Code
if (!require("pacman")) install.packages("pacman")
pacman::p_load(tidyverse, ggpubr,
estimatr,car,modelsummary,datarium,
dae)- 1
-
複数のパッケージを一度に読み込める
pacmanパッケージが入っていない場合は,インストールする - 2
- パッケージの読み込み
if (!require("pacman")) install.packages("pacman")
pacman::p_load(tidyverse, ggpubr,
estimatr,car,modelsummary,datarium,
dae)pacmanパッケージが入っていない場合は,インストールする
pacman複数のパッケージを読み込めるパッケージ。そのパッケージの中のp_loadコマンドを使うと,()内に指示したパッケージを読み込める。さらにそのパッケージがそもそもインストールされていない場合にはインストールした後に読み込んでくれる
tidyverseRのコードを楽にするたくさんのパッケージをパッケージにしたもの
調査者が何らかの操作をして行う調査・研究
.svg)
参加者をランダムに2つ(以上)のグループに割り振って,片方には新しい薬を,片方には薬ではないもの(プラセボ)を投与して,新薬の効果を検証する

同じ場所に並べた複数の植木のうち,ランダムに選んだいくつかには肥料を与え,残りには与えないことで,肥料の効果を検証する

アクセスしてくる人のうち一定割合に別のデザインの画面を表示し,クリックする先やクリック率等を比較する。(どちらのデザインの方が良いか?)



実験的手法は,調査者が何らかの介入をして,その介入効果を見るようなもの。そのような特徴から
元々理系では実験的手法が中心だったけれど,上記の特徴から社会科学領域でも実験的研究が重視されてきている。
2019年のノーベル経済学賞をとったBanerjee, Duflo, Kremerも「世界の貧困を改善するための実験的アプローチに関する功績」
一方で,
Rにサンプルデータとして入っているheadacheデータを使用
ある製薬会社が片頭痛患者を対象に3種類の治療法を試験した。実験には72人の参加者が登録された。その目的は、片頭痛エピソードに関連する痛みのスコアを下げる新しいクラスの治療法の可能性を調べることである。
参加者は男性36名、女性36名である。男性と女性はさらに(等しく)片頭痛のリスクが低いか高いかに細分化された。
以下の変数を含む:
gender性別: 「男性」と「女性」;
