Code
- 1
-
複数のパッケージを一度に読み込める
pacmanパッケージが入っていない場合は,インストールする - 2
- パッケージの読み込み
2024/06/10
pacmanパッケージが入っていない場合は,インストールする
pacman複数のパッケージを読み込めるパッケージ。そのパッケージの中のp_loadコマンドを使うと,()内に指示したパッケージを読み込める。さらにそのパッケージがそもそもインストールされていない場合にはインストールした後に読み込んでくれる
tidyverseRのコードを楽にするたくさんのパッケージをパッケージにしたもの
magrittrtidyverseに含まれる%>%などのコードをさらに拡張するもの。これがあると%$%とか%<>%が使える
使うデータは,アイスクリーム屋さんの気温と客数のデータです(アイスクリーム統計学より)。
気温はkion,客数はkyakuという名前になっていることを確認します。
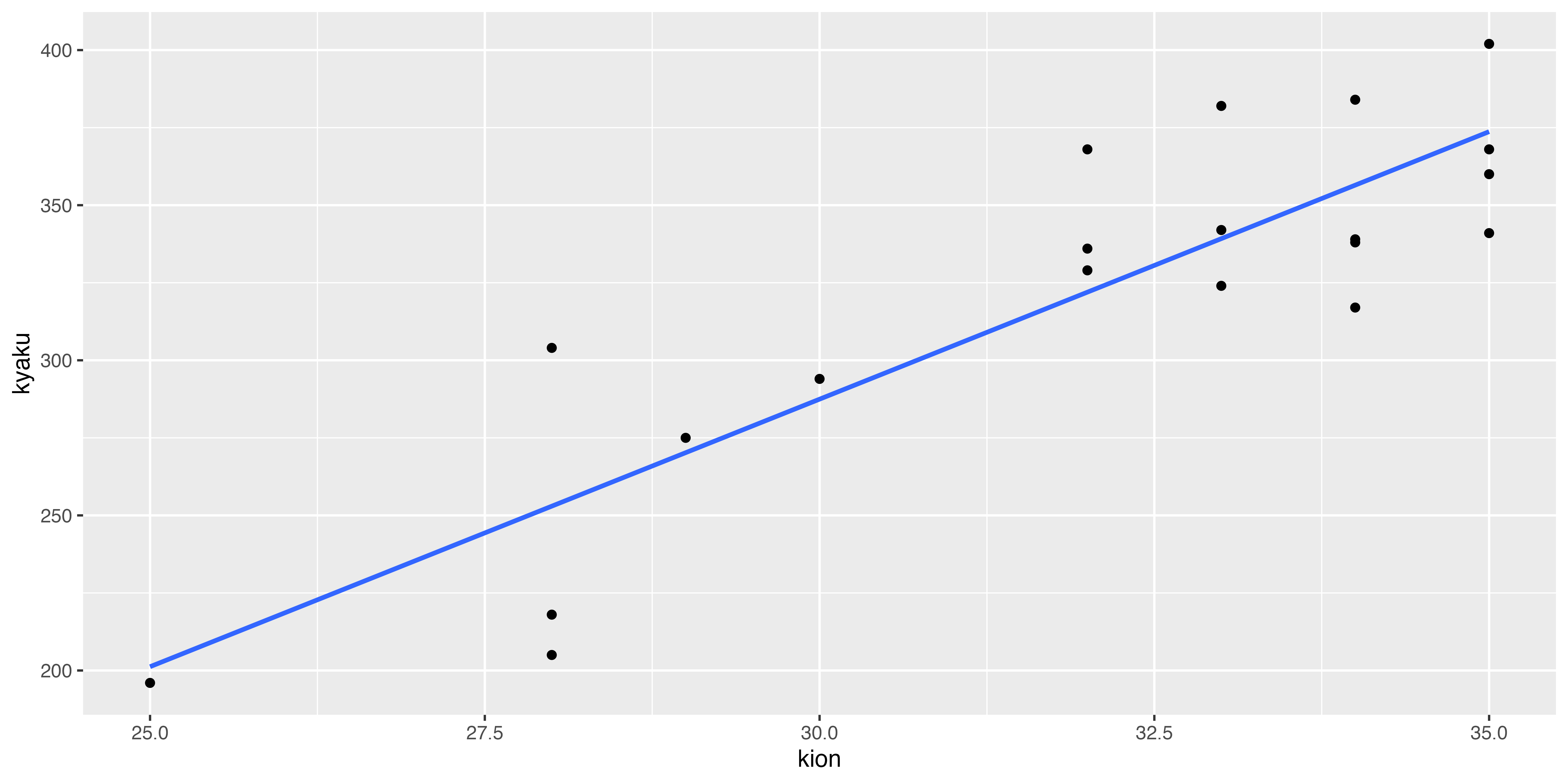
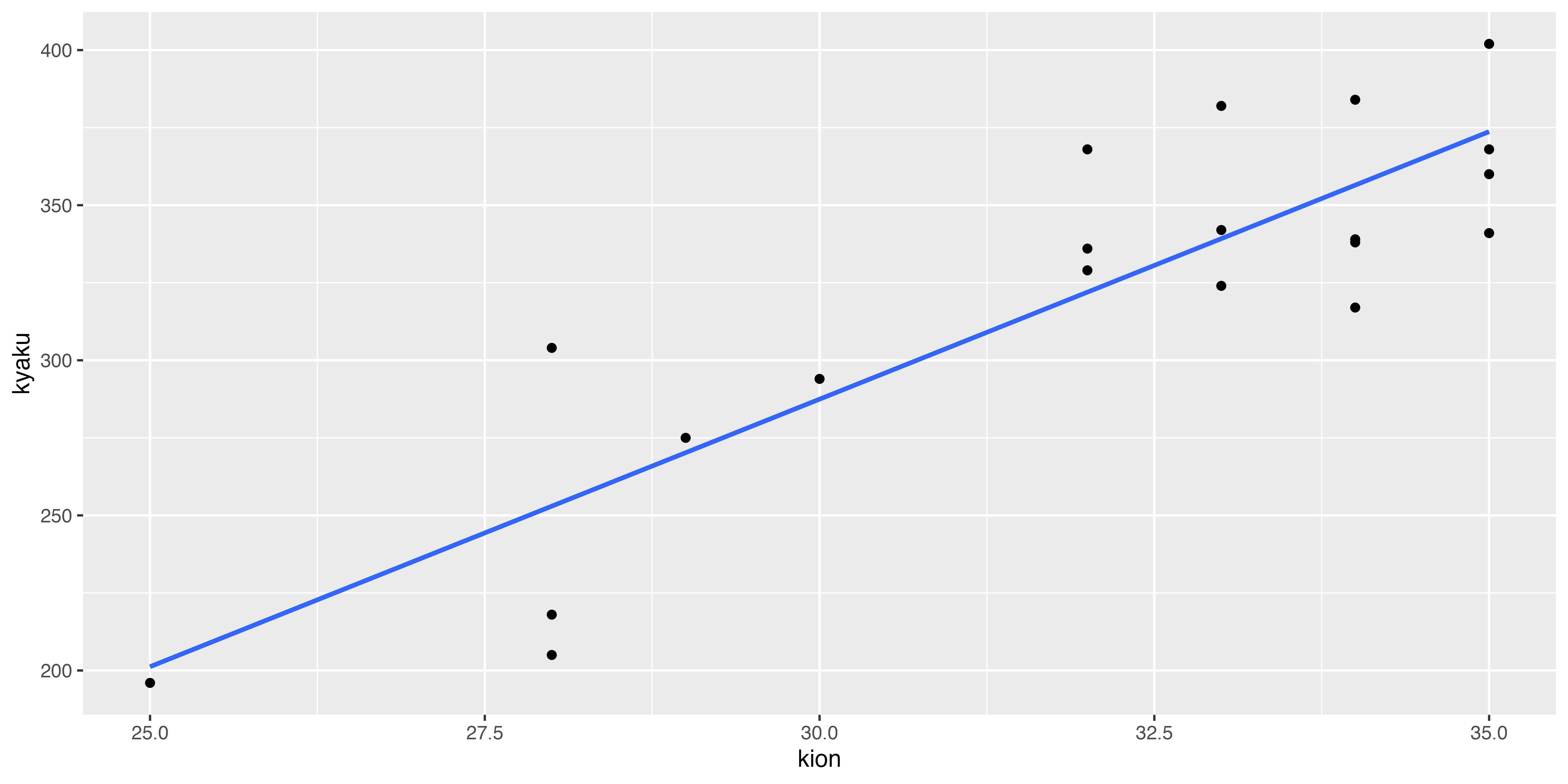
その上でまず,データの散布図と,それにフィットする直線を書いてみます。
ただ相関係数を求めるだけでも二つの変数の関係の強さはわかりますが,こうして関係を要約するような直線を引くことで,別のサンプルに対する予測値を出すことができます。
\[ y_i = \beta_0 + \beta_1x_i+u_i \]
\(\beta_0\)は切片,\(\beta_1\)は傾き。\(u_i\)は誤差。個々の点と直線の乖離
例
アイスクリーム屋さんの客数(y,単位は人)とその日の最高気温(x,単位は℃)には以下の関係があると推定できたとします。
\[ y = 100+10x \]
このような式が推定できると,例えば最高気温20度の日には300人,30度の日には400人の来客があると予測できます。この予測を元にアルバイトの人数や時間数,仕入・仕込みの量を調整することができます。
この直線は,以下で紹介する最小二乗法を使って推定するが,限られたデータ(サンプル)を使って推定されたもの。
先ほどのスライドの図表では自動で線が引かれていますが,例えばこんな線もあり得そうでもあります。
g1 <- ggplot(data = ice4, #使うデータを指定
