Code
pacman::p_load(tidyverse, magrittr, readxl, kableExtra,rmarkdown,tinytable, here)
case_wide <- here("data","case_wide.xlsx") |> read_excel()
case_wide管理会計は一言で言うと,
企業の構想実現のために会社で使われる仕組み
谷 (2022)
組織の構想実現のために企業内で整備される仕組み
企業のデータを構想実現に役立てる仕組み
会計データをはじめとしたデータを経営管理のために使う
企業はさまざまな情報源からさまざまなデータを集めている

大きく分けて2種類の使い方があるとされる(Luft 2009; Grafton, Lillis, and Widener 2010; 伊丹 and 青木 2016)
従業員の行動に影響を与える
業績評価アプローチ
(意思決定影響機能)
企業目標に向かって自発的に働いてくれるよう仕向ける
意思決定に役立てる
意思決定アプローチ
(意思決定支援機能)
組織のさまざまな階層における経営管理者が組織目標達成のために遂行する仕事。
これらの使い方は,それぞれ別の仕組みがあるとは限らず,1つの仕組みの中で2つの役割が求められることがほとんど。
会計データは,企業の活動を金銭的価値として測定したもの
大きく分けて財務会計と管理会計がある

それぞれ(時に別のデータと組み合わせながら)様々な目的のために分析される 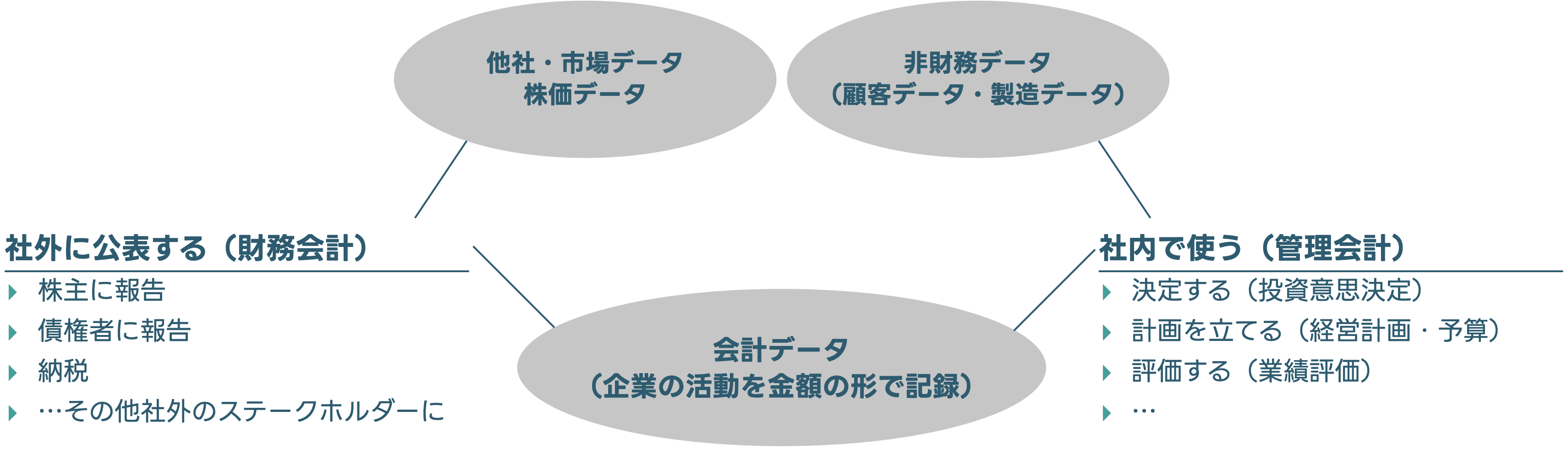
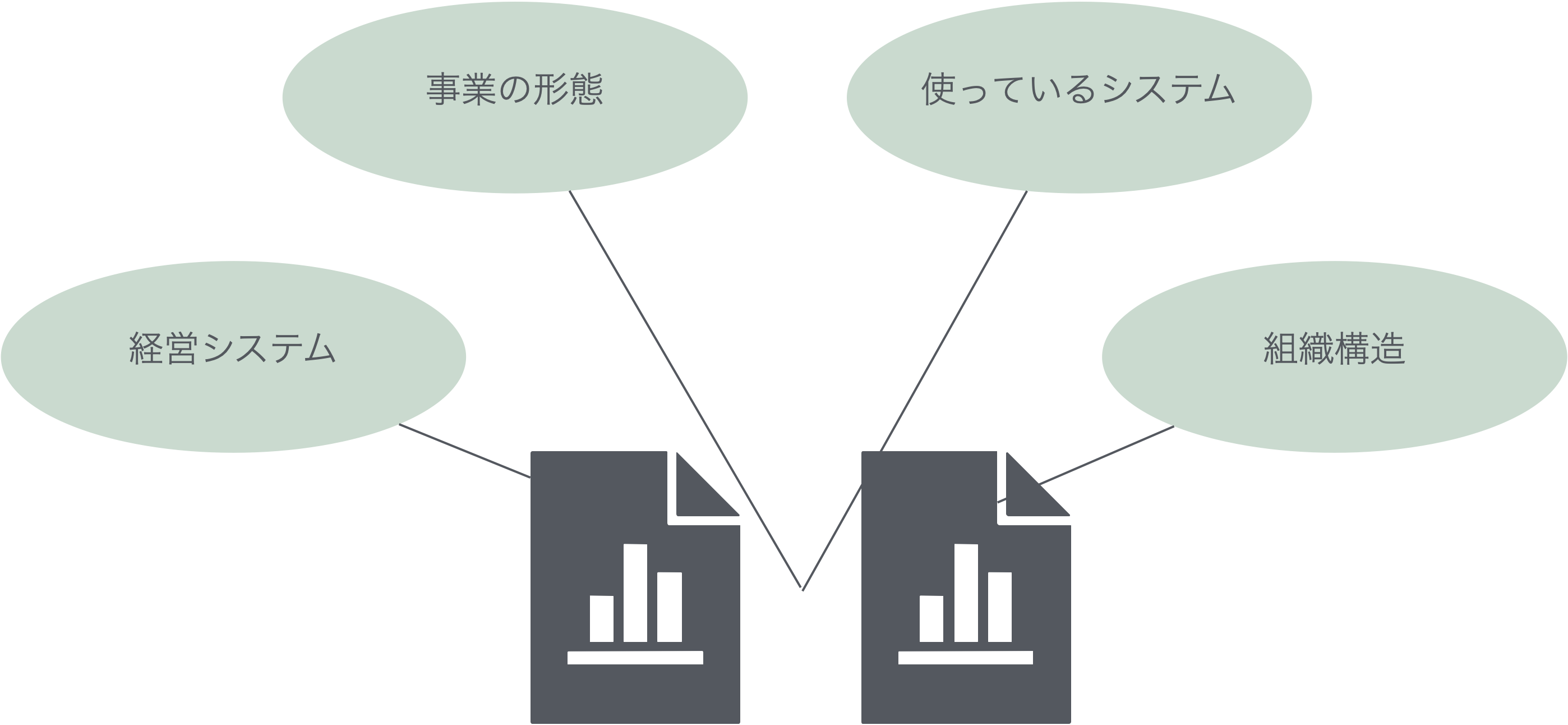
企業が経営管理のために役立てられるデータの幅は増えてきています。
