---
title: "8 規模効果の検証を例とした線形ファクター・モデル入門"
date: 2026/05/29
format:
html: default
revealjs:
output-file: 8_value_slide.html
bibliography: references.bib
---
## この回で新たに学ぶ関数 {data-name="この回の見取り図"}
今回はポートフォリオ・ソートによるCAPMの実証的検証と,Fama-Frenchの3ファクター・モデルを扱う.新しく登場する関数を確認しておこう.
| 関数 | パッケージ | 役割 |
|---|---|---|
| `ntile()` | `dplyr` | データを$n$等分のグループに振り分ける |
| `table()` | base R | クロス集計表を作成する |
| `geom_col()` | `ggplot2` | 棒グラフを描画する |
| `geom_hline()` | `ggplot2` | グラフに水平線を追加する |
| `bind_rows()` | `dplyr` | 複数のデータフレームを縦に結合する |
| `everything()` | `tidyselect` | 残りの全列を選択する(列の並び替えに使用) |
- 前回までに学んだ`lm()`,`tidy()`,`full_join()`,`filter()`,`mutate()`,`group_by()`,`summarize()`,`lag()`なども引き続き使用する.
- 迷ったらこの表に戻って「今どの関数を使っているのか」を確認しよう.
------------------------------------------------------------------------
## ポートフォリオ・ソート(教科書第6.1.2節)
### 時価総額によるポートフォリオ・ソート
- 何らかの特性に基づき各銘柄を順位付けて,その順位に基づいてポートフォリオを構築することを[**ポートフォリオ・ソート**]{style="color: blue"}と呼ぶ.
::: {.callout-note icon="false"}
#### 目標
- ここではその例として前年度末の時価総額に応じて投資ユニバース[^1]を十等分し,その実現リターンを比較してみよう.
:::
{width="80%"}
------------------------------------------------------------------------
### (Step 1) 月次データ`ch05_output1.csv`と年次データ`ch05_output1.csv`の読み込み
```{r}
pacman::p_load(tidyverse, broom)
monthly_data <- read_csv("../simulation_data/ch05_output1.csv")
annual_data <- read_csv("../simulation_data/ch05_output2.csv")
```
------------------------------------------------------------------------
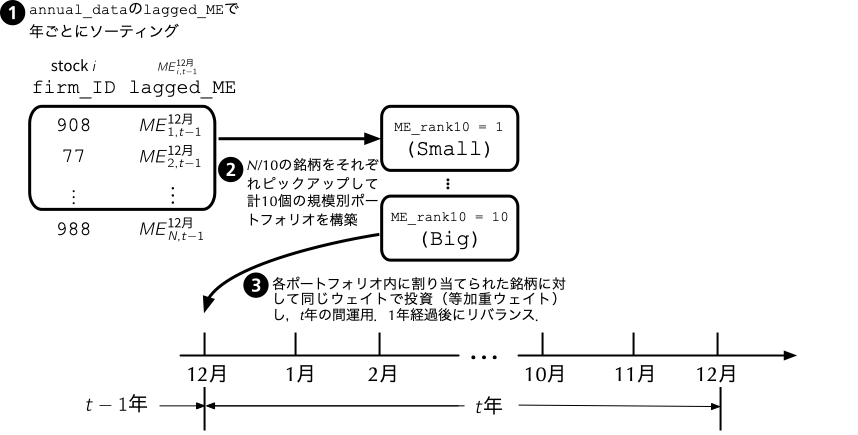
### (Step 2) 前年度末の時価総額`lagged_ME`を追加すると共に,年度ごとに`ME_rank10`という変数名で十分位に振り分け
```{r}
annual_data <- annual_data %>%
group_by(firm_ID) %>% # firm_IDでグループ化
mutate(lagged_ME = lag(ME)) %>% # 前年度末の時価総額を定義
ungroup() %>%
group_by(year) %>% # 年ごとにグループ化
mutate(ME_rank10 = factor(ntile(lagged_ME, 10))) %>% # ntile()関数を用いて十個のグループに分類
ungroup()
```
- 時価総額が小さい方から順に`1`から`10`までを割り振るために,`dplyr`の`ntile()`関数を用いて`ME_rank10`という変数を作成している.
- `ntile()`関数は,最初の引数としてグループ分けしたいデータ(ここでは`lagged_ME`)を取り,その次の引数にグループの数(ここでは`10`)を取る.
- ちなみに,十分位はdecile,五分位はquintile,四分位はquartile,三分位はtertileという.
- `ntile()`関数の返り値は自然数型となるので,上のコードでは`factor()`関数によりそれをファクター型に変更している.
------------------------------------------------------------------------
### (Step 3) 各ポートフォリオに属する企業数を確認
```{r}
table(annual_data$year, annual_data$ME_rank10)
```
------------------------------------------------------------------------
### (Step 4) `full_join()`関数を用いて`monthly_data`と結合
- 以下のコードでは,`year`と`firm_ID`をキーにして`monthly_data`と結合すると共に,`drop_na()`関数により欠損データを除いている.
```{r}
annual_data %>%
select(year, firm_ID, ME_rank10) %>% # 年次データから追加したい情報を抽出
full_join(monthly_data, by = c("year", "firm_ID")) %>% # yearとfirm_IDをキーに月次データと結合
drop_na() # 欠損行を削除
```
------------------------------------------------------------------------
### (Step 5) 各月・各ポートフォリオごとに実現超過リターンを計算
- ポートフォリオ$P$に属する$N$銘柄に対して,同金額配分する(すなわち,100万円を5銘柄に配分する場合は,各銘柄に対する投資金額は20万円であり,各々の保有割合は20%である)場合を考えよう.このような考え方で保有割合を決定したポートフォリオのことを[**等加重ポートフォリオ**]{style="color: blue"} (equal-weighted portfolio)と呼ぶ.
