Code
- 1
- 前の作業など,rのメモリに入っているものをリセットするコマンド
- 2
-
パッケージ管理用のパッケージである
pacmanが入っていない場合はインストール - 3
- 複数のパッケージを一度に呼び出す
- 4
-
日本語で図表を作ったときに文字化けするのを防ぐための処理
2024/04/29
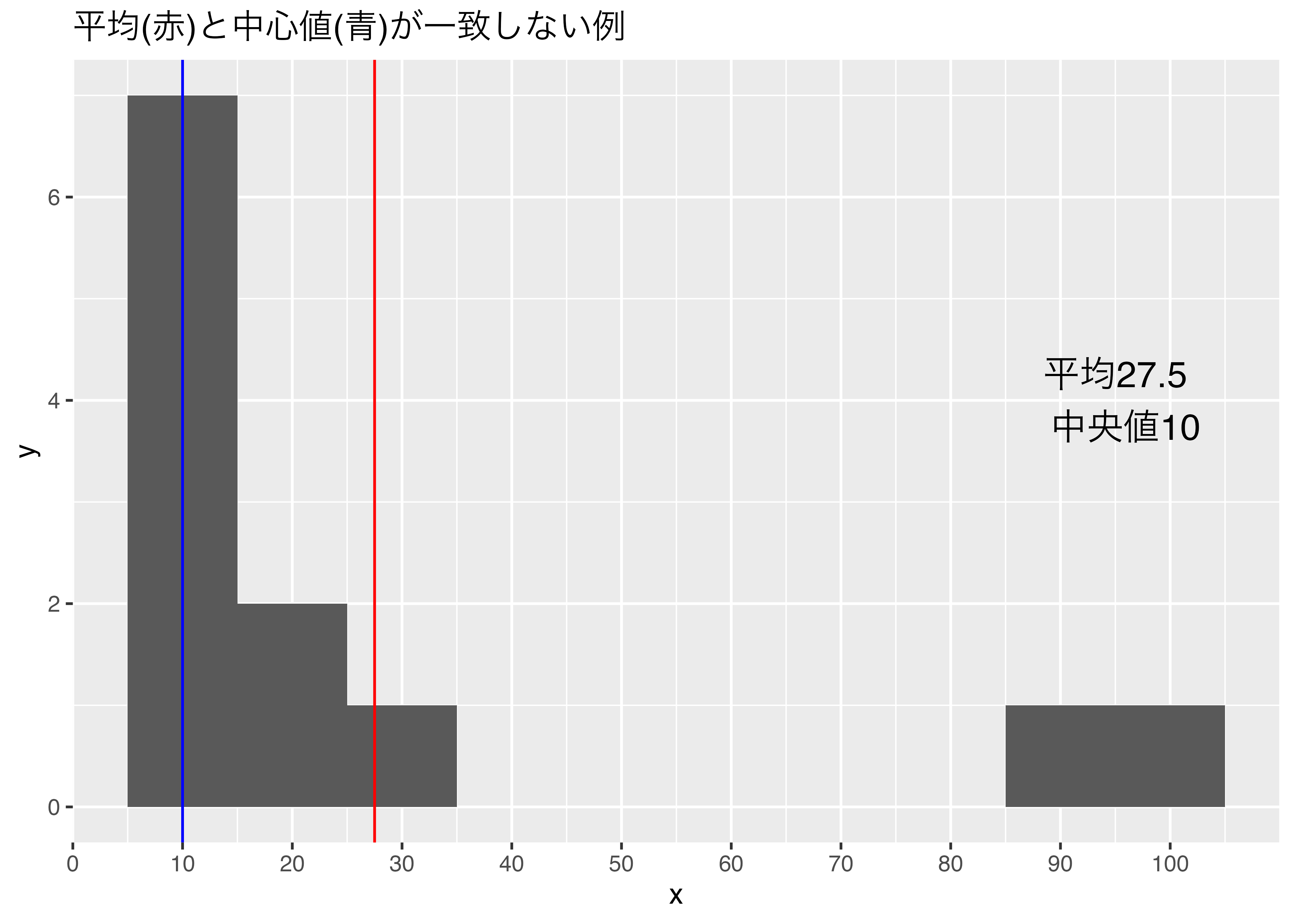
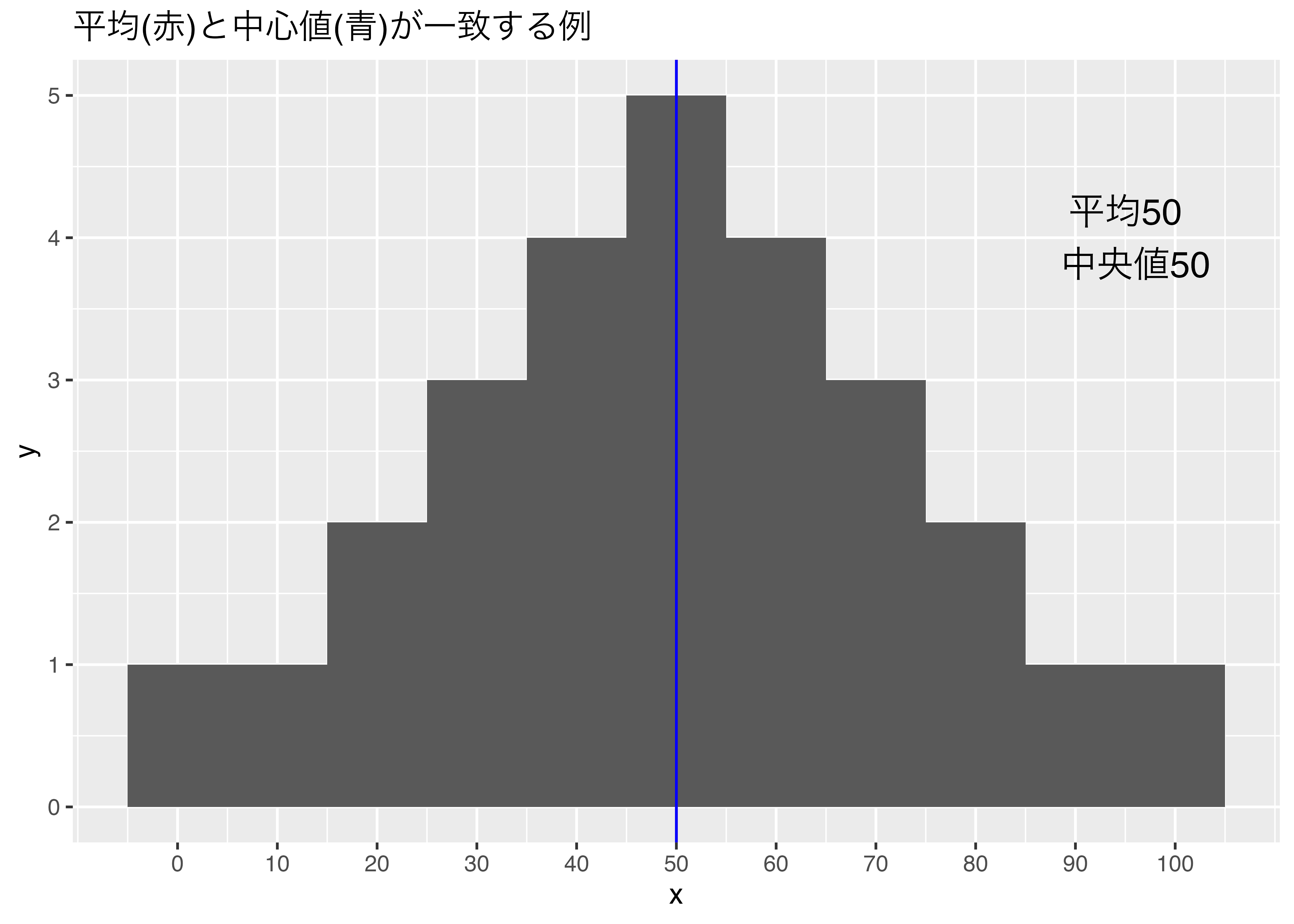
一致する場合もあります。
