Code
- 1
-
複数のパッケージを一度に読み込める
pacmanパッケージが入っていない場合は,インストールする - 2
- パッケージの読み込み
2024/07/01
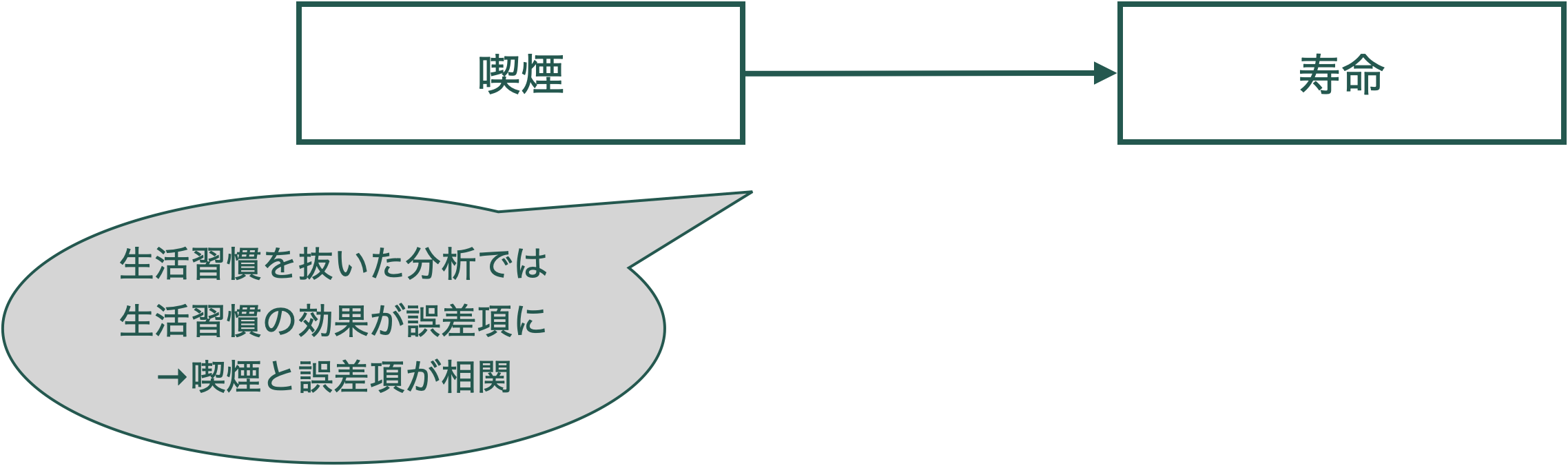
xがyの原因となる


「国民健康・栄養調査」による年齢別の身長・体重データ
Call:
lm(formula = Height_m ~ Weight_m, data = height_weight)
Residuals:
Min 1Q Median 3Q Max
-19.024 -6.791 1.333 6.576 12.108
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 84.79730 2.43480 34.83 <2e-16 ***
Weight_m 1.33911 0.04636 28.89 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 7.615 on 60 degrees of freedom