- 等加重ポートフォリオを前提にした場合,月次$t$におけるポートフォリオ$P$の実現超過リターン$R_{P,t}^{e}$は,以下のように計算することができ,各銘柄の超過リターンの単純平均を取れば計算可能であることが分かる.
$$
R_{P,t}^{e} = \frac{1}{N} R_{1,t}^{e} + \frac{1}{N} R_{2,t}^{e} + \cdots + \frac{1}{N} R_{N,t}^{e} = \frac{\sum_{j = 1}^{N} R_{j,t}^{e}}{N}
$$
------------------------------------------------------------------------
### 各月・各ポートフォリオの実現超過リターンを計算し,そのデータフレームを`ME_sorted_portfolio`と名付けよう
```{r}
ME_sorted_portfolio <- annual_data %>%
select(year, firm_ID, ME_rank10) %>% # 年次データから追加したい情報を抽出
full_join(monthly_data, by = c("year", "firm_ID")) %>% # yearとfirm_IDをキーに月次データと結合
drop_na() %>% # 欠損行を削除
group_by(month_ID, ME_rank10) %>% # month_IDとME_rank10に関してグループ化
summarize(Re = mean(Re),
.groups = "drop") # 各グループで月次超過リターンの平均値を計算
head(ME_sorted_portfolio)
```
------------------------------------------------------------------------
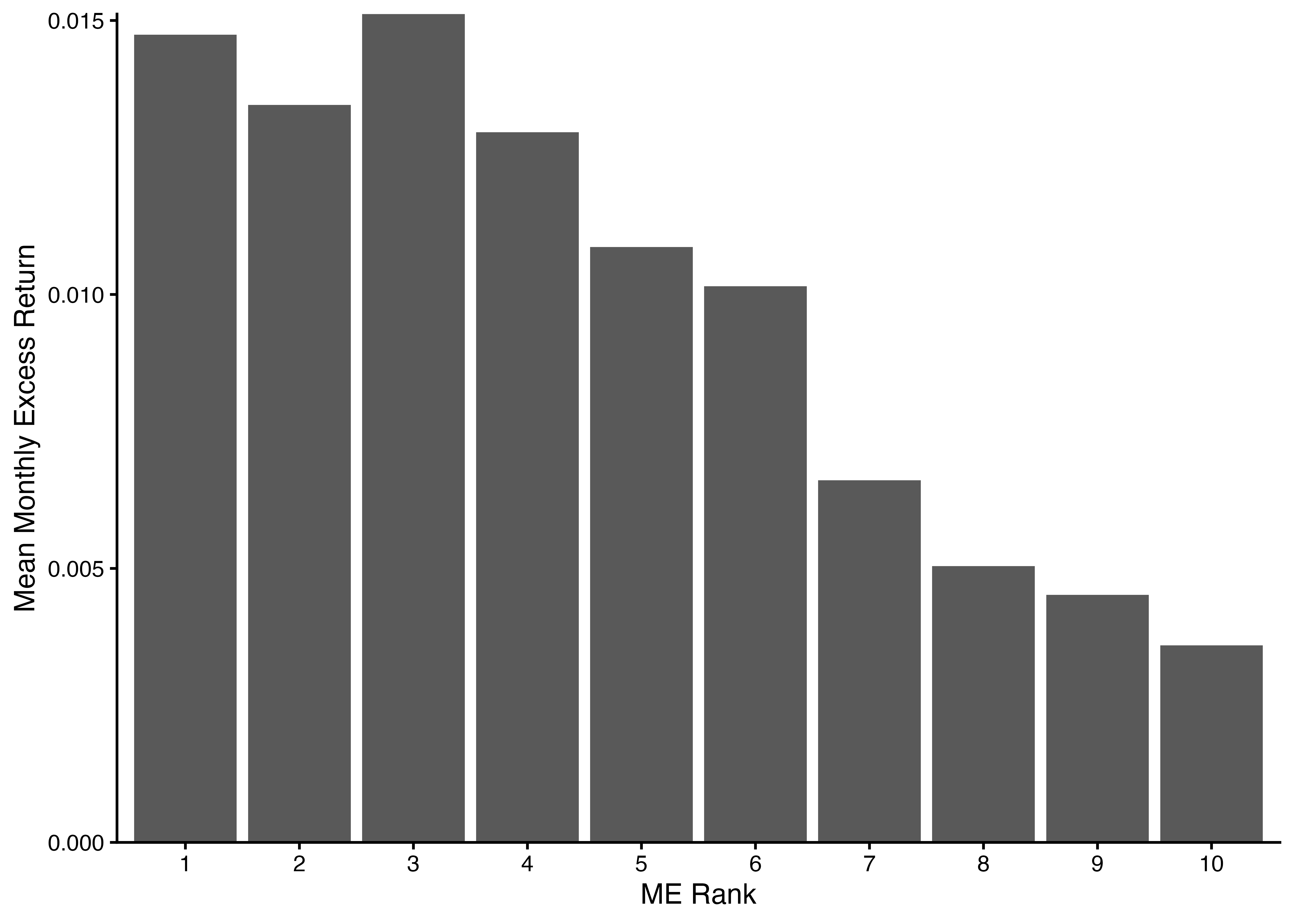
### 各ポートフォリオの平均超過リターンを棒グラフにより可視化してみよう!
```{r}
ME_sorted_portfolio %>%
group_by(ME_rank10) %>% # ME_rank10に関してグループ化
summarize(mean_Re = mean(Re)) %>% # 月次超過リターンの平均値を計算
ggplot() +
geom_col(aes(x = ME_rank10, y = mean_Re)) + # 棒グラフを描くにはgeom_col()関数を用いる
labs(x = "ME Rank", y = "Mean Monthly Excess Return") +
scale_y_continuous(expand = c(0, 0)) +
theme_classic()
```
------------------------------------------------------------------------
### なぜこのようなシステマティックな現象が観察されるのか?
- CAPMが正しい $\Rightarrow$ `ME_rank10`が小さい企業ほど,マーケット・ベータが高いので,平均的に超過リターンが高い傾向にある.