riskリスク: 低 “と”高”
treatment治療の種類:3つのカテゴリーがある: X”、“Y”、“Z”の3つのカテゴリーがある。
data("headache")
headache <- headache |>
filter(treatment != "Y") |>
mutate(treatment = as.character(treatment), #<
treatment = as.factor(treatment))headacheデータを読み込み、以下の処理を上書き保存
treatmentのうち,Yを除外する。
分析例を簡単にするため,treatment Yを落とした。なので,Xを治療なし,Zを薬による治療と解釈して話を進める
記述統計を見ると,gender(男女)とrisk(高い低い)は各条件に均等に配分されている。
datasummary(pain_score + gender + risk ~
treatment * (mean + sd+N + Percent()),
data = headache)| X | Z | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| mean | sd | N | Percent | mean | sd | N | Percent | ||
| pain_score | 80.45 | 8.57 | 24 | 50.00 | 76.24 | 5.88 | 24 | 50.00 | |
| gender | male | 12 | 25.00 | 12 | 25.00 | ||||
| female | 12 | 25.00 | 12 | 25.00 | |||||
| risk | high | 12 | 25.00 | 12 | 25.00 | ||||
| low | 12 | 25.00 | 12 | 25.00 | |||||
ggplot(headache, aes(x = treatment, y = pain_score))+
geom_boxplot()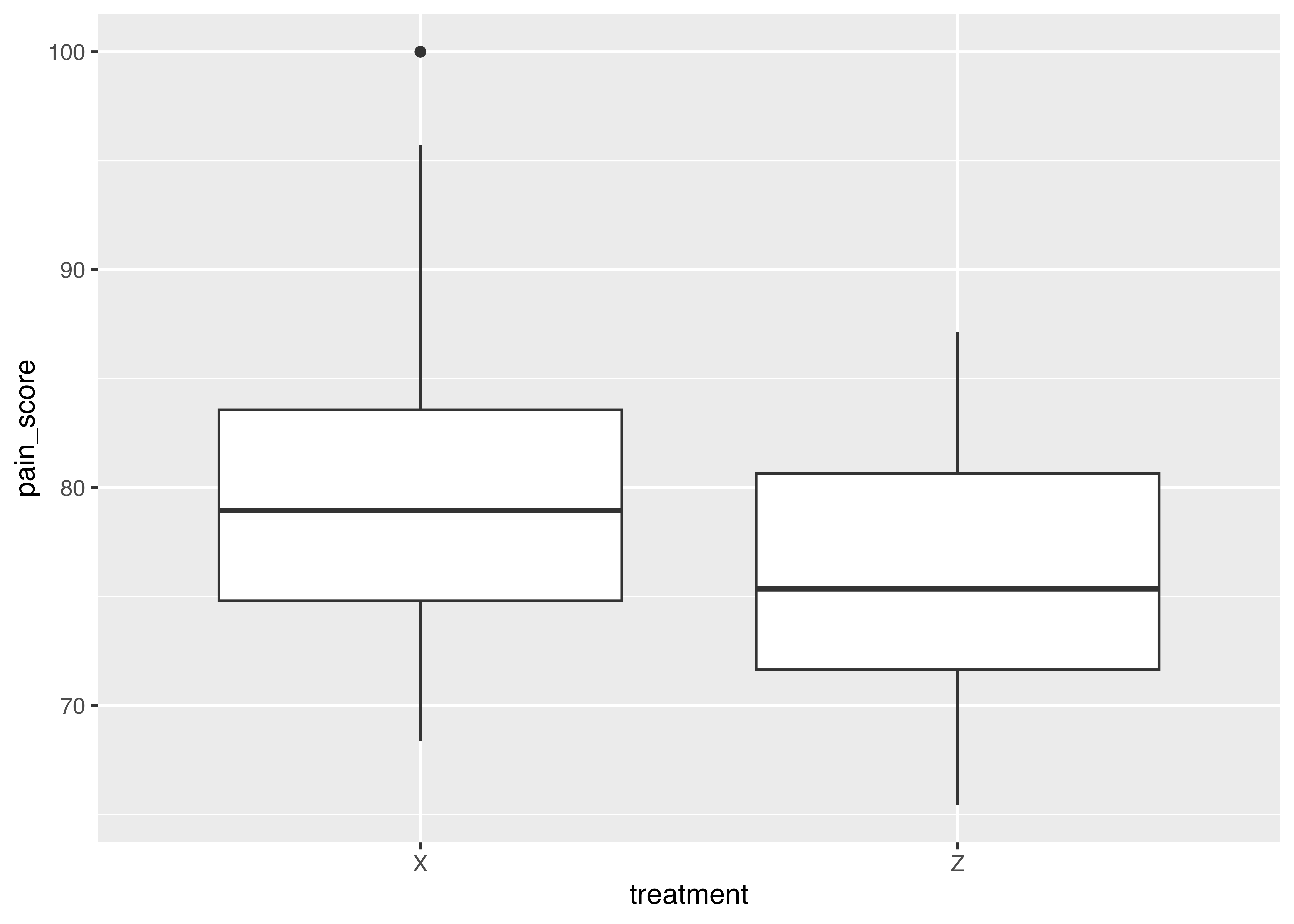
主な分析は分散分析(ANOVA)。aov(結果 ~ 要因, data = データ名)コマンドで実行可能
aov(pain_score ~ treatment, data = headache) |>
summary() Df Sum Sq Mean Sq F value Pr(>F)
treatment 1 213.2 213.21 3.946 0.053 .
