13 コストドライバとKPIの分析
2024/07/05
2 BSC(Balanced Scorecard:バランスト・スコアカード)とは
端的に言うと
- 「測定できなければ管理できない」と言う精神のもと
- 財務指標だけでは測れない業務における多様な側面を非財務的な複数の指標で測定し
- 多面的に測定・評価しよう
という取り組み。複数の視点を4つの視点に整理

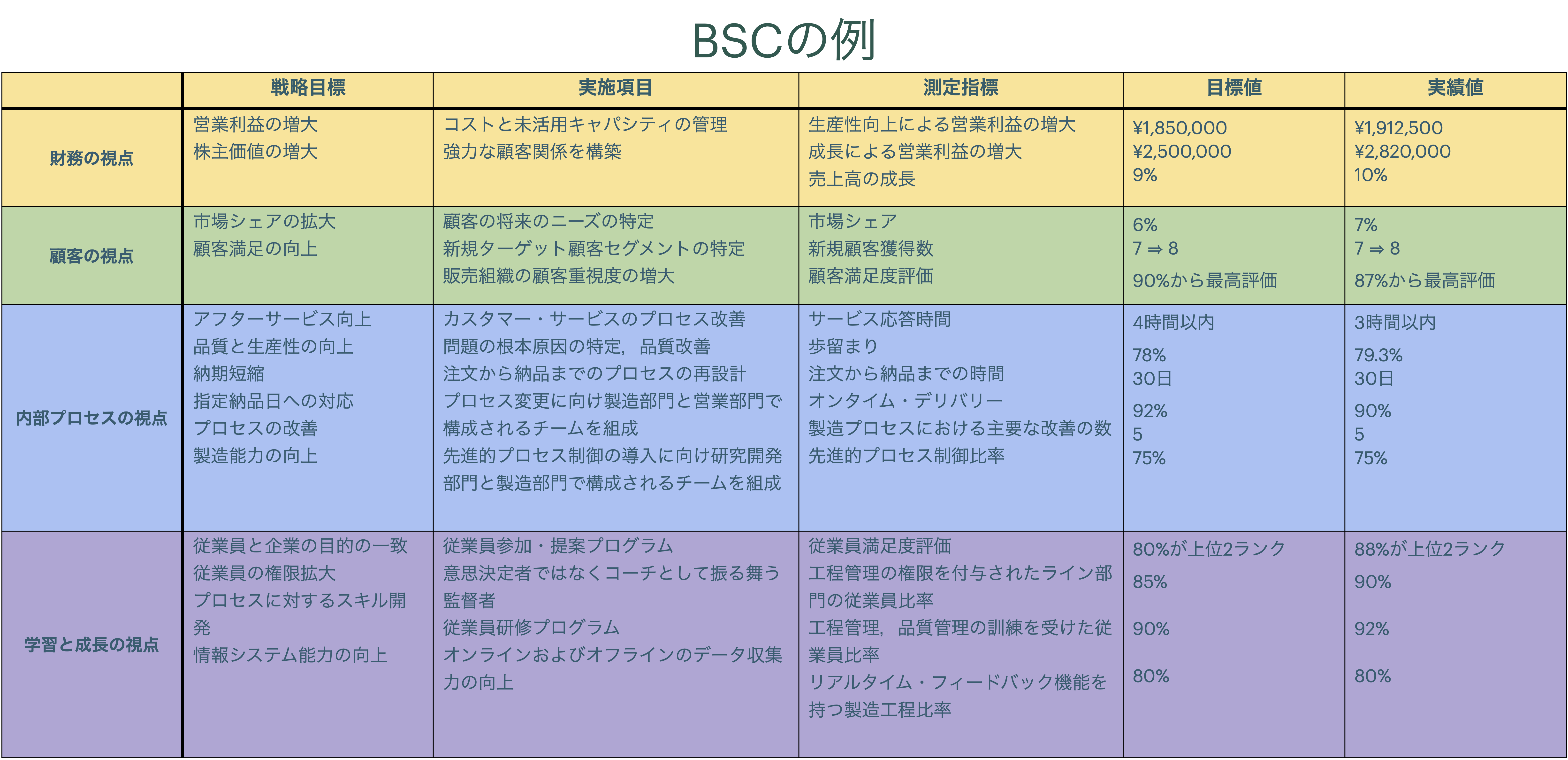
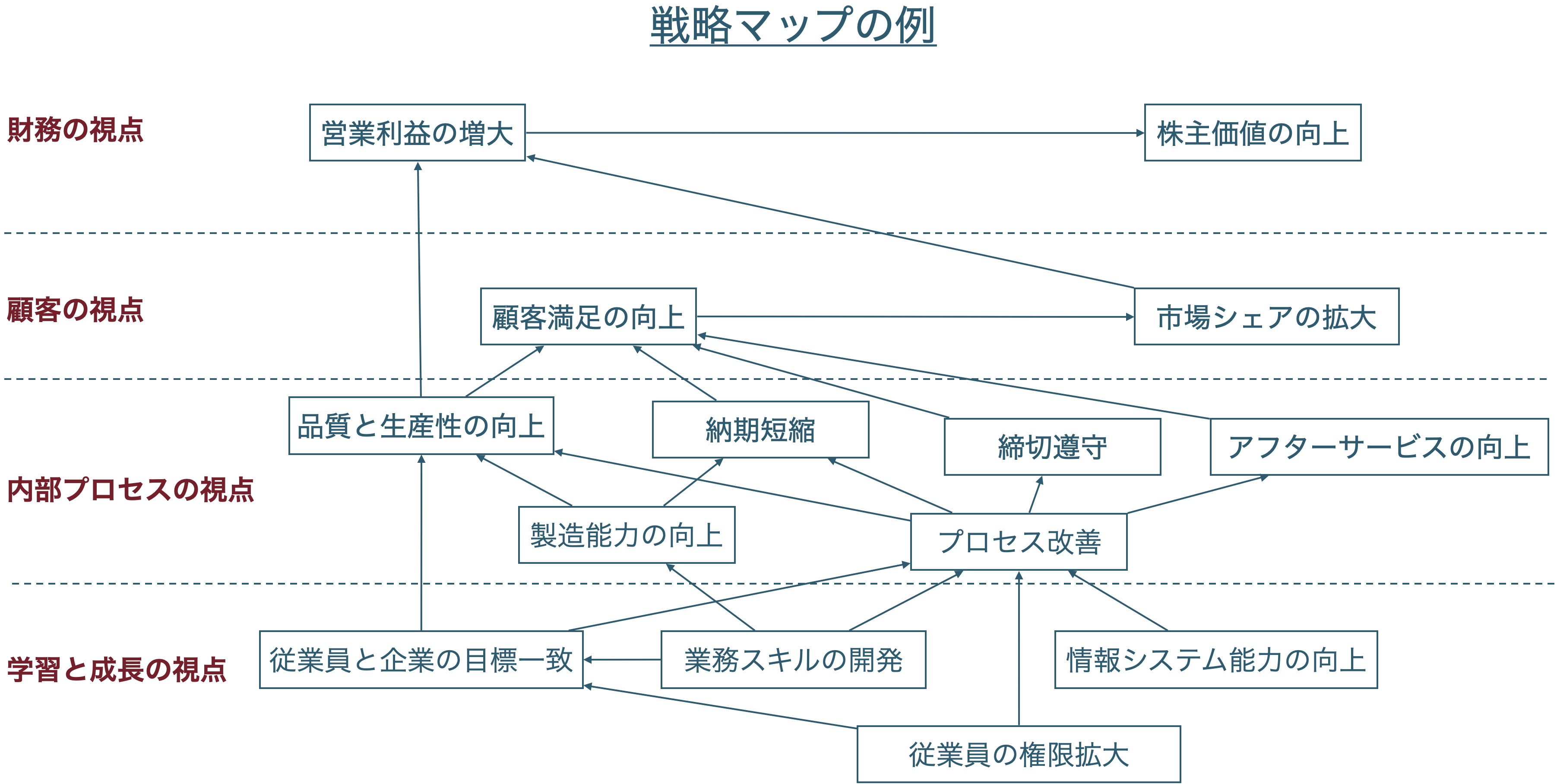
2.1 戦略マップ
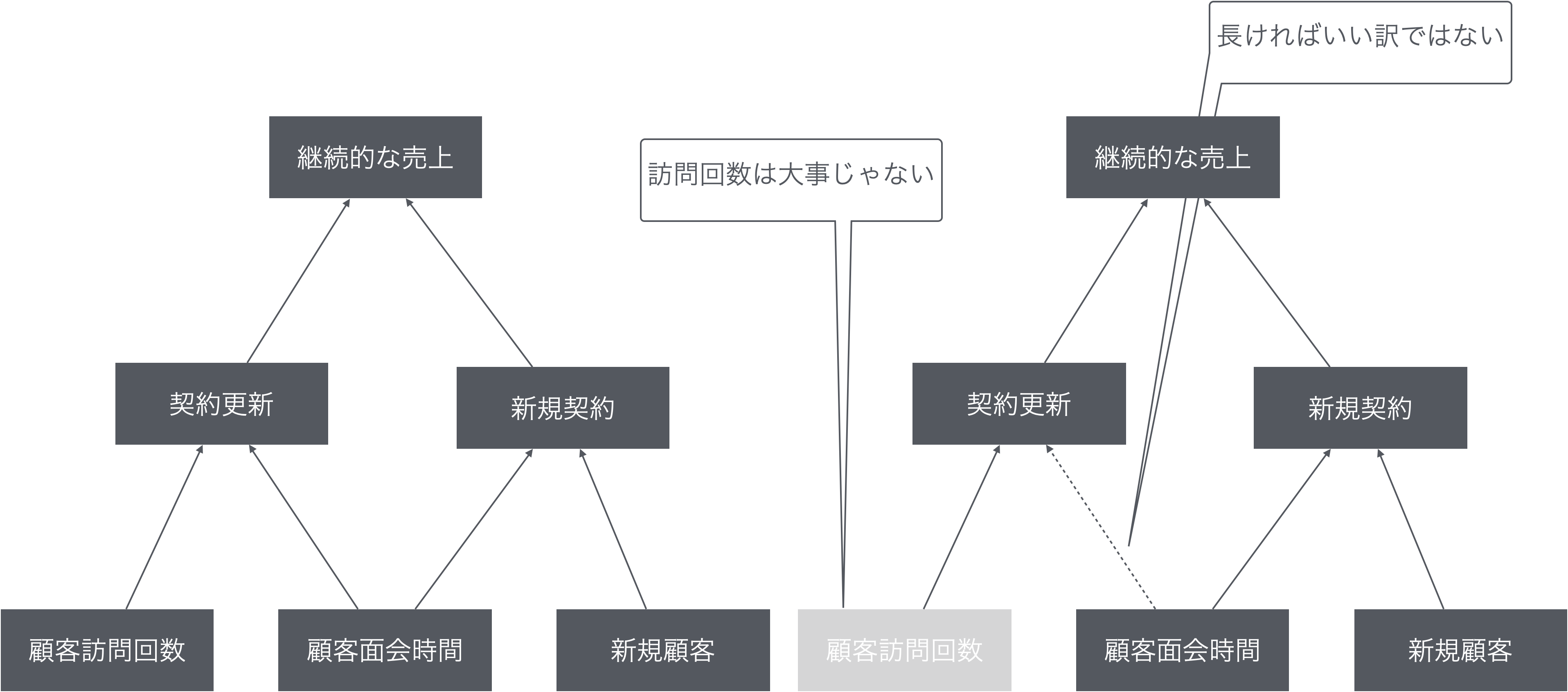
BSCで設定される指標間に想定される因果関係を図示したのが戦略マップ
2.2 期待される効果
2.2.1 短期志向の緩和
会計業績は通常1年,半年,4半期などの単位で集計
会計数値を目標として業務を行うと,比較的短期の業績を高くするために行動をとるように
- 言い換えると,長期的な視点が欠如する
- もっとひどい場合は長期的業績を犠牲にして短期的業績をとりに行くような行動をとる
BSCでは,より長期的な視野を持った指標(顧客→社内プロセス→育成と行くほど長期的な視点に立っています)を管理指標とすることで,短期思考を軽減することが期待される
2.2.2 多面的な業績評価
