Code
2options(digits = 3)
if (!require("pacman")) install.packages("pacman")
pacman::p_load(tidyverse, magrittr, ggpubr, here,
car, modelsummary, datarium, dae, ggdist) - 2
- 必要なパッケージを読み込み
2024/07/26
調査者が何らかの操作をして行う調査・研究
.svg)
参加者をランダムに2つ(以上)のグループに割り振って,片方には新しい薬を,片方には薬ではないもの(プラセボ)を投与して,新薬の効果を検証する

同じ場所に並べた複数の植木のうち,ランダムに選んだいくつかには肥料を与え,残りには与えないことで,肥料の効果を検証する

アクセスしてくる人のうち一定割合に別のデザインの画面を表示し,クリックする先やクリック率等を比較する。(どちらのデザインの方が良いか?)



xがyの原因となる


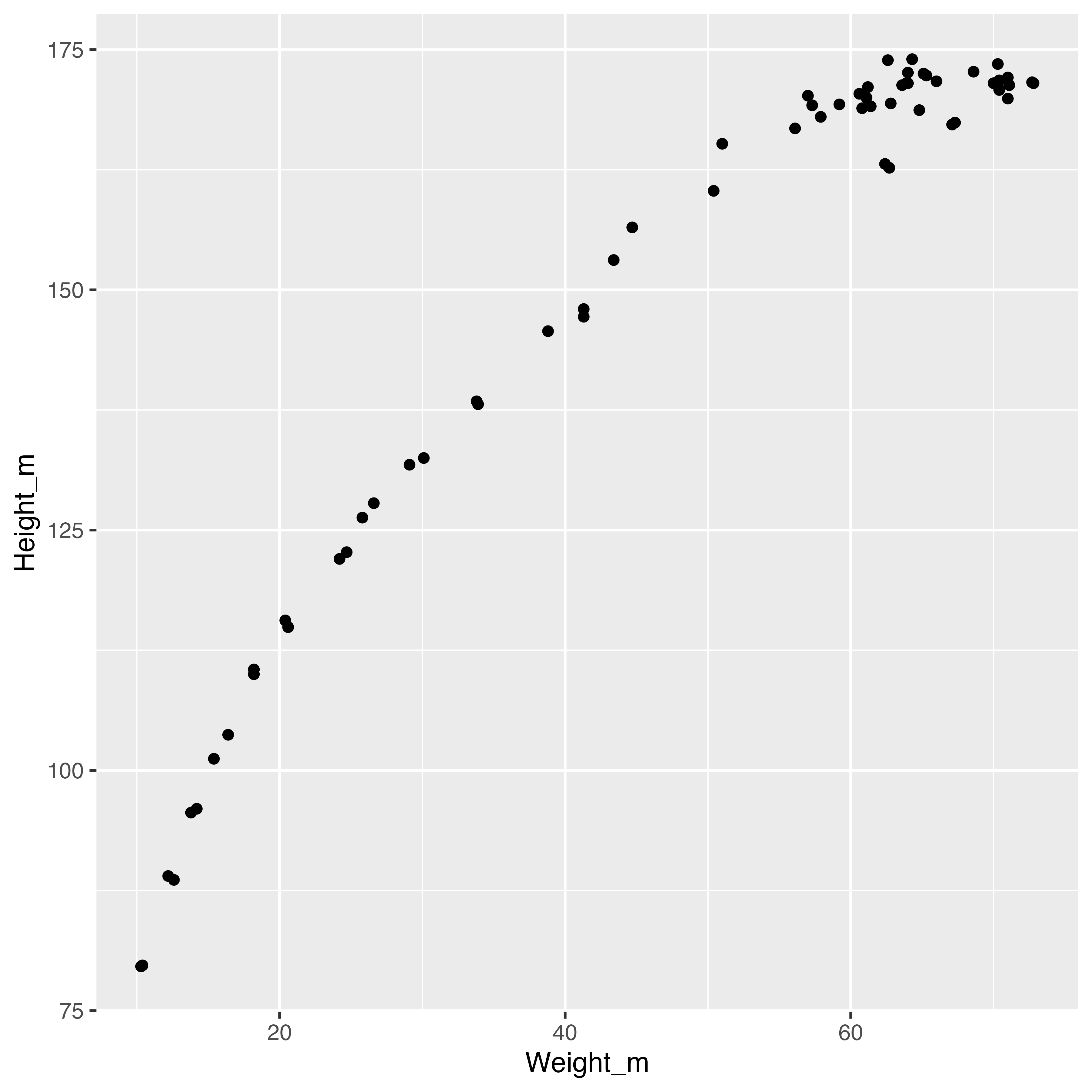
「国民健康・栄養調査」による年齢別の身長・体重データ
Call:
lm(formula = Height_m ~ Weight_m, data = height_weight)
Residuals:
Min 1Q Median 3Q Max