Residuals 46 2485.7 54.04
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1仮説検定での帰無仮説は治療の効果はない。治療の違いの効果は10%水準で有意(水準を10%としたら,関係ないと言う帰無仮説は棄却される)
ANOVAの原理はダミー変数を使った回帰分析と一緒。なので以下のような単回帰分析をしても同じ
lm(pain_score ~ treatment, data = headache) |>
summary()
Call:
lm(formula = pain_score ~ treatment, data = headache)
Residuals:
Min 1Q Median 3Q Max
-12.093 -5.620 -1.165 4.403 19.547
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 80.453 1.501 53.617 <2e-16 ***
treatmentZ -4.215 2.122 -1.986 0.053 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 7.351 on 46 degrees of freedom
Multiple R-squared: 0.079, Adjusted R-squared: 0.05898
F-statistic: 3.946 on 1 and 46 DF, p-value: 0.05297更に,性別やそもそもの頭痛リスクを踏まえた分析をしてみる
aov(pain_score ~ treatment * risk, data = headache) |>
summary() Df Sum Sq Mean Sq F value Pr(>F)
treatment 1 213.2 213.2 6.741 0.0128 *
risk 1 1076.0 1076.0 34.019 5.94e-07 ***
treatment:risk 1 18.1 18.1 0.573 0.4531
Residuals 44 1391.7 31.6
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1リスク高低で分けると,治療の効果は5%水準で有意に。
リスクも有意。そもそもリスクが高い人は頭痛度合いが強い。
効果は似た感じ(交互作用はない)。
