Code
- 1
-
複数のパッケージを一度に読み込める
pacmanパッケージが入っていない場合は,インストールする - 2
- パッケージの読み込み
2024/06/17
pacmanパッケージが入っていない場合は,インストールする
主要なパッケージ
pacman複数のパッケージを読み込めるパッケージ。そのパッケージの中のp_loadコマンドを使うと,()内に指示したパッケージを読み込める。さらにそのパッケージがそもそもインストールされていない場合にはインストールした後に読み込んでくれる
tidyverseRのコードを楽にするたくさんのパッケージをパッケージにしたもの
magrittrtidyverseに含まれる%>%などのコードをさらに拡張するもの。これがあると%$%とか%<>%が使える
回帰分析では,2つの変数間の関係を線形関係(\(y = \beta_0 + \beta_1x\)という形)にモデル化して推定しました。
しかし,ある現象(例えば前回の例だったアイスクリーム屋さんの客数)が,1つの要因(気温)によって決まるということは稀です。
どれが最も重要なのかを知るために,例えば
みたいな形で別々に客数との関係を推定するのはあまり効率的ではありません。そこで使われるのが重回帰分析です。
\[ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + u \]
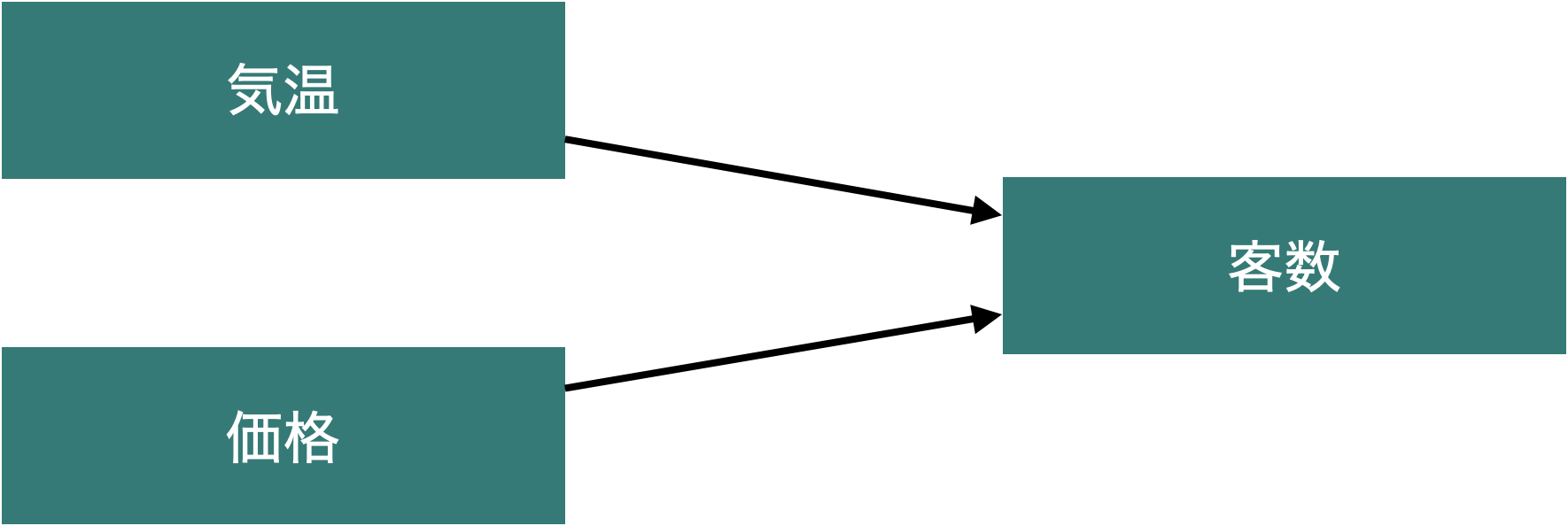
\[ ramen_i = \beta_0 + \beta_1 soup_i +\epsilon_i \]
ramen: ラーメンの総合評価soup: スープの評価
\(\beta_1\)が正で,統計的に有意だった。ここからスープ評価が大事だとわかる。
ここで
スープだけでなく麺の食感も大事でしょう
チャーシューの味や分厚さが大事
味玉の美味しさでラーメン屋の仕事の丁寧さがわかる
とか言ってくる人も?結局どれがどれぐらい大事?
じゃあ関係ありそうな要因を全て入れてみて
\[ ramen_i = \beta_0 + \beta_1 soup_i + \beta_2 men_i + \beta_3 niku_i + \beta_4 negi_i + \epsilon_i \tag{1}\]
とできる1。こうすることで
つまり,上記のような疑問に(ある意味)対処した上でのスープの評価が大事かどうかがわかる。
今回使うのは,以前課題で使ったアイスクリーム屋さんの例です (アイスクリーム統計学より)
データの読み込み
データには,その日の最高気温saikou,最低気温saitei,客数kyakuが含まれています。
| (1) | (2) | |
|---|---|---|
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 | ||
| (Intercept) | -229.982** | 118.600 |
| (73.787) | (151.256) | |
| saikou | 17.248*** | |
| (2.300) | ||
| saitei | 8.100 | |
| (6.029) | ||
| Num.Obs. | 20 | 20 |
| R2 | 0.758 | 0.091 |
| R2 Adj. | 0.744 | 0.041 |
これは,最高気温が客数と有意ににプラスの関係にある一方で,最低気温と客数に関係が見られない,ということを示唆しています。
関連して,普通の相関係数を求めてみる。データのうち,通し番号(Num)は必要ないので,dplyr::select()コマンドで,使う変数(saikou, saitei, kyaku)だけを選択し,そのあとcor()関数を使う。
saikou saitei kyaku
saikou 1.0000000 0.7058315 0.8703519
saitei 0.7058315 1.0000000 0.3019116
kyaku 0.8703519 0.3019116 1.0000000
最高気温と客数は強い正の相関(0.87),最低気温と客数はあまり強くない相関(0.30)最高気温と最低気温も強い正の相関(0.71)
重回帰分析は,単回帰分析の独立変数部分を複数にして,「+」で繋ぐ。
Call:
lm(formula = kyaku ~ saitei + saikou, data = ice10)
Residuals:
Min 1Q Median 3Q Max
-17.274 -9.342 -2.920 10.810 26.392
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -90.640 37.718 -2.403 0.0279 *
saitei -16.703 2.012 -8.301 2.20e-07 ***
saikou 25.957 1.486 17.463 2.71e-12 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 13.52 on 17 degrees of freedom
Multiple R-squared: 0.952, Adjusted R-squared: 0.9464
F-statistic: 168.6 on 2 and 17 DF, p-value: 6.161e-12重回帰分析を先ほどの2本の単回帰分析と並べてみる
| (1) | (2) | (3) | |
|---|---|---|---|
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 | |||
| (Intercept) | -229.982** | 118.600 | -90.640* |
| (73.787) | (151.256) | (37.718) | |
| saikou | 17.248*** | 25.957*** | |
| (2.300) | (1.486) | ||
| saitei | 8.100 | -16.703*** | |
| (6.029) | (2.012) | ||
| Num.Obs. | 20 | 20 | 20 |
| R2 | 0.758 | 0.091 | 0.952 |
| R2 Adj. | 0.744 | 0.041 | 0.946 |
R-squaredとAdjusted R-squaredという2つの種類は大差ないという話だったAdjusted R-squared
回帰から問題のある変数のうち1つを取り除く分散拡大要因 (Variance Inflation Factor: VIF)の値が5または10を上回る変数がないか確認する
今回は問題ない
2024社会調査法(立命館大学)