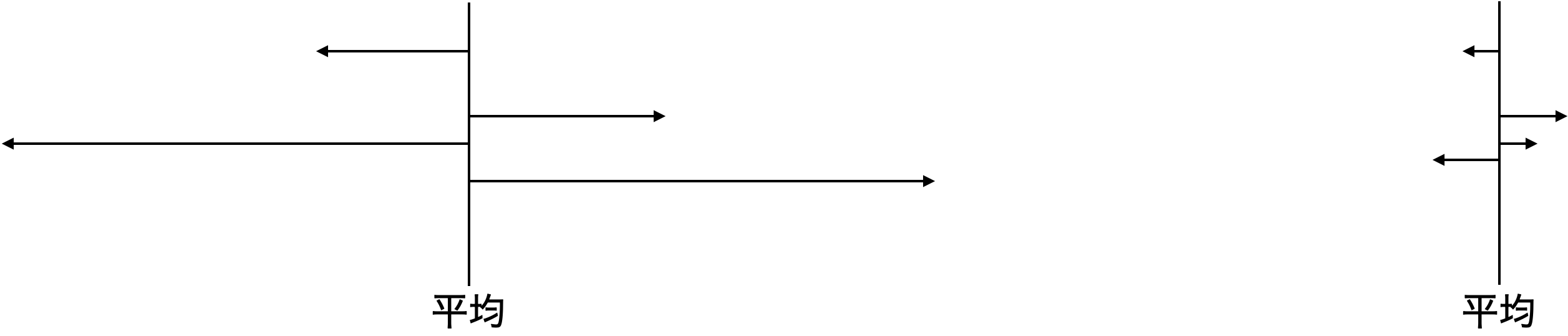
データのばらつき度合いを表します。例えば,A, Bという2つのクラスがあるとします。ある教科のテストの平均,中央値が両クラスとも60だったとしても,
というように得点の分布が全く異なる場合があり得ます。この違いは平均や中央値だけでは読み取れません。この違いを表す,平均からのばらつき度合いを把握する指標が分散です。
平均からの距離 (\(\bar X - X_i\))は,プラスにもマイナスにもなり,足し合わせたら0になってしまうので,これを2乗した\((\bar X - X_i)^2\)をデータの数だけ足し合わせて,データの数で割ったものを分散とします。
\[ Var(X) = \frac{1}{n} \sum_{i = 1}^n(\bar X - X_i)^2 \]
分散は大きければ大きいほどばらつき度合いが高いということを意味します。
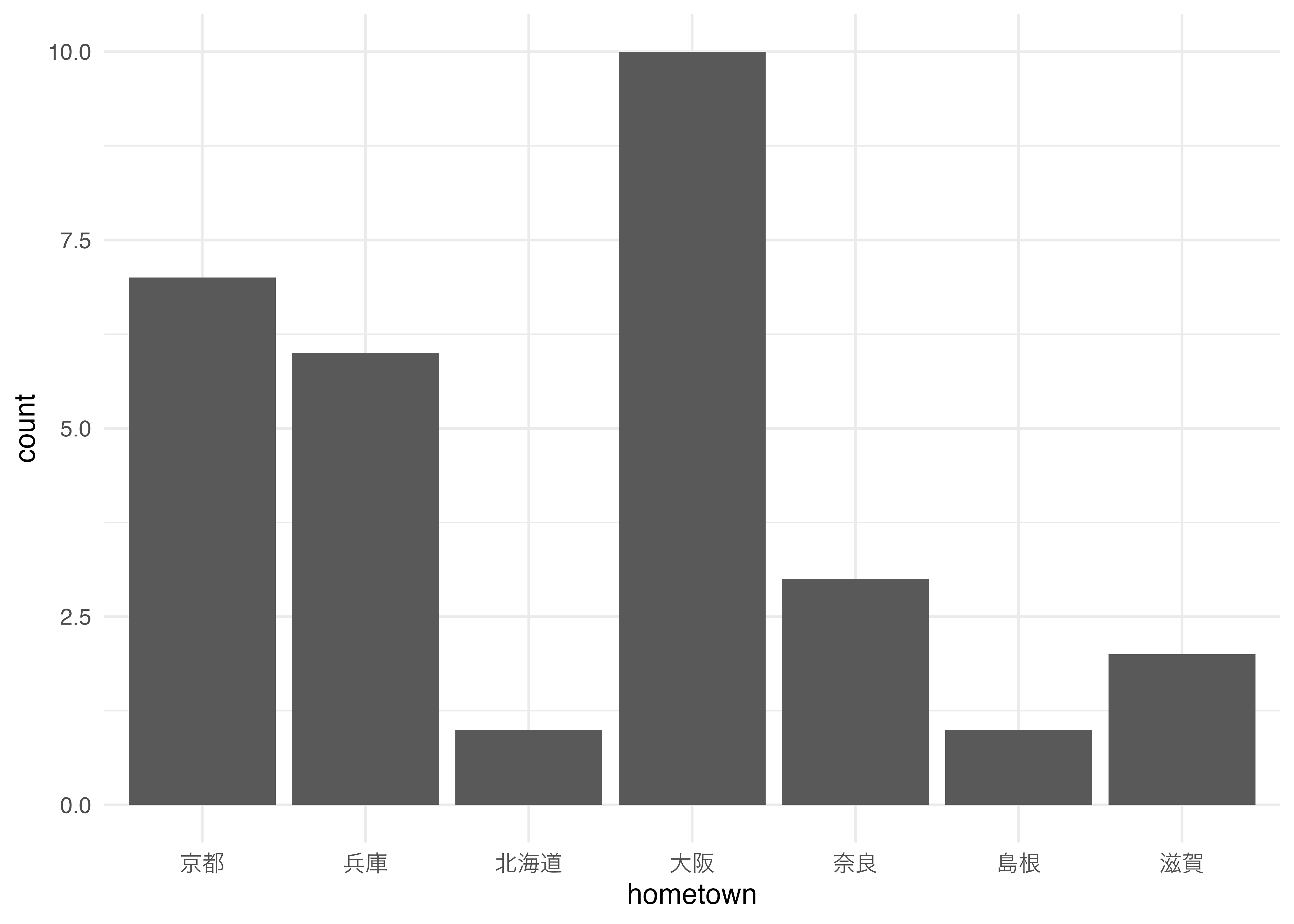
カテゴリごとの度数を棒の高さで表したら棒グラフになります。
割合を見やすくするなら円グラフ
data3 |>
ggplot(aes(x = 1, fill = factor(hometown))) +