また,ggline()コマンドを使うと,効果を図に表せる
ggline(data = headache, #データを指定
x = "treatment", #x軸
y = "pain_score", #y軸
color = "risk", #色分けしたい条件
add = c("mean") #それぞれの条件での平均値を載せる
) +
theme_minimal() 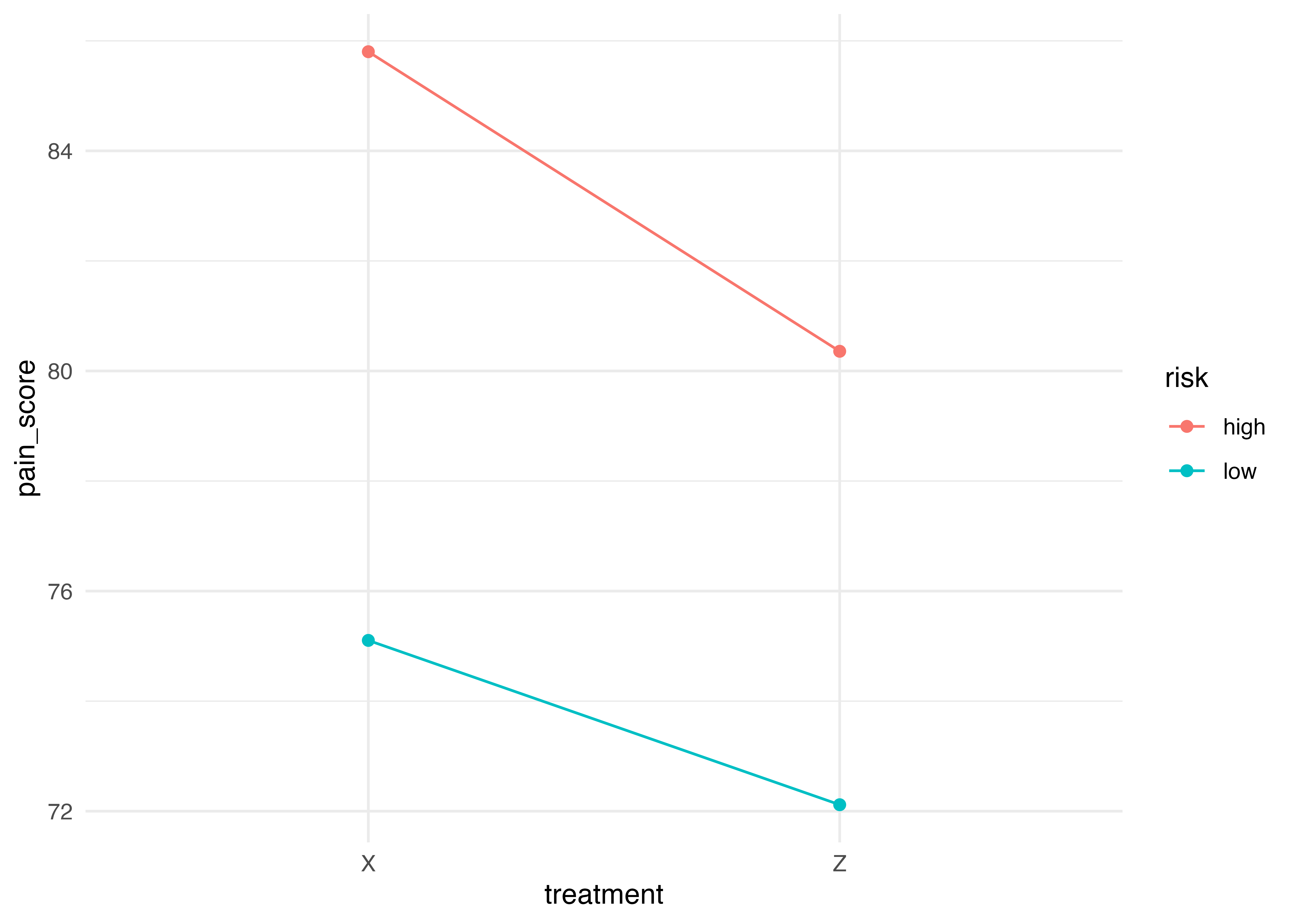
男女で効き目が違うか
aov(pain_score ~ treatment * gender, data = headache) |>
summary() Df Sum Sq Mean Sq F value Pr(>F)
treatment 1 213.2 213.21 4.475 0.0401 *
gender 1 273.4 273.36 5.738 0.0209 *
treatment:gender 1 116.2 116.20 2.439 0.1255
Residuals 44 2096.2 47.64
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1ggline(data = headache, #データを指定
x = "treatment", #x軸
y = "pain_score", #y軸
color = "gender", #色分けしたい条件
add = c("mean") #それぞれの条件での平均値を載せる
) +
theme_minimal() 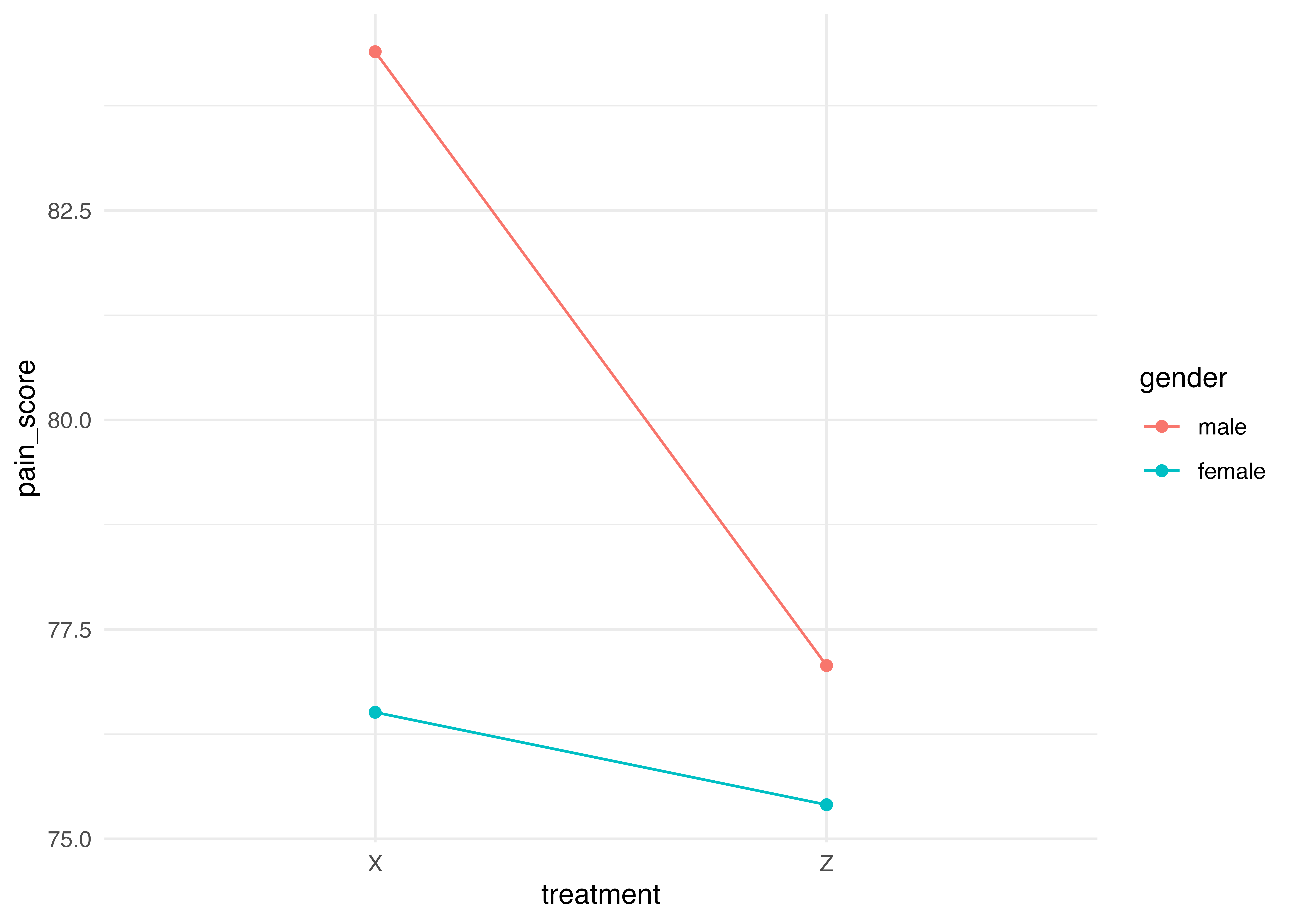
男性の方が効果が大きい。ただし,交互作用が有意とまではいかない(p < 0.123)
aov(pain_score ~ treatment+risk+gender,
data = headache) |>
summary() Df Sum Sq Mean Sq F value Pr(>F)
treatment 1 213.2 213.2 8.255 0.00623 **
risk 1 1076.0 1076.0 41.659 7.24e-08 ***
gender 1 273.4 273.4 10.584 0.00219 **
Residuals 44 1136.4 25.8
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1treatment, gender, riskはそれぞれ頭痛の度合いと有意に関係