Multiple R-squared: 0.9329, Adjusted R-squared: 0.9318
F-statistic: 834.5 on 1 and 60 DF, p-value: < 2.2e-16身長と体重は有意に正の関係がある。
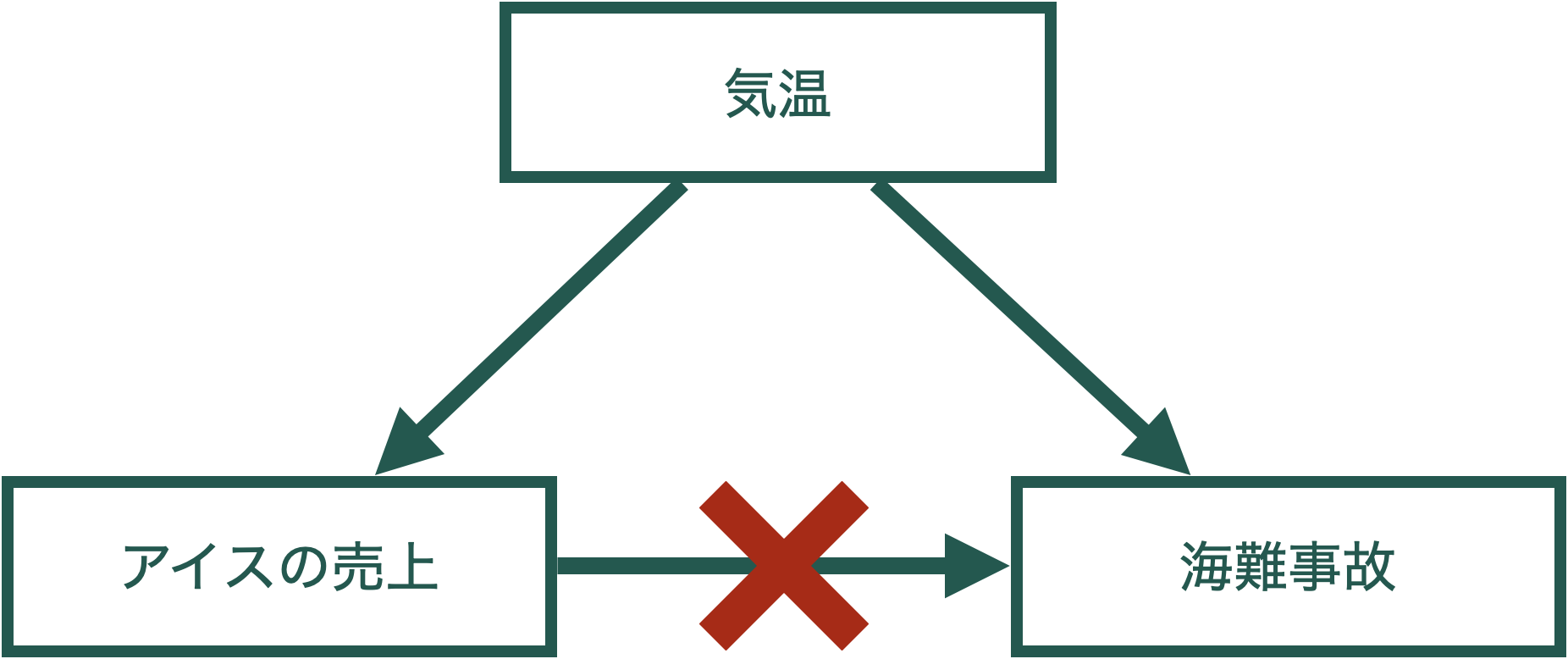
でも,これは明らかに因果関係ではない。
おそらく単なる相関関係
偶然相関があるように見える

人口あたりのチーズの消費量とベッドシーツに絡まって死ぬ人の数

アメリカの科学・宇宙・テクノロジーに対する支出と首吊り,絞殺,窒息による自殺者数
つまり…
単に相関を計算したり,回帰分析をしただけではx → yという因果関係はわからない。
仮に薬の効果を知りたいとしたら,薬を投与した人と投与しない人1人ずつのその効果(例えば血液検査の結果数値など)を比べる?