- もし,上記が当てはまらないのであれば,CAPMは現実データを適切に描写しない誤ったモデルである可能性が高い.
------------------------------------------------------------------------
## CAPMの実証的な検証(教科書第6.2節)
### CAPMの概要(再掲)
::: callout-imporatant
#### 二つの命題
- [**(第一命題)**]{style="color: blue"} 市場ポートフォリオは接点ポートフォリオと一致し,効率的フロンティア(資本市場線)上に位置する.
- [**(第二命題)**]{style="color: blue"} 各証券のリスクプレミアムは,その証券のマーケット・ベータに比例する.
$$
\begin{align*}
\underbrace{\mathbb{E}\left[R_i\right]-R_F}_{\textbf{証券$i$のリスクプレミアム}} & =\underbrace{\beta_i}_{\textbf{証券$i$のマーケット・ベータ}}\underbrace{\left(\mathbb{E}\left[R_M\right]-R_F\right)}_{\textbf{市場リスクプレミアム}}\\
\text{ただし,}\quad \beta_i & =\frac{{\rm Cov}[R_i,\ R_M]}{{\rm Var}[R_M]}
\end{align*}
$$
:::
### その世界では,マーケット・ベータこそ全て(再掲)
- 第二命題は期待値に関する主張なので,実際に観察されるリターンはこれに誤差項$\varepsilon_{i,t}$が加わったものと考えることができる.
$$
\begin{align}
\underbrace{R_{i,t}}_{\textbf{証券$i$の実現リターン}} - \underbrace{R_{F,t}}_{\textbf{無リスク金利}} & = \beta_i(\underbrace{R_{M,t}}_{\substack{\textbf{市場ポートフォリオの} \\ \textbf{実現リターン}}} - \underbrace{R_{F,t}}_{\textbf{無リスク金利}}) +\varepsilon_{i,t}\nonumber\\
\underbrace{R_{i,t}^e}_{\textbf{証券$i$の実現超過リターン}} & = \beta_i\underbrace{R_{M,t}^e}_{\substack{\textbf{市場ポートフォリオの} \\ \textbf{実現超過リターン}}} +\varepsilon_{i,t} \label{eq:CAPM1} \tag{6.1}
\end{align}
$$
- 表記をシンプルとするため,$R_{i,t}^e$という記号を用いたが,これは$t$期における証券$i$の無リスク金利に対する実現超過リターン$R_{i,t}-R_{F,t}$ を意味する.
------------------------------------------------------------------------
### 誤差項の仮定(再掲)
ここで,$\varepsilon_{i,t}$に関して以下の仮定を置こう.
1. $\varepsilon_{i,t}$は独立同一分布に従う
2. $\mathbb{E}[\varepsilon_{i,t}] = 0$
3. $\mathbb{E}[R_{M,t}^e \varepsilon_{i,t}] = 0$
- このように定式化すると,CAPMの実証的な検証は線形回帰に帰着させることができる.つまり,超過リターンの時系列データを用意し,個別銘柄の超過リターンを市場ポートフォリオのそれで線形回帰する.
- その際の[**回帰係数がマーケット・ベータ**]{style="color: blue"}である.
------------------------------------------------------------------------
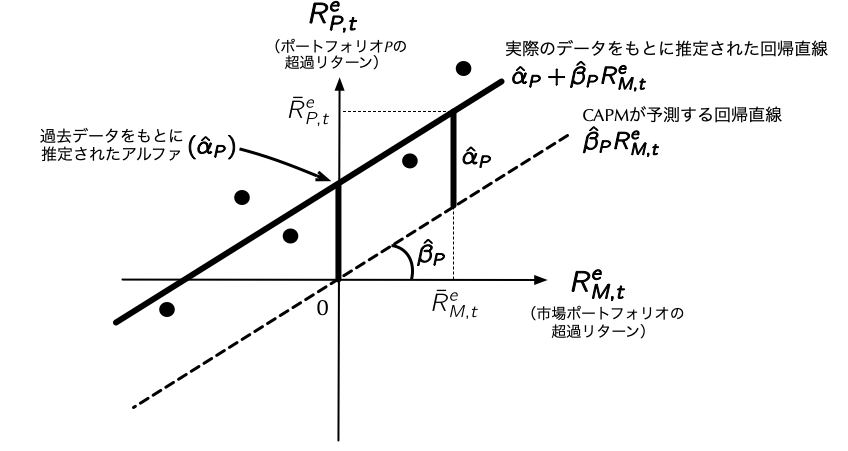
### CAPMの実証的な検証
- CAPMは任意の資産に成立するものであり,個別銘柄の組合せであるポートフォリオにも応用できる.以降では,先に作成した時価総額で十等分したポートフォリオを検証対象としよう.
- これらのポートフォリオのリターンを次の回帰モデルで説明することを考える.
$$
\begin{align}
R_{P,t}^e=\underbrace{\alpha_{P}}_{\substack{\textbf{CAPMが成立} \\ \textbf{すればゼロ}}} + \beta_{P}R_{M,t}^e+\varepsilon_{P,t} \label{eq:CAPM2} \tag{6.2}
\end{align}
$$
{width="80%"}
------------------------------------------------------------------------
### (\ref{eq:CAPM1})式と(\ref{eq:CAPM2})式の相違点
1. (\ref{eq:CAPM1})式と比べてみると,ポートフォリオ$P$が対象となるため,従属変数を証券$i$の実現超過リターン$R_{i,t}^e$からポートフォリオ$P$の実現超過リターン$R_{P,t}^e$へ,また,回帰係数と誤差項についても,証券$i$のものからポートフォリオ$P$のものへと置き換えている.
2. より本質的な違いとして,(\ref{eq:CAPM2})式には定数項$\alpha_{P}$が登場している点に注意しよう.CAPMが成立する世界では,超過リターンが唯一マーケット・ベータのみで説明できるので,定数項は不要である.しかし,ここではCAPMが実証的に成立しているかを検証したいので,CAPMが成立しない可能性を考慮して$\alpha_{P}$も回帰モデルに組み込んでいる.