aov(pain_score ~ treatment*risk*gender,
data = headache) |>
summary() Df Sum Sq Mean Sq F value Pr(>F)
treatment 1 213.2 213.2 11.646 0.001485 **
risk 1 1076.0 1076.0 58.770 2.25e-09 ***
gender 1 273.4 273.4 14.931 0.000399 ***
treatment:risk 1 18.1 18.1 0.990 0.325773
treatment:gender 1 116.2 116.2 6.347 0.015854 *
risk:gender 1 26.5 26.5 1.449 0.235751
treatment:risk:gender 1 243.2 243.2 13.286 0.000762 ***
Residuals 40 732.3 18.3
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1treatmentとriskとgenderの3要因に交互作用
interaction.ABC.plot(pain_score,
x.factor = treatment,
groups.factor = gender,
trace.factor = risk,
data = headache,
title = "Effect")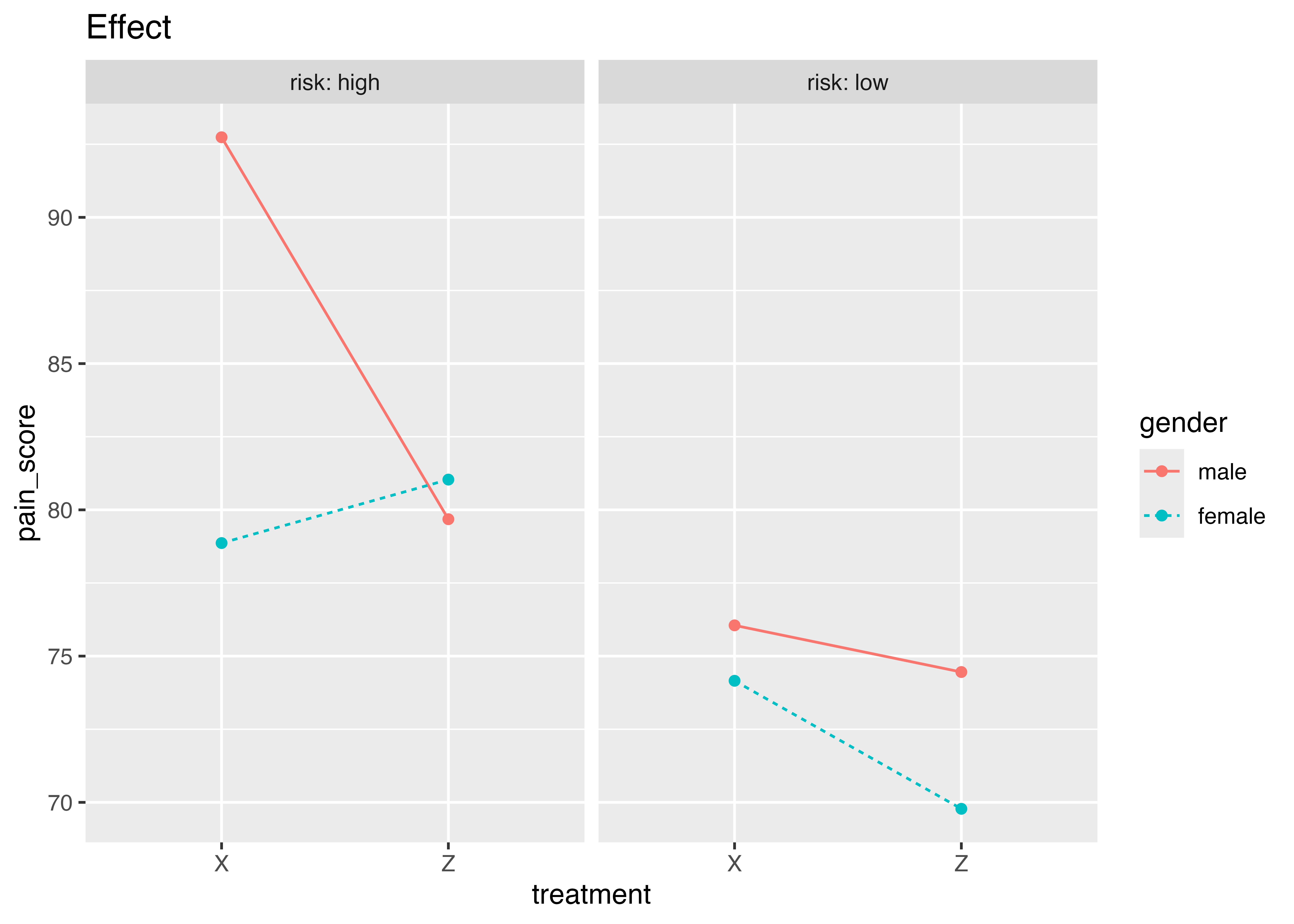
回帰分析の結果を並べるとこんな感じ
list(
m1 <- lm(pain_score ~ treatment ,data = headache),
m2 <- lm(pain_score ~ treatment + gender,data = headache),
m3 <- lm(pain_score ~ treatment * gender,data = headache),
m4 <- lm(pain_score ~ treatment + risk,data = headache),
m5 <- lm(pain_score ~ treatment * risk,data = headache),
m6 <- lm(pain_score ~ treatment + gender + risk ,data = headache),