適切な比較はできない
本来的には薬の効果(薬と症状改善の因果関係)は「同じ人が投与した場合と投与していない場合」を比較しないといけない。

でも,現実に観察されるのはどっちか。薬ありもしくは薬なしどっちかのデータしか取れない。
パラレルワールド・タイムマシンがない限り実現できない。反実仮想が必要。因果推論の根本問題とか言われる
たくさんの参加者を集めて,その人たちにランダムに処置(投与するかしないか)を割り振る
ランダムに割り振った集団間の比較をすることで薬の「平均的な」効果を推定することができる

(星野, 田中, and 北川 2023 , CRESCO Tech Blog)
# 平均値、分散を指定していい感じに作る
a_male <- round(rnorm(n = 160, mean = 60, sd = 10), 0)
a_female <- round(rnorm(n = 40, mean = 75, sd = 10), 0)
b_male <- round(rnorm(n = 40, mean = 55, sd = 10), 0)
b_female <- round(rnorm(n = 160, mean = 70, sd = 10), 0)
# その後、四捨五入しているので結局、微調整を手でしています。
a_male <- c(
45, 63, 55, 68, 60, 66, 64, 71, 46, 56,
71, 60, 42, 46, 53, 68, 72, 56, 64, 46,
47, 66, 65, 55, 55, 49, 66, 60, 44, 64,
60, 60, 34, 66, 63, 58, 62, 45, 66, 66,
60, 64, 53, 58, 69, 59, 65, 55, 58, 57,
76, 56, 67, 56, 76, 34, 53, 67, 49, 63,
59, 44, 53, 63, 48, 59, 60, 66, 53, 58,
40, 49, 56, 63, 57, 55, 74, 58, 61, 68,
74, 63, 64, 68, 77, 49, 69, 69, 63, 56,
67, 54, 49, 79, 60, 62, 63, 71, 71, 57,
56, 70, 81, 81, 58, 57, 54, 69, 64, 70,
56, 62, 66, 85, 63, 75, 59, 68, 65, 57,
59, 69, 91, 78, 59, 60, 55, 48, 52, 55,
52, 57, 70, 70, 58, 45, 49, 61, 46, 64,
50, 57, 71, 65, 47, 69, 59, 72, 49, 54,
71, 33, 61, 66, 53, 49, 47, 61, 57, 48)
a_female <- c(
80, 73, 92, 98, 75, 72, 65, 72, 62, 63,
83, 90, 82, 77, 79, 70, 73, 87, 72, 76,
70, 76, 82, 72, 67, 68, 71, 54, 78, 74,
90, 91, 74, 64, 63, 74, 77, 89, 63, 62)
b_male <- c(
56, 64, 61, 60, 53, 66, 65, 51, 50, 54,
50, 52, 51, 59, 59, 52, 61, 72, 42, 55,
42, 58, 49, 59, 60, 36, 75, 48, 34, 64,
53, 62, 46, 60, 47, 54, 59, 49, 55, 57)
b_female <- c(
90, 80, 62, 73, 60, 76, 75, 68, 82, 82,
67, 79, 71, 81, 54, 82, 65, 77, 71, 61,
62, 76, 71, 76, 62, 90, 55, 64, 83, 92,
66, 90, 71, 66, 80, 57, 63, 65, 71, 62,
55, 52, 68, 72, 79, 81, 76, 65, 65, 76,