より多くのデータを使うことで,データの収集・集計,分析の難易度は増しています。
一方で,財務指標データ(会計データ)とその他データは多くの場合,バラバラの部署でバラバラに蓄積されています。
京セラで生まれ,関連企業だけでなく,KCCSマネジメントコンサルティングを通して多くの企業に導入されている経営の仕組み
- 小集団(例えば5人とか10人とか)
- それぞれが社内外と取引する形にする
- 社内外での売り買いがあるので利益計算が可能
結果として,それぞれの小集団が小さい会社のように利益追求できるように
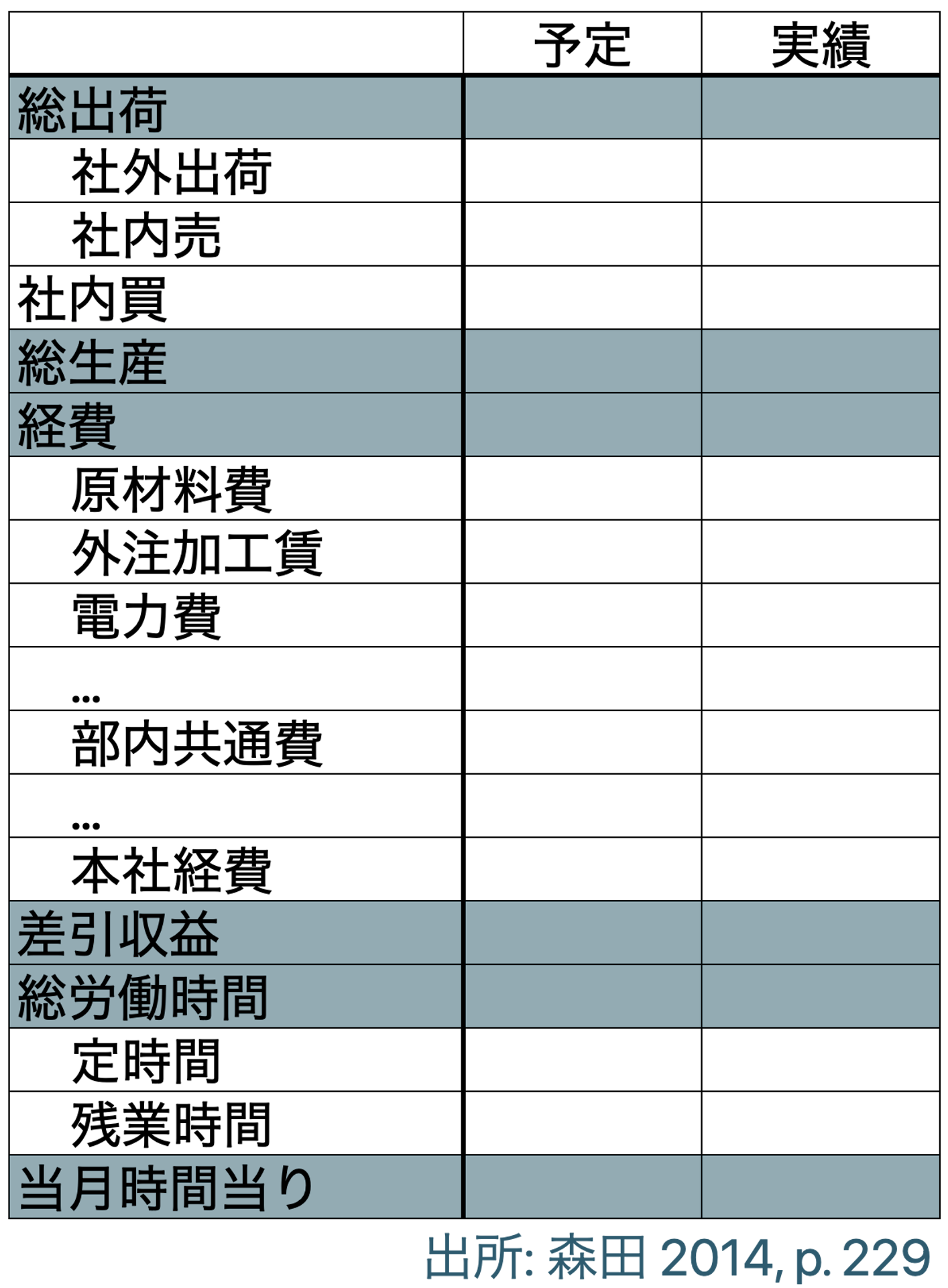
アメーバ経営において,小集団がそれぞれ利益管理ができるよう,簡単な利益計算のフォーマットが作成される
一般的(簿記の仕組みで出てくる)費目の分け方や,利益の計算方法とは違う