m7 <- lm(pain_score ~ treatment * gender * risk ,data = headache)
) |>
msummary(stars = TRUE,
gof_omit = "Log.Lik.|AIC|BIC|RMSE|F",
statistic = NULL
)| (1) | (2) | (3) | (4) | (5) | (6) | (7) | |
|---|---|---|---|---|---|---|---|
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 | |||||||
| (Intercept) | 80.453*** | 82.839*** | 84.395*** | 85.188*** | 85.802*** | 87.574*** | 92.739*** |
| treatmentZ | -4.215+ | -4.215* | -7.327* | -4.215* | -5.444* | -4.215** | -13.058*** |
| genderfemale | -4.773* | -7.885** | -4.773** | -13.874*** | |||
| treatmentZ × genderfemale | 6.224 | 15.228*** | |||||
| risklow | -9.469*** | -10.698*** | -9.469*** | -16.687*** | |||
| treatmentZ × risklow | 2.458 | 11.462** | |||||
| genderfemale × risklow | 11.978** | ||||||
| treatmentZ × genderfemale × risklow | -18.009*** | ||||||
| Num.Obs. | 48 | 48 | 48 | 48 | 48 | 48 | 48 |
| R2 | 0.079 | 0.180 | 0.223 | 0.478 | 0.484 | 0.579 | 0.729 |
| R2 Adj. | 0.059 | 0.144 | 0.170 | 0.454 | 0.449 | 0.550 | 0.681 |
ハンバーガー統計学より引用
ある小学校で、算数の分数の計算を教えるためのマンガを使った新しい教材を開発した。この教材の効果は従来のものと比べ、効果があるようだということはわかっているが、さらにその効果が子どもの算数に対する好みによってどう違うのかを調べたいと思う。