75, 85, 74, 60, 59, 67, 63, 64, 81, 84,
81, 81, 55, 76, 80, 69, 84, 57, 78, 72,
63, 72, 82, 79, 58, 73, 52, 57, 58, 69,
73, 70, 83, 76, 58, 92, 65, 65, 65, 59,
80, 78, 68, 61, 64, 78, 62, 69, 81, 65,
91, 79, 68, 74, 68, 67, 81, 83, 67, 92,
67, 84, 75, 67, 67, 53, 62, 55, 68, 74,
65, 77, 75, 70, 68, 56, 74, 60, 65, 61,
54, 69, 68, 71, 67, 62, 66, 80, 69, 74,
69, 59, 69, 79, 69, 64, 67, 56, 66, 78,
85, 83, 53, 56, 56, 80, 53, 55, 70, 53)
# 表を作る関数
create_table <- \(male, female, school){
table_male <- tibble(male) |>
rename(得点 = male) |>
mutate(性別 = "男性")
table_female <- tibble(female) |>
rename(得点 = female) |>
mutate(性別 = "女性")
return(bind_rows(table_male, table_female) |>
mutate(学校 = school))
}
# A校とB校をユニオンする
data <- bind_rows(
create_table(a_male, a_female, "A校"),
create_table(b_male, b_female, "B校")
) |>
select(学校, 性別, 得点)
data %<>%
group_by(学校,性別) |>
mutate(平均点 = mean(得点)) 共通テストの結果をA校とB校,それぞれ男女別に集計した。男性,女性ともに成績が良いのはA校
ところが,全体を見ると
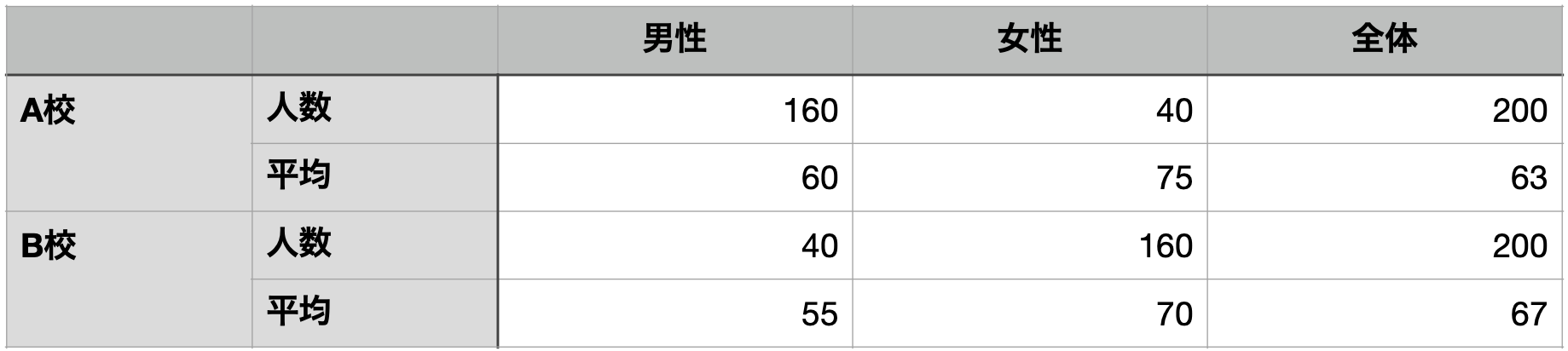
B予備校の方が高い…
これは,「シンプソンのパラドックス」として有名な現象
# プロパティとして使用する項目の関数
properties <- \() {
prop <- NULL
prop$add_mean_A_x <- "平均 A校"
prop$add_mean_A_y <- round(mean(data[data$学校 == "A校", ]$得点), 0)
prop$add_mean_B_x <- "平均 B校"
prop$add_mean_B_y <- round(mean(data[data$学校 == "B校", ]$得点), 0)
prop$add_mean_a_male_x <- "平均 A校"
prop$add_mean_a_male_y <- round(mean(data[data$学校 == "A校" &
data$性別 == "男性", ]$得点), 0)
prop$add_mean_b_male_x <- "平均 B校"
prop$add_mean_b_male_y <- round(mean(data[data$学校 == "B校" &
data$性別 == "男性", ]$得点), 0)
prop$add_mean_a_female_x <- "平均 A校"
prop$add_mean_a_female_y <- round(mean(data[data$学校 == "A校" &
data$性別 == "女性", ]$得点), 0)
prop$add_mean_b_female_x <- "平均 B校"
prop$add_mean_b_female_y <- round(mean(data[data$学校 == "B校" &
data$性別 == "女性", ]$得点), 0)
return(prop)
}