aes(x = kion, y = kyaku)) +
geom_point() + #散布図を作成
geom_smooth(method = "lm", se = FALSE) +
geom_hline(aes(yintercept = 320),
color = "salmon") + #<1>高さ320の水平線
geom_abline(intercept = 150, slope = 5,
color = "yellowgreen")#<2>傾き5,切片150の直線
#散布図にフィットする直線を書く。方法は,線形モデル(lm)
plot(g1)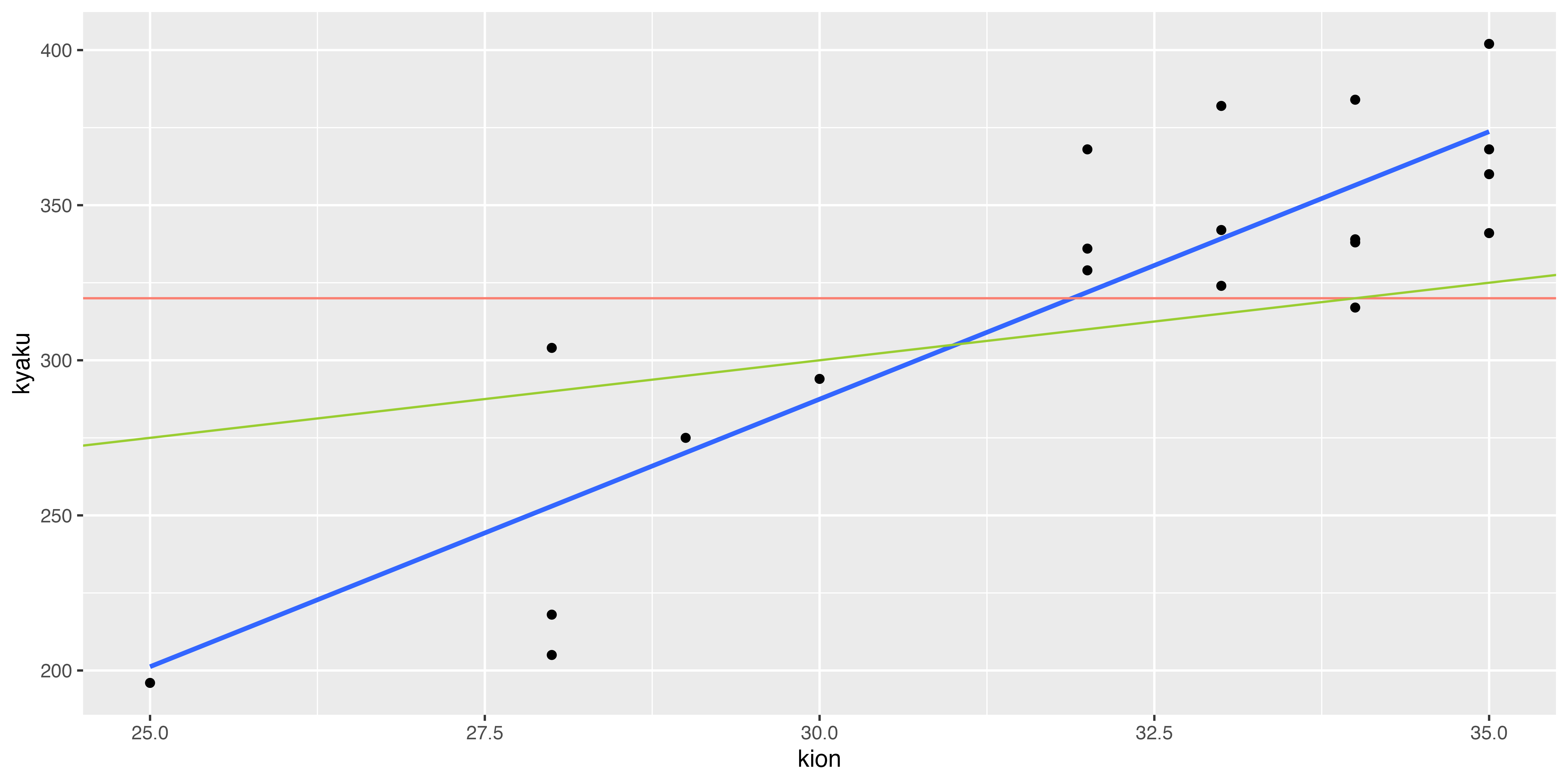
じゃあ,どんな線が最も良い線なのか,それを決めて線を引く,というか線の式を求めるのが回帰分析です。
回帰分析では,最小二乗法という方法で計算します。この方法の考え方は
直線と各データの誤差を最小にする線が最も良い線であろう
というものです。
これは,他の図で矢印になっている誤差を全部足したらしたらゼロになる点を探すことを意味します。±打ち消し合うので \(E(u)=0\) が理想です。
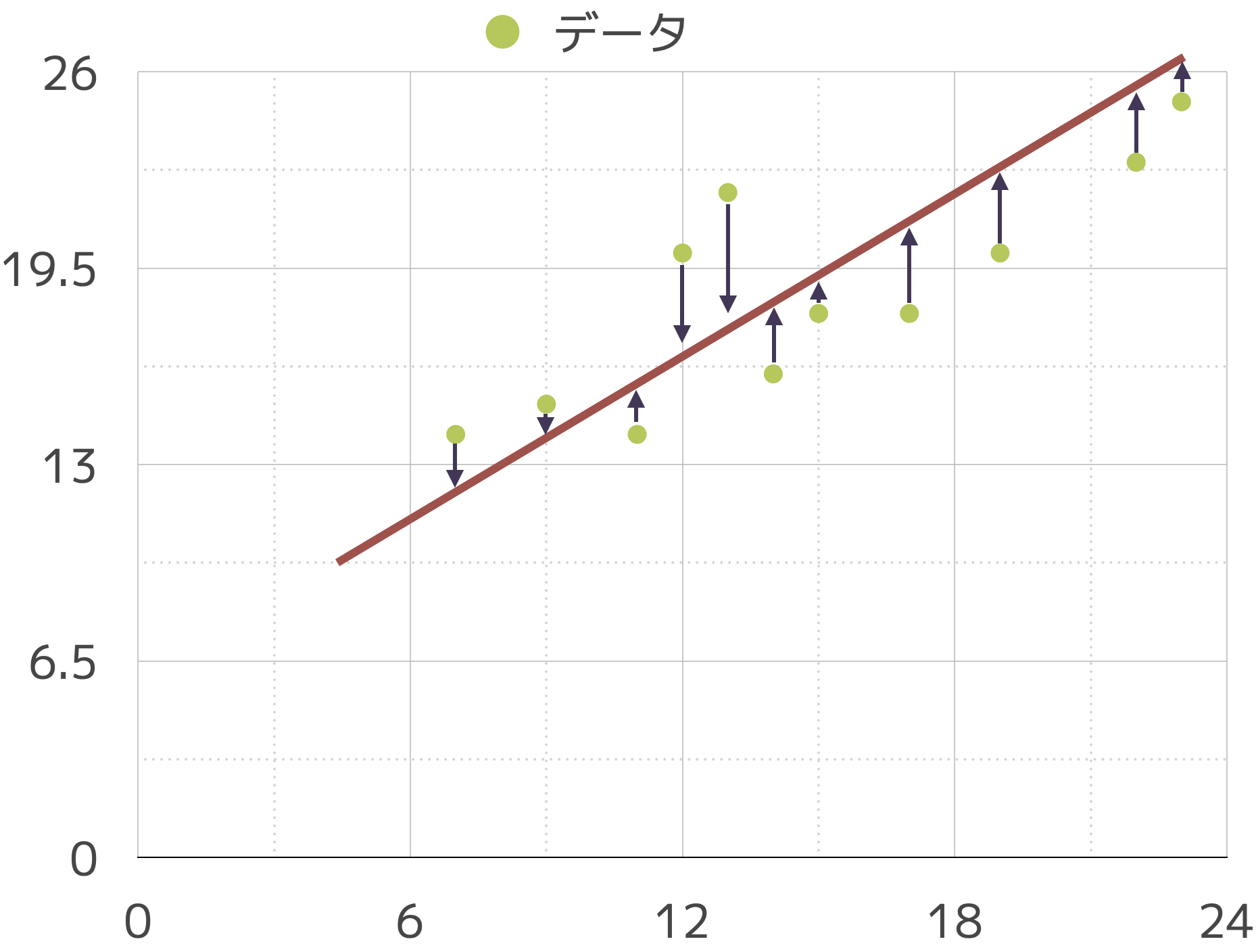
アイス屋さんにおける気温を\(x\),客数を\(y\)とします。気温とアイスの客数にある一定の傾向があるとは予想できますが,一直線上にビタッと並ぶことはなさそうです。
このような,気温以外の要因で販売量が増減する部分を誤差\(u\)とします。すると
\[ y_i = \beta_0 + \beta_1x_i+u_i \tag{1}\]
という直線をイメージしていることになります。ただし添え字の\(i\)はサンプル(散布図の個々の点)です。
このような式では,暗黙的にxを用いてyを予測する,つまりxが原因でyが結果ということを想定します1。
と呼びます。(どちらの言い方も同程度によく聞きます)
Equation 1 において,誤差が最小になるような線を引きたいので, Equation 1 を変形して
\[ u_i = y_i - \beta_0 - \beta_1x_i \tag{2}\]
が最小となる切片\(\beta_0\)と傾き\(\beta_1\)を探すと良いということです。ということは,絶対としての\(u\)が一番小さくなる,つまり\(|u|=0\)が理想的。ただ,絶対値の計算は少し大変なので,それぞれの残差を2乗したものをすべて足しあわせて,それを最小化すれば良い。