- もし実際に推定された$\hat{\alpha}_{P}$がゼロではないとすると,それはCAPMが実証的に成立していない証拠となる.この定数項$\alpha_{P}$は,CAPMを前提にした値であることを強調するため,[**CAPMアルファ**]{style="color: red"}と呼ばれる.
------------------------------------------------------------------------
### `ME_Rank10`が`1`のポートフォリオのみを対象とした検証
まずは下準備として,市場ポートフォリオの超過リターンが収録された`ch06_output.csv`を`factor_data`として読み込み,`month_ID`をキーに`ME_sorted_portfolio`と結合し,市場ポートフォリオの超過リターン`R_Me`を追加したのが以下のコードである.
```{r}
# ファクター・データの読み込み
factor_data <- read_csv("../simulation_data/ch06_output.csv")
# 市場ポートフォリオの超過リターンを追加
ME_sorted_portfolio <- factor_data %>%
select(-R_F) %>% # 無リスク金利は重複するので結合前に削除
full_join(ME_sorted_portfolio, by = "month_ID") %>% # month_IDをキーに
select(-R_Me, R_Me) # R_Meを最終列へ移動
head(ME_sorted_portfolio)
```
------------------------------------------------------------------------
### 時系列回帰 --- 概要
- ここでは手始めに時価総額が最小のポートフォリオ (`ME_rank10`が`1`)のデータのみを抽出して,(\ref{eq:CAPM2})式を推定してみよう.これ[**時系列回帰**]{style="color: blue"} (time-series regression)といって,個々の銘柄やポートフォリオの実現リターンが市場ポートフォリオのリターンによってどの程度説明できるかを回帰したモデルである.
- 時系列回帰のイメージは,下の図のとおりであり,任意のポートフォリオ$P$に関して,$x$軸には市場ポートフォリオの月次超過リターンを,$y$軸にはポートフォリオ$P$の月次超過リターンを取ったものである.
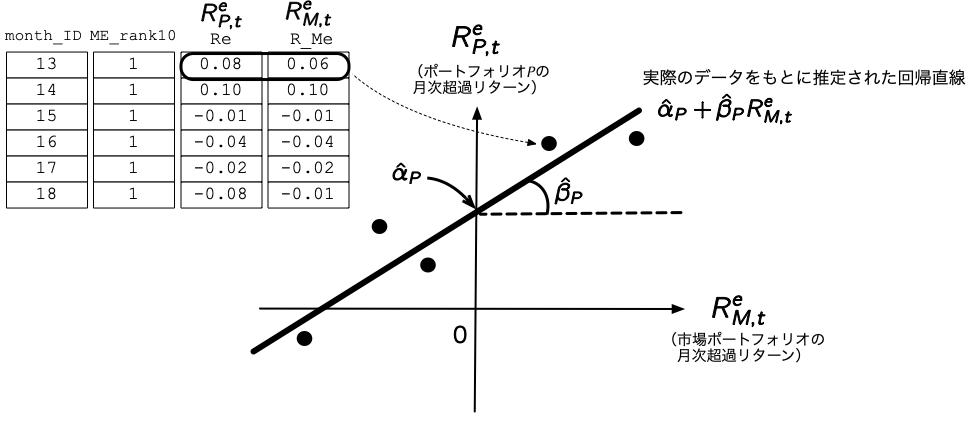{width="80%"}
------------------------------------------------------------------------
### 時系列回帰 --- OLSの実行
```{r}
ME_sorted_portfolio %>%
filter(ME_rank10 == 1) %>% # 時価総額が最小のポートフォリオを抽出
lm(Re ~ R_Me, data = .) %>% # .を使ってlm()関数の第二引数にデータを代入
tidy() # 線形回帰の結果をtidy()関数でデータフレームに変換
```
- 推定結果を見てみると,マーケット・ベータは`R_Me`の回帰係数として`0.654`と推定されており,このポートフォリオが市場ポートフォリオと正に相関していることが確認できる.
- 続いて,CAPMアルファを見てみると,推定値は`(Intercept)`の`0.0121`であり,対応する$t$値は`3.00`と表示されている,したがって,[**CAPMアルファがゼロと等しいという帰無仮説**]{style="color: blue"}は,有意水準1%で棄却されるため,少なくともこのデータにおいてはCAPMが成立していない可能性が高いと言える.
------------------------------------------------------------------------
### `for`文を用いた全ポートフォリオの推定
::: {.callout-note icon="false"}
#### 目標
- 先のコード群では,時価総額が最小のポートフォリオを例に(\ref{eq:CAPM2})式の推定方法を学んだが,ここでは`for`文を用いて,全てのポートフォリオについて同様の推定を行ってみよう.
:::
{width="60%"}
------------------------------------------------------------------------
### 目標を実現するためのコード
- 下のコードで定義した`CAPM_results`はリストであり,推定結果を閲覧するにはその各要素にアクセスする必要がある.異なるポートフォリオ間で推定結果を比較するには,各データフレームを一つのデータフレームに統合する方が便利である.それを実現するには,`dplyr`の`bind_rows()`関数を用いる.今回のように二つ以上のデータフレームを一つに結合したい場合に重宝する.