-19.02 -6.79 1.33 6.58 12.11
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 84.7973 2.4348 34.8 <2e-16 ***
Weight_m 1.3391 0.0464 28.9 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 7.61 on 60 degrees of freedom
Multiple R-squared: 0.933, Adjusted R-squared: 0.932
F-statistic: 834 on 1 and 60 DF, p-value: <2e-16身長と体重は有意に正の関係がある。
でも,これは明らかに因果関係ではない。
おそらく単なる相関関係
偶然相関があるように見える

人口あたりのチーズの消費量とベッドシーツに絡まって死ぬ人の数

アメリカの科学・宇宙・テクノロジーに対する支出と首吊り,絞殺,窒息による自殺者数
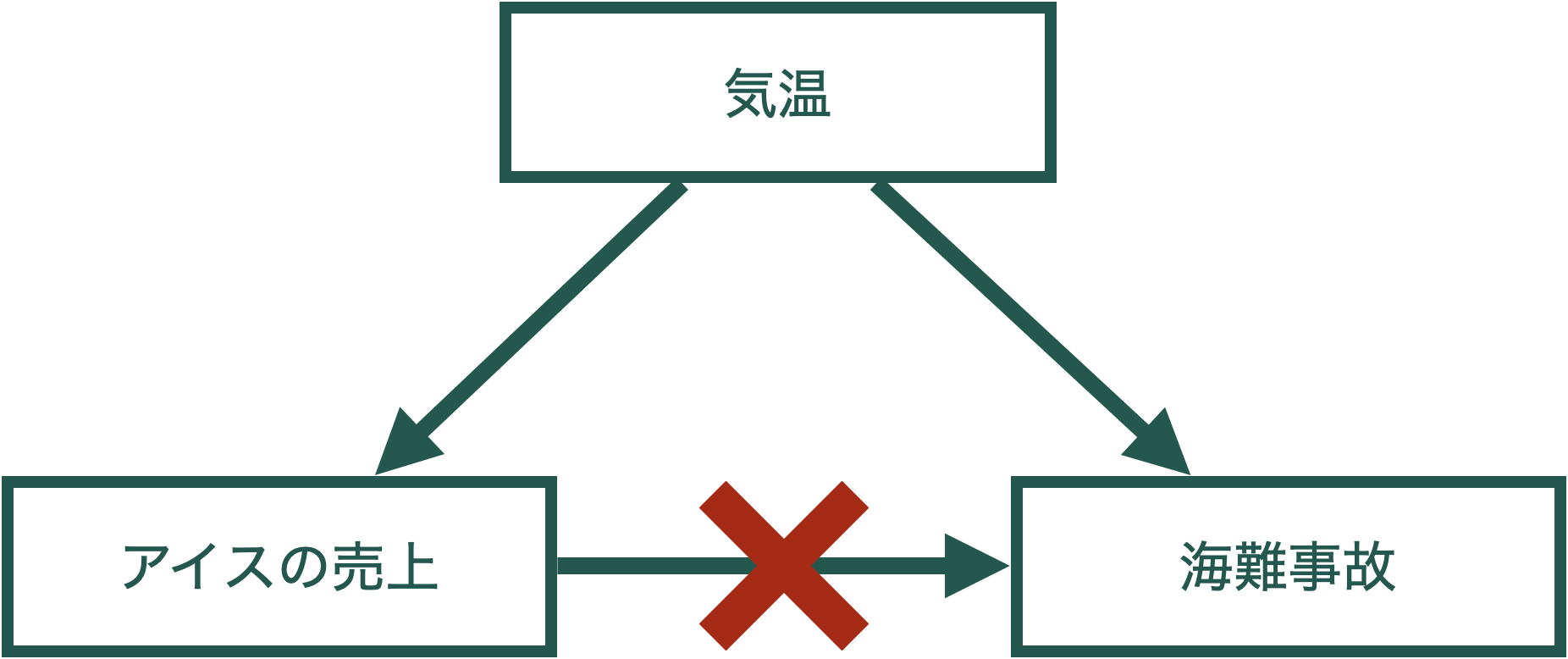
つまり…
単に相関を計算したり,回帰分析をしただけではx → yという因果関係はわからない。
仮に薬の効果を知りたいとしたら,薬を投与した人と投与しない人1人ずつのその効果(例えば血液検査の結果数値など)を比べる?