財務指標は従業員たちが企業の目的に沿った行動をとっているかどうかを把握する指標としては不完全
- 例えばチームワークよく働けるような気配りや,部下のフォロー,アドバイスとった行動は,企業の目的達成に資する行動だけど,財務指標では測定しづらい
BSCを用いることで,このような会計情報だけでは把握しにくい企業の貢献を多面的な指標によって汲み取れることが期待される
- BSCなどの多面的業績評価システムが業績を改善するということは数多くの研究で報告されている (Lee and Yang 2011; Chenhall 2005; Hyvönen 2007; Van der Stede, Chow, and Lin 2006)。
2.2.3 指標間の因果関係を意識した行動の変容
「顧客満足は大事」,「従業員満足は大事」,「利益目標の達成は大事」など大事なことは様々
- それら大事なものを会計指標にこだわらず数値化して管理する,というのがBSC
- 戦略マップと併用することで,大事なもの同士の関係が明示される

3 戦略的業績測定システム運用上の困難性
BSCをはじめとする戦略的業績測定システムは,
- 多様な指標を組み合わせて使う
ことを想定し,暗黙的に,もしくは明示的に
- 指標間の因果関係を想定
します。
理想的には,因果関係が本当に存在するのかどうかを定期的に確認し,改善していくことが望まれる