```{r}
# 推定結果を保存するために空のリストを準備
CAPM_results <- list(NA)
for(i in 1:10){
CAPM_results[[i]] <- ME_sorted_portfolio %>%
filter(ME_rank10 == i) %>%
lm(Re ~ R_Me, data = .) %>%
tidy() %>%
mutate(ME_rank10 = factor(i)) %>% # 推定対象のポートフォリオ名を保存
select(ME_rank10, everything()) # ME_rank10を第一列に移動
}
# 複数のデータフレームを一つに統合
binded_CAPM_results <- bind_rows(CAPM_results)
head(binded_CAPM_results)
```
------------------------------------------------------------------------
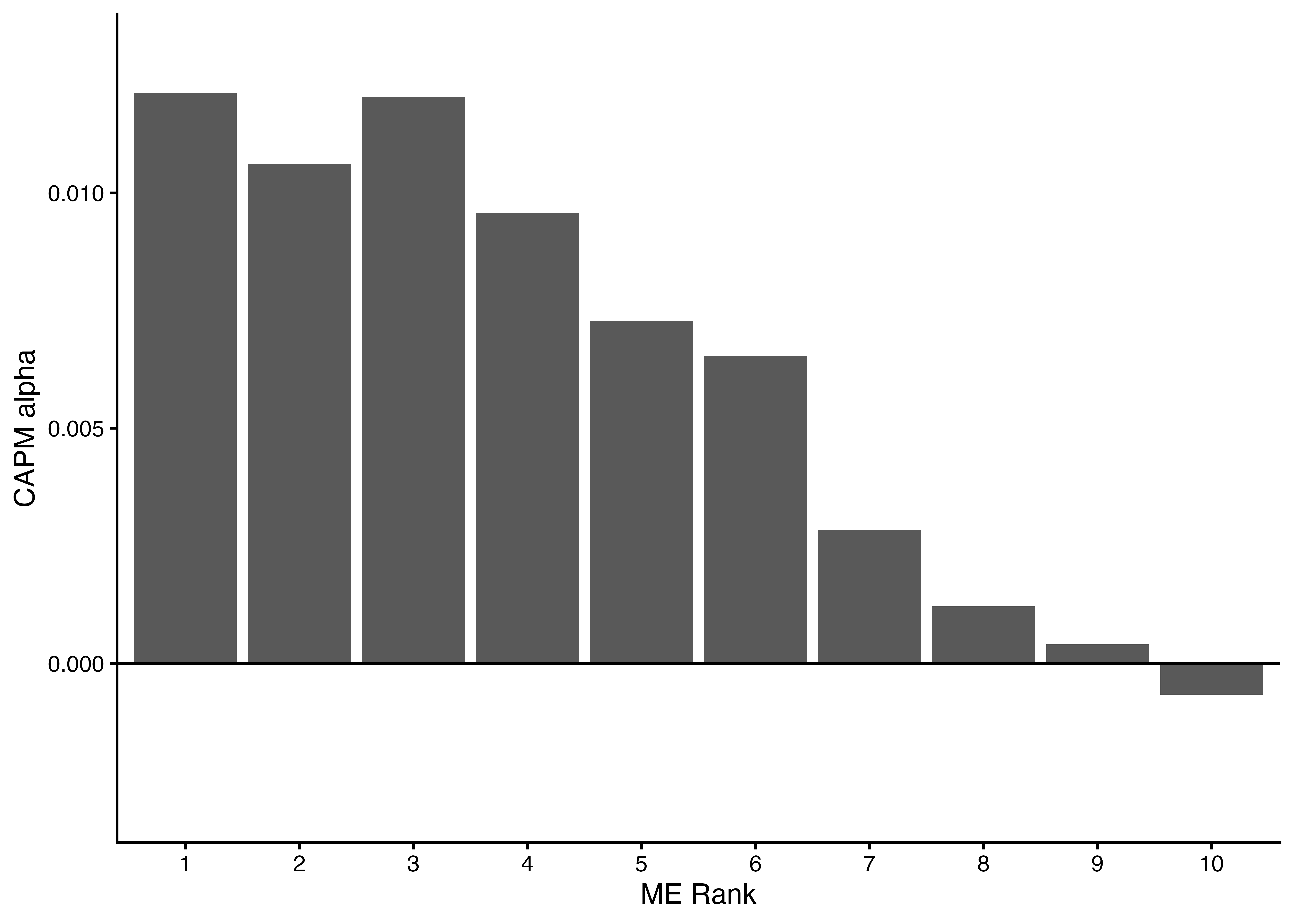
### 各ポートフォリオのCAPMアルファの可視化 {#CAPM_alpha_bar}
- 最後に,定数項に関する推定結果のみを`filter()`関数により抽出し,棒グラフにより各十分位ポートフォリオのCAPMアルファを描画してみよう.
```{r}
binded_CAPM_results %>%
filter(term == "(Intercept)") %>% # 定数項に関する推定結果のみを抽出
ggplot() +
geom_col(aes(x = ME_rank10, y = estimate)) + # 横軸をME_rank10, 縦軸をCAPM_alphaとする棒グラフ
geom_hline(yintercept = 0) +
labs(x = "ME Rank", y = "CAPM alpha") +
scale_y_continuous(limits = c(-0.003, 0.013)) +
theme_classic()
```
- 出力結果を見てみると,時価総額が小さいポートフォリオほど,`CAPM_alph`が高いということが分かる.特に時価総額が最も小さいポートフォリオのCAPMアルファは1.21%で,年率に換算すると14.52% ($=1.21% \times 12$)にもなる.
- したがって,先に確認した実現超過リターンの傾向は,マーケット・ベータを調整済みのCAPMアルファでも存在することが分かる.
------------------------------------------------------------------------
## 線形ファクター・モデルの導入(教科書第6.3節)
### 線形ファクター・モデルの概要
- ファイナンス理論の歴史において,様々なCAPMの拡張・修正が提案されてきたが,その多くが線形ファクター・モデルという部類に属する.
::: callout-tip
#### 線形ファクター・モデルとは?
任意の証券の無リスク金利に対する超過リターンが,ファクターと呼ばれる$K$個の確率変数$F^k$ ($k = 1, 2, \ldots, K$),及び誤差項$\varepsilon_{i}$の線形結合で記述できるというモデルである. $$
\begin{align*}
R_{i,t}^e = \beta_i^1 F_t^1+\beta_i^2 F_t^2+\cdots + \beta_i^K F_t^K + \varepsilon_{i,t}
\end{align*}
$$
ただし,誤差項$\varepsilon_{i}$は$\mathbb{E}[\varepsilon_{i}]=0$,かつ${\rm Cov}[\varepsilon_{i}, F^k]=0$を満たす.ここで,$\beta_i^k$は[**ファクター・ローディング**]{style="color: blue"} (factor loading)と呼ばれ,証券$i$のリターンとファクター$F^k$との共変動の強さを表すパラメータであり,説明変数を一つから複数へと増やした重回帰分析によって推定することができる.ただし,[**通常の回帰分析と異なり,定数項を除いている**]{style="color: purple"}点がポイントである.