適切な比較はできない
本来的には薬の効果(薬と症状改善の因果関係)は「同じ人が投与した場合と投与していない場合」を比較しないといけない。

でも,現実に観察されるのはどっちか。薬ありもしくは薬なしどっちかのデータしか取れない。
パラレルワールド・タイムマシンがない限り実現できない。反実仮想が必要。
因果推論の根本問題とか言われる
たくさんの参加者を集めて,その人たちにランダムに処置(投与するかしないか)を割り振る
ランダムに割り振った集団間の比較をすることで薬の「平均的な」効果を推定することができる

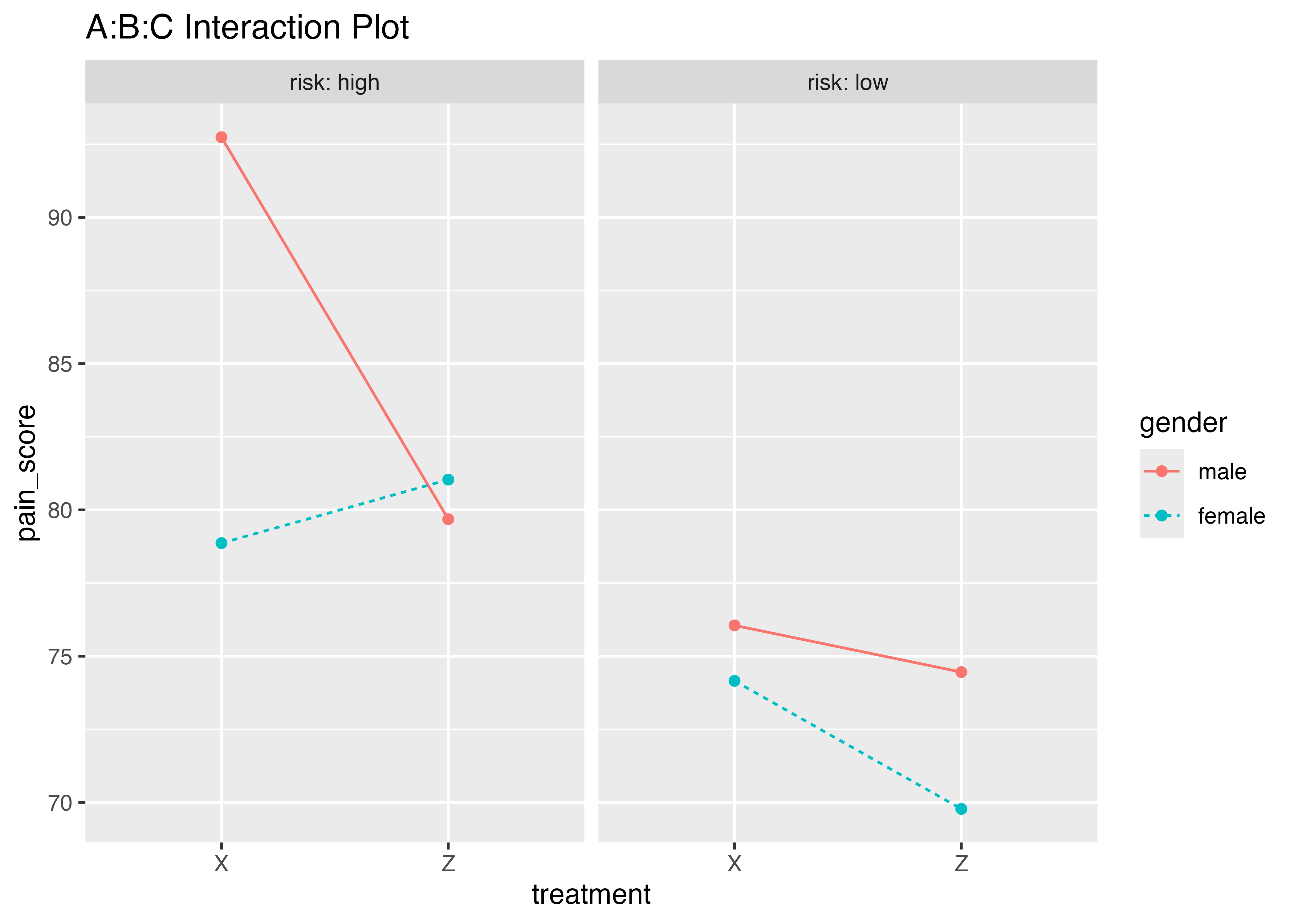
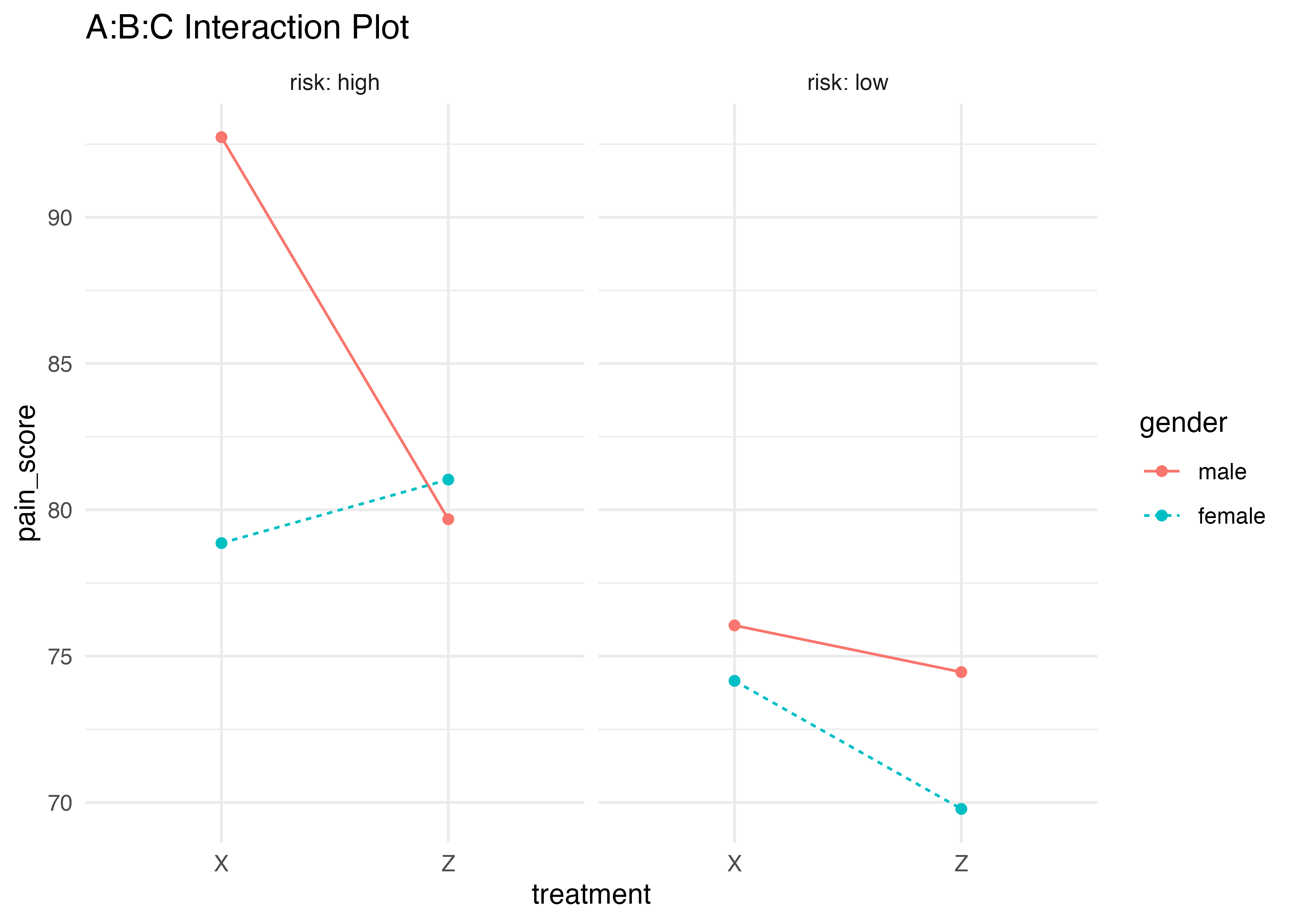
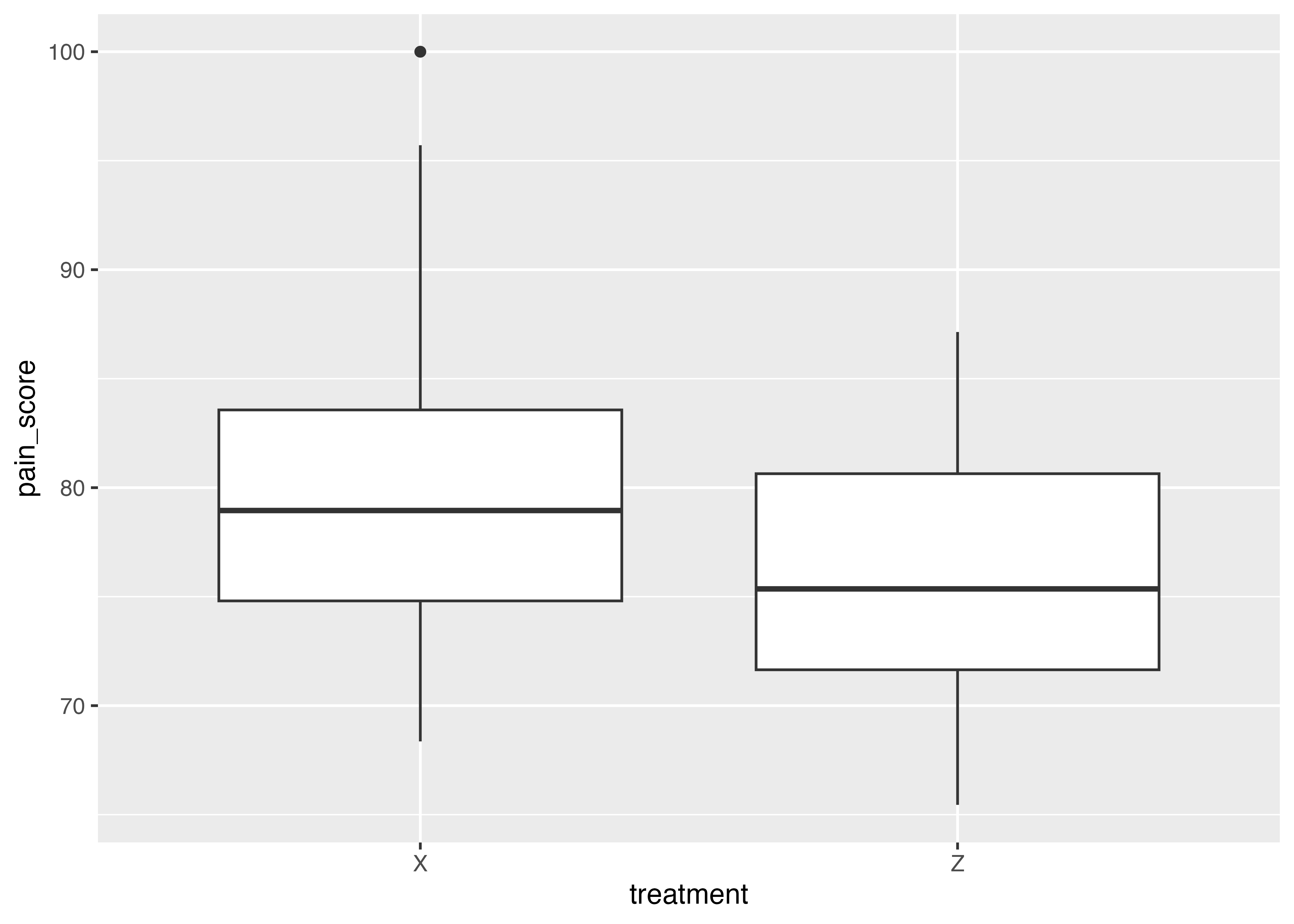
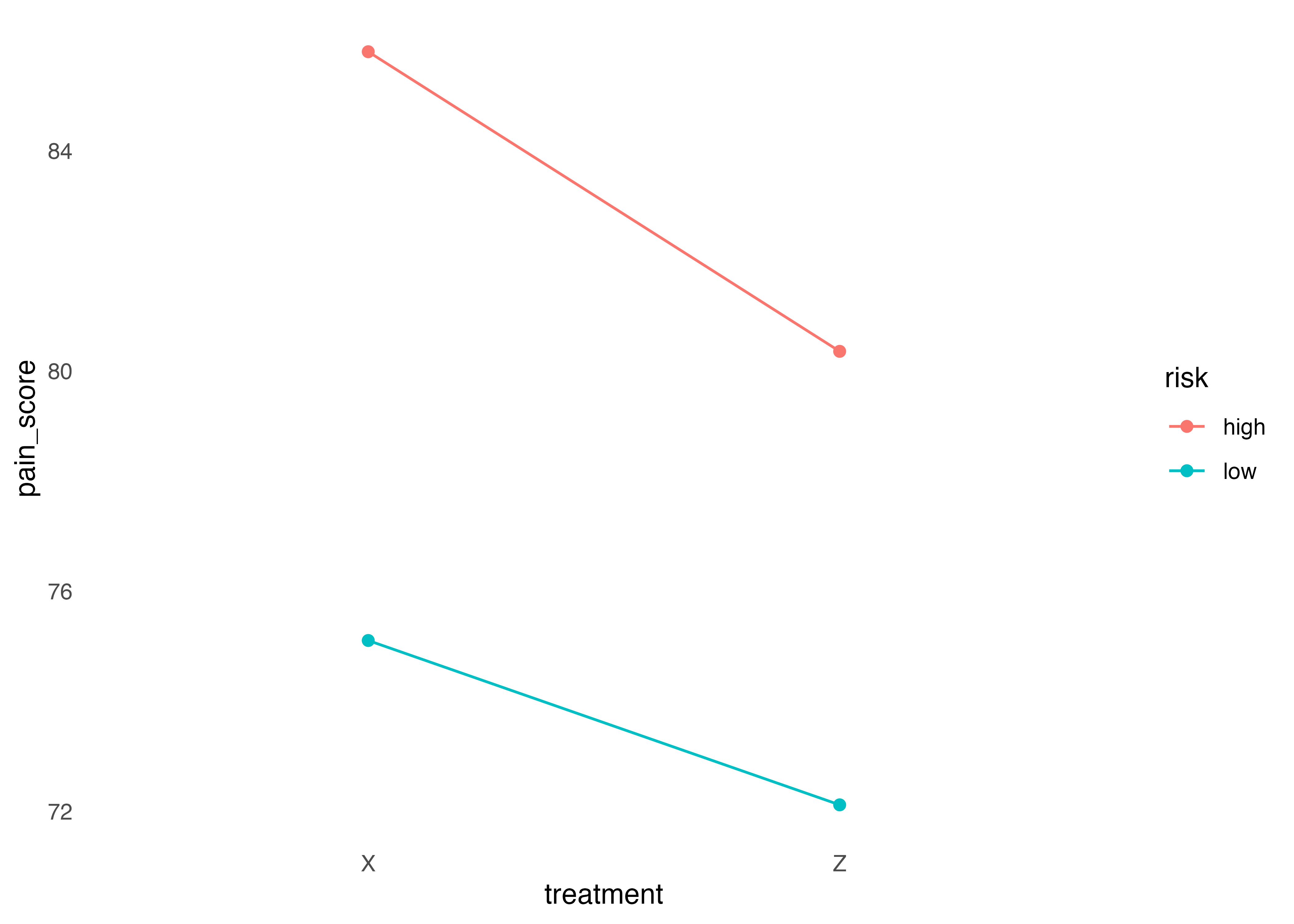