数式で表すと
\[ \sum_{i=1}^n \hat{u}_i^2= \sum_{i=1}^n (y_i -\hat{\beta_0}-\hat{\beta_1}x_1)^2 \tag{3}\]
が最も小さくなる\(\beta_0\)と\(\beta_1\)を求めれば良い。2次関数の最小値問題。微分して0,とすると計算しやすいので,\(\beta_0\)と\(\beta_1\)をそれそれ微分して
\[ \begin{equation}\left\{ \, \begin{aligned}&\frac{\partial \Sigma}{\partial \hat{\beta_0}} = \sum_{i=1}^n (y_i -\hat{\beta_0}-\hat{\beta_1}x_1) = 0 \\&\frac{\partial \Sigma}{\partial \hat{\beta_1}} = \sum_{i=1}^n x_i(y_i -\hat{\beta_0}-\hat{\beta_1}x_1) = 0 \end{aligned}\right.\end{equation} \tag{4}\]
という連立方程式を解けば良い。
ヒント
\(\bar{x}=\dfrac{1}{n}\sum_{i=1}^nx_i\)とする
\[ \begin{equation} \left\{ \, \begin{split} &\sum_{i=1}^n (y_i -\hat{\beta_0}-\hat{\beta_1}x_1) = 0 \\ &\sum_{i=1}^n x_i(y_i -\hat{\beta_0}-\hat{\beta_1}x_1) = 0 \end{split} \right. \end{equation} \tag{5}\]
上の式から
\(\begin{split}&\Sigma y_i - n \hat{\beta_0} - \hat{\beta_1}\Sigma x_i = 0 \\\hat{\beta_0} &= \frac{1}{n} (\Sigma y_i - \hat{\beta_1}\Sigma x_i) \\&= \bar{y} - \hat{\beta_1} \bar{x}\end{split}\)