しかし,この指標間の因果関係を実際に検証するのはすごく難しいです。
結果として…
間違った目標に向けて努力
結果に繋がらない

3.1 そもそも何が難しいのか?
- 根本的に因果関係を推定するのは難しい
最近因果推論の研究者がノーベル経済学賞を取っている(2021年)ように,データから因果関係を明らかにする手法は発展している。でも難しい。
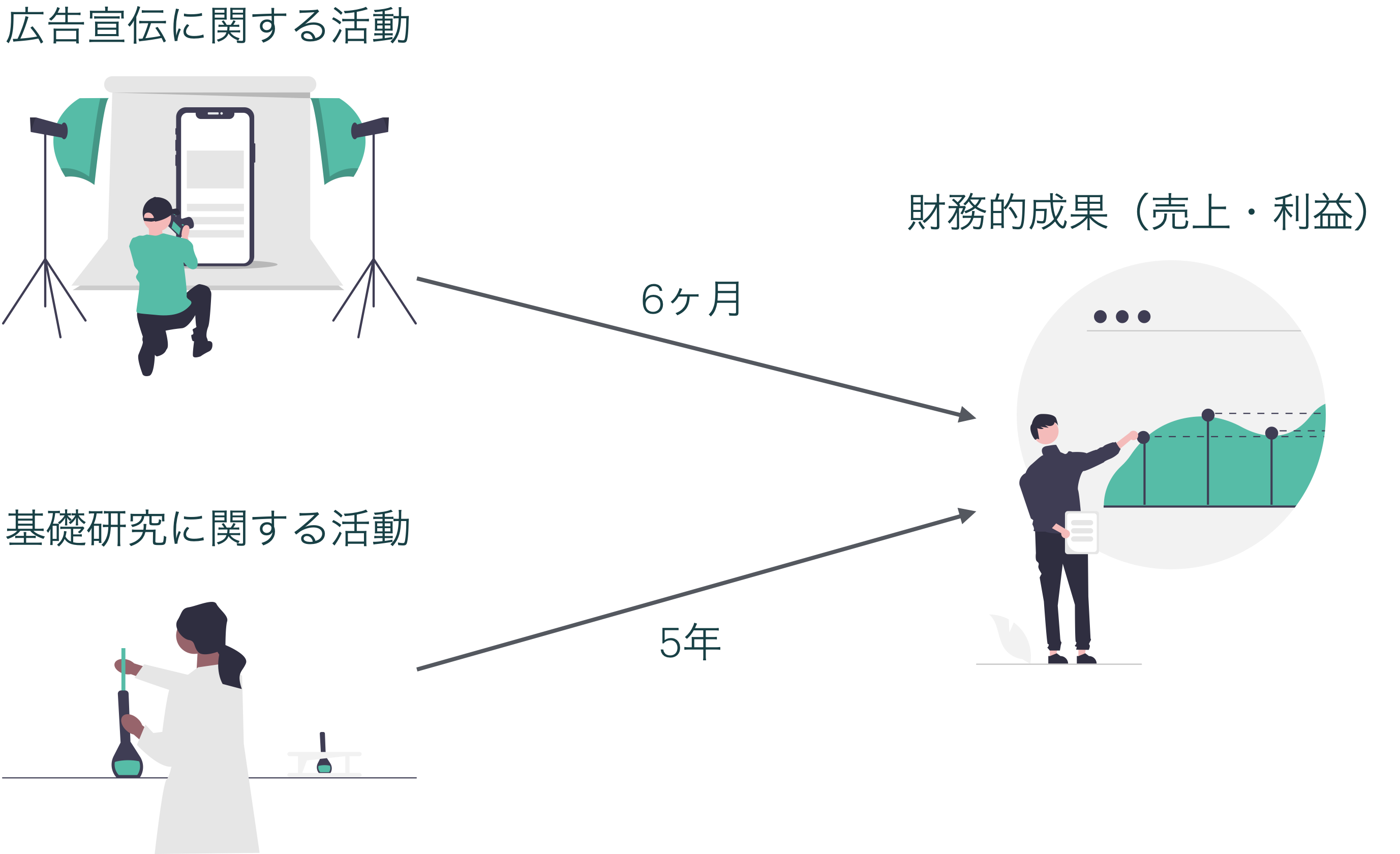
- 各関係は異なるタイムラグを持つかもしれない
- 非財務指標と財務指標との間の関係は線形ではないかもしれない
例えば,最高品質を目指すことは収益につながるのか?
- ある程度以上を超えたら十分,みたいなラインはないのか?
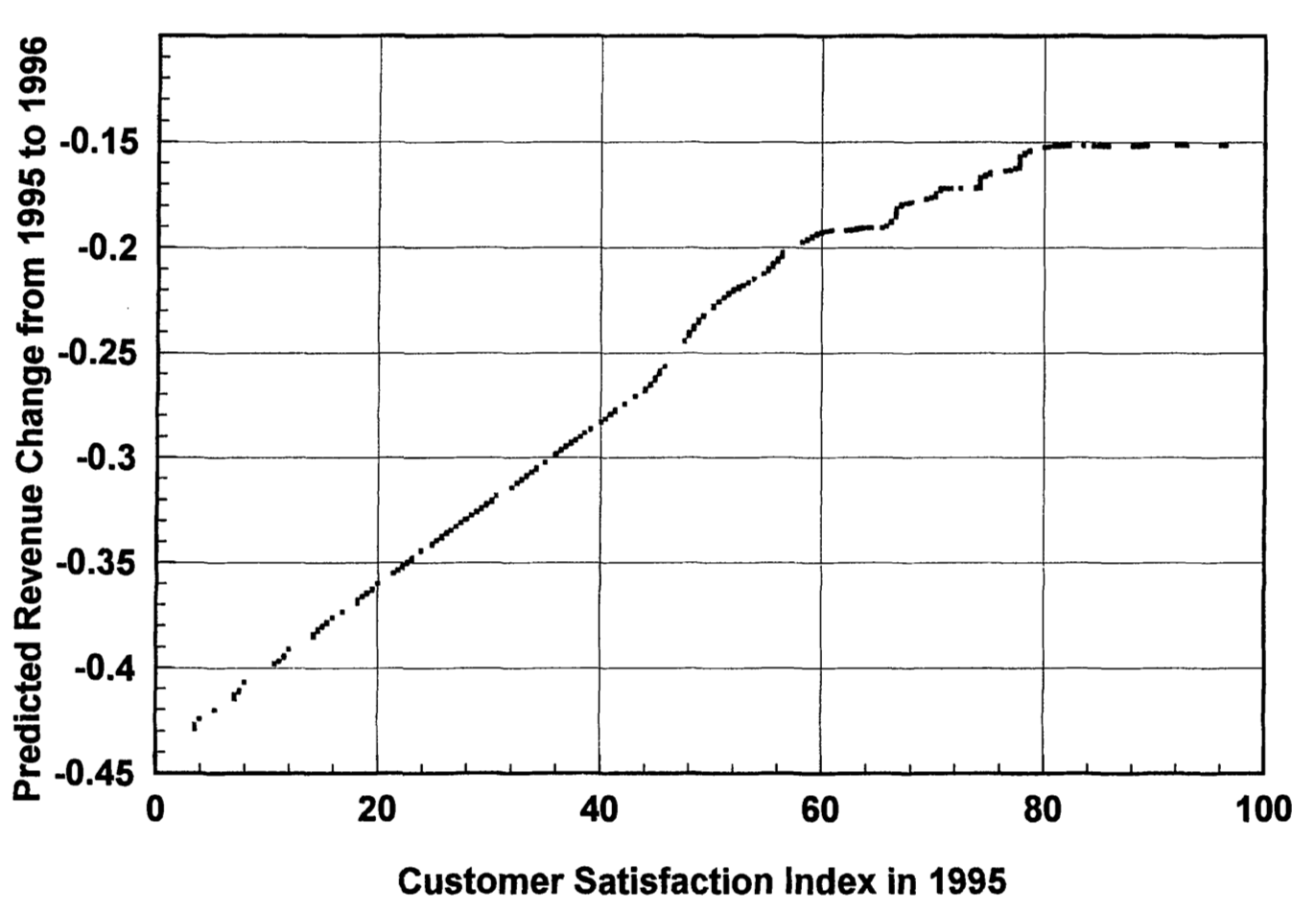
Ittner and Larcker (1998)
アメリカの通信会社の顧客満足データと財務データを使って,満足度と収益変化の非線形な関係を発見。
再掲
- 各関係は異なるタイムラグを持つかもしれない
6.2.2 時系列グラフ
Code
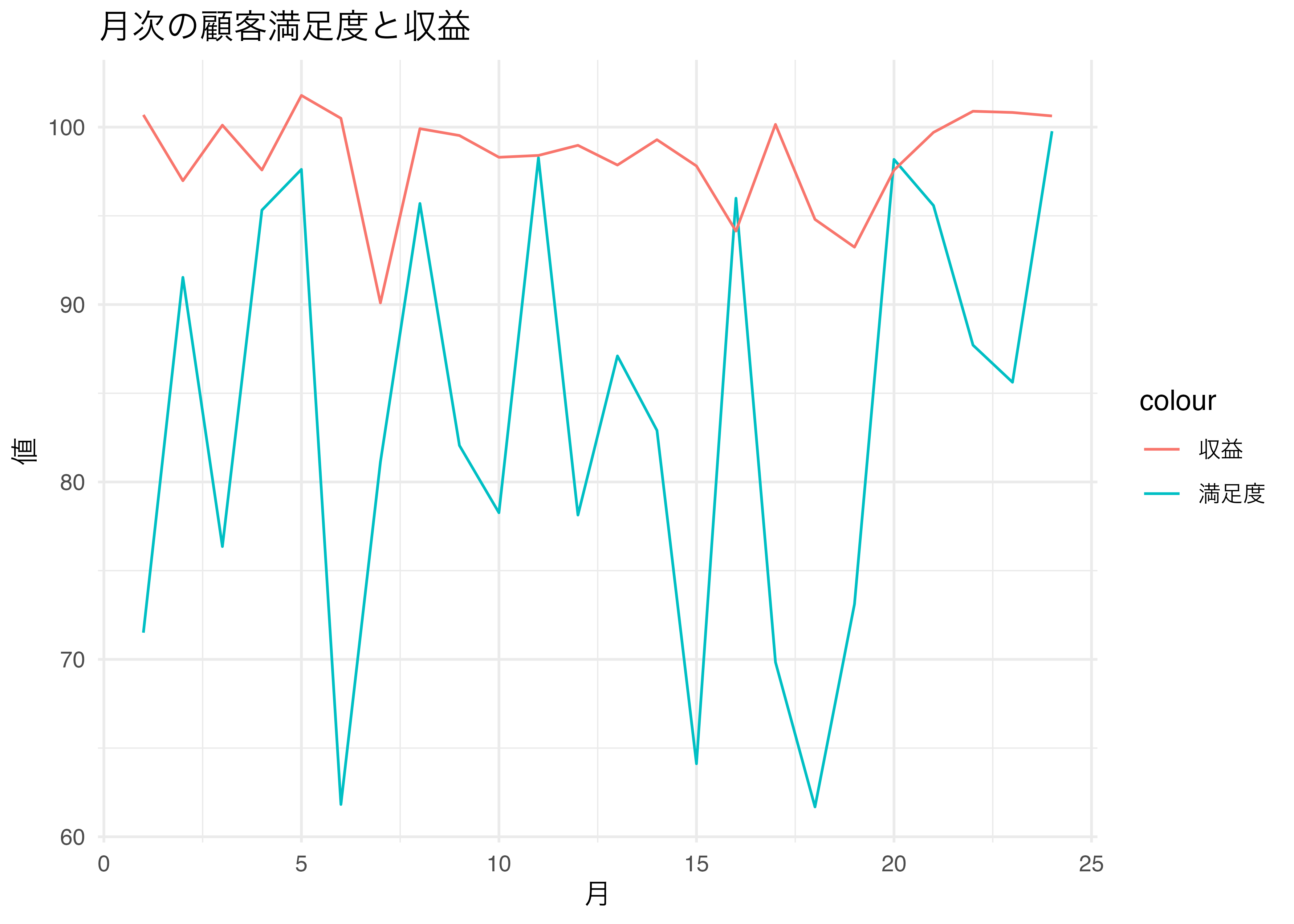
満足度と収益の間にはタイムラグがありそう。1ヶ月程度。
Code
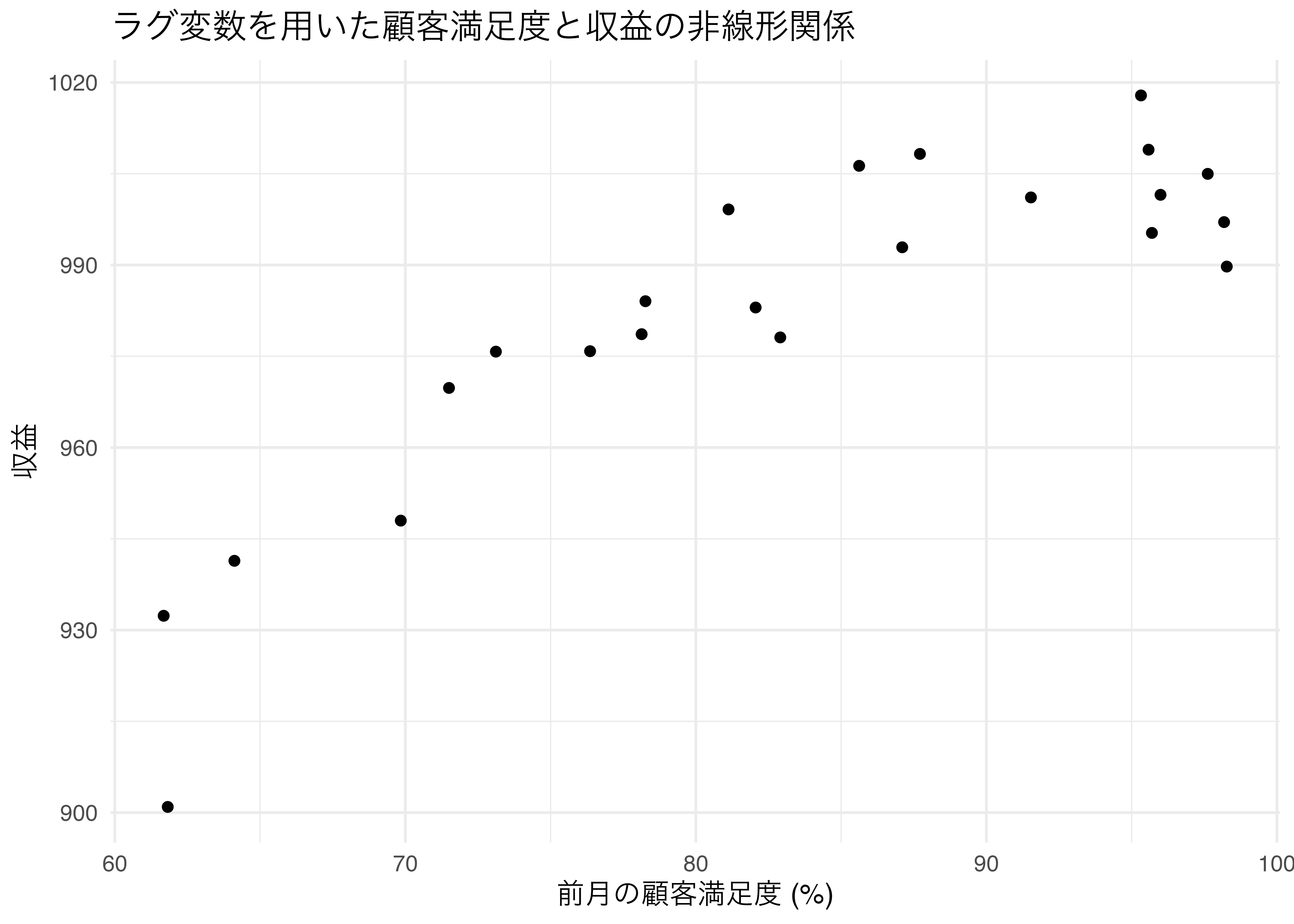