geom_bar(stat = "count", color = "black")+
coord_polar(theta = "y")+
theme_minimal(base_family = "Sans") +
theme(panel.grid = element_blank(),
axis.title = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank()) +
geom_text(stat = "count",
aes(x = 1, y = after_stat(count),
label = after_stat(count)),
position = position_stack(vjust = 0.5)) 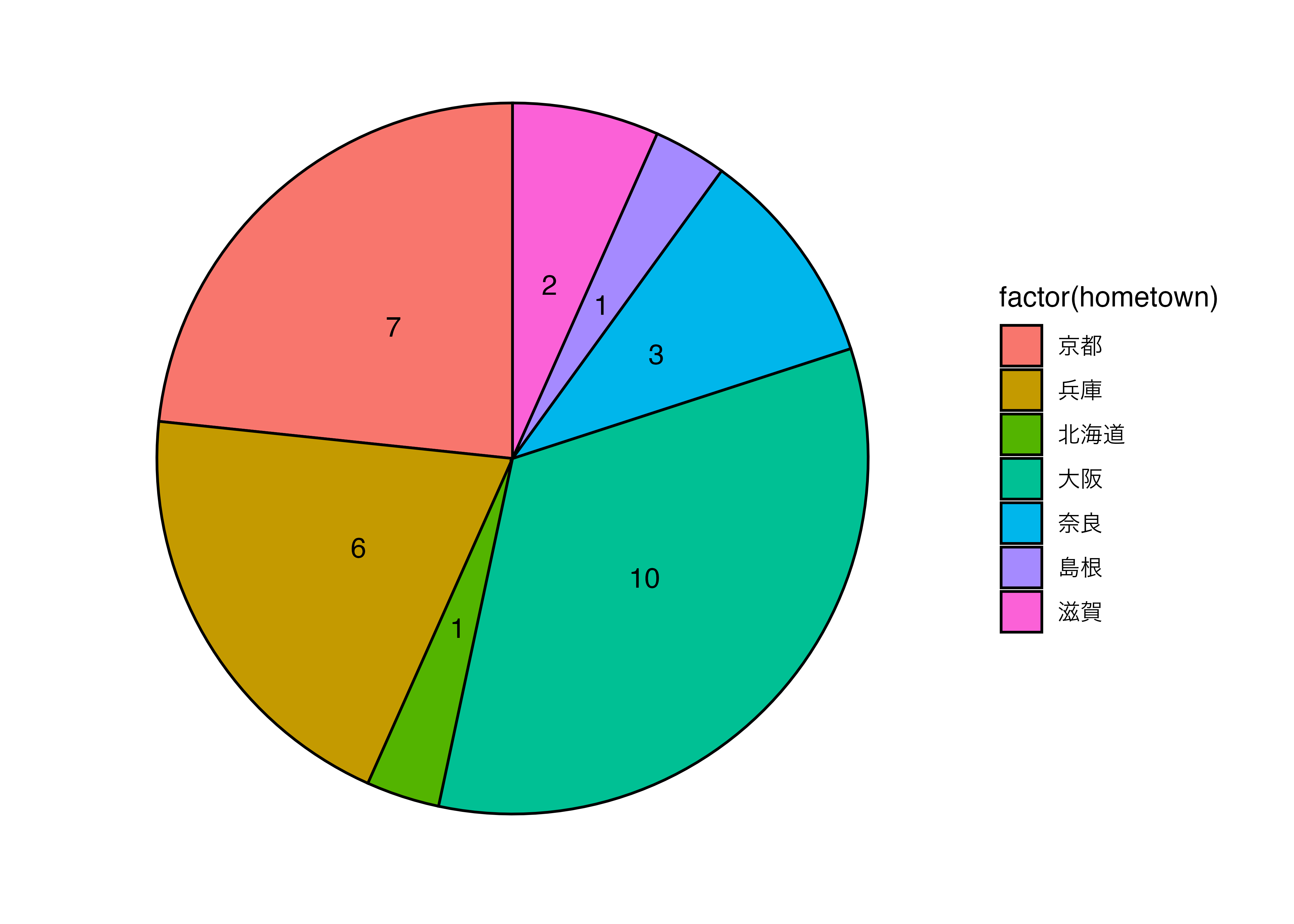
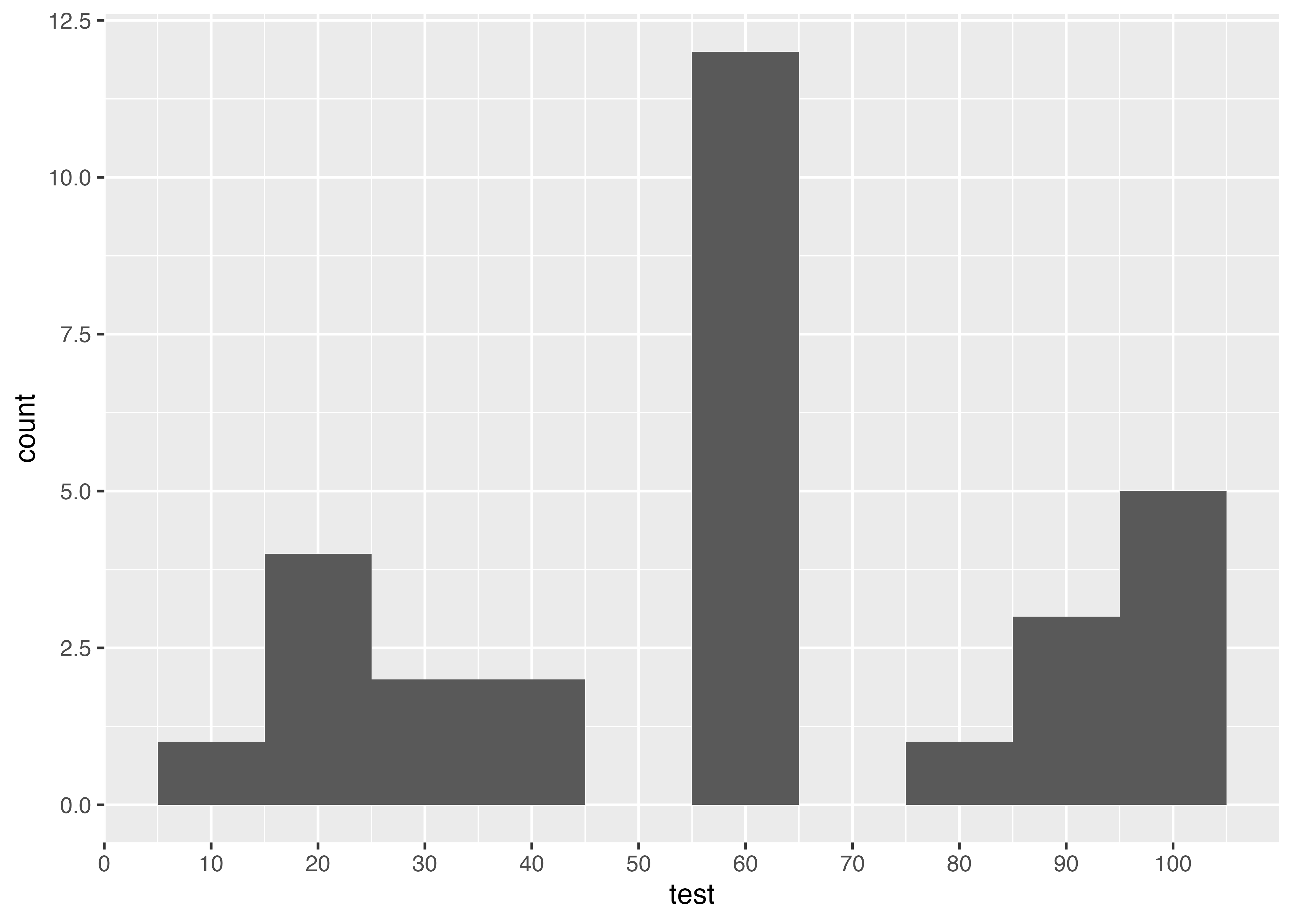
特定のカテゴリごとの度数がわかるグラフです。例えばテストの点数なら,特定の範囲にどれぐらいの人がいるかがわかります。棒グラフとは違って,連続的な変数をある一定の範囲で区切っています。
