- 1
- パッケージの読み込み
- 2
-
3_test.csvというファイルをtestという名前でRに読みこませる
3 調査方法・データの種類
2024/04/22
1.1 調査の目的
- 現状を知る
- 問いを明らかにする、特に因果関係を見つけるようなことを目指して調査が行われます。

1.2 調査の方法
- 調査の方法にはさまざまなものが
- 実験
- アーカイバルデータ分析
- アンケートデータ分分析
- 観察データ分析
- インタビューデータ分析
- この授業では、統計的な処理のできる定量データを扱います。
- ただし、文字データはテキストマイニングなどの方法で定量データ化が可能ですが本授業では扱いません。

1.3 データの分類
1.3.1 定量的データ
- 実験データ
- アーカイバルデータ
- アンケートデータ1
- 定量的観察データ
1.3.2 定性的データ
- 定性的観察データ
- インタビューデータ

2 データ解析

2.1 データ解析の目的
得られたデータは,解析され,色々な役に立てられます。 大きく分けて,予測と発見があると言われています。


2.2 予測
現在のデータを使って,別の場所・時間の傾向を予測するのに役立つ
- 天気予報
- 過去の気象データから,将来の天気を予測する
- 株価予測
- 過去の企業業績・計画・為替・世界情勢等のデータから,企業の株価を予測する
- 販売予想
- 過去の販売実績・顧客アンケート・競合他社のデータ等からある製品の今期の販売数を予測する
予測をするには,データを使った原因と結果の特定が必要
- データは以後の因果関係を仮定したり理解したりが必要で,(少なくとも現代の)AIに任せることはできない
2.3 発見
例えば,データをいくつかのグループに分ける。
- 性別ごとに分ける
- 年代ごとに分ける
- 国籍ごとに分ける
あらかじめ分け方が決まっていない場合には,データ自身にグループを作成させるクラスタリングを行う
- 想像していなかったグループが見つかることも
3.2 データの種類
データ(変数)はその性質に応じて分類が可能です。
- 観測値が数値となるような変数を量的変数,量的変数について計測されたデータを量的データと言います。
- 属性や項目,カテゴリなどを便宜的に数値データとしたようなものを質的変数,計測されたデータを質的データと言います。
- 質的変数
-
「分類する」変数
数字の大小比較に意味がない
例:血液型
- 量的変数
-
数字そのものが意味を持っている
数字の大小比較に意味がある
例:身長