微妙だけど,顧客満足度がある程度以上高いとき,収益は伸びていなさそう
6.3 分析
6.3.1 非線形関係の表現
線形回帰モデルでは,独立変数の高次の項目を入れることで非直線の関係をモデル化できる
\[ y_i = \beta_0 + \beta_1 x_i + \beta_2 x^2_i + e_i \tag{1}\]
Equation 1 は \(x\)の二次関数とみることができる。
- \(\beta_2\)が正だとUの形,負だと放物線の形
Rでは,高次の項を含めるときには以下のように表現する
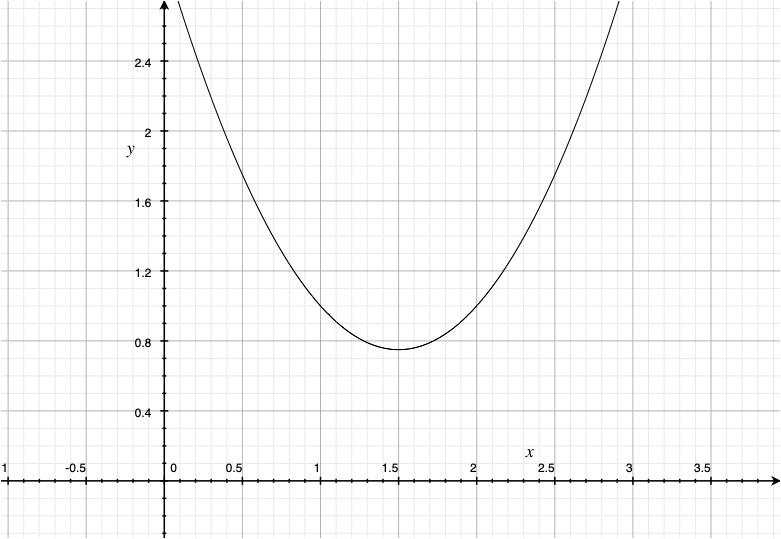
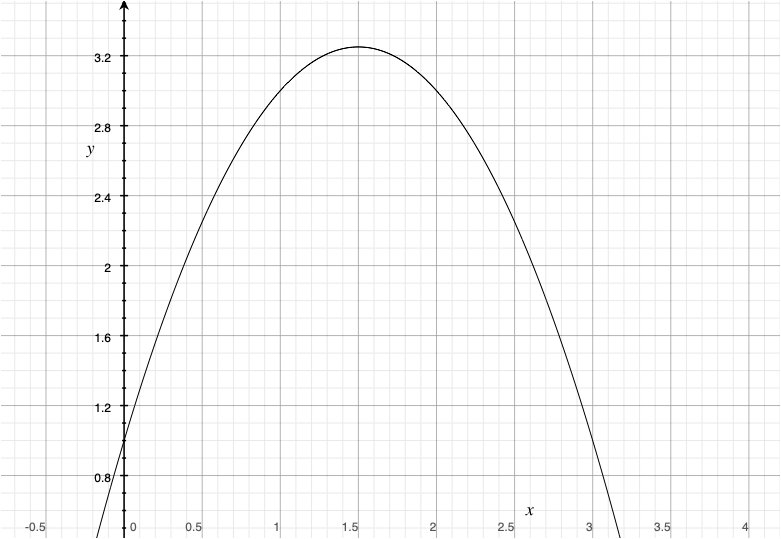
Code
m0 <- lm(revenue ~ lagged_satisfaction, data = kpi2)
m1 <- lm(revenue ~ lagged_satisfaction + I(lagged_satisfaction^2), data = kpi2)
m2 <- lm(revenue ~ lagged_satisfaction + I(lagged_satisfaction^2)+ I(lagged_satisfaction^3), data = kpi2)
# モデルの要約
list(m0, m1, m2) |>