下の式に代入
\(\begin{split}\Sigma x_i \{y_i - (\bar{y} - \hat{\beta_1}\bar{x}) - \hat{\beta_1}x_i\} &= 0 \\ \Sigma x_i \{(y_i - \bar{y}) - \hat{\beta_1}(x_i - \bar{x})\} &= 0 \\\Sigma x_i (y_i - \bar{y}) - \hat{\beta_1}\Sigma x_i (x_i - \bar{x}) &= 0 \\\end{split}\)
ヒントから
\(\Sigma (x_i - \bar{x})(y_i - \bar{y}) - \hat{\beta_1}\Sigma (x_i - \bar{x}) (x_i - \bar{x}) = 0\)
以上より
\[ \hat{\beta_1} = \dfrac{\Sigma (x_i - \bar{x})(y_i - \bar{y})}{ \Sigma (x_i - \bar{x})^2} = \dfrac{ x \mbox{と}y\mbox{の共分散}}{ x\mbox{の分散}} \tag{6}\]
\[ \hat{\beta_0} = \bar{y} - \dfrac{\Sigma (x_i - \bar{x})(y_i - \bar{y})}{ \Sigma (x_i - \bar{x})^2} \bar{x} \tag{7}\]
参考にあるような仮定が満たされている時,最小二乗法によって推定された係数は,不偏で,最も効率性が高い推定量(BLUE; Best liner unbiased estimater)となることが知られています。
この特性からか,最小二乗法はほとんどの統計的分析の基礎となっています。
次に,Rで回帰分析をします。回帰分析は,lm()でやります。()の中には,(従属変数 ~ 独立変数, data = データ名)という内容を書きます。結果は,summary(分析結果)で出ます。
Call:
lm(formula = kyaku ~ kion, data = ice4)
Residuals:
Min 1Q Median 3Q Max
-47.969 -17.709 -1.218 17.413 51.031