(言い訳じみていますが)管理会計のデータは千差万別で,こんな分析ができますよ,というのを体系立てて説明することは結構難しいです。
そこで…
といったことを扱います。
データを集計して,表にまとめるときには,いくつかの方法があります。
データ分析上望ましいのは,変数が列,測定単位が行の形です。
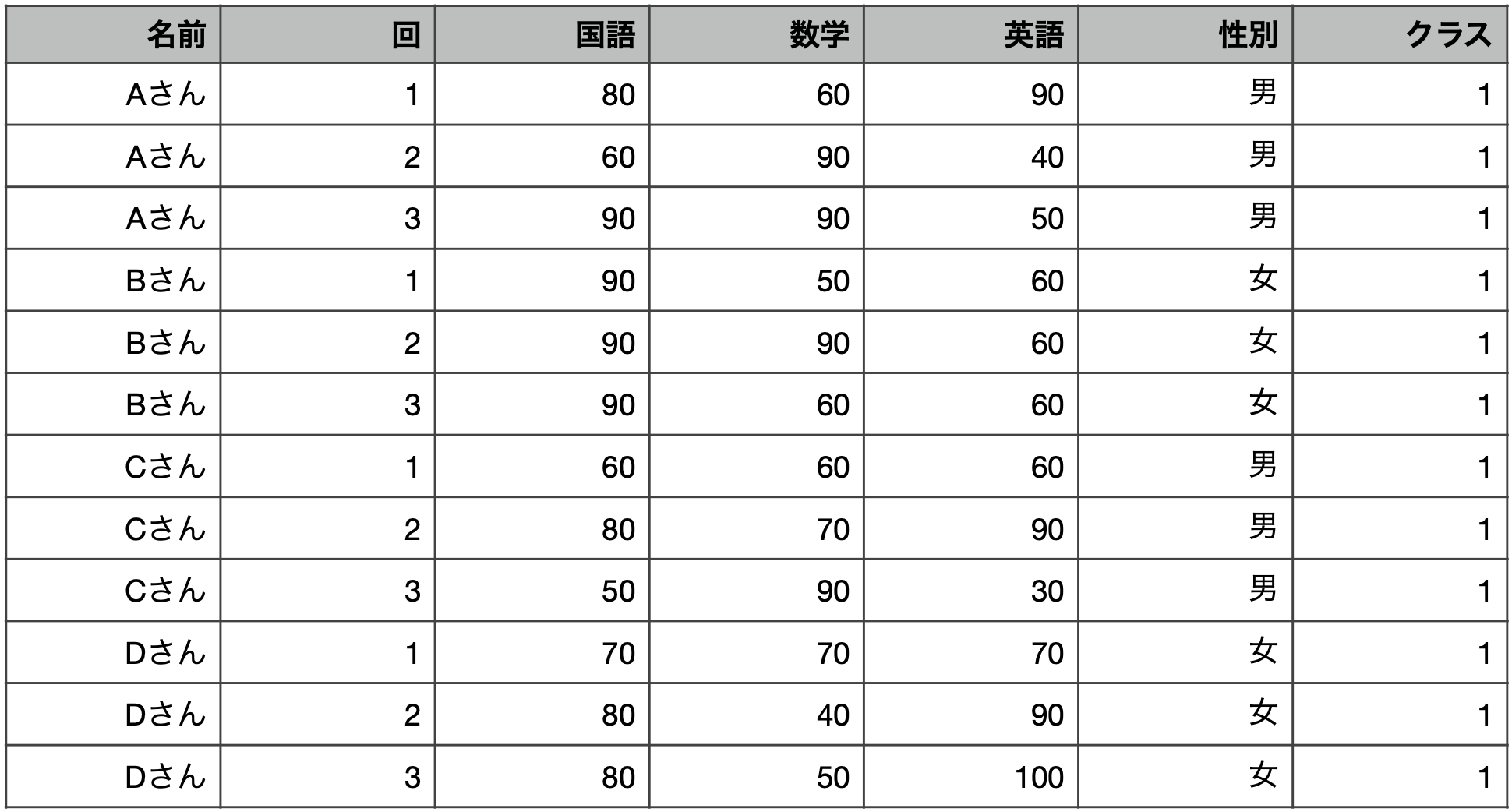
ある兄弟は,毎月身長を測っています。年齢データとともに表にまとめました。
pacman::p_load(tidyverse, magrittr, readxl, kableExtra,rmarkdown,tinytable, here)
case_wide <- here("data","case_wide.xlsx") |> read_excel()
case_wide分析に使うために望ましいのは
状態。これを目指す!