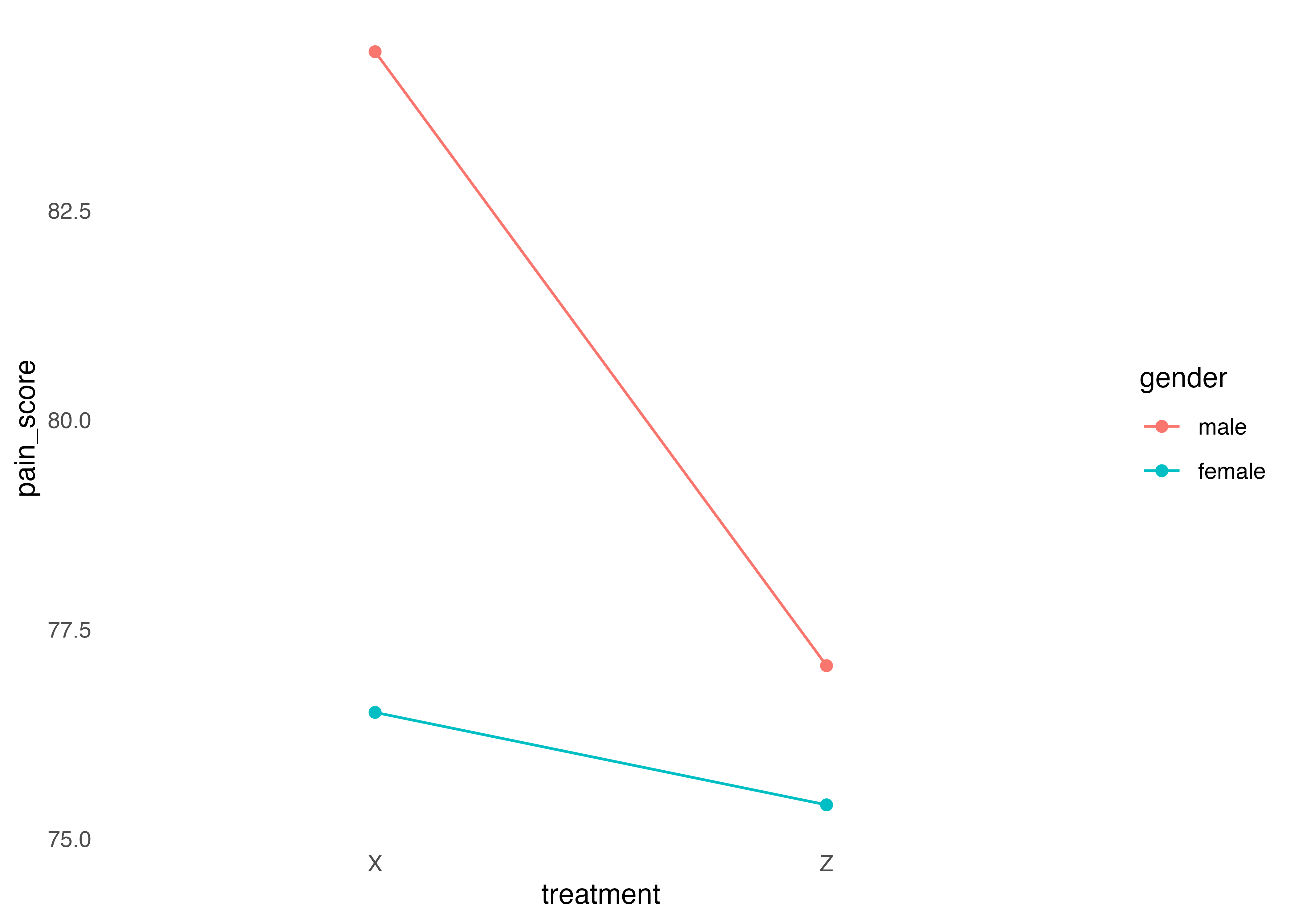
また,ggline()コマンドを使うと,効果を図に表せる
int <- interaction.ABC.plot(data = headache,
1 response = pain_score,
x.factor = treatment,
groups.factor = gender,
trace.factor = risk) interaction.ABC.plot (daeパッケージ)を使うと比較的簡単にかける