4 データセットの形式

5 データセットの種類
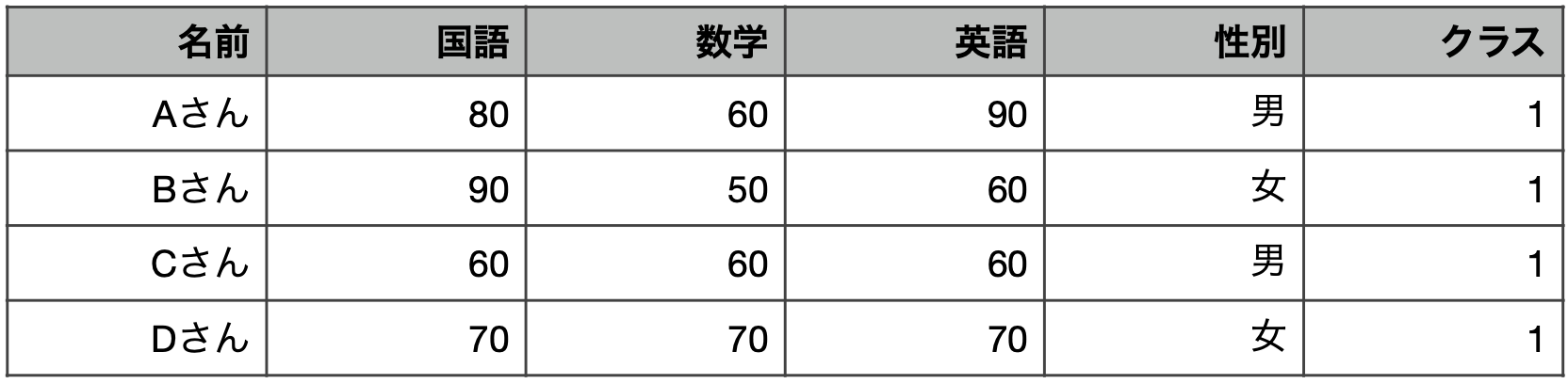
5.1 クロスセクションデータ
- 測定単位がそれぞれ独立しているデータ。
- 例えば,
- 1回だけとったアンケート
- 1回だけやった学力テスト
- 1時点の傾向がわかる
- 例えば,
5.2 時系列データ
- 1つの測定対象に対して複数時点でとったデータ
- 時系列変化がわかる
](images/t3-5.png)
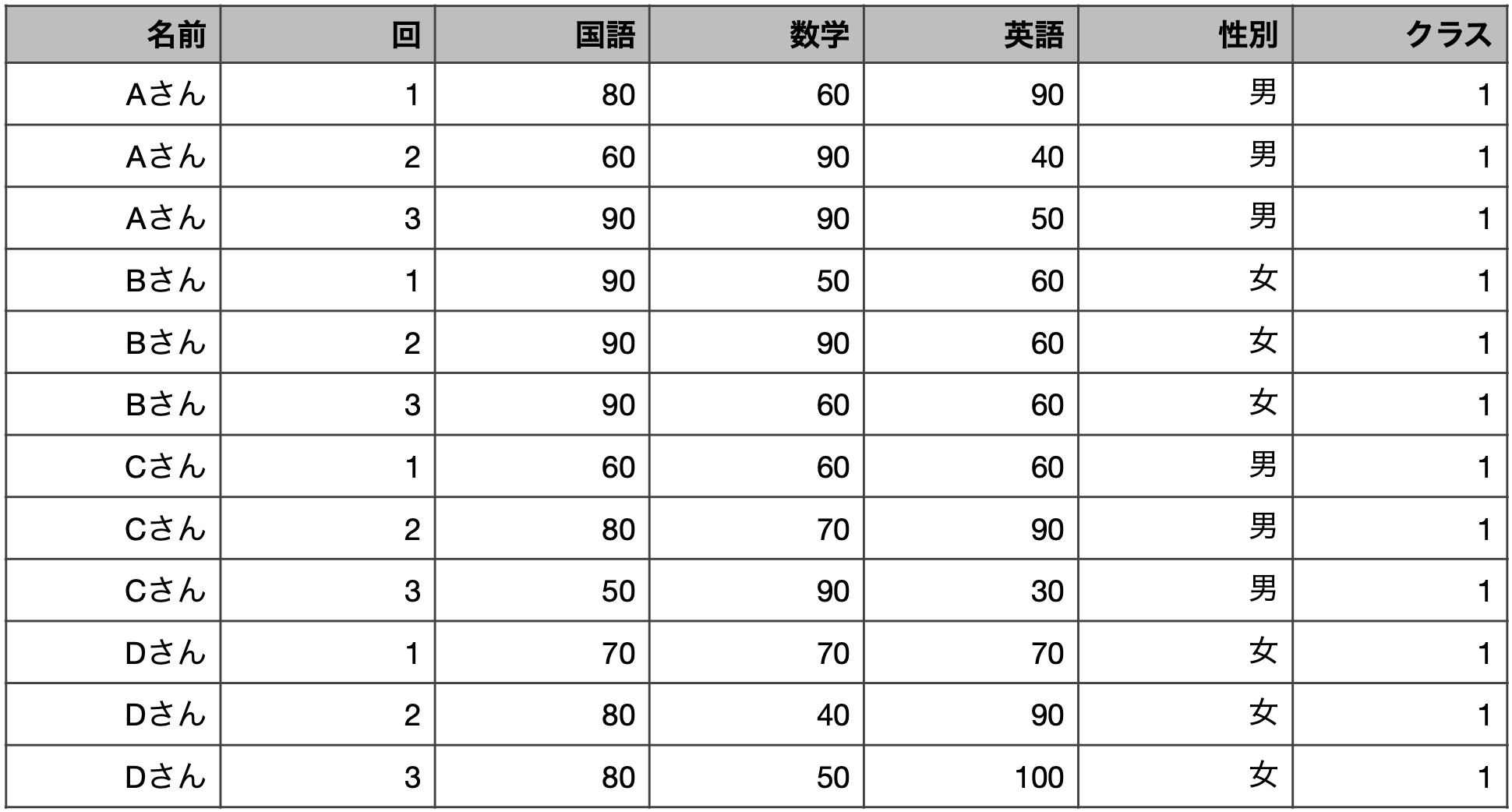
5.3 パネルデータ
- 複数の測定対象に対して,複数時点でとったデータ
- クロスセクション × 時系列
- いろんなことがわかる
5.4 まとめ(データセットの種類)