case_widel <- case_wide |>
pivot_longer(starts_with("m"),
names_to = "month",
names_prefix = "m",
values_to = "height") |>
mutate(month = as.numeric(month))
case_widelデータセットには,集計された種類で大きく3種類に分けられます。
測定単位がそれぞれ独立しているデータ。
1時点の傾向がわかる
1つの測定対象に対して複数時点でとったデータ
](images/t3-5.png)
複数の測定対象に対して,複数時点でとったデータ
いろんなことがわかる

ある企業の店舗レベルデータ
case1a <- here("data","case1_a.xlsx") |> read_excel()
case1b <- here("data","case1_b.xlsx") |> read_excel()
case1c <- here("data","case1_c.xlsx") |> read_excel()
case1a理想的な形は月次のパネルデータ
| shop | shop_id | 売上高 | 売上原価 | … | 年 | 月 |
|---|---|---|---|---|---|---|
| A | 20 | 6600 | 3684 | 2016 | 4 | |
| A | 20 | 7100 | 3928 | 2016 | 5 | |
| A | 20 | 6300 | 3529 | 2016 | 6 |
現在の形はワイド形式,long形式に直したい
case1al <- case1a |>
select(-合計) |>
pivot_longer(cols = c(-shop_id, -shop, -himoku),
names_to = "yearmonth") |>
pivot_wider(id_cols = c(shop_id, shop, yearmonth),
names_from = himoku,
values_from = value)
case1al元々のデータ
case1a指定した範囲の列を一つの列に結合して縦に伸ばす
pivot_longer()関数を使う
cols = として,結合したい列を指定する。今回は結合”したくない”列を取り除く形で指定してるcase1al <- case1a |>
select(-合計) |>
pivot_longer(cols = c(-shop_id, -shop, -himoku),
names_to = "yearmonth")
case1al費目単位で横に伸ばす
pivot_wider()関数を使う
id_colsはそのまま残したい列names_from列名にしたい(引き伸ばしたい)情報が入った列values_fromは,列に入れたい情報が入った列case1al <- case1al |>
pivot_wider(id_cols = c(shop_id, shop, yearmonth),
names_from = himoku,
values_from = value)
case1alforループを使って繰り返しを自動化しますfile_list <- c("data/case1_a.xlsx",
"data/case1_b.xlsx",
"data/case1_c.xlsx")
data_list <- list()
for (file in file_list) {
data <- here(file) |> read_excel()
data_list[[file]] <- data |>
select(-合計) |>
pivot_longer(cols = c(-shop_id, -shop, -himoku),
names_to = "yearmonth") |>
pivot_wider(id_cols = c(shop_id, shop, yearmonth),
names_from = himoku,
values_from = value)
}
combined_data <- bind_rows(data_list)
combined_databind_rows()関数)
次のような順番で作業してみる
findata.csvと,case3_p1.xlsx, case3_p2.xlsxという三つのデータを使います
findata <- here("data/findata.csv") |> read.csv()
case3_p1 <- here("data/case3_p1.xlsx") |> read_excel()
case3_p2 <- here("data/case3_p2.xlsx") |> read_excel()
case3_p1bind_rows()関数は,変数名が同じ2つのデータセットを縦方向に結合してくれる。person <- bind_rows(case3_p1,case3_p2)
person <- person |>
rename(fiscalyear = year)
personcase_when() 関数は,条件分岐させて処理を変えるための関数。
ifelse()関数も条件分岐。
findata <- findata |>
mutate(fiscalyear = case_when(month %in% c(1, 2, 3) ~ year - 1,
TRUE ~ year),
half = ifelse(month >= 4 & month < 10, 1,2))
findata財務データの列に店長と業績評価の列をくっつける
