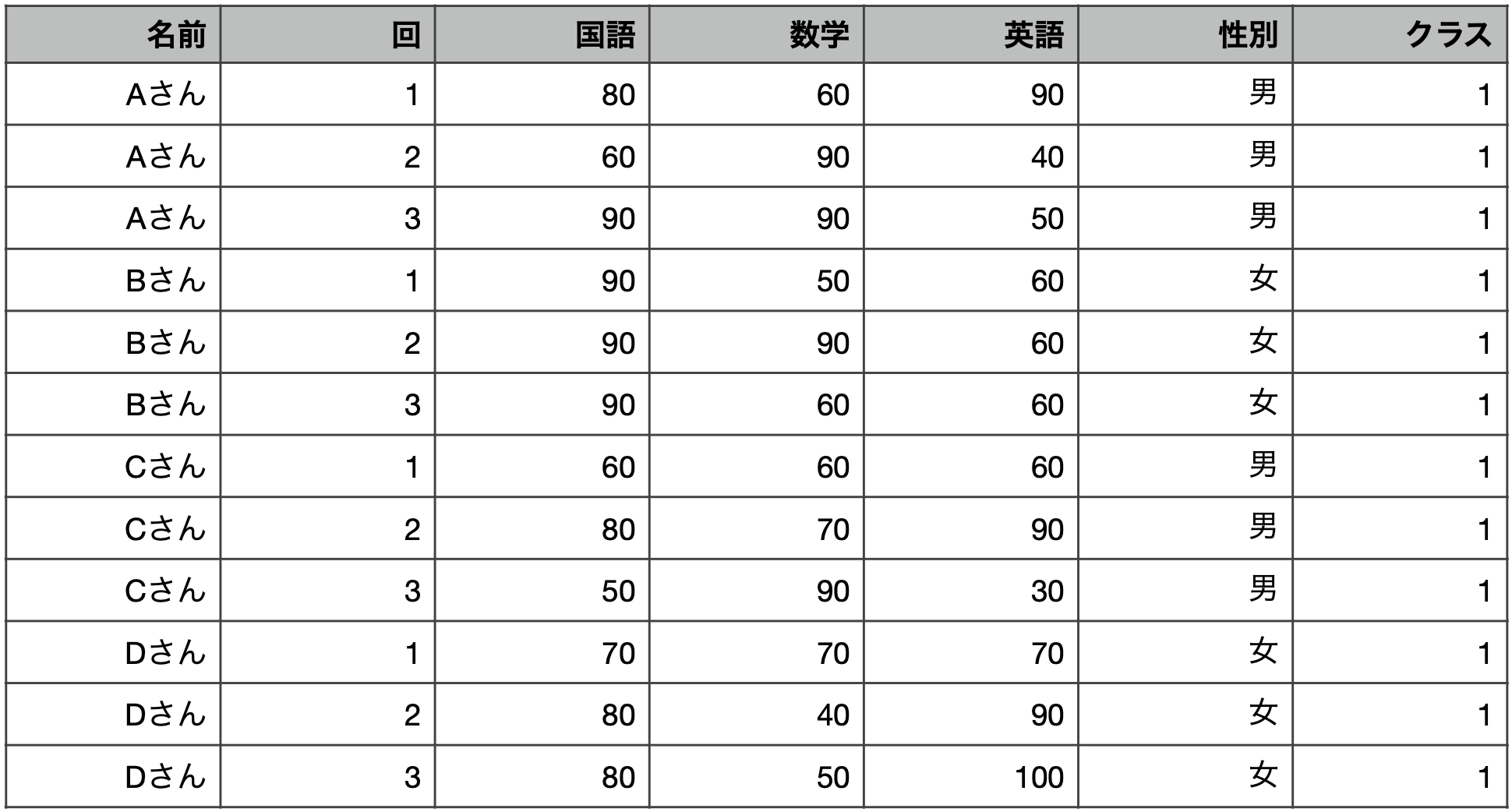
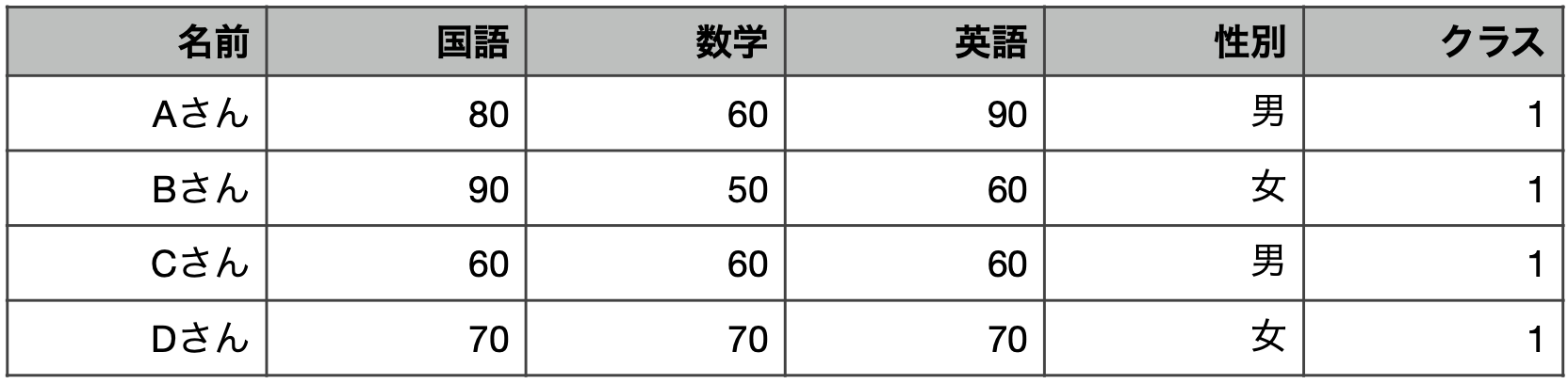
ある学校の1組には,A,B,C,Dさんの4人がいました。
Aさん,Cさんは男性,Bさん,Dさんは女性です。
それぞれのテストの点数は以下のとおりでした。
df <- data.frame(
name = c("A", "B", "C", "D"),
japanese = c(80, 90, 60, 70),
math = c(60, 50, 60, 70),
english = c(90, 60, 60, 70)
)
dfpacman::p_load(tidyverse, magrittr, readxl, kableExtra, rmarkdown, tinytable)
case_wide <- read_excel("data/case_wide.xlsx")
tt(case_wide)| name | age | m1 | m2 | m3 | m4 | m5 | m6 | m7 | m8 | m9 | m10 | m11 | m12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 田中一郎 | 25 | 171 | 173 | 174 | 175 | 177 | 178 | 179 | 181 | 182 | 183 | 185 | 185 |
| 田中次郎 | 24 | 170 | 171 | 172 | 173 | 174 | 176 | 177 | 179 | 180 | 181 | 183 | 184 |
| 田中三郎 | 23 | 166 | 167 | 169 | 170 | 172 | 172 | 173 | 174 | 175 | 176 | 177 | 178 |
| 田中四郎 | 22 | 161 | 162 | 164 | 165 | 167 | 168 | 169 | 171 | 172 | 173 | 174 | 176 |
| 田中五郎 | 21 | 190 | 192 | 193 | 194 | 195 | 197 | 198 | 200 | 201 | 203 | 205 | 206 |