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -229.98 73.79 -3.117 0.00596 **
kion 17.25 2.30 7.499 6.08e-07 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 29.54 on 18 degrees of freedom
Multiple R-squared: 0.7575, Adjusted R-squared: 0.744
F-statistic: 56.23 on 1 and 18 DF, p-value: 6.082e-07
Call:
lm(formula = kyaku ~ kion, data = ice4)
Residuals:
Min 1Q Median 3Q Max
-47.969 -17.709 -1.218 17.413 51.031
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -229.98 73.79 -3.117 0.00596 **
kion 17.25 2.30 7.499 6.08e-07 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 29.54 on 18 degrees of freedom
Multiple R-squared: 0.7575, Adjusted R-squared: 0.744
F-statistic: 56.23 on 1 and 18 DF, p-value: 6.082e-07
Estimate: 推定された係数。(intercept)は切片Std. Error: 標準誤差(推定量の標準偏差)t value: 「係数が0」を帰無仮説とする検定のt値。Estimate / Std. Errorで算出されるPr(>|t|) : 「係数が0」を帰無仮説とする検定のp値。有意確率はここで見るSignif. codes: 有意確率に応じて星がつく。R-squaredとAdjusted R-squared: 推定された直線のデータとの当てはまりの良さF-statistic: 全ての係数が0,という仮説のF検定の結果。単回帰分析では,p値は独立変数のp値とほぼ一致Note