:::
- CAPMも線形ファクター・モデルの一種であり,$K = 1$かつ$F_t^1 = R_{M,t}-R_{F,t}$と書ける.
------------------------------------------------------------------------
### Fama-Frenchの3ファクター・モデル
- 「CAPMだけで観察されたリターンを説明しようとすると,小型株やバリュー株がアルファを持つ」というCAPMアノマリーが数多くの実証研究によって報告されていた.
- [**Fama-Frenchの3ファクター・モデル**]{style="color: blue"}(以降では,FF3モデルと略)は,それらをモデルに取り込むために,(1) 市場ポートフォリオの超過リターン$R_{M}^e$に加えて,(2) サイズ・ファクター$\mathit{SMB}$と(3) バリュー・ファクター$\mathit{HML}$を追加したモデルである. $$
\begin{align}
R_{i,t}^e=\beta_i^MR_{M,t}^e+\beta_i^{\mathit{SMB}}{\mathit{SMB}}_t+\beta_i^{\mathit{HML}}{\mathit{HML}}_t+\varepsilon_{i,t} \label{eq:FF3} \tag{6.3}
\end{align}
$$
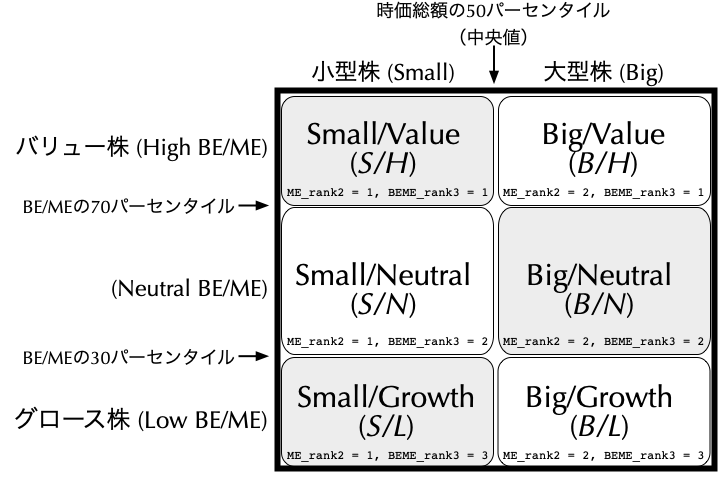
- 実際に$\mathit{SMB}$と$\mathit{HML}$の両者を計算するには,銘柄ユニバースを次スライドの図のように六分割する.
- ここで横軸は時価総額の中央値を境に二分割されており,左に小型株が,右に大型株が分類される.一方,縦軸はBE/MEの30%,70%分位点を境に三分割されており,上にバリュー株が,下にグロース株が分類される.こうして時価総額とBE/MEの違いによって異なった特性を持つ六つのサブポートフォリオが構築されることになる.
------------------------------------------------------------------------
### 6 size-BE/MEポートフォリオ
{width="60%"}
- 月次$t$の$\mathit{SMB}$を表す$\mathit{SMB}_{t}$は,次のように計算することができる. $$
\begin{align*}
\mathit{SMB}_{t} = \underbrace{\left(\frac{\mathit{S/H}_{t}+\mathit{S/N}_{t}+\mathit{S/L}_{t}}{3}\right)}_{\textbf{小型株の平均リターン (\textcolor{red}{Small})}}-\underbrace{\left(\frac{\mathit{B/H}_{t}+\mathit{B/N}_{t}+\mathit{B/L}_{t}}{3}\right)}_{\textbf{大型株の平均リターン (\textcolor{red}{Big})}}
\end{align*}
$$ ただし,右辺の各項は月次$t$における各ポートフォリオの月次リターンであり,例えば,$\mathit{S/H}_{t}$は$\mathit{S/H}$ポートフォリオの時価総額加重平均リターンを表す.
- 他方,月次$t$の$\mathit{HML}$を表す$\mathit{HML}_{t}$は,次のように計算することができる. $$
\begin{align*}
\mathit{HML}_{t} = \underbrace{\left(\frac{\mathit{S/H}_{t}+\mathit{B/H}_{t}}{2}\right)}_{\textbf{バリュー株の平均リターン (\textcolor{blue}{High BE/ME})}}-\underbrace{\left(\frac{\mathit{S/L}_{t}+ \mathit{B/L}_{t}}{2}\right)}_{\textbf{グロース株の平均リターン (\textcolor{blue}{Low BE/ME})}}
\end{align*}
$$
------------------------------------------------------------------------
### FF3アルファ
::: {.callout-note icon="false"}
#### 目標
- CAPMを前提としてアルファを推定したが,ここでは,CAPMに代わってFF3モデルに基づくアルファ(以下では,[**FF3アルファ**]{style="color: blue"}と略称)を推定しよう.
- CAPMを前提とすれば,時価総額に基づく十分位ポートフォリオのいくつかでは統計的にも有意なアルファが観察されたが,[**FF3モデルを前提とすれば,アルファは消滅するか否かを検証するのが目的**]{style="color: purple"}である.
- この検証のために利用する回帰モデルは,次式のとおりである. $$
\begin{align}
R_{P,t}^e = {\alpha_P^{\mathit{FF3}}} + \beta_P^MR_{M,t}^e+\beta_P^{\mathit{SMB}}{\mathit{SMB}}_t+\beta_P^{\mathit{HML}}{\mathit{HML}}_t+\varepsilon_{P,t} \label{eq:FF3a} \tag{6.4}
\end{align}
$$
:::
- これに基づいて推定されたFF3アルファ$\hat{\alpha}_P^{\mathit{FF3}}$は,[**そのポートフォリオの超過リターンが,FF3モデルが予測するパフォーマンスから平均的にどの程度正負に乖離しているか**]{style="color: red"}を意味する.したがって,FF3モデルがポートフォリオの超過リターンをうまく説明する限り,$\hat{\alpha}_P^{\mathit{FF3}}$はゼロになるはずである.