left_join()関数はExcelのvlookupみたいな挙動。by =で指定した変数をキーにして,2つのデータを横向きに結合data_full <- left_join(findata, person ,
by = c('fiscalyear','half','shop'))
data_fullcase2.xlsxは企業の財務データです。
| shop | … | 売上高 | 売上原価 | yearmonth |
|---|---|---|---|---|
| A | 1604 | |||
| A | 1605 | |||
| … | … | |||
| B | 1604 | |||
| … | … | |||
| C | 1604 |
kadai <- here("data/case2.xlsx") |> read_excel()
tt(kadai)| shop_id | shop | himoku | 1604 | 1605 | 1606 | 1607 | 1608 | 1609 | 1610 | 1611 | 1612 | 1701 | 1702 | 1703 | 合計 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 20 | A | 売上高 | 6600 | 7100 | 6300 | 6900 | 8000 | 6600 | 6800 | 6400 | 9300 | 9000 | 6400 | 6800 | 86200 |
| 20 | A | 売上原価 | 3711 | 3924 | 3541 | 3880 | 4462 | 3727 | 3770 | 3552 | 5155 | 5020 | 3582 | 3782 | 48105 |
| 20 | A | 人件費合計 | 1550 | 1650 | 1421 | 1584 | 1832 | 1460 | 1526 | 1454 | 2109 | 2014 | 1486 | 1574 | 19660 |
| 20 | A | 水道光熱費計 | 33 | 36 | 32 | 35 | 41 | 34 | 35 | 32 | 47 | 45 | 33 | 34 | 437 |
| 20 | A | その他営業経費 | 14 | 14 | 14 | 14 | 17 | 14 | 14 | 13 | 20 | 18 | 13 | 14 | 178 |
| 20 | A | 本部・本社費計 | 594 | 640 | 567 | 622 | 720 | 594 | 613 | 576 | 838 | 811 | 576 | 612 | 7764 |
| 20 | A | 経費合計 | 5902 | 6264 | 5574 | 6135 | 7072 | 5829 | 5958 | 5627 | 8169 | 7908 | 5690 | 6016 | 76144 |
| 20 | A | 店舗営業利益高 | 698 | 836 | 726 | 765 | 928 | 771 | 842 | 773 | 1131 | 1092 | 710 | 784 | 10056 |
| 70 | B | 売上高 | 5400 | 6200 | 5800 | 6000 | 7400 | 5400 | 5800 | 5300 | 8500 | 8000 | 5400 | 5800 | 75000 |
| 70 | B | 売上原価 | 3068 | 3433 | 3195 | 3400 | 4127 | 3064 | 3215 | 3000 | 4762 | 4499 | 3010 | 3267 | 42040 |
| 70 | B | 人件費合計 | 1236 | 1409 | 1303 | 1330 | 1728 | 1211 | 1318 | 1185 | 1926 | 1763 | 1219 | 1361 | 16988 |
| 70 | B | 水道光熱費計 | 28 | 32 | 29 | 31 | 37 | 28 | 29 | 27 | 43 | 41 | 28 | 30 | 382 |
| 70 | B | その他営業経費 | 12 | 13 | 12 | 13 | 16 | 11 | 12 | 11 | 17 | 17 | 11 | 12 | 156 |
| 70 | B | 本部・本社費計 | 487 | 558 | 523 | 540 | 666 | 486 | 522 | 478 | 766 | 720 | 486 | 523 | 6756 |
| 70 | B | 経費合計 | 4831 | 5446 | 5062 | 5314 | 6574 | 4799 | 5096 | 4701 | 7514 | 7040 | 4754 | 5192 | 66322 |
| 70 | B | 店舗営業利益高 | 569 | 754 | 738 | 686 | 826 | 601 | 704 | 599 | 986 | 960 | 646 | 608 | 8678 |
| 100 | C | 売上高 | 4109 | 4441 | 4958 | 4183 | 5548 | 5918 | 4927 | 4370 | 6033 | 6897 | 4437 | 5942 | 61763 |
| 100 | C | 売上原価 | 2265 | 2478 | 2750 | 2340 | 3056 | 3261 | 2808 | 2405 | 3393 | 3872 | 2444 | 3270 | 34342 |