例えば,グループごとに色分けする
data3 <- data3 |>
mutate(class = as.factor(class))
data3 |>
1 ggplot(aes(test, fill = class)) +
geom_histogram(breaks = seq(5, 105, 10)) +
scale_x_continuous(breaks = seq(0, 100, 10))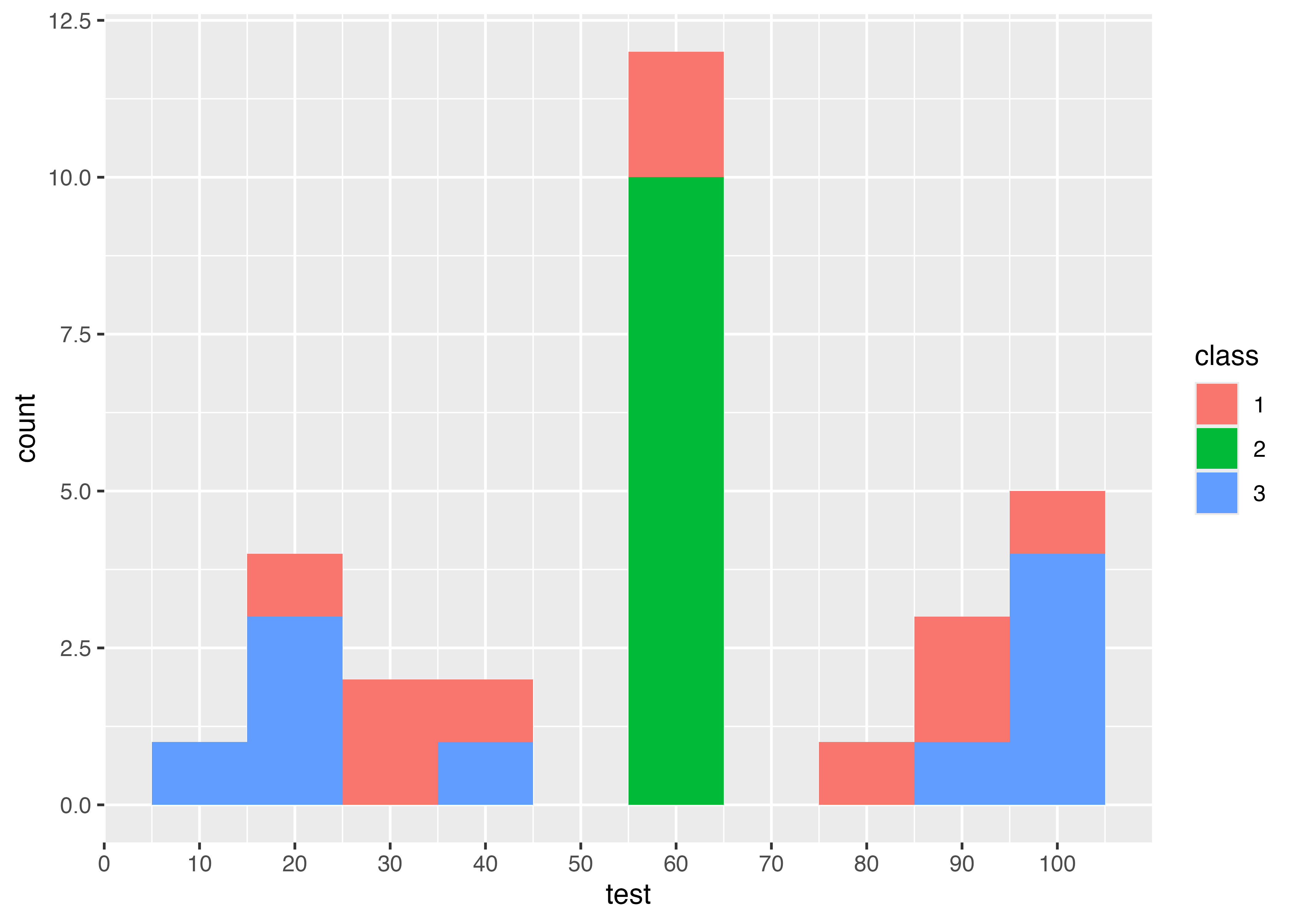
クラスごとに分けて作成
data3 %>%