# ggplotで描画する関数
my_ggplot <- \(data, prop) {
g <- ggplot(
data = data,
mapping = aes(
x = data$学校,
y = data$得点)) + # ベースとなるデータの指定
geom_jitter(
size = 4,
alpha = 0.5,
height = 0,
width = 0.2,
mapping = aes(
shape = 性別,
colour = 性別
)
) + # 揺らぎを持たせたグラフ描画
scale_color_manual(values = c("#E60012", "#124DAE")) + # 配色指定
annotate(geom = "point",
x = prop$add_mean_A_x,
y = prop$add_mean_A_y,
size = 4, shape = 15, alpha = 0.7) + # A校の平均
annotate(geom = "point",
x = prop$add_mean_B_x,
y = prop$add_mean_B_y,
size = 4, shape = 15, alpha = 0.7) + # B校の平均
annotate(geom = "point",
x = prop$add_mean_a_male_x,
y = prop$add_mean_a_male_y,
size = 4, shape = 17, alpha = 0.7,
colour = "#124DAE") + # A校男性の平均
annotate(geom = "point",
x = prop$add_mean_b_male_x,
y = prop$add_mean_b_male_y,
size = 4, shape = 17, alpha = 0.7,
colour = "#124DAE") + # B校男性の平均
annotate(geom = "point",
x = prop$add_mean_a_female_x,
y = prop$add_mean_a_female_y,
size = 4, shape = 19, alpha = 0.7,
colour = "#E60012") + # A校女性の平均
annotate(geom = "point",
x = prop$add_mean_b_female_x,
y = prop$add_mean_b_female_y,
size = 4, shape = 19, alpha = 0.7,
colour = "#E60012") + # B校女性の平均
annotate(geom = "text",
family = "Hiragino Sans",
size = 3,
x = c("平均 A校", "平均 B校"),
y = c(prop$add_mean_A_y + 5,
prop$add_mean_B_y - 5),
label = c(paste0("平均 A校:",
prop$add_mean_A_y),
paste0("平均 B校:",
prop$add_mean_B_y))) + # A校の平均
annotate(geom = "text",
family = "Hiragino Sans",
size = 3,
x = c("平均 A校", "平均 B校"),
y = c(prop$add_mean_a_male_y - 5,
prop$add_mean_b_male_y - 5),
label = c(
paste0("平均 A校(男性):",
prop$add_mean_a_male_y),
paste0("平均 B校(男性):",
prop$add_mean_b_male_y))) + # 男性の平均
annotate(
geom = "text", family = "Hiragino Sans", size = 3,
x = c("平均 A校", "平均 B校"),
y = c(prop$add_mean_a_female_y + 5, prop$add_mean_b_female_y + 5),
label = c(