modelsummary(stars = TRUE,
gof_omit = 'Log.Lik.|RMSE')| (1) | (2) | (3) | |
|---|---|---|---|
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 | |||
| (Intercept) | 813.544*** | 286.774* | 496.759 |
| (21.388) | (104.605) | (977.322) | |
| lagged_satisfaction | 2.032*** | 15.311*** | 7.226 |
| (0.255) | (2.617) | (37.498) | |
| I(lagged_satisfaction^2) | -0.082*** | 0.020 | |
| (0.016) | (0.474) | ||
| I(lagged_satisfaction^3) | 0.000 | ||
| (0.002) | |||
| Num.Obs. | 23 | 23 | 23 |
| R2 | 0.751 | 0.892 | 0.892 |
| R2 Adj. | 0.739 | 0.881 | 0.875 |
| AIC | 191.9 | 174.8 | 176.8 |
| BIC | 195.3 | 179.4 | 182.4 |
| F | 63.447 | 82.196 | 52.201 |
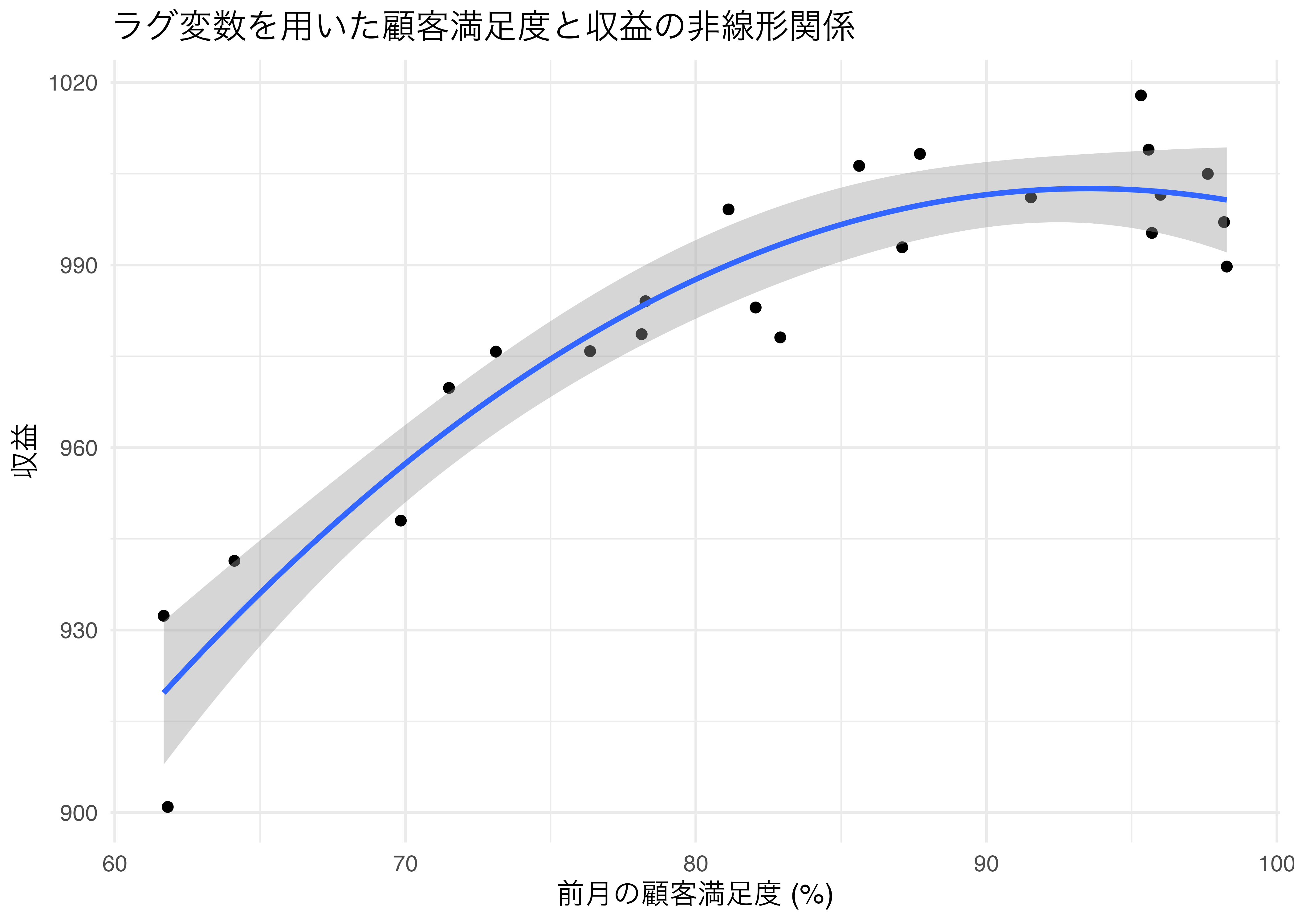
二次関数のモデル2が良さそう
- 決定係数,AIC,BIC,係数の有意性
二次の項が有意に負→放物線の形
Code
6.3.2 他のモデルとの比較
Code
# ラグなしの線形モデル
model1 <- lm(revenue ~ satisfaction, data = kpi2)
# ラグなしの非線形モデル(2次関数)
model2 <- lm(revenue ~ satisfaction + I(satisfaction^2), data = kpi2)
# ラグを含む線形モデル
model3 <- lm(revenue ~ lagged_satisfaction, data = kpi2)
# ラグを含む非線形モデル(2次関数)
model4 <- lm(revenue ~ lagged_satisfaction + I(lagged_satisfaction^2), data = kpi2)
# ラグなしとラグありの変数を両方含むモデル
model5 <- lm(revenue ~ satisfaction + I(satisfaction^2) + lagged_satisfaction + I(lagged_satisfaction^2), data = kpi2)