p値に出てくる”6.08e-07“は,\(6.08 \times 10^{-7}\)を意味しています。なのでp値は0.001,つまり0.1%よりもかなり低いです。こんな書き方を浮動小数点表記法 floating point expression あるいは,科学的表記法 scientific notation と呼びます。
この推定結果から
\[ kyaku = 17.25kion - 229.98 \]
という式が推定されたことになる。例えば気温が30度の時,
\[ 17.25 \times 30 -229.98 = 287 \text{人} \]
ぐらいの来客があると予測できる。
Rでは,新しいデータ(tibble形式)で,予測したい気温が入ったデータを作り,predict関数を使って算出できる
回帰分析は,未知の母集団における法則性を推定しています。
少ないデータによって未知の母集団を推定しているので,その推定値は必ずしも母集団と一致するわけではありません。
そこで,この母集団を推定するにあたっての性能を統計的に検定することが一般的です。
具体的には,係数が0(つまり関係ない)かどうかを平均値の差の検定と同じt検定で検定します。
たまたま斜めに線が引かれたけど,母集団では関係ない(傾きゼロ)なんじゃないか?
帰無仮説を0とおいたt検定の結果が,先ほどの回帰式でいうt valueとして表示されていて,有意確率が Pr(>|t|)として表示されています。
Call:
lm(formula = kyaku ~ kion, data = ice4)
Residuals:
Min 1Q Median 3Q Max
-47.969 -17.709 -1.218 17.413 51.031
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -229.98 73.79 -3.117 0.00596 **
kion 17.25 2.30 7.499 6.08e-07 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 29.54 on 18 degrees of freedom
Multiple R-squared: 0.7575, Adjusted R-squared: 0.744