| 100 | C | 人件費合計 | 954 | 1034 | 1152 | 999 | 1289 | 1363 | 1166 | 1051 | 1348 | 1569 | 1008 | 1382 | 14315 |
| 100 | C | 水道光熱費計 | 22 | 23 | 26 | 22 | 29 | 30 | 25 | 23 | 30 | 35 | 23 | 30 | 316 |
| 100 | C | その他営業経費 | 9 | 9 | 10 | 9 | 11 | 12 | 10 | 9 | 13 | 14 | 9 | 12 | 130 |
| 100 | C | 本部・本社費計 | 370 | 400 | 446 | 377 | 499 | 533 | 444 | 394 | 544 | 621 | 400 | 535 | 5564 |
| 100 | C | 経費合計 | 3620 | 3944 | 4384 | 3747 | 4884 | 5200 | 4454 | 3882 | 5328 | 6111 | 3883 | 5230 | 54667 |
| 100 | C | 店舗営業利益高 | 489 | 496 | 575 | 436 | 664 | 719 | 473 | 488 | 706 | 786 | 554 | 712 | 7096 |
| 111 | D | 売上高 | 4659 | 4011 | 4426 | 4059 | 5036 | 5065 | 4333 | 4560 | 6859 | 6993 | 4067 | 5880 | 59949 |
| 111 | D | 売上原価 | 2608 | 2226 | 2443 | 2267 | 2832 | 2880 | 2424 | 2592 | 3851 | 3863 | 2327 | 3315 | 33627 |
| 111 | D | 人件費合計 | 1072 | 912 | 986 | 978 | 1161 | 1135 | 1021 | 1052 | 1586 | 1622 | 933 | 1317 | 13774 |
| 111 | D | 水道光熱費計 | 24 | 21 | 23 | 21 | 26 | 26 | 22 | 24 | 35 | 36 | 21 | 30 | 306 |
| 111 | D | その他営業経費 | 10 | 9 | 10 | 8 | 10 | 10 | 9 | 10 | 15 | 15 | 9 | 12 | 126 |
| 111 | D | 本部・本社費計 | 420 | 361 | 399 | 365 | 454 | 456 | 391 | 411 | 618 | 630 | 366 | 530 | 5401 |
| 111 | D | 経費合計 | 4134 | 3529 | 3860 | 3639 | 4483 | 4507 | 3867 | 4088 | 6105 | 6164 | 3656 | 5204 | 53235 |
| 111 | D | 店舗営業利益高 | 525 | 482 | 565 | 419 | 553 | 558 | 466 | 472 | 754 | 829 | 412 | 676 | 6713 |
| 200 | E | 売上高 | 6831 | 6394 | 5546 | 4954 | 5145 | 5869 | 4272 | 4090 | 7557 | 7720 | 5890 | 6781 | 71047 |
| 200 | E | 売上原価 | 3759 | 3523 | 3091 | 2743 | 2831 | 3313 | 2352 | 2335 | 4230 | 4339 | 3317 | 3794 | 39627 |
| 200 | E | 人件費合計 | 1508 | 1496 | 1260 | 1151 | 1170 | 1367 | 972 | 980 | 1741 | 1714 | 1380 | 1542 | 16281 |
| 200 | E | 水道光熱費計 | 35 | 33 | 28 | 26 | 26 | 30 | 22 | 21 | 39 | 39 | 30 | 34 | 362 |
| 200 | E | その他営業経費 | 14 | 13 | 12 | 10 | 11 | 13 | 9 | 9 | 15 | 16 | 12 | 14 | 149 |
| 200 | E | 本部・本社費計 | 616 | 576 | 500 | 446 | 464 | 529 | 385 | 368 | 681 | 695 | 530 | 610 | 6400 |
| 200 | E | 経費合計 | 5931 | 5641 | 4890 | 4376 | 4502 | 5252 | 3740 | 3713 | 6706 | 6803 | 5270 | 5996 | 62821 |
| 200 | E | 店舗営業利益高 | 899 | 752 | 656 | 578 | 642 | 617 | 531 | 377 | 851 | 917 | 620 | 786 | 8227 |
kadai <- kadai |>
select(-合計) |>
pivot_longer(cols = c(-shop_id, -shop, -himoku),
names_to = "yearmonth")|>
pivot_wider(id_cols = c(shop_id, shop, yearmonth),
names_from = himoku,
values_from = value)
kadai