# 各モデルの結果を表にまとめる
models <- list(
"線形モデル(ラグなし)" = model1,
"非線形モデル(ラグなし)" = model2,
"線形モデル(ラグあり)" = model3,
"非線形モデル(ラグあり)" = model4,
"複合モデル(ラグなし+ラグあり)" = model5
)
modelsummary(models,
stars = TRUE,
gof_omit = 'Log.Lik.|RMSE',
title = "顧客満足度と収益の関係モデル比較")| 線形モデル(ラグなし) | 非線形モデル(ラグなし) | 線形モデル(ラグあり) | 非線形モデル(ラグあり) | 複合モデル(ラグなし+ラグあり) | |
|---|---|---|---|---|---|
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 | |||||
| (Intercept) | 960.107*** | 1043.680** | 813.544*** | 286.774* | 445.484** |
| (40.958) | (300.653) | (21.388) | (104.605) | (137.868) | |
| satisfaction | 0.276 | -1.820 | -2.634 | ||
| (0.484) | (7.483) | (2.237) | |||
| I(satisfaction^2) | 0.013 | 0.019 | |||
| (0.046) | (0.014) | ||||
| lagged_satisfaction | 2.032*** | 15.311*** | 13.467*** | ||
| (0.255) | (2.617) | (2.397) | |||
| I(lagged_satisfaction^2) | -0.082*** | -0.070*** | |||
| (0.016) | (0.015) | ||||
| Num.Obs. | 24 | 24 | 23 | 23 | 23 |
| R2 | 0.015 | 0.018 | 0.751 | 0.892 | 0.924 |
| R2 Adj. | -0.030 | -0.075 | 0.739 | 0.881 | 0.908 |
| AIC | 232.8 | 234.7 | 191.9 | 174.8 | 170.5 |
| BIC | 236.3 | 239.4 | 195.3 | 179.4 | 177.4 |
| F | 0.326 | 0.195 | 63.447 | 82.196 | 54.989 |