この効果を調べるために、あるクラスでは従来の教材で教え(統制群)、別のクラスではマンガ教材で教えた(マンガ群)。一日おいて、分数の計算テストをした。このとき、各クラスで、算数が好きか嫌いかというアンケートをあらかじめ取っておき、算数が好きな子ども10人と嫌いな子ども10人とで比較することにした。
テストの点数データ(10点満点)は次のようになった。これを分散分析したい。
| 統制群 | マンガ群 | |
| 算数が好き | 7, 8, 6, 8, 10, 7, 8, 8, 9, 7 | 8, 9, 10, 10, 8, 8, 9, 7, 10, 8 |
| 算数が嫌い | 4, 6, 5, 4, 3, 7, 5, 6, 4, 5 | 8, 7, 8, 6, 9, 7, 8, 8, 10, 8 |
(1) この検定での帰無仮説を言いなさい。
(2) この検定での対立仮説を言いなさい。
(3) 4つの条件におけるそれぞれの平均と標準偏差を計算しなさい(コードと結果)。
(4) 分散分析を行いなさい(コード)。
(5) 有意水準を1%としたとき、この分散分析表から言えることを書きなさい。
(6) 以上の検定の結果を、わかりやすいことばで説明しなさい。
次ページにデータ作成用コマンドがあります。
データ作成
score <- c(7, 8, 6, 8, 10, 7, 8, 8, 9, 7,
8, 9, 10, 10, 8, 8, 9, 7, 10, 8,
4, 6, 5, 4, 3, 7, 5, 6, 4, 5,
8, 7, 8, 6, 9, 7, 8, 8, 10, 8)
like <- c(1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
manga <-c(0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1)
kadai <- tibble(score,like,manga) |>
mutate(like = factor(like,
levels = c(1, 0),
labels = c("like", "dislike")
),
manga = factor(manga,
levels = c(1, 0),
labels = c("manga", "normal")
)
)tibble)に。続けて0,1変数をダミー変数と認識させて(factor),ラベルをつけている