F-statistic: 56.23 on 1 and 18 DF, p-value: 6.082e-07気温( kion)の係数は17.25,有意確率は限りなく0に近い(気温と客数に関係がないとする仮説は99.999%の確率で棄却される),つまり気温と客数に関係はありそうだという結論になる。このように,帰無仮説0が棄却されることを「有意」と言います。
分析結果の当てはまり度合いを表す指標(のひとつ)が決定係数 (\(R^2\))
R-squaredとAdjusted R-squaredという2つの種類が表示されているが,とりあえず今日の分析(単回帰分析)では大差ない回帰分析は独立変数(x)を使って従属変数(y)を予測するような数式を推定する分析
\[ y_i = \beta_0 + \beta_1x_i+u_i \]
回帰分析はlm(従属変数 ~ 独立変数 ,data = データ名)で実行可能
Estimate,xがyと関係あるかの検定(t検定)結果の有意確率はPr(>|t|)で確認できるR-squaredで確認できるpredict関数を使って,予測値を算出できる。\[ y = \beta_0 + \beta_1x \]
回帰分析の計算方法の部分で,ヒントとした\(\Sigma^n_{i=1}x_i(x_i-\bar x) = \Sigma^n_{i=1}(x_i-\bar x)(x_i-\bar x)\)となるのは,左辺から
\[ \begin{split} \Sigma^n_{i=1}&x_i(x_i-\bar x) \\ & = \Sigma^n_{i=1} x_i^2 - \bar x \Sigma^n_{i=1} x_i \\ & = \Sigma^n_{i=1}x_i^2 - n(\bar x)^2 \end{split} \]
一方で右辺から
\[ \begin{split} \Sigma^n_{i=1}&(x_i-\bar x)(x_i-\bar x) \\ & = \Sigma^n_{i=1} (x_i^2 - 2 x_i \bar x +(\bar x)^2) \\ & = \Sigma^n_{i=1}x_i^2 -2 \bar x \Sigma^n_{i=1}x_i + (\bar x)^2\\ & = \Sigma^n_{i=1}x_i^2 - n(\bar x)^2 \\ \end{split} \]
論文に書くような結果の表は,modelsummaryパッケージのmsummaryを使うと出力できます。
2024社会調査法(立命館大学)