# A tibble: 6 × 9
year month month_ID firm_ID stock_price DPS shares_outstanding
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2015 1 1 1 954 0 2422000
2 2015 2 2 1 960 0 2422000
3 2015 3 3 1 1113 0 2422000
4 2015 4 4 1 1081 0 2422000
5 2015 5 5 1 1317 0 2422000
6 2015 6 6 1 1366 29 2422000
# ℹ 2 more variables: adjustment_coefficient <dbl>, R_F <dbl>6 株式データ分析入門
2024-05-17
1.3 (余談)日本企業が採用する配当政策
- 安定配当政策・・・日本企業の多くが採用していた伝統的な配当政策.業績に関わらず,毎期一定の配当を支払うことを目標にする考え方.
- 代表例:井村屋(年一回1株当たり28円)
- 配当性向 (payout ratio)政策・・・業績に応じて,配当額を変化させる考え方
- 代表例:伊藤忠商事(配当性向目標30%)

- 例えば,東京エレクトロンは,両者を組合せて配当性向50%を目処とするとともに,安定的に還元するため,1株当たりの年間配当金は50円を下回らないようにしている.
1.4 近年では,DOEを意識する企業も
- 株主資本配当率 (Dividend on Equity ratio; DOE)政策・・・1株当たりの株主資本に対して,一定の割合の配当を支払うことを目標にする考え方
- 代表例:エーザイ(DOE目標15%)
- 一般的に,利益よりも株主資本の方が分散が少ないので,配当性向政策を採用する企業よりも,DOE政策を採用する企業の方が,安定的な配当が見込める.
1.6 調整係数が1以外の値を取る例
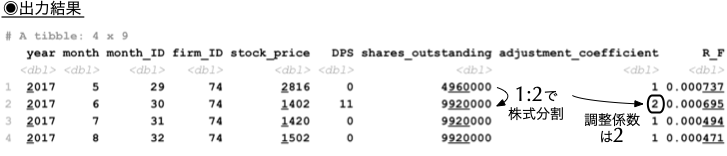
- 8列目の
adjustment_coefficientは,株式分割や併合などに伴う株式数の変化を調整するためのデータである. - 例えば,株式分割により旧1株が新しく2株になったとしよう.理論株価は半分になる一方で,元の株主はそれを相殺するように2倍の株式数を手にする.ここで単純に株価だけを用いてプライス・リターンを計算してしまうと,株主の資産の変化を誤って捉えてしまう.したがって,この場合は調整係数を
2として,リターンを計算する際に調整する必要がある.
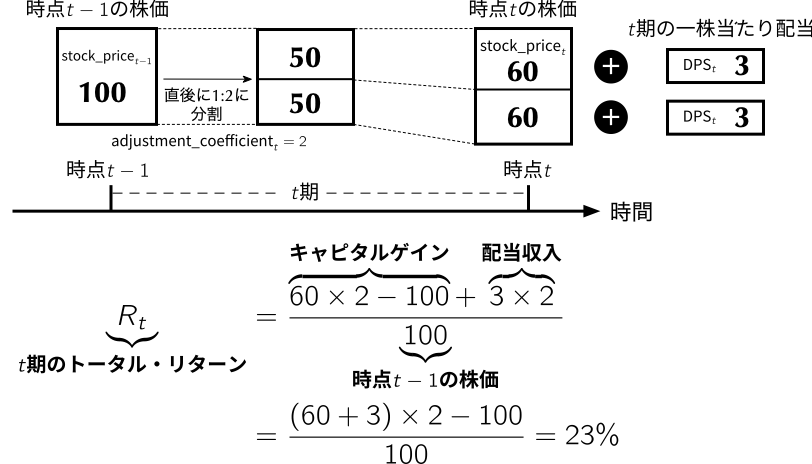
1.8 トータル・リターンの計算
- ここで計算するリターンはトータル・リターンや配当込みリターンと言われ,株価の変化に加え配当収入も加味したリターンである.
- 例えば,ある投資家が保有する銘柄が株式分割を行ったとしよう.定義より,月末時点でその投資家は元の保有株数の\({\rm adjustment\_coefficient}_t\)倍の株式を保有することになる.そして,ポートフォリオの時価評価は一株当たり\({\rm stock\_price}_t\)であり,更に\({\rm DPS}_t\)の配当を受け取る.したがって,この株式の\(t\)期のトータル・リターンは以下のように計算できる.