------------------------------------------------------------------------
### 目標を実現するためのコード
```{r}
# 推定結果を保存するために空のリストを準備
FF3_results <- list(NA)
# ポートフォリオごとにFF3アルファの推定
for(i in 1:10) {
FF3_results[[i]] <- ME_sorted_portfolio %>%
filter(ME_rank10 == i) %>%
lm(Re ~ R_Me + SMB + HML, data = .) %>% # 3ファクターの実現値を独立変数として重回帰
tidy() %>%
mutate(ME_rank10 = factor(i)) %>% # 推定対象のポートフォリオ名を保存
select(ME_rank10, everything()) # ME_rank10を第一列に移動
}
# 複数のデータフレームから構成されるリストを一つのデータフレームに統合
binded_FF3_results <- bind_rows(FF3_results)
```
------------------------------------------------------------------------
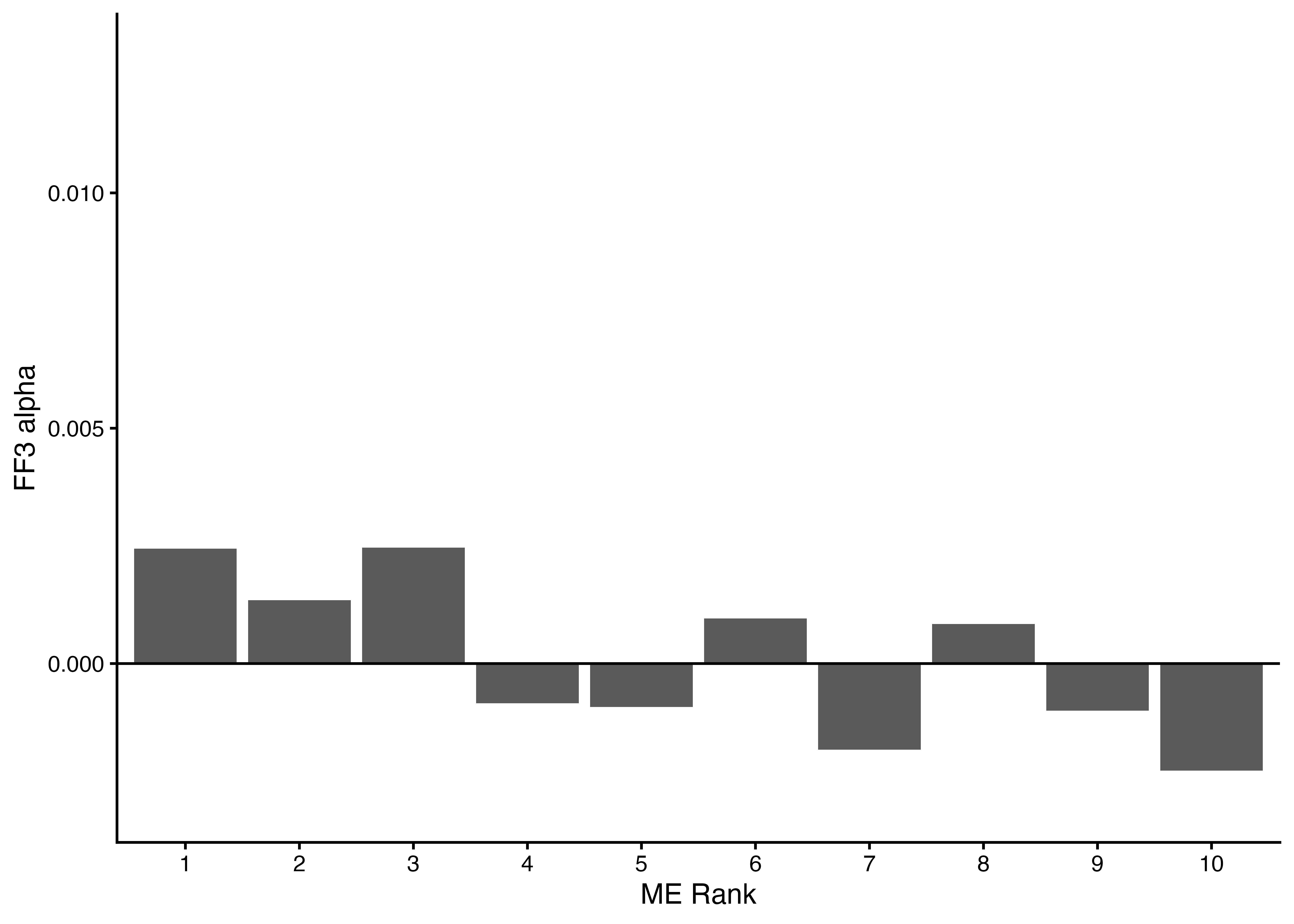
### FF3アルファの可視化
- [先のスライド](#CAPM_alpha_bar)で`CAPM_alpha`を図示した要領で,ポートフォリオごとにFF3アルファを描画してみよう.
- 次スライドのコードでは,`binded_FF3_results`から各ポートフォリオの定数項$\hat{\alpha}_P^{\mathit{FF3}}$を抽出した後,それを棒グラフで可視化している.
```{r}
binded_FF3_results %>%
filter(term == "(Intercept)") %>% # 定数項に関する推定結果のみを抽出
ggplot() +
geom_col(aes(x = ME_rank10, y = estimate)) + # 横軸をME_rank10,縦軸をFF3_alphaとする棒グラフ
geom_hline(yintercept = 0) +
labs(x = "ME Rank", y = "FF3 alpha") +
scale_y_continuous(limits = c(-0.003, 0.013)) +
theme_classic()
```
------------------------------------------------------------------------
### 結果の解釈
- 出力された`FF3_alpha`のグラフを見てみると,いずれのポートフォリオもアルファにほとんど差がないことが分かる.