paste0("平均 A校(女性):", prop$add_mean_a_female_y),
paste0("平均 B校(女性):", prop$add_mean_b_female_y))) + # 女性の平均
xlab("学校と平均") + # X軸のラベル
ylab("得点") + # Y軸のラベル
scale_y_continuous(
breaks = seq(0, 100, by = 10),
limits = c(0,100),
minor_breaks = NULL) + # 縦軸の書式設定
theme_minimal(base_family = "Hiragino Sans") + # テーマとフォント
theme(legend.title = element_blank(),
axis.title.x = element_text(size = rel(1.5)),
axis.title.y = element_text(size = rel(1.5)),
axis.text.x = element_text(size = rel(1.5)),
axis.text.y = element_text(size = rel(1.5)),
panel.grid.major.x = element_blank()) # 凡例と縦軸の削除
return(g)
}
# 描画
print(my_ggplot(data, properties()))
アメリカ海軍は第二次世界大戦中,任務を終えて戻った飛行機の損傷箇所を検証
これは生存者バイアスというセレクションバイアスの一つ
, McGeddon (picture), Cameron Moll (concept), CC BY-SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0>, via Wikimedia Commons")

同時性は,従属変数と独立変数が,相互に依存している場合に起きます。
警察官の配置が犯罪抑止にどれぐらい役立つのかを検証しようとしました。地域別の警察官の配置人数と犯罪発生件数のデータを集め,地域\(i\)の警察官の数を\(X_i\),犯罪件数を\(Y_i\)として以下のようなモデルの回帰分析を行いました。
\[ Y_i= \beta_0 + \beta_1 X_i + \epsilon_i \]
分析の結果,Xの係数は有意に正でした。

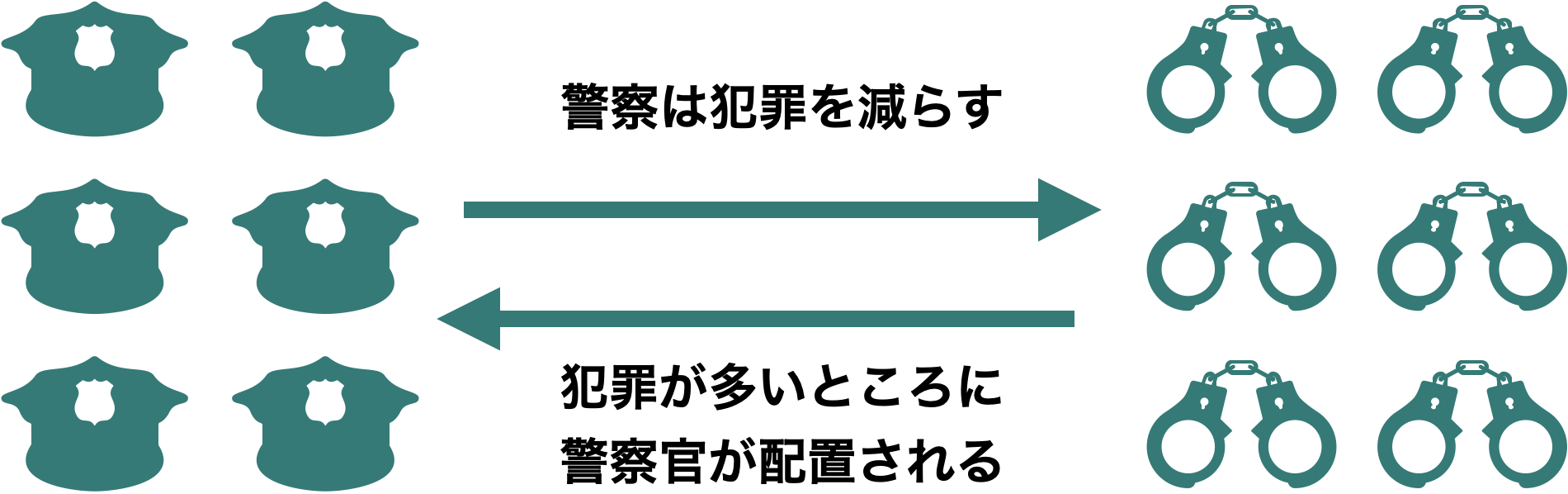
n <- 200
b0 <- 1
b1 <- 2
Estimate <- \(lambda){
e <- rnorm(n)
X <- (1 + lambda * e ) * runif(n)
Y <- b0 + X * b1 + e
lm(Y~X)$coefficient
}
simulate <- \(lambda){
estimates <- matrix(0,100,2)
for(i in 1:100) estimates[i, ] <-Estimate(lambda)
colMeans(estimates)
}
lambdas <-(0:60) / 100
results <- mapply(simulate, lambdas)
bias0 <-results[1, ] -b0
bias1 <-results[2, ] -b1
#par(family= 'Hiragino Sans')
#plot(lambdas, bias0, xlab='λ', ylab = 'バイアス')
#plot(lambdas, bias1, xlab='λ', ylab = 'バイアス')
a <- tibble(lambdas,bias0,bias1)
ggplot(a,
aes(x = lambdas,
y = bias0)
) +
geom_point()+
theme(text = element_text(family = 'Hiragino Sans')) +
labs(title= "切片のバイアス",
x = 'λ',
y = 'バイアス')