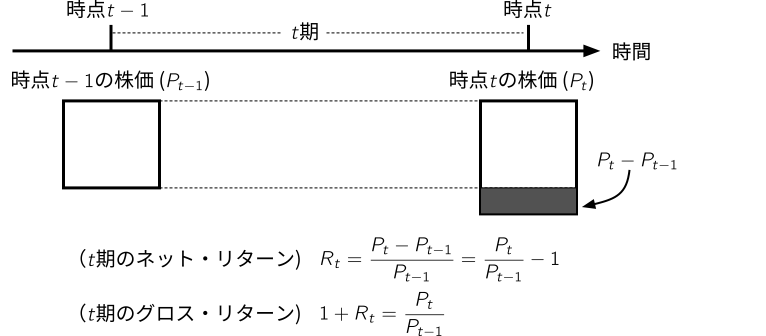
1.10 様々なリターンの定義(教科書コラム2.1)
- 例えば,昨日の株価が100円で,今日の株価が110円になった場合,ネット・リターンは10% (\(=\) 0.1)である.一方,元本分も含める場合はグロス・リターンと呼び,ネット・リターンに1を足して110% (\(=\) 1.1)となる.
- 単純にリターンと言った場合にどちらを指すかは文脈によるが,本書では原則としてネット・リターンの意味で用いる.
2 リターンの累積(教科書第5.3節)
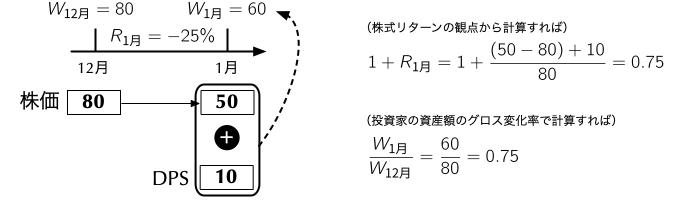
2.1 バイ・アンド・ホールド・リターンの考え方 - 1ヶ月間を例に
- 例えば,ある銘柄に12月末に投資をして,1ヶ月保有し続けた場合の1ヶ月間のリターンを考えてみよう.この例のように,一度投資すれば,後は売買することなく保有し続けた場合のリターンのことを明示的に強調するために,バイ・アンド・ホールド・リターン (buy-and-hold return)と呼ぶ.
- バイ・アンド・ホールド・リターンは元本を再投資し続けた場合のリターンと言い換えられるので,運用を継続することによる複利の効果を反映した値である.
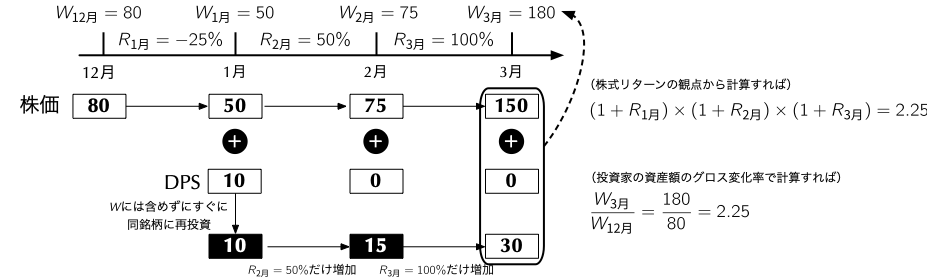
2.2 バイ・アンド・ホールド・リターンの考え方 - 3ヶ月間を例に
- 1ヶ月が3ヶ月に伸びたところで同じように考えることができる.すなわち,バイ・アンド・ホールドで3ヶ月間のリターンを累積するには,12月末から3月末にかけての投資家の資産額の変化率を計算すれば良い.ここでのポイントは,(得られた配当はすぐにその同銘柄に再投資すると考える限りにおいて)資産額のグロス変化率は,以下のように積の形で分解できる点である.
\[ \begin{align*} \underbrace{\left(\frac{W_{\text{3月}}}{W_{\text{12月}}}\right)}_{\textbf{グロスの3ヶ月間のリターン}} = \underbrace{\left(\frac{\cancel{W_{\text{1月}}}}{W_{\text{12月}}}\right)}_{1 + R_{\text{1月}}} \times \underbrace{\left(\frac{\cancel{W_{\text{2月}}}}{\cancel{W_{\text{1月}}}}\right)}_{1 + R_{\text{2月}}} \times \underbrace{\left(\frac{W_{\text{3月}}}{\cancel{W_{\text{2月}}}}\right)}_{1 + R_{\text{3月}}} \end{align*} \]
3.3 既成の関数を使うやり方
- Rでは\(t\)検定を行うために
t.test()関数が用意されている. - この関数は第一引数に標本集合を取り,第二引数以降に検定の詳細を指定する.第二引数以降が省略された場合,自動的に帰無仮説は期待値ゼロに設定される.