ggplot(., aes(test)) +
geom_histogram(breaks = seq(5, 105, 10)) +
scale_x_continuous(breaks = seq(0, 100, 10)) +
1 facet_grid(~class)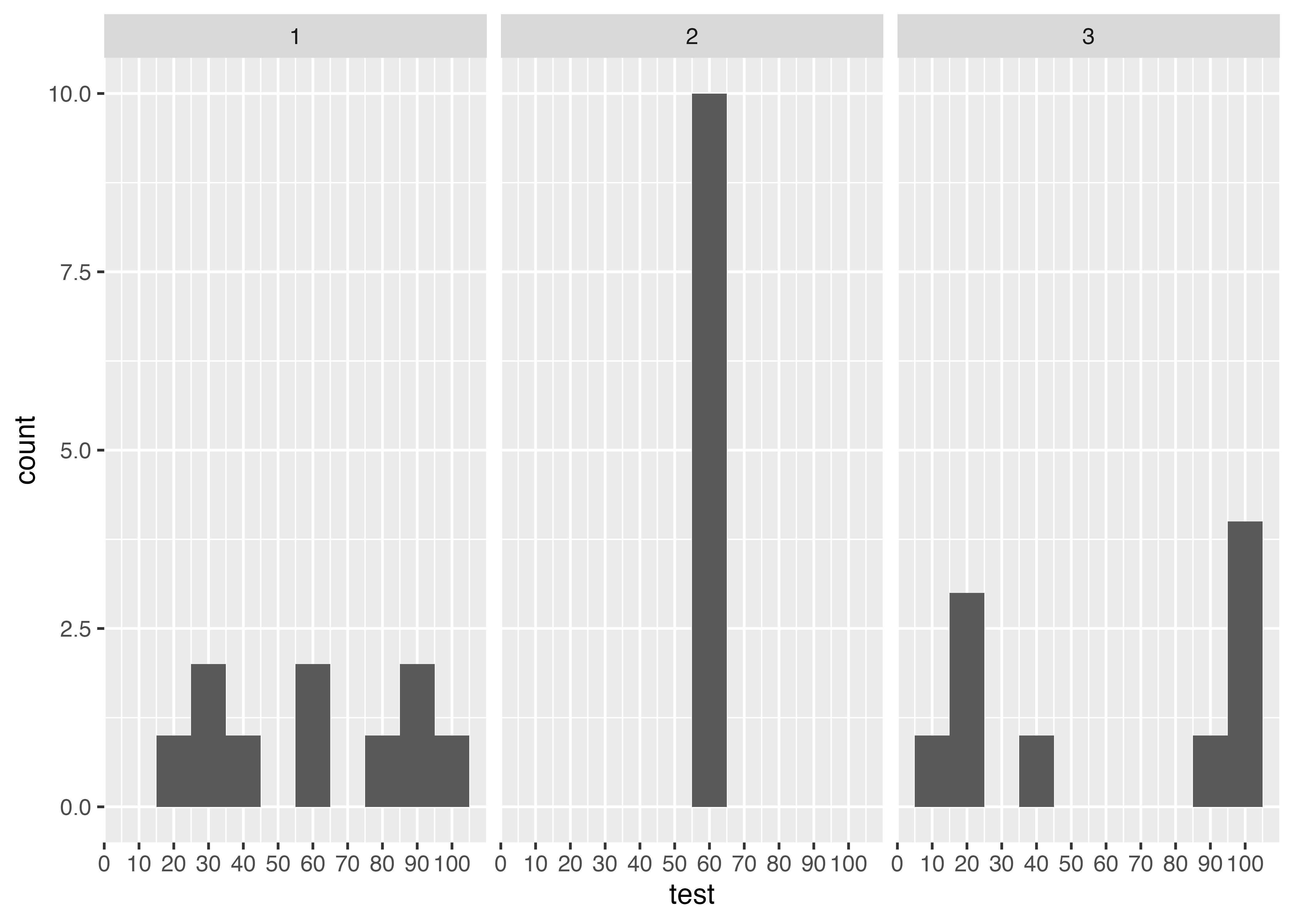
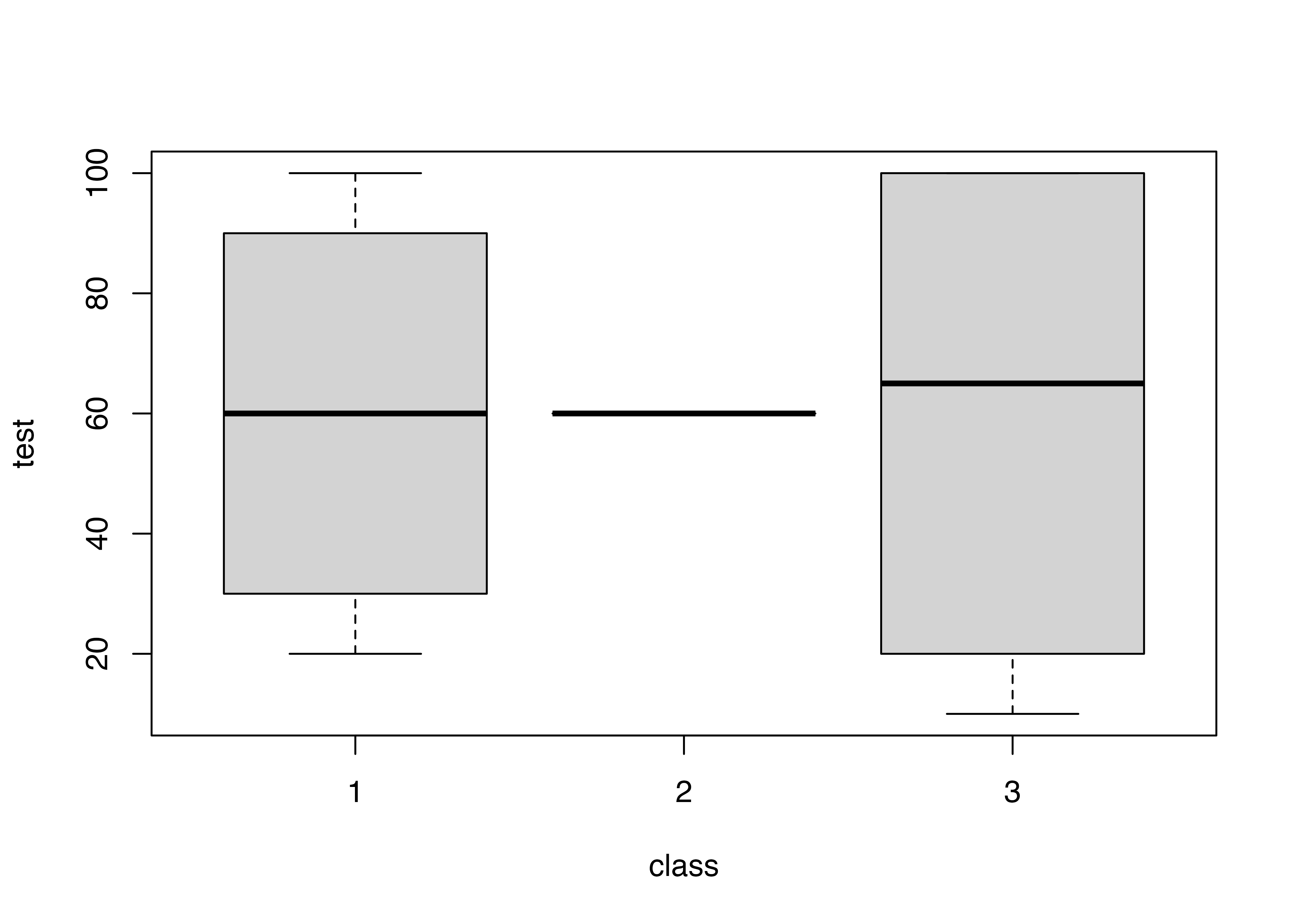
これだと,平均がどれも60点の3クラスだけど,得点のばらつき度合いが大きく違う,ということがわかりやすいです。