- この結果は`CAPM_alpha`のそれと対照的であり,CAPMが説明できなかった平均超過リターンの違いを,FF3モデルではうまく説明できることが分かる.
- 定義上,線形ファクター・モデルは任意の銘柄やポートフォリオのリスクプレミアムを説明するはずである.したがって,ファクター調整済みのアルファが規則性を持って観察されるということは,そのファクター・モデルが現実には成立していない証拠となる.
- 規模別ソートという簡単な手順でアルファが観察される以上,[**CAPMは実証的な説明力が高いとは言い難い**]{style="color: blue"}.それとは対照的に,FF3モデルは必要最小限のファクター数で,規模別ソートを含む様々な種類のポートフォリオのリターンを説明できるという意味で支持を集めてきたのである.
[^1]: 一般に,投資対象となる資産のことを投資ユニバースと呼ぶ.
## 自習課題 {data-name="自習課題"}
- 以下の課題に取り組み,今回学んだ内容の理解度を自分で確認しよう.
- 課題では,講義で作成した`annual_data`,`ME_sorted_portfolio`,`binded_CAPM_results`,`binded_FF3_results`をそのまま使用する.
### 準備:自分だけの分析条件を生成する
- 以下のコードをRコンソールで実行しよう.`set.seed()`関数の引数には,**自分の学籍番号の末尾4桁の数字**(末尾の英字を除く)を入力すること.
```{r}
#| eval: false
# 自分の学籍番号の末尾4桁の数字を入力(例: 学籍番号が2001234Bの場合は1234)
set.seed(1234)
# 自分だけの分析条件を生成
my_rank <- sample(1:10, 1) # 分析対象のポートフォリオ番号
my_n <- sample(c(5, 10, 20), 1) # 分位数(五分位/十分位/二十分位)
my_year <- sample(2016:2020, 1) # 企業数確認用の年度(lagged_MEが必要なので2016年以降)
cat("対象ポートフォリオ:", my_rank, "\n")
cat("分位数:", my_n, "\n")
cat("対象年度:", my_year, "\n")
```
------------------------------------------------------------------------
### Q1: `ntile()` と `table()` によるポートフォリオ・ソート
::: {.callout-note icon="false"}
#### 問題
- 講義では時価総額を十分位($n = 10$)に分割したが,ここでは準備で生成した`my_n`分位で同様のソートを行え.具体的には,`annual_data`に対して`group_by(year)`した上で,`ntile(lagged_ME, my_n)`を用いて`ME_rank`列を追加せよ.
- `table()`関数を使い,`my_year`年度における各ポートフォリオの企業数を確認せよ.各グループにほぼ均等に企業が振り分けられているか,一文で答えよ.
:::
------------------------------------------------------------------------
### Q2: CAPMアルファの確認と解釈
::: {.callout-note icon="false"}
#### 問題
- `binded_CAPM_results`から,準備で生成した`my_rank`番目のポートフォリオの推定結果を`filter()`で抽出し,CAPMアルファ($\hat{\alpha}_P$)の推定値,$t$値,$p$値を報告せよ.
- CAPMアルファが有意水準5%で統計的に有意かどうかを判定し,この結果が「CAPMの成立」に関してどのような含意を持つか,一文で答えよ.
:::
------------------------------------------------------------------------
### Q3: FF3アルファとの比較
::: {.callout-note icon="false"}
#### 問題
- `binded_FF3_results`から,Q2と同じ`my_rank`番目のポートフォリオの推定結果を抽出し,FF3アルファ($\hat{\alpha}_P^{\mathit{FF3}}$)の推定値,$t$値,$p$値を報告せよ.
- Q2で求めたCAPMアルファとFF3アルファを比較し,推定値の大きさと統計的有意性がどのように変化したか,一文で述べよ.この変化がFF3モデルの説明力について何を意味するか,一文で答えよ.
:::
------------------------------------------------------------------------
### Q4: ファクター・ローディングの解釈
::: {.callout-note icon="false"}
#### 問題
- `binded_FF3_results`から,`my_rank`番目のポートフォリオにおける$\hat{\beta}_P^{\mathit{SMB}}$(`SMB`の係数)と$\hat{\beta}_P^{\mathit{HML}}$(`HML`の係数)の推定値をそれぞれ報告せよ.
- $\hat{\beta}_P^{\mathit{SMB}}$の符号に着目せよ.$\hat{\beta}_P^{\mathit{SMB}} > 0$は,そのポートフォリオのリターンが$\mathit{SMB}$ファクター(小型株マイナス大型株)と**正に連動**していることを意味する.`my_rank`番目のポートフォリオの$\hat{\beta}_P^{\mathit{SMB}}$はこの解釈と整合的か,一文で答えよ.
- `my_rank`が`1`(最小時価総額)の場合と`10`(最大時価総額)の場合で$\hat{\beta}_P^{\mathit{SMB}}$の符号を比較し,両者の違いを報告せよ.その上で,時価総額が小さい企業で構成されるポートフォリオであっても,必ずしも$\hat{\beta}_P^{\mathit{SMB}}$が大きくなるとは限らない理由を一文で考えよ.
:::
::: goal
**(ヒント!)**
1. $\hat{\beta}_P^{\mathit{SMB}}$はあくまで$\mathit{SMB}$ファクターとの**共変動の強さ**を表すパラメータであり,ポートフォリオの構成銘柄の時価総額の大小(特性; characteristics)そのものとは概念的に異なる.小型株であっても,ファクター・ローディング$\hat{\beta}_P^{\mathit{SMB}}$が大きくなるとは限らないのである.ファクター・ローディングと特性の違いに関する議論は,@daniel1997 を参照されたい.
2. 全十分位ポートフォリオの$\hat{\beta}_P^{\mathit{SMB}}$を並べて見比べると,特性とローディングの関係がより明確に観察できる.
:::
## 参考文献