| 田中六郎 | 20 | 155 | 156 | 158 | 159 | 160 | 161 | 162 | 163 | 164 | 166 | 167 | 168 |
| 田中七郎 | 19 | 180 | 182 | 183 | 185 | 186 | 188 | 189 | 191 | 193 | 194 | 195 | 196 |
ひとまずこれを目指す!
case_widel <- case_wide |>
pivot_longer(starts_with("m"),
names_to = "month",
names_prefix = "m",
values_to = "height") |>
mutate(month = as.numeric(month))
head(case_widel,20) |> tt()| name | age | month | height |
|---|---|---|---|
| 田中一郎 | 25 | 1 | 171 |
| 田中一郎 | 25 | 2 | 173 |
| 田中一郎 | 25 | 3 | 174 |
| 田中一郎 | 25 | 4 | 175 |
| 田中一郎 | 25 | 5 | 177 |
| 田中一郎 | 25 | 6 | 178 |
| 田中一郎 | 25 | 7 | 179 |
| 田中一郎 | 25 | 8 | 181 |
| 田中一郎 | 25 | 9 | 182 |
| 田中一郎 | 25 | 10 | 183 |
| 田中一郎 | 25 | 11 | 185 |
| 田中一郎 | 25 | 12 | 185 |
| 田中次郎 | 24 | 1 | 170 |
| 田中次郎 | 24 | 2 | 171 |
| 田中次郎 | 24 | 3 | 172 |
| 田中次郎 | 24 | 4 | 173 |
| 田中次郎 | 24 | 5 | 174 |
| 田中次郎 | 24 | 6 | 176 |
| 田中次郎 | 24 | 7 | 177 |
| 田中次郎 | 24 | 8 | 179 |
データセットには,集計された種類で大きく3種類に分けられます。
](images/t3-5.png)