複数のグループごとの中央値やばらつき度合いを視覚的に表現できます。ここでは,クラスごとのテストの点数の箱ひげ図を書きます。
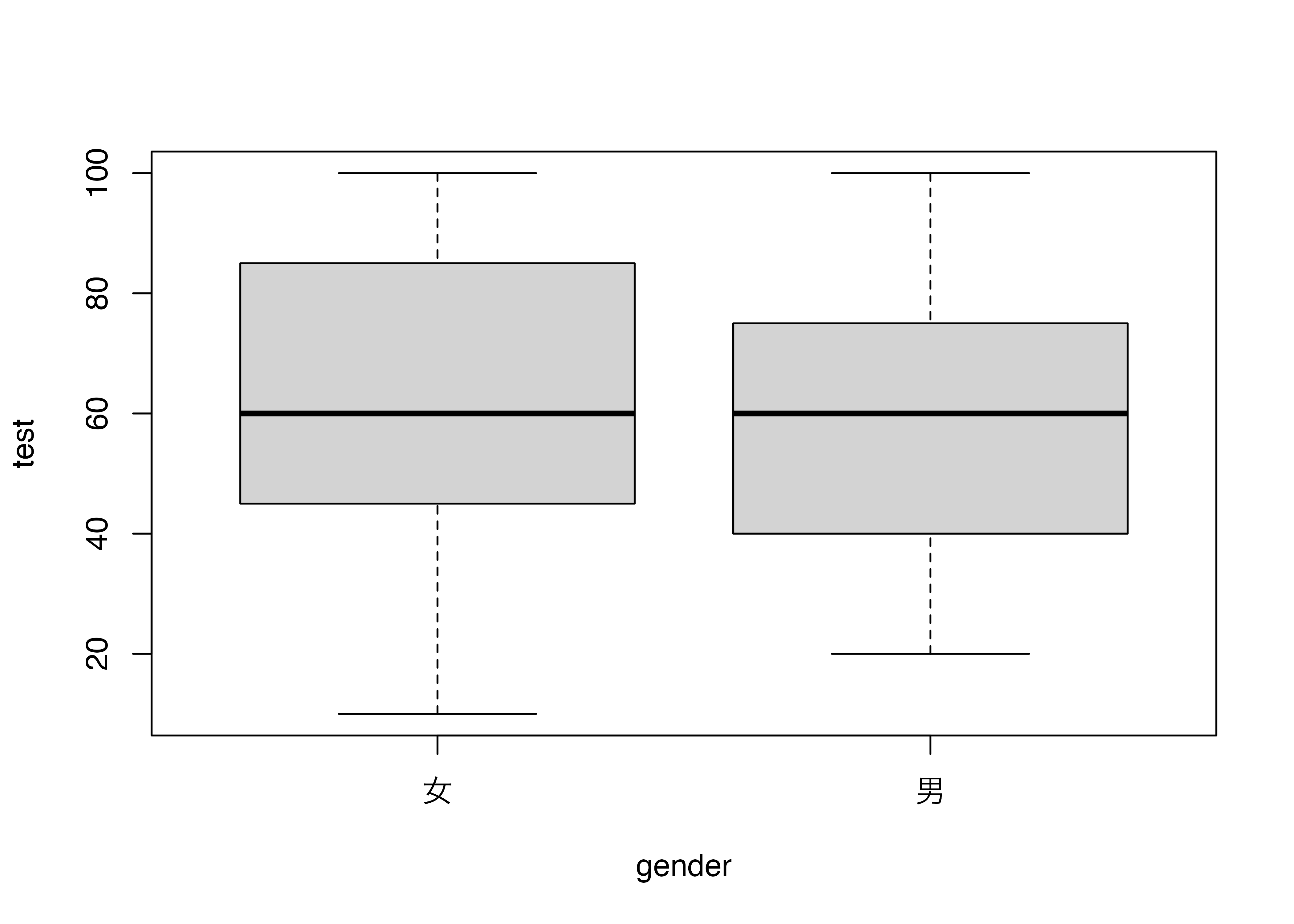
男女別に分ける
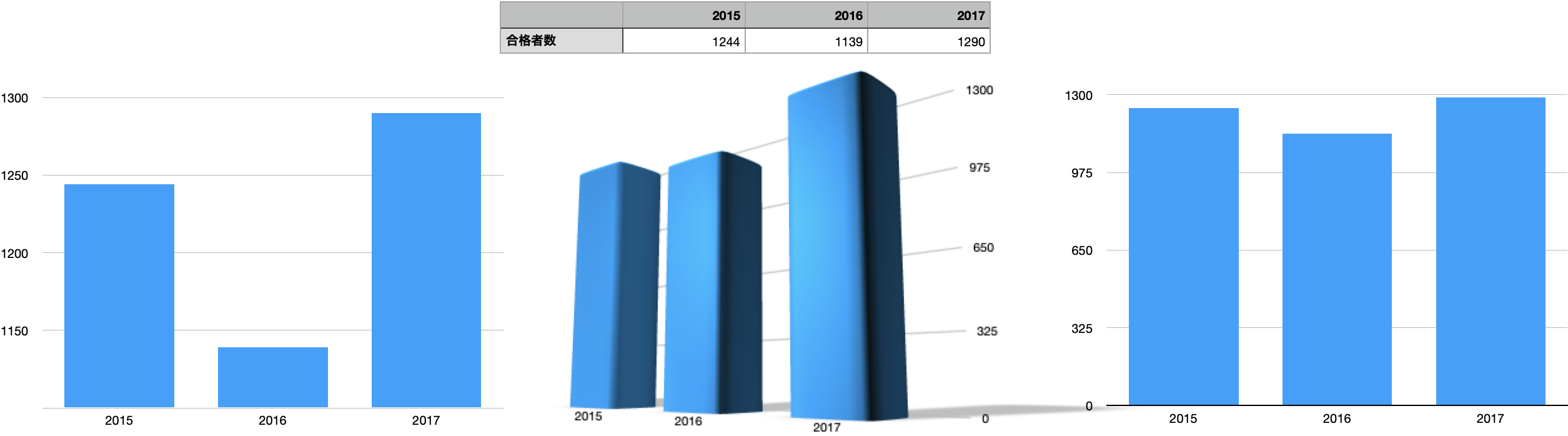
これらは全部同じデータから作った棒グラフです
リンクは,実態を歪んでみせるような可視化方法,いわゆる詐欺グラフを集めたnoteです。悪い例がたくさん載っています。表示の仕方で事実の受け取り方を操作しようという悪質な試みです。特